
MISRA-C++ bietet Richtlinien und Konformität auch für neuen Sprachstandard C++20
Mit den Programmierrichtlinien MISRA-C++:2020 erhalten Entwickler ein Werkzeug, das sie auf dem Weg der sicheren Programmierung mit C++20 unterstützt.

(Bild: BeeBright / Shutterstock.com)
- Peter Sommerlad
C++ wird oft für technische Systeme eingesetzt, die zuverlässig funktionieren müssen. Ein Fehlverhalten einer solchen C++-Software durch Programmierfehler, zum Beispiel im Auto, kann damit eine Gefahr für Leib und Leben darstellen. Diese Gefahr wird durch funktionale Sicherheit (Safety) adressiert. Aus diesem Grund existieren Programmierrichtlinien und statische Prüfwerkzeuge. Ziel ist es, das Risiko durch typische Programmierfehler, die zum Beispiel Undefined Behavior verursachen, zu reduzieren. Dieser Artikel thematisiert die entsprechenden Richtlinien mit dem Fokus auf die gerade aktualisierten MISRA-C++-Regeln.
Oft steht die Informationssicherheit (Security) im Fokus und selten die funktionale Sicherheit. Bei vernetzten technischen Systemen ist Informationssicherheit jedoch eine Voraussetzung für funktionale Sicherheit. Zum Beispiel konnten Hacker schon aus der Ferne Fahrzeuge manipulieren, wie beim sogenannten Chrysler Jeep Hack.
Notwendigkeit für Regelwerke ergibt sich häufig aus der Praxis
Allgemeine Regelwerke, wie die Norm EN 61508 "Funktionale Sicherheit sicherheitsbezogener elektrischer/elektronischer/ programmierbarer elektronischer Systeme", fordern "gute Ingenieurspraxis", wie umfassende Dokumentation und Validierung, sowie sinngemäß die Nutzung des "Stands der Technik", also keine überholten Verfahren und Technologien. Speziellere Regelwerke, zum Beispiel für Luftfahrzeuge, versuchen Dinge zu verhindern, die früher passiert sind.
Zum Beispiel haben Großflugzeuge heute in der Kabine durchweg abgerundete Fenster. Diese wurden vorgeschrieben, nachdem die de Havilland Comet 1, ein früher Passagierjet in den 1950er-Jahren, mit Druckkabine und eckigen Fenstern abstürzte. Als Absturzursache konnte man Risse im Rumpf feststellen, die sich von den Fensterecken her ausbreiteten. Das zeigt in vielen Fällen, vor allem beim Einsatz neuer Technologien, wie damals der Flugzeugdruckkabine, dass man Sicherheit erst durch schlechte Erfahrungen erlangt. Darum können sich neuere Programmiersprachen und Sprachversionen (C++20) nicht in den entsprechenden Richtlinien wiederfinden. Es fehlt schlicht die Erfahrung, was bei der Anwendung neuer Dinge, beispielsweise Coroutinen, schiefgehen kann.


Die Programmiersprache C++ gibt es seit 1979. Über vier Millionen aktive Entwicklerinnen und Entwickler nutzen sie heute. Das iX-Developer-Sonderheft "Modernes C++" bietet zahlreiche Artikel zum neuen Sprachstandard C++20 und eine Sammlung der iX-Artikel zu C++ aus den vergangenen zwei Jahren. Zu den Highlights zählen ein Interview mit Bjarne Stroustrup, dem Erfinder von C++, der Artikel über MISRA-C++ von Peter Sommerlad und Basiswissen für den Entwickleralltag.
Das führt auch dazu, dass für sicherheitskritische Systeme oft eigentlich überholte Technologien genutzt werden, obwohl das im Widerspruch zum von den Normen ebenfalls geforderten Aktualitätsgrad der Technologien steht. Letztlich geht es darum, bewusst abzuwägen, welche Kombination von Technologien in einem sicherheitsrelevanten System sinnvoll ist, und diese dann auch ordentlich einzusetzen.
Leider zeigen sich manche Fehler, die ein Hersteller dabei macht, oft erst, wenn das System bereits fertig ist. Im schlimmsten Fall machen sie sich erst bemerkbar, wenn das System abstürzt. Wenn sich Fehler erst nach Jahren, teilweise nach einer umfangreichen Testzeit, in echten Gefahren oder Unfällen niederschlagen, ist es teuer oder gar zu spät, diese noch zu beheben. Die Flugzeuge der Comet-Serie wurden außer Betrieb genommen und der englische Passagierjet-Pionier de Havilland vom amerikanischen Unternehmen Boeing überholt. Umso wichtiger ist es, aus Fehlern zu lernen und das Lernergebnis in zukünftige Sicherheitsnormen und -praktiken einfließen zu lassen. Je früher das passiert, desto besser. Aber auch solche Verfahren zur kontinuierlichen Verbesserung und Weiterbildung werden von den entsprechenden Sicherheitsnormen gefordert.
