Läuft überall: Die Java Virtual Machine im Überblick

Für viele ist die JVM nur das Programm, mit dem sich Java-Klassen ausführen lassen. Aber sie ist viel mehr: Sie ermöglicht, dass sich einmal erzeugte Java-Klassen auf diversen Hardwareplattformen nutzen lassen, ohne dass sie dabei Schaden anrichten können.
Die Idee einer virtuellen Maschine ist wahrlich nicht neu. Beschreibungen und Implementierungen derartiger Systeme existieren bereits aus den 1960er Jahren. Einfach gesprochen definiert man zunächst ein abstraktes System, das alle gewünschten Eigenschaften besitzt, und übersetzt Quellcode derart, dass das resultierende Programm auf der virtuellen Maschine ablaufen kann. Alle, die das Programm nun laufen lassen wollen, müssen nur noch das abstrakte System für die konkrete Laufzeitumgebung implementieren.
Prominentes Beispiel ist vielleicht das UCSD p-System, das Mitte der 1970er Jahre an der University of California in San Diego (UCSD) als maschinenunabhängiges, portables (deswegen das p) Betriebssystem gestaltetet war und erlaube, p-Code ablaufen zu lassen. Damit konnten einmal übersetzte Pascal-Programme unverändert auf jeder unterstützten Hardware laufen und die dort verfügbare Peripherie nutzen. Das p-System war sogar neben CP/M und MS-DOS eines der Betriebssysteme, die auf IBMs PC laufen konnten.
Da Java ursprünglich für eingebettete Systeme wie Set-Top-Boxen gedacht war, lag es nah, mit einer virtuellen Maschine der Anzahl verschiedenster Prozessoren und Systeme Herr zu werden. Diese Entscheidung hat sich letztlich in vielerlei Hinsicht bewährt: Unter anderem ist Java gerade wegen seiner virtuellen Maschine spezifikationsgemäßer Bestandteil jedes Blue-ray-Spielers.
Write once, run anywhere!
Die Java Virtual Machine (JVM) ist eine solche abstrakte Maschine. Sie ist sorgfältig spezifiziert und kann garantieren, dass ein Java-Programm auf jeder JVM grundsätzlich das gleiche Ergebnis liefert, weil genau definiert ist, wie Java-Programme ablaufen und wie sich die Datentypen verhalten. Programmierer, die etwa mit C/C++ arbeiten müssen, können nur neidvoll auf die Java-Spezifikation blicken, die ganz konkret definiert, wie breit etwa ein int ist. Die C-Spezifikation enthält dagegen keine konkreten Aussagen über die Größe der verwendeten Datentypen, um auch wirklich jeden Prozessor unterstützen zu können. Diese Großzügigkeit führt bei vielen Dingen zu "implementation-defined", "undefined" oder gar zum "unspecified".
In einer zufällig zur Verfügung stehenden PDF-Version einer C-Spezifikation von 1997 kommt das Wort "undefined" knapp 170-mal, "implementation-defined" 140-mal und "unspecified" 70-mal vor. In der Java Virtual Machine Specification (JVMS) kommt "undefined" nur fünfmal, "unspecified" nur einmal und "implementation-defined" überhaupt nicht vor. In der Java Language Specification (JLS) kommt "undefined" sogar nur zweimal vor; "implementation-defined" immerhin noch einmal, allerdings in einem Beispiel, das Bezug auf C/C++ nimmt. Die JVM legt die Repräsentation der einzelnen Datentypen genau fest. Beispielsweise ist ein int ein vorzeichenbehafteter 32-Bit-Wert, der im Zweierkomplement repräsentiert ist. Damit ist alles – bis hin zur Position und Wertigkeit der einzelnen Bits – eindeutig spezifiziert.
Gleitkommazahlen stellen diesbezüglich eine Besonderheit dar: Während die Repräsentation dieser Zahlen auch eindeutig definiert ist, überlässt die JVM das Rechnen mit den Zahlen der zugrunde liegenden Hardware. Deshalb wurde mit der Version 1.2 ein Flag zur Annotation von Klassen eingeführt, womit garantiert werden kann, dass auf jeder JVM das exakt gleiche Ergebnis geliefert wird – ungeachtet einer deutlich schlechteren Performance, falls in diesem Fall ohne Unterstützung der Hardware gerechnet werden muss.