Sichere Autosoftware
Im Bereich der Kraftfahrzeugtechnik spezialisiert die Norm ISO 26262 den Bereich der durch EN 61508 vorgegebenen Maßnahmen. Da sich die eingesetzten Technologien, wie die der sogenannten Steuergeräte (ECU – Embedded Control Unit), aber auch der darauf laufenden Software, ständig weiterentwickeln, wird auch in dieser Norm vorwiegend auf den Ablauf eines Entwicklungsvorhabens geschaut, ohne in technologische Details zu gehen. Da nicht jeder Teil einer in einem Fahrzeug eingesetzten Software gleich relevant für die funktionale Sicherheit des Gesamtsystems ist, definieren die Normen wie ISO 26262 sogenannte Sicherheitsstufen. Diese Automotive Safety Integrity Levels reichen von ASIL-D (hochkritisches System) bis ASIL-A (wenig kritisches System), für unkritische Systeme in Fahrzeugen ergänzt durch das Level QM (Quality Management).
Allgemein gilt für die jeweiligen Sicherheitsstufen, dass die Anforderungen an die Maßnahmen, das Risiko zu reduzieren, umso höher sind, je wahrscheinlicher und gefährlicher ein Fehlverhalten des Systems ist. Damit wird versucht, das Gesamtrisiko für die Gefährdung von Personen auf ein erträgliches Maß zu senken.
Videos by heise
Heute baut ein Großteil der Innovationen im Fahrzeugbereich auf Software auf. Diese läuft in der Regel auf entsprechenden Steuergeräten, die miteinander vernetzt sind. Da ECUs zum Teil Fahrzeugfunktionen steuern – wie Lenkung oder Bremsen – die für die Sicherheit der Insassen und der anderen Verkehrsteilnehmer relevant sind, muss sich auch die Softwareentwicklung dafür entsprechenden Risikobewertungen und -überprüfungen unterwerfen.
Aus diesem Grund hat das MISRA-Konsortium (Motor Industry Software Reliability Association) ab 1998 Programmierrichtlinien für die Sprache C bereitgestellt, mit der aktuellen Version MISRA-C:2012. 2008 wurden mit MISRA-C++:2008 auch entsprechende darauf aufbauende Richtlinien für C++ veröffentlicht. Seither hat sich die C++-Norm allerdings deutlich weiterentwickelt (C++11, C++14, C++17, C++20), sodass viele der bisherigen Regeln veraltet wirken und die neueren, eindeutig besseren Sprachmittel nicht abgedeckt sind.
Modernere komplexe Systeme im Automobilbereich lassen sich mit der dort dominanten Programmiersprache C kaum noch beherrschen, weil C vergleichbar gute Abstraktionsmöglichkeiten fehlen – wie C++ sie beispielsweise bietet. Das hat das AUTOSAR- Konsortium (AUTomotive Open System ARchitecture – Entwicklungspartnerschaft im Automobilbereich) bewogen, auf C++ für die neue "AUTOSAR Adaptive"-Plattform zu setzen. Sie wird mit dem Ziel entwickelt, umfangreichere Fahrerassistenzsysteme bis hin zum selbstfahrenden Fahrzeug zu unterstützen.
MISRA-C++:2020
Weil MISRA-C++:2008 modernere C++-Mechanismen nicht unterstützte, begann eine AUTOSAR-Arbeitsgruppe die MISRA-C++-Regeln auf den C++14-Sprachstandard hin zu aktualisieren und zu ergänzen. Einen Teil der Regeln hatte die Arbeitsgruppe unverändert übernommen, einen anderen modernisiert beziehungsweise ersetzt und weitere neue Regeln hinzugefügt. Andere C++-Programmierrichtlinien, wie die C++ Core Guidelines, High Integrity C++ und der "C++ Coding Standard" des SEI CERT, dienten als Ausgangsbasis.
Jetzt schließt sich der Kreis, indem die MISRA-C++-Arbeitsgruppe auf Basis der AUTOSAR-C++-Regeln aktuelle auf den C++17 Sprachstandard abzielende Richtlinien entwirft, die bis Ende 2020 erscheinen sollen. Dabei streicht die Arbeitsgruppe einige der MISRA-C++:2008-Regeln, überarbeitet andere wenn nötig und fügt neue Regeln hinzu. Das Ergebnis lässt sich auf etwa 300 Regeln in MISRA-C++:2020 schätzen. Die Arbeitsgruppe für die MISRA-C++-Regeln setzt sich aktuell aus Experten für Safety-critical Software, Softwareexperten aus der Automobilbranche, Mitarbeitern von Herstellern statischer Analysewerkzeuge sowie Experten des ISO-C++-Normierungskomitees zusammen.
In der Vor-COVID-Zeit traf man sich sechsmal im Jahr für zwei Tage, um an den Regeln zu arbeiten. Zwischendurch gab es zum Teil kürzere Videokonferenzen. Jetzt treffen sich die Experten nur noch online, aber öfter, um die Regeln bis Ende 2020 zu veröffentlichen. Zum Zeitpunkt des Entstehens dieses Artikels finden wöchentliche Videokonferenzen statt. Daneben gibt es noch eine Unterarbeitsgruppe, die sich mit möglichen Safety-Regeln für hochparallele Systeme in C++ (z. B. GPUs) beschäftigt. Diese erweiterten Regeln fließen noch nicht in die nächste MISRA-C++-Version ein, sind aber in Software für autonomes Fahren wichtig.
Die Zielgruppe der Richtlinien sind nicht C++-Experten, sondern durchschnittlich begabte C++-Entwickler. Das hat zum Beispiel bei MISRA-C++:2008 den Eindruck bei C++-Cracks erweckt, dass die Regeln kein gutes und modernes C++ fördern, weil modernes C++ von den Regeln zum Teil ignoriert oder nicht direkt unterstützt wurde. Da der komplette Regeltext für eine geringe Gebühr (ca. 20 Euro) lizenziert werden muss, förderte die fehlende freie Zugänglichkeit zu den jeweiligen Begründungen die Mythenbildung zu MISRA-C++. Das sollte sich mit dem neuen Regelwerk MISRA-C++ ändern, da an diesem Experten mitwirken, denen wichtig ist, dass modernes und gutes C++ gefördert wird. Das war unter anderem der Grund, warum der Autor dort pro bono mitwirkt.
Wenn man heute schon nach MISRA-C++ entwickeln soll, ist es sinnvoll, sich über die kompletten Regeln zu informieren und den Text des Regelwerkes zu lizenzieren, um bei Fehlermeldungen der Prüfwerkzeuge die zugehörige Begründung für eine Regel nachvollziehen zu können. Dies hilft auch bei der Entscheidung, eine Meldung aus der statischen Codeanalyse gegebenenfalls bewusst zu ignorieren.
Sicher programmieren mit zielführenden Regeln
Ein globales Ziel ist einfache und verständliche Software, wie dies auch von den Safety-Normen gefordert wird. Sicherheitskritische Software muss sich immer auch von Menschen untersuchen lassen, speziell wenn unerwünschtes Verhalten beobachtet wird. Programmcode, der aufgrund seiner Kompliziertheit nicht durchschaubar ist, lässt sich nur schwer einem entsprechenden Sicherheitsreview unterziehen. Einfacher Code ist aber auch in der Entwicklung besser beherrschbar. Er ist elegant und drückt sich klar aus, das heißt aber nicht, dass nur primitive Sprachmittel zur Verfügung stehen. Letztere führen oft eher zu unnötiger Kompliziertheit. Zum Beispiel sind für Anfänger globale Variablen oft einfacher zu verstehen als die vielfältigen Parameterübergabemechanismen in C++, sie führen aber rasch zu unbeherrschbarer Komplexität wie im Fall der unerwarteten Beschleunigung bei Toyota-Fahrzeugen, die durch überkomplizierte Software verursacht wurde.
Leider ist C++ eine umfangreiche und zum Teil komplizierte Programmiersprache. Vor allem die Ähnlichkeit zu C und die trotzdem vorhandenen Unterschiede führen zu Missverständnissen von Programmierern im Programmcode. C++ bietet ein wesentlich besseres Typsystem, das aber aus Kompatibilitätsgründen bewusst Schwachstellen des Typsystems von C umfasst, beispielsweise die automatische Promotion "kleinerer" Ganzzahltypen, bei denen auch vorzeichenlose Typen wie (uint16_t) zu vorzeichenbehafteten Typen (int – heute oft 32 Bit) umgewandelt werden. Letzteres birgt die Gefahr von Undefined Behavior bei Überlauf, zum Beispiel bei der Multiplikation zweier Variablen vom Typ uint16_t, die als signed int-Multiplikation erfolgt. Der folgenden Kasten zeigt die Regel "Kontrollausdrücke dürfen nicht invariant sein", die vom Autor übersetzt wurde.
Kategorie: verlangt (Required)
Analyse: unentscheidbar (Undecidable), System
Vertiefung (Amplification)
Diese Regel gilt bei:
- Kontrollausdrücken von
if,while,for,do ... whileundswitch-Anweisungen und - dem ersten Operanden des
?:-ternären Operators.
Sie gilt nicht bei Kontrollausdrücken:
- von
if constexpr-Anweisungen, - in nicht instanziierten Templates,
- innerhalb eines instanziierten Templates, wenn der Ausdruck von einem Templateparameter abhängt.
Begründung (Rationale)
Ein invarianter Wert eines Kontrollausdrucks ist möglicherweise ein Programmierfehler. Er führt dazu, dass unerreichbarer Code existiert, den der Compiler möglicherweise entfernt. Das kann zum Beispiel dazu führen, dass defensiver Programmcode, der eigentlich Fehler erkennen soll, aus dem ausführbaren Programm entfernt ist.