Darüber hinaus macht die JVM noch eine Reihe weiterer Zusicherungen. Sie gewährleistet unter anderem die Ausführung aller Operationen in der Reihenfolge, in der sie angegeben sind. Freilich steht es der JVM frei, die Operationen umzusortieren, solange es keine Auswirkungen auf Nebeneffekte hat. Führt die Kaskade der Methodenaufrufe
o.f1().f2().f3()
zu einer Exception in f2, ist garantiert, dass f1 vollständig ausgeführt und mit f3 auf keinen Fall angefangen wurde.
Java 2017
Mehr Informationen zu Java 9, Java EE 8 und aktuellen Entwicklungen im Java-Umfeld gibt es im iX-Developer-Sonderheft zum Thema, das unter anderem im heise Shop [1] erhältlich ist.
Nicht zuletzt ist durch das Java Memory Model (JMM) genauestens spezifiziert, wie sich die JVM in einem nebenläufigen und parallelen Kontext verhält. Es beschreibt, welche Operationen atomar ablaufen und welche Sichtbarkeitsgarantien bei Mehrkern- oder Multiprozessorsystemen gewährt werden können.
Entwickler wissen somit jederzeit, was sie erwarten können und auf was sie achten müssen. Sie können alle Programme für die JVM problemlos auf jede andere JVM bringen. In diesem Zusammenhang sei jedoch erwähnt, dass die Umgebung, in der die JVM läuft, durchaus eine Rolle spielt. In Abhängigkeit vom Betriebssystem müssen Entwickler sorgfältig darauf achten, welche Annahmen sie beispielsweise über das Dateisystem oder die Benutzeroberfläche machen. Das betrifft genau genommen jedoch die Java-Bibliotheken und nicht die JVM.
Stapelweises Verarbeiten
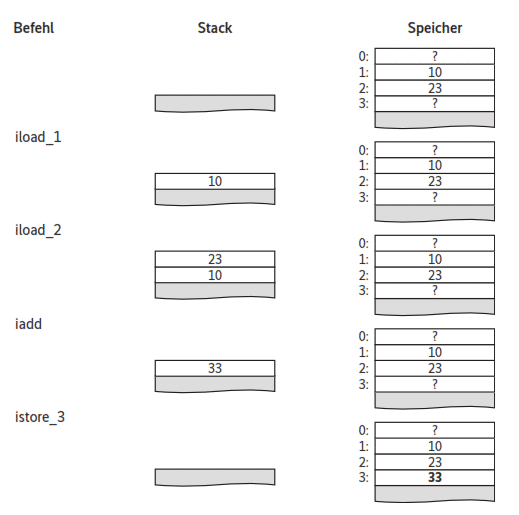
Die JVM ist eine Stack-orientierte Maschine. Das bedeutet, dass sie keine Register hat, sondern die für eine Operation benötigten Werte auf einem Stack (Stapel) ablegt und sie durch das Ergebnis austauscht. Das System berechnet beispielsweise den Ausdruck
c = a + b;
für ganzzahlige int, indem es zunächst den Wert von a aus dem lokalen Speicher lädt und auf dem Stack ablegt. Anschließend lädt es den Wert von b und legt es auf dem Stack ab. Schließlich ruft es die für int zuständige Addition auf, die die beiden zuoberst liegenden int entfernt und sie durch ihre Summe ersetzt. Abschließend wird diese Summe vom Stack entfernt und im lokalen Speicher von c gespeichert. In der Code-Repräsentation werden die Namen für a, b und c durch nummerierte Speicherplätze ersetzt. Wenn die drei Variablen auf den Plätzen 1, 2 und 3 liegen, sieht der Code für obige Anweisung folgendermaßen aus:
iload_1
iload_2
iadd
istore_3
Einen Stack zu benutzen ist in vielerlei Hinsicht praktisch. Insbesondere lässt sich damit eine virtuelle Maschine nahezu trivial und vor allem effizient implementieren, weil für die Ausführung nicht viel mehr als der Stack und der lokale Speicher benötigt werden. Die JVMS beschreibt das wie folgt:
do {
atomically calculate pc and fetch opcode at pc;
if (operands) fetch operands;
execute the action for the opcode;
} while (there is more to do);

Zudem verlangt die JVM für jede Methode den exakt benötigten lokalen Speicher und die maximal benötigte Größe des Stacks, was Stack-Überläufe verhindert. Schließlich gibt es durch die Nummerierung der Speicherplätze keine Adressen (Pointer), die in anderen Sprachen zu überraschenden Fehlern führen können.