Ausnahmen (Exception)
- Der Ausdruck
truekann für Endlosschleifen genutzt werden. - Eine
do-while-Schleife darf den Kontrollausdruck false haben.
Beispiele – Auszug
Anmerkung: s8a steht für eine Variable vom Typ int8_t, u16a für eine Variable vom Typ uint16_t.
s8a = ( u16a < 0u ) ? 0 : 1; /* Non-compliant - u16a always >= 0 */
if ( 2 > 3 )
{
/* Non-compliant - always false */
}
Jede MISRA-Regel ist einer der Kategorien "obligatorisch" (Mandatory), "verlangt" (Required) oder "empfohlen" (Ad visory) zugeordnet. Außerdem liefern die Regeln Informationen darüber, ob sie durch Werkzeuge überprüfbar sind (Decidable), ob sich die Prüfung anhand einer Übersetzungseinheit (Single Translation Unit), also einer C++-Quelldatei, entscheiden lässt oder ob das Gesamtprogramm (System) zu analysieren ist. Es gibt Regeln, die aber nicht im Allgemeinen entscheidbar sind, wie das obige Beispiel. In solchen Fällen kann ein Prüfwerkzeug zwar offensichtliche Verletzungen anzeigen, aber die Abwesenheit der Meldungen solcher nicht entscheidbaren Regeln heißt nicht automatisch, dass sie nicht doch verletzt sind. An dieser Stelle sind ein menschliches Review sowie entsprechende Tests notwendig.
Innerhalb der Regel kann die sogenannte Amplification genauer spezifizieren, was mit der Regelüberschrift gemeint ist. Die "Rationale" erklärt die Situation, warum die Regel existiert, und mit "Exception" werden Ausnahmen angegeben, bei denen die Regel nicht angewendet werden soll.
Überraschende Regeln
Regeln blind einzuhalten, weil zum Beispiel ein Regelprüfwerkzeug eine Verletzung einer Regel anzeigt, ist trotzdem selten eine gute Idee. Manchmal verhindern Regeln die Ausgangssituation einer anderen Regel. Diese erscheint daher unnötig. Solche "sinnlosen" Regeln dienen dazu, die Situation zu entschärfen, die beim bewussten Verletzen der anderen Regel entsteht. Ein bewusstes Ausschalten der Prüfung einer verlangten Regel (Deviation) kann im Kontext eines Projekts durchaus sinnvoll sein. Regeln der Kategorie "Mandatory" sind unbedingt einzuhalten. Regeln mit Empfehlungscharakter (Advisory) lassen sich mit dokumentierter Begründung für ein Projekt generell ignorieren.
Beispielsweise dürfen eigentlich verbotene rekursive Funktionen trotzdem vorkommen, wenn im Projektkontext nachgewiesen wird, dass die Rekursion nicht zum Überlauf des Aufrufstacks führt. Eine rekursiv formulierte binäre Suche könnte zum Beispiel dadurch begrenzt sein, dass die zugehörige Datenstruktur eine fixe Größe hat, deren Zweierlogarithmus deutlich kleiner ist als der verfügbare Stackbereich. Hierzu die Regel im folgenden Kasten als Beispiel. Eine solche Abweichung von einer Regel muss aber nicht nur bewusst erfolgen, sondern auch adäquat dokumentiert werden (Deviation Procedure). Das kann man im gebührenfrei verfügbaren Dokument zur MISRA-Compliance nachlesen.
Kategorie: verlangt
Analyse: unentscheidbar, System
Begründung
Rekursion birgt das Risiko, den verfügbaren Platz auf dem Laufzeitstack zu überschreiten. Das kann zu ernsthaftem Fehlverhalten führen. Wenn Rekursion nicht eng kontrolliert ist, ist es nicht möglich, vor der Ausführung festzustellen, wie viel Platz für den Laufzeitstack notwendig ist.
Anmerkung des Autors: Jede Abweichung (Deviation), die eine Verletzung dieser Regel begründet, muss erklären, wie der Laufzeitstack begrenzt wird.
Ausnahme
Eine constexpr-Funktion, die nur innerhalb einer Core Constant Expression aufgerufen wird, darf rekursiv sein. (Anmerkung: Das bedeutet, die Funktion wird vom Compiler ausgeführt und nicht zur Laufzeit des Programms.)
Beispiele – Auszug
int32_t fn ( int32_t x )
{
if ( x > 0 )
{
x = x * fn ( x – 1 ); // Non-compliant
}
return x;
}
constexpr int32_t fn_4 ( int32_t x )
{
if ( x > 0 )
{
x = x * fn_4 ( x – 1 ); // Compliant by exception
}
return x;
}
constexpr int32_t n = fn_4 ( 6 ); // Core constant expression
Die MISRA-Regeln geben zwar oft konkrete Hinweise auf die Verwendung von Sprachmechanismen, aber diese allein sind nicht ausreichend für ein sicherheitskritisches Softwaresystem. Deswegen verzichtet MISRA generell darauf, bestimmte stilistische Elemente zu fordern. Jedes entsprechende Projekt definiert aus diesem Grund weitere Programmierrichtlinien, um einen konsistenten Programmcodestil zu erreichen. AUTOSAR hat beispielsweise die Regel A7-1-7, die ein bestimmtes Codelayout fordert. Dieses Layout untersagt, mehrere Deklarationen oder Anweisungen pro Codezeile zu nutzen. Diese Regel wird wie weitere ähnliche C++-Regeln in AUTOSAR nicht in das neue MISRA-C++-Regelwerk übernommen.
Der nächste Kasten zeigt ein weiteres Beispiel für eine neue Regel im MISRA-C++ an. Zum Zeitpunkt des Entstehens des Artikels, ist diese noch nicht endgültig abgestimmt, aber sie zeigt, wie neuere Spracheigenschaften berücksichtigt werden.
Kategorie: verlangt
Analyse: entscheidbar, Single Translation Unit
Version: ab C++11
Vertiefung
Diese Regel bezieht sich auf Member-Funktionen, die bei ihrer Anwendung auf ein temporäres Objekt Zeiger oder Referenzen auf Dinge aus der folgenden Liste zurückgeben:
*this,- Daten-Member von
*this, - Basisklassen-Subobjekte von
*thisoder - andere Daten, die
*thisverwaltet und die zusammen mit*thisgelöscht werden.
Versieht man solche Member-Funktionen mit einer Referenzqualifizierung (lvalue-ref-qualifier), verhindert das, dass sie auf temporären Objekten aufgerufen werden.
Begründung
Member-Funktionen ohne Referenzqualifikation kann man auf temporären Objekten aufrufen (Anmerkung: aus historischen Kompatibilitätsgründen auch die Nicht-const-Member-Funktionen). Wenn eine solche Funktion eine Referenz oder einen Zeiger auf die "Innereien" des Objekts zurückgibt, führt die Verwendung dieses Rückgabewerts, nachdem das Objekt zerstört wurde, zu undefiniertem Verhalten.
Ausnahmen
Die Nutzung der zurückgegebenen Referenz innerhalb desselben Ausdrucks, also bevor das temporäre Objekt gelöscht wird, ist erlaubt.
Beispiele
Das folgende Beispiel zeigt, dass der vom Compiler automatisch definierte Zuweisungsoperator diese Regel verletzt. Der Operator hat keine Referenzqualifikation, liefert aber eine Referenz auf das *this-Objekt. Benutzt man die Referenz dangle nach ihrer Initialisierung, verweist sie auf ein bereits gelöschtes Objekt.
struct X{};
void f() {
X& dangle = (X{} = X{}); // Non-compliant
}
Der folgende Code zeigt die Ausnahme. Obwohl der Output-Operator (operator<<) auch eine Referenz auf *this zurückgibt, erfolgt die Nutzung innerhalb eines Ausdrucks und das temporäre Objekt überlebt lange genug.
void log(std::ostream &out){
std::osyncstream{out} << "write log message atomically" << std::endl;
}
Speziell gefährdet ist das Range-for-Statement, wenn der "Range" eine Referenz auf ein temporäres Objekt ist.
void g(){
extern std::vector<std::string> make();
for (char c : make().front()) { // Non-compliant
// ...
}
}
Vor allem dieses Beispiel zeigt, wie die Nutzung der Member-Funktion front() auf dem von make() gelieferten Vektor dazu führt, dass die Schleife versucht, über einen bereits gelöschten String zu iterieren. Intern wird das Range-for-Statement wie folgt umgesetzt:
{ auto&& __range = make().front();
...
}Die Referenz __range würde die Lebensdauer eines temporären Objekts auf der rechten Seite der Zuweisung verlängern. Das gelingt aber nicht, wenn dort als Ergebnis kein Wert, sondern eine Referenz herauskommt. Glücklicherweise geben moderne C++-Compiler (Clang) dafür eine entsprechende Warnung aus (-Wdangling-gsl), sodass man solche Fehler auch ohne teure statische Analysewerkzeuge vermeiden kann. Voraussetzung ist, alle entsprechenden Compilerwarnungen anzuschalten. Mindestens sollte also der Compileraufruf die Warnstufe -Wall -Werror enthalten, am besten zusätzlich -Wextra -pedantic, um sicherzugehen – andere Compiler als Clang und GCC bieten vergleichbare Optionen.
Falls einige der Extrawarnungen zu viele unbedenkliche korrekte Codestellen als Fehler melden, ist es besser, diese Warnungen separat und sichtbar im Build-System abzuschalten und ähnlich wie bei einer "Deviation" von den MISRA-Regeln mit einer Begründung zu dokumentieren. Das gilt auch für nicht sicherheitsrelevanten Code.