Häppchen in Byte-Größe
Die auszuführenden Instruktionen legt das System einzeln in Bytes ab. Da der Bytecode extrem kurz ist, lässt er sich effizient über ein Netzwerk übertragen. Nur zum Vergleich (von Äpfeln und Birnen): Die Java-Version des klassischen "Hallo Welt!"-Programms, das nichts anderes tut, als ebendiese Zeichenkette auszugeben, benötigt (in Abhängigkeit von der Länge der Paket- und des Klassennamens) etwas mehr als ein halbes KByte (540 Byte). Das funktionsgleiche Programm in C belegt knapp 8 KByte (8432 Byte), von denen der Teil, der die eigentliche Anweisungen für die Ausgabe enthält, lediglich 768 Byte benötigt.
Der tatsächlich ausführbare Bytecode in Java nimmt übrigens deutlich weniger Platz ein: Der Code für die Initialisierung der Klasse benötigt lediglich 5 Byte und die Ausgabe der Zeichenkette 9 Byte. Der Rest enthält zusätzliche Informationen wie den Klassennamen, die Methodensignaturen, Dateinamen, Zeilennummern und Ausnahmen.
Java 2017
Mehr Informationen zu Java 9, Java EE 8 und aktuellen Entwicklungen im Java-Umfeld gibt es im iX-Developer-Sonderheft zum Thema, das unter anderem im heise Shop [2] erhältlich ist.
Nebenbei bemerkt ist eine Java-Klassendatei eine effiziente Datenstruktur, die sämtliche Informationen über den sogenannten Constant Pool bereitstellt. Dabei werden alle Elemente variabler Größe als Attribute gespeichert, die sich über ihren Namen identifizieren lassen. Neben den für den Ablauf vordefinierten Attributen lässt sich eine Klasse so (auch für eigene Zwecke) beliebig erweitern.
Die Entscheidung, die Instruktionen in einzelnen Bytes abzulegen, hat jedoch auch Nachteile. Unter anderem ist der Befehlssatz dadurch auf "nur" 256 Instruktionen beschränkt. Des Weiteren müssen die Befehle oder deren Teile, die aus mehreren Bytes bestehen, in der Regel aus einzelnen Bytes zusammengesetzt werden, da die zugrunde liegende Hardware möglicherweise keine direkten Zugriffe auf Wörter erlaubt, die nicht an passenden Adressen ausgerichtet sind. Aber die dadurch entstehenden längeren Ausführungszeiten nimmt man billigend für die kleineren Klassendateien in Kauf.
Sicher ist sicher
Eine Besonderheit der JVM ist, dass sie sich nicht darauf verlässt, dass der hauseigene Java-Compiler eine Klasse übersetzt hat. Ein Grund dafür könnte in der Historie von Java liegen, die von der Idee geprägt war, auszuführenden Code von irgendwoher über das Netzwerk zu übertragen. Code, der – wenn auch nur kurzfristig – nicht mehr der Kontrolle der Erzeugers unterliegt, kann manipuliert worden sein. Also muss nicht nur sicher gestellt sein, dass der Code unverändert sein Ziel erreicht, sondern (unveränderter) Code nicht mehr darf, als ihm zugestanden wird.
Vor der Ausführung überprüft der Bytecode Verifier zunächst, ob eine Klasse überhaupt der definierten, äußeren Form genügt. Unter anderem muss die Klassendatei mit der hexadezimalen Byte-Sequenz CA FE BA BE beginnen und die richtige Versionsnummer haben. Anschließend überprüft das System grob, ob die Klasse den inneren Einschränkungen genügt. Dazu gehört, dass keine zwei Methoden denselben Namen und dieselbe Signatur haben und die Oberklasse eine Ableitung zulässt, also nicht final ist.
Erst anschließend lässt sich die Klasse überhaupt verwenden. Aber vor jeder tatsächlichen Ausführung prüft der Bytecode Verifier Zug um Zug weitere Eigenschaften und gleicht beispielsweise erst beim Aufruf einer Methode die Größe des Stacks und die Anzahl der lokalen Variablen mit dem Bytecode ab – ohne ihn auszuführen. Das System führt die Instruktionen erst aus, wenn sichergestellt ist, dass sämtliche auf dem Stack abzulegenden Werte zu der jeweiligen Instruktion passen und mit dem auszuführenden Code kein Schindluder getrieben werden kann.