Implementierunabhängiges Verhalten
Neben offensichtlichen Programmierfehlern adressiert MISRA C++ auch sogenanntes implementierungsabhängiges Verhalten (Implementation-defined Behavior). Das sind Konstrukte einer Programmiersprache, die aus Gründen der Effizienz nicht einheitlich auf allen Plattformen realisiert sind. Leider gilt das auch für die elementaren Ganzzahldatentypen int, long, short, char sowie deren entsprechende unsigned-Varianten. Heute ist es auf gewöhnlichen 64-Bit-Prozessoren üblich, dass int 32 Bit beansprucht, long ebenso und long long 64 Bit (LLP64).
Es gab Zeiten, als int nur 16 Bit für seinen Wertebereich zur Verfügung hatte, wie es heute auf kleineren Mikrocontrollern noch üblich ist. Zum Teil sind es auch Compileroptionen oder die Plattform, die die Anzahl der Bits der vordefinierten Ganzzahldatentypen und Zeiger festlegen. Damit ist es enorm schwierig, sicherzustellen, dass sich Programmcode auf verschiedenen Systemen wie der Entwickler-Workstation und dem Mikrocontroller in der ECU identisch verhält.
Einen Schritt geht MISRA-C++ in die entsprechende Richtung, indem eine Empfehlung (Advisory) vorschlägt, generell auf die eingebauten Datentypen zu verzichten und nur die im Standardheader <cstdint> definierten Ganzzahltypen mit fixer Breite, wie uint16_t, zu nutzen. Da Ganzzahlkonstanten aber ohne spezielle Markierung den Typ int bekommen, müsste man diese zuerst in den passenden kürzeren Typ per static_cast konvertieren.
Hier bietet sich an, dazu "User-defined Literal"-Operatoren (UDL) zu definieren, damit man analog zu 0xffULL für Hexadezimalkonstanten vom Typ unsigned long long auch die Typen aus <cstdint> als Konstantentypen nutzen kann – etwa 0xff_u8 für uint8_t oder 12345_i16 für int16_t. Wenn man hierbei noch zur Compilezeit prüfen möchte, ob die Konstante auch wirklich im Wertebereich für den Typ liegt, muss man entweder auf das C++20-Schlüsselwort consteval warten oder die Konvertierung der Ziffernzeichen als Template-UDL-Operator implementieren. Der Code dazu findet sich im Repository UDL4stdint des Autors auf GitHub.
Im folgenden Beispiel zu consteval kommt ein throw-Ausdruck zum Einsatz, der zu einem Compilefehler führt, wenn die Konstante nicht in den Zieltyp passt:
consteval uint8_t operator""_u8(unsigned long long val) {
if (val <= std::numeric_limits<uint8_t>::max())
return val;
else
throw "value is out of range of uint8_t"; // raise compile time error
}
Konstanten mit den von MISRA-C++ empfohlenen Typen zu definieren, ist nur ein erster Schritt, denn die "kürzeren" Varianten werden wegen der Ganzzahl-Promotion für Berechnungen zuerst nach int konvertiert. Durch den dann möglichen Überlauf mit Undefined Behavior fordert sicherer Code besondere Sorgfalt.
Sicherlich ist es besser, gar nicht erst die eingebauten Datentypen für Domänenwerte zu nutzen, sondern konsequent eigene Datentypen (keine Typaliase) für die vorkommenden Größen zu definieren (Strong Typing). Neben der Reduktion von Parameterverwechselungen, die durch die eingebauten automatischen Konvertierungen "erleichtert" werden, bietet sich die Möglichkeit, die entsprechenden erlaubten Rechenoperationen auf die sinnvollen einzuschränken. Es ergibt beispielsweise wenig Sinn, im Fahrzeug die gefahrene Distanz mit dem Verbrauch in Litern zu multiplizieren. Eine Division kann jedoch den Verbrauch pro Distanz oder die Reichweite pro Volumeneinheit berechnen. C++ bietet die Möglichkeit, das ohne zusätzlichen Laufzeit- und Speicherbedarf umzusetzen, wie der Codeausschnitt in Listing zeigt. Das zugehörige Framework PSsst (Peter’s simple strong typing) kann man auf GitHub nachvollziehen.
struct literGas : strong<double,literGas>
, ops<literGas,Additive,Order,Out>{
constexpr static inline auto suffix=" l";
};
struct kmDriven : strong<double,kmDriven>
, ScalarMultImpl<kmDriven,double>,Out<kmDriven> {
constexpr static inline auto prefix="driven ";
constexpr static inline auto suffix=" km";
};
struct literPer100km : strong<double,literPer100km>
, ops<literPer100km,Eq,Out>{
constexpr static inline auto suffix=" l/100km";
};
struct kmpl : strong<double,kmpl>, ops<kmpl,Eq,Out>{
constexpr static inline auto suffix=" km/l";
};
constexpr
literPer100km operator/(literGas l, kmDriven km){
return {l.value/(km/100.0).value};
}
constexpr
kmpl operator/(kmDriven km, literGas l){
return {km.value/l.value};
}
// kein Overhead!