Zudem stellt die JVM sicher, dass Klassen nur auf diejenigen Elemente einer anderen Klasse zugreifen dürfen, die dafür bestimmt sind. Privates ist nur der Klasse selbst vorbehalten, Öffentliches kann von allen Objekten gelesen und geschrieben werden, einiges ist nur Klassen vorbehalten, die aus dem selben Paket stammen oder in einer Vererbungsbeziehung zueinander stehen. Mit Java 9 lassen sich Klassen darüber hinaus noch in Module packen, die anderen Modulen nur dann Zugriff auf Elemente gewähren, wenn diese zusätzlich explizit exportiert werden.
Unabhängig davon ist jede Klasse noch einem logischen Besitzer zugeordnet (dem Class Loader), der darüber entscheidet, woher die noch zu ladenden Klassen kommen sollen und welche Rechte der Code hat. Während Ersteres ermöglicht, innerhalb der JVM sogar verschiedene Versionen ein und derselben Klasse auszuführen, hat Letzteres nur insoweit mit der JVM zu tun, dass diese darüber Buch führt, wer welche Klasse geladen hat.
Clever interpretiert
Nach dem Laden einer Klasse interpretiert die JVM den Code Byte für Byte. Aufgrund der Stack-orientierten Struktur und des einfachen Formats des Bytecode geht das relativ schnell vonstatten. Trifft die JVM dabei auf eine noch unbekannte Klasse, lädt sie diese unter Berücksichtigung der beschriebenen Sicherheitsmechanismen nach. Alleine um das kurze "Hallo Welt!"-Programm laufen zu lassen, lädt die JVM unter Java 1.8 – Java SE Runtime Environment (Build 1.8.0-b132) mit Java HotSpot 64-Bit Server VM (Build 25.0-b70) unter Mac OS X 10.12.4 – sage und schreibe 426 Klassen. Um einen Webserver ans Laufen zu bringen sind mehrere Tausend Klassen erforderlich.
Die Ausführungsgeschwindigkeit ist trotz dieser Interpretation in vielen Fällen völlig ausreichend. Die Vorteile wiegen die Performanceeinbußen mehr als auf. Durch das dynamische Verhalten lassen sich Klassen zu einem beliebigen Zeitpunkt nachladen. Das bedeutet unter anderem, dass Entwickler die Software auch erst zur Laufzeit konfigurieren können, was sie unter C/C++ nicht mit derselben Leichtigkeit erreichen.
Dennoch ist die Performance ein nicht zu unterschätzender Faktor beim Betrieb einer Anwendung. Damit Java mit anderen Systemen konkurrieren kann, bedient man sich eines eleganten Vorgehens: Die Übersetzung des Bytecode in nativ ausgeführten Maschinencode erfolgt nur, wenn es sich zu lohnen scheint. Das ist etwa bei Schleifen der Fall: Die häufige Ausführung derselben Codefragmente wiegen die Übersetzungskosten relativ schnell auf.
Die enorme Qualität der Just-in-time-Übersetzungen solcher Hot Spots ist nicht zu unterschätzen, weil die JVM dabei auf Informationen zugreifen kann, die typischerweise bei der Übersetzungszeit noch nicht zur Verfügung stehen. Da sie über jede geladene Klasse Bescheid weiß, kann sie Optimierungen vornehmen, die sonst nicht möglich wären oder nur für eine Übergangszeit gelten. Beim Ausführen des Codes einer abstrakten Klasse, von der die JVM weiß, dass nur genau eine konkrete implementierende Klasse im System existiert, kann sie deren Code getrost überall hineinkopieren (inlining), um die aufwendigen dynamischen Aufrufe zu eliminieren. Erst wenn sie eine weitere Implementierung der abstrakten Klasse lädt, müsste die JVM die Änderungen wieder rückgängig machen und eine konservativere Optimierung vornehmen.
Optimierungen dieser Art, die gelegentlich sogar C++-Entwickler vor Neid erblassen lassen, gehen so weit, dass die JVM bei einer Schleife feststellen kann, dass sie die Werte gar nicht benötigt und in dem Fall die Schleife vollständig entfernt. Diese Cleverness erschwert es leider, bei einzelnen Codeteilen zu messen, ob eine Variante schneller ist als eine andere. Beim Isolieren des zu messenden Bereich kann es passieren, dass die JVM den Code ausnahmslos interpretiert, weil sie ihn vor der Messung nicht oft genug durchlaufen hat. Ebenso könnte sie Regelmäßigkeiten erkannt und durch Konstanten ersetzt haben oder den Code vollständig eliminieren, weil das Ergebnis nicht genutzt wird.
Dynamisch dank Indy
Eigentlich bietet die JVM alles, was Java-Programmierer brauchen, aber Java ist nunmal nicht die einzige Sprache, die auf der JVM laufen soll. Statisch typisierte Programmiersprachen, die im Vorfeld alles Wissenswerte kennen, haben in der Regel keine Probleme, ihren Syntaxbaum auf den Bytecode abzubilden. Problematischer wird es bei den dynamischen Sprachen, die etwa bei a + b überhaupt nicht wissen, welche Typen a und b haben werden.
Eine Implementierung dafür scheint auf den ersten Blick unmöglich, weil die JVM immer genauestens prüft, ob die Parameter wirklich zu dem Befehl passen. Aber auch hierfür gibt es seit Java 7 eine Lösung in der JVM: Das Invoke Dynamic (Indy). Mit Hilfe der Indy-Anweisung lässt sich der konkrete Aufruf auch zur Laufzeit festlegen.
Dazu wird im Bytecode nicht wie sonst der Aufruf einer konkreten Methode (invokevirtual) oder einer konkreten Prozedur (invokestatic) eingebettet, sondern ein dynamischer Aufruf über eine Beschreibung getätigt (invokedynamic). Letztere enthält insbesondere die (unveränderliche) verantwortliche Stelle, die Auskunft darüber gibt, was unter den gegebenen Bedingungen (beispielsweise in Abhängigkeiten der konkret übergebenen Werten) zu tun ist. An dieser Stelle lässt sich eine Art Referenz der aufzurufenden Methode liefern
Das Interessante daran ist, dass sich die Gültigkeitsdauer dieser Methodenreferenz festlegen lässt. Sie kann nur für das eine Mal gelten, aber auch für alle zukünftigen Aufrufe. Ebenso ist möglich, dass sie nur solange gilt, bis eine bestimmte Bedingung eintritt. Entwickler haben damit ein mächtiges Mittel an der Hand, das ihnen sogar ermöglicht, eigene Aufrufmechanismen zu implementieren. Und das Beste daran ist, dass die JVM immer noch alle Laufzeitoptimierungen vornehmen kann, weil sie immer genau weiß, mit was sie es zu tun hat, wenn auch eventuell nur temporär.
Unangenehme Aufräumarbeiten
Ein wunder Punkt der JVM ist die Speicherbereinigung (Garbage Collection). Dass Programme den Speicher für die Objekte nicht explizit freigeben müssen, ist grundsätzlich eine feine Sache. Schließlich verhindert das eine Reihe kaum nachvollziehbarer und oft nicht reproduzierbarer Fehlern. Allerdings ist das Feature nicht wirklich eine freiwillige Entscheidung zugunsten einer besseren Entwicklung, sondern eine strenge Notwendigkeit aus Sicherheitsgründen. Denn nur dadurch lässt sich effektiv verhindern, dass jemand auf Daten zugreift, die er nicht sehen darf. Andernfalls könnte ein Objekt eine freigegebene Referenz behalten, wodurch das Programm gelegentlich schauen könnte, ob etwas Interessantes darin zu finden ist.
Die Speicherbereinigung kann leider den laufenden Betrieb merklich unterbrechen. Zwar erfordern C/C++-Umgebungen ebenfalls eine Freigabe des Speichers, was dort aber kontinuierlich geschieht, sofern die Entwickler es nicht vergessen oder falsch umsetzen. Die Speicherbereinigung findet dort versteckt als Teil eines Ablaufs statt. Die JVM muss jedoch zunächst herausfinden, ob sie ein Stück Speicher überhaupt freigeben kann.
In der Regel ist der Zeitpunkt zur Freigabe irgendwann gekommen und kann inkrementell erfolgen, wenn der Speicher Stücke enthält, die groß genug sind, um wiederverwendet zu werden. Irgendwann kann die JVM jedoch an den Punkt gelangen, an dem sie den Speicher umsortieren muss. Im schlechtesten Fall muss sie dafür den Betrieb vollständig anhalten und kann erst nach der Speicherbereinigung wieder weiter laufen. Je größer die Anzahl der freizugebenden Speicherstücke, umso länger dauert das Blockieren für die Freigabe. Das kann eventuell die laufende Anwendung länger anhalten. Allerdings hat sich bei der Speicherbereinigung viel weiterentwickelt, sodass diese Aufgabe zu immer kürzeren Unterbrechungen führt.