static_assert(sizeof(double)==sizeof(kmDriven));
namespace myliterals {
constexpr literGas operator"" _l(long double value){
return literGas{static_cast<literGas::value_type>(value)};
}
constexpr literGas operator"" _l(unsigned long long value){
return literGas{static_cast<literGas::value_type>(value)};
}
constexpr kmDriven operator"" _km(long double value){
return kmDriven{static_cast<kmDriven::value_type>(value)};
}
constexpr kmDriven operator"" _km(unsigned long long value){
return kmDriven{static_cast<kmDriven::value_type>(value)};
}
}
literPer100km consumption(literGas l, kmDriven km) {
return l/km;
}
kmpl efficiency(literGas l, kmDriven km) {
return km/l;
}
void testConsumptionVSEfficiency(){
using namespace myliterals;
auto const l = 40_l;
auto const km = 500_km;
ASSERT_EQUAL(100/(l/km).value, (km/l).value);
}Regelwerkzeuge helfen beim Einhalten der Regeln
Nachdem die MISRA-C++-Regeln und ihre Historie bekannt und weitere Mechanismen zur lesbareren und typsichereren C++-Programmierung erläutert sind, stellt sich nun die Frage, wie sich die entsprechenden Regeln einhalten lassen. Ein Mensch kann sicherlich nicht allen Code in einem Projekt visuell überprüfen und auch nicht alle Regeln beim Programmieren konsequent einhalten. Aus diesem Grund gibt es entsprechende Prüfwerkzeuge, die im Idealfall auch noch eine Regelverletzung korrigieren oder zumindest eine Korrektur vorschlagen. Das erste Werkzeug ist sicherlich der Compiler, der Code, der die Typr egeln der Sprache verletzt, gar nicht erst kompiliert. Hier ist es sinnvoll, die vorgeschlagenen Warnungen mit der Option -Werror auch als Fehler zu definieren, damit sich kein Schlendrian einschleicht. Unsauberer Code kompiliert dann nicht.
In der Regel werden nur einfachere Prüfungen als Compilerwarnungen unterstützt, weil Compiler möglichst schnell Code übersetzen sollen. Gute Geschwindigkeit beim Kompilieren hilft auch, rasch kleine Änderungen mit den Unit-Tests zu überprüfen. Schnelles Feedback wie durch solche Tests ist essenziell für das menschliche Lernen. Lange Feedbackzyklen lassen intuitives Lernen durch eigene Fehler nicht zu. Spätes Feedback kann das menschliche Gehirn nicht mehr direkt der Ursache zuordnen. Das ist zum Beispiel der Grund, warum Menschen vorsichtig sind, um Verletzungen zu vermeiden, sich aber den Körper ruinieren mit Dingen, die erst durch Langzeiteffekte wirken.
Ein solch relativ rasches Feedback ist aber auch nötig, wenn man die notwendigen statischen Analysewerkzeuge nutzt, die umfangreichere Prüfungen als ein Compiler bieten. Projekte kamen schon in Schwierigkeiten, weil sie die Prüfwerkzeuge erst nach der Entwicklung ernst genommen haben, um dann die (große Menge an) Meldungen zu bearbeiten. Das Ignorieren der Warnungen der Prüfwerkzeuge und des Compilers für längere Zeit kann dazu führen, dass man grundlegende Designentscheidungen mit den entsprechenden Konsequenzen und Aufwänden noch mal ändern muss. Idealerweise bekommen Entwickler schon beim Schreiben von Code problematische Stellen angezeigt – wie bei der Rechtschreibprüfung in einer Textverarbeitung – und können diese sofort und im Idealfall gleich automatisch korrigieren. Diesen Ansatz bietet die kostenlose Open-Source-C++-Entwicklungsumgebung Cevelop, an der der Autor mitgearbeitet hat.
Open-Source-C++-Entwicklungsumgebung Cevelop

Während des Codierens läuft im Hintergrund eine eingebaute (beschränkte) statische Analyse des Quellcodes und der Editor zeigt eventuelle Problemstellen direkt an (s. Abb. 1). Zusätzlich lassen sich per Menü oder Knopfdruck Korrekturvorschläge anzeigen und anwenden (s. Abb. 2).

Cevelop nutzt diesen Mechanismus, um die konsistente Nutzung von const vorzuschlagen (Constificator Plug-in) oder auch um die von MISRA-C++ geforderten Ganzzahldatentypen mit fester Breite automatisch einzusetzen (s. Abb. 3) (Intwidthfixator) beziehungsweise dies auch wieder rückgängig zu machen.

Außerdem existiert ein Beta-Plug-in, das einige Regeln der C++ Core Guidelines sowie AUTOSAR und MISRA-C++:2003- Regeln prüft und automatische Korrekturen vorschlägt. Die Abbildungen 4 bis 8 zeigen einige Beispiele für AUTOSAR-Regelverletzungen (rotes A).