Offene Wünsche
Trotz alledem gibt es noch viele Dinge mehr, die man sich für die JVM wünschen kann. Gelegentlich hilft es bereits, die Software auf der aktuellen JVM laufen zu lassen. Wenn man Pech hat, verlangsamt das Teile der Software, aber insgesamt führt jede neue Version zu einer deutlichen Verbesserung. Schließlich kann sich die JVM mit der Zeit immer besser auf die Neuerungen in der Prozessortechnik einstellen. Als Beispiel seien die breiteren Prozessorregister genannt, die mehr Daten gleichzeitig verarbeiten können (Single Instruction, Multiple Data – SIMD). So lassen sich etwa in einem 256-Bit-Register vier 64-Bit-Zahlen, acht 32-Bit-Zahlen, sechzehn 16-Bit-Zahlen oder zweiunddreißig Byte gleichzeitig manipulieren.
Darüber hinaus gibt es aber noch weiteren Verbesserungsbedarf. Ein wichtiger Punkt sind Werteobjekte, die sich einerseits wie Objekte strukturieren und mit Methoden versehen, und andererseits wie primitiven Datentypen über den Stack verwalten lassen. Damit muss die JVM sie nicht jedes Mal erzeugen, um sie im Anschluss direkt wieder einzusammeln. Gleichermaßen wichtig ist die Option, bei einer Methode mehrere Werte zurückzuliefern, um nicht behelfsweise auf Arrays oder spezialisierte Objekte zurückgreifen zu müssen.
Viele Entwickler wünschen sich, mehr Einfluss auf das Layout der einzelnen Felder eines Objekts (oder später auch eines Werts) nehmen zu können, damit sie das Verhalten beim Caching beeinflussen können. Das schließt insbesondere das Linearisieren von Objekten ein, indem beispielsweise nur die Werte eines Objekts in einem Array abgelegt werden und nicht deren Referenzen. Nicht zuletzt wünschen sich besonders die Bibliotheksentwickler einen besseren Zugang zu Maschinenbefehlen, die in den meisten modernen Prozessoren verfügbar sind.
Letzteres gilt übrigens auch für die Entwickler der JVM selbst, die sich wünschen, dass sie sowohl diese als auch den Hot-Spot- beziehungsweise Just-in-time-Compiler weitestgehend in Java schreiben können. Wenn sie schon eine extrem kniffelige Software schreiben müssen, sollten sie es wenigstens in der Sprache tun können, für die sie den ganzen Aufwand treiben.
Fazit
Die JVM ist ein faszinierendes Stück Software, das die Art zu Programmieren und Programme auszuliefern nachhaltig verändert hat. Wegen des bis ins kleinste Detail sorgfältig spezifizierten Konzepts genügt es nunmehr, (Java-)Progamme ein einziges Mal zu erstellen, um sie in beliebigen Umgebungen mit einer JVM ablaufen zu lassen. Darüber hinaus lassen sich aus gleichem Grund auch die virtuellen Maschinen selbst problemlos austauschen, so dass neben der ohnehin schon sehr effizienten Referenzimplementierung Alternativen zur Verfügung stehen, die für spezifische Anwendungszwecke (extrem großer Speicher, maximale Performance, unterbrechungsfreie Ausführung etc.) ausgerichtet sind.
Darüber hinaus erlaubt die Abstraktion der JVM, die Ablaufqualität unabhängig vom Programm zu verbessern – was in den letzten zwanzig Jahren kontinuierlich erfolgreich demonstriert wurde. Die JVM kann nämlich die aktuellen Entwicklungen der Prozessoren berücksichtigen und die Just-in-time- und Hot-Spot-Optimierungen entsprechend anpassen. Dabei wird sehr sorgfältig darauf geachtet, dass die Kompatibilität gewahrt bleibt: So laufen auch heute noch alle Programme, die für die erste Version vor über zwanzig Jahren geschrieben und übersetzt wurden.
Alles in allem ist die JVM also ein wunderbares Konzept, um die zunehmenden Komplexität von Hard- und Software in den Griff zu bekommen.
Michael Wiedeking
ist Gründer der MATHEMA Software GmbH und Java-Programmierer der ersten Stunde. Am liebsten "sammelt" er Programmiersprachen und beschäftigt sich mit deren Design und Implementierung – auch mit seiner eigenen, die auf der JVM läuft.
(rme [3])
URL dieses Artikels:
https://www.heise.de/-3847142
Links in diesem Artikel:
[1] https://shop.heise.de/katalog/ix-developer-java
[2] https://shop.heise.de/katalog/ix-developer-java
[3] mailto:rme@ix.de
Copyright © 2017 Heise Medien