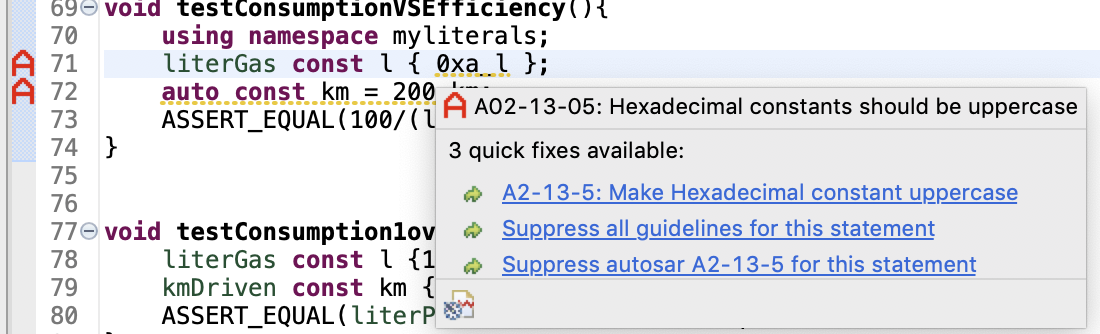

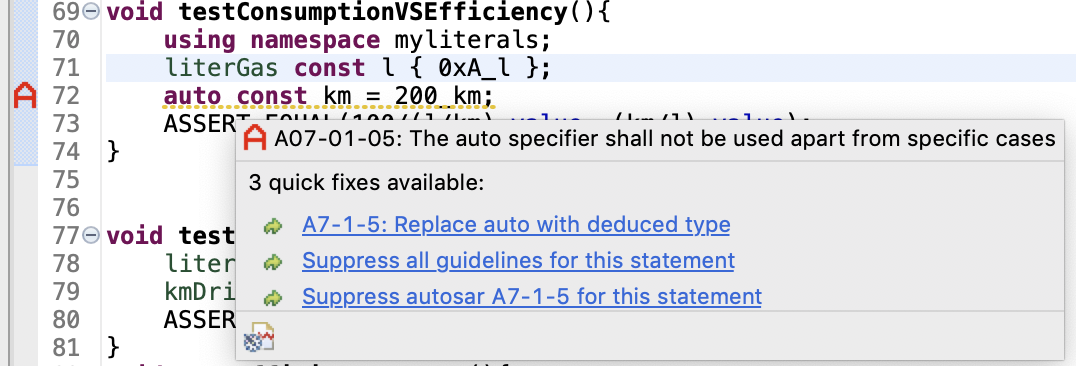
Fazit
Die interaktive Prüfung beim Entwickeln reicht aber für eine vollständige Konformitätsprüfung durch statische Analyse nicht aus. Hier ist der Einsatz eines oder mehrerer Prüfwerkzeuge notwendig, die den gesamten Quellcode eines Projekts entsprechend den Regeln analysieren. MISRA-C++:2020 wird für eventuelle lokale Abweichungen von einer Regel eine einheitliche Syntax auf Basis von C++-Attributen einführen. Damit wird im Gegensatz zu bisher – heute bietet jedes Werkzeug einen eigenen (Kommentar-)Mechanismus an, um Regeln an bestimmten Code stellen abzuschalten – die Nutzung mehrerer statischer Analysewerkzeuge, die unterschiedliche Stärken haben, für die MISRA-C++- Regeln praktikabel.
Prüfwerkzeuge wie auch das frei verfügbare Tool clang-tidy sowie Compilerwarnungen und IDE-Feedback sind auch dann eine gute Hilfe zum Vermeiden von Flüchtigkeitsfehlern, wenn man keinen sicherheitskritischen Code schreiben muss. Eingeübte, aber ungünstige Praktiken lassen sich auf diese Weise eliminieren.
Zusätzlich gehört zu sicherer Softwareentwicklung auch noch sonstiges gutes Softwareengineering, wie Testautomatisierung (z. B. mit Unit Testing), automatische Builds und Versionsmanagement. Leider braucht man für all diese Werkzeuge und Praktiken entsprechende Einarbeitungszeit und Übung. Aber es lohnt sich auf jeden Fall. Es gibt also keine Entschuldigung, unsicheren oder schlechten C++-Code zu schreiben. Entwickler sollten dabei auf Einfachheit achten und keine barocke Kompliziertheit einzubauen, denn "Weniger Code == Mehr Software" (Kevlin Henney und Peter Sommerlad).
Peter Sommerlad
war bis Anfang 2020 Professor für Informatik und leitete das IFS Institut für Software an der HSR Hochschule für Technik Rapperswil. Heute ist er freiberuflicher Berater, Coach und Trainer für C++ und Softwareengineering. Er ist Mitglied in den ISO-Arbeitsgruppen WG21 (C++) und WG23 (Vulnerabilities) und beteiligt sich aktiv an der Gestaltung von MISRA-C++. Außerdem hat er die C++-Arbeitsgruppe von AUTOSAR beraten.
(mdo)
