Missing Link: Stephen Wolfram über die Rolle der KI in der Forschung (Teil 2)
Stephen Wolfram – Erfinder des Computeralgebrasystems "Mathematica" – gibt einen Einblick in die Grenzen und Potenziale von KI in der Wissenschaft.
Dieser Beitrag wurde uns mit freundlicher Genehmigung von Stephen Wolfram zur Verfügung gestellt: Stephen Wolfram (2024), "Can AI Solve Science? [1]", Stephen Wolfram Writings.
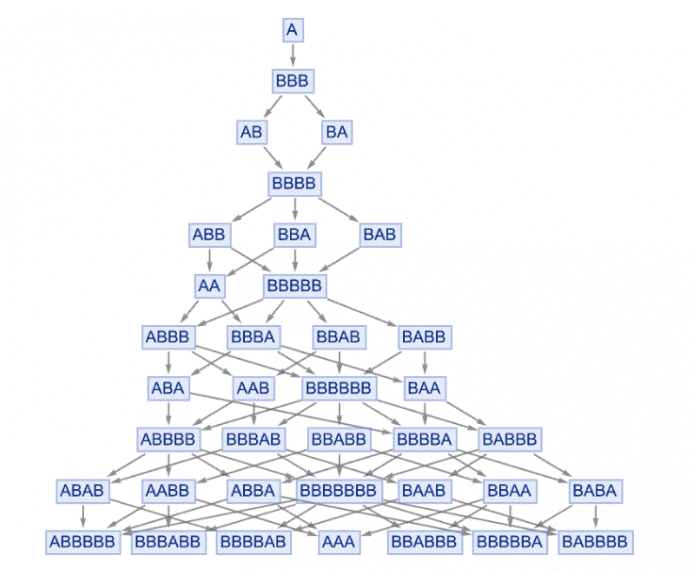
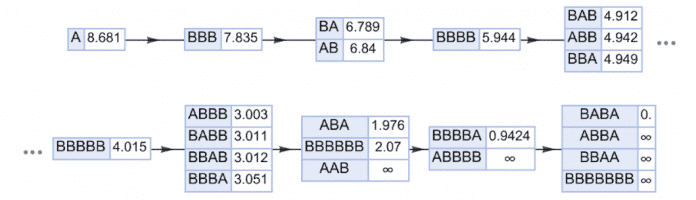
Im ersten Teil des Beitrags [2] ging es hauptsächlich um die Frage, ob Künstliche Intelligenz [3] helfen kann, bestimmte Berechnungsprozesse zu "überspringen" und abzukürzen. Es gibt jedoch auch viele Situationen, in denen es stattdessen darum geht, einen Prozess zu beschleunigen, den man als multikomputationalen Prozess (zur Erklärung siehe den unten stehenden Kasten) bezeichnen könnte, bei dem es in jedem Schritt viele mögliche Ergebnisse gibt und das Ziel beispielsweise darin besteht, einen Weg zu einem bestimmten Endergebnis zu finden. Als einfaches Beispiel für einen multikomputationalen Prozess kann ein Mehrwegsystem betrachtet werden, das auf Zeichenketten operiert, wobei in jedem Schritt die Regeln {A BBB, BB A} auf alle möglichen Arten angewendet werden:

(Bild: Stephen Wolfram)
Was ist nun der kürzeste Pfad von A nach BABA? In dem hier gezeigten Fall lässt sich die Antwort leicht berechnen, beispielsweise indem explizit ein Pfadsuchalgorithmus auf dem Graphen ausgeführt wird:
{A, BBB, AB, BBBB, ABB, AA, ABBB, ABA, BBBBA, BABA]
Es gibt viele Arten von Problemen, die diesem allgemeinen Muster folgen. Viele Herausforderungen folgen einem universellen Schema:
- eine siegreiche Zugfolge innerhalb eines Spielgraphen ermitteln
- ein Rätsel als Sequenz von Zügen anhand eines Möglichkeitsgraphen lösen
- einen Beweis für ein Theorem basierend auf definierten Axiomen entdecken
- einen chemischen Syntheseweg anhand grundlegender Reaktionen identifizieren
Im Kern geht es um das Durchdringen von NP-Problemen [4], bei denen sich eine Vielzahl "nichtdeterministischer" Berechnungspfaden offenbart.

Im sehr einfachen oben genannten Beispiel ist es uns ohne Weiteres möglich, einen gesamten Mehrweggraphen explizit zu erzeugen. In den meisten praktischen Beispielen wäre der Graph jedoch astronomisch groß.
Die Herausforderung besteht daher typischerweise darin herauszufinden, welche Züge gemacht werden sollen, ohne den gesamten Graphen der Möglichkeiten nachzuzeichnen. Ein gängiger Ansatz ist der Versuch, den verschiedenen möglichen Zuständen oder Ergebnissen eine Bewertung zuzuweisen und nur die Pfade mit etwa den höchsten Bewertungen zu verfolgen.
Bei automatisierten Beweisen von Theoremen ist es auch üblich, "von den Anfangspropositionen abwärts" und "von den endgültigen Theoremen aufwärts" zu arbeiten, um zu versuchen, den Treffpunkt der Pfade in der Mitte zu finden. Zudem gibt es eine weitere wichtige Idee: Hat man erst einmal das Lemma etabliert, dass es einen Weg von X nach Y gibt, kann man X Y als eine neue Regel in die Sammlung der Regeln aufnehmen.

Wie könnte KI helfen? Als ersten Ansatz könnte man in Betracht ziehen, etwas Ähnliches wie das oben beschriebene Mehrwegsystem für Zeichenketten zu nehmen und eine KI, die einem Sprachmodell entspricht, darauf zu trainieren, Sequenzen von Token zu generieren, die Pfade (oder was in einem mathematischen Kontext Beweise wären) darstellen. Die Idee besteht darin, die KI mit einer Sammlung gültiger Sequenzen zu füttern, ihr dann den Anfang und das Ende einer neuen Sequenz zu präsentieren und sie zu bitten, die Mitte auszufüllen.
Hierfür habe ich ein ziemlich einfaches Transformer-Netzwerk verwendet:

(Bild: Stephen Wolfram)
Dann trainiert man es, indem man viele Sequenzen von Token übergibt, die gültigen Pfaden entsprechen (wobei E das „End-Token“ darstellt).
A,BABA:BBB,AB,BBBB,ABB,AA,ABBB,ABA,BBBBAE
zusammen mit "negativen Beispielen", die das Fehlen von Pfaden anzeigen:
BABA,A:N
Das trainierte Netzwerk erhält einen Prompt mit einem Präfix, ähnlich jenen aus den Trainingsdaten. Anschließend erfolgt die iterative Ausführung „im Stil eines Sprachmodells“ (effektiv bei einer Temperatur von Null, das heißt, stets wird der „wahrscheinlichste“ nächste Token ausgewählt):
A,BABA:
A,BABA,B
A,BABA,BB
A,BABA,BBB
A,BABA,BBB,
A,BABA,BBB,A
A,BABA,BBB,AB
A,BABA,BBB,AB,
A,BABA,BBB,AB,B
⁝
A,BABA:BBB,AB,BBBB,ABB,AA,ABBB,AAB,ABBBBE
Eine Zeit lang funktioniert es perfekt – doch gegen Ende treten Fehler auf, wie durch die in Rot dargestellten Token angezeigt. Die Leistung variiert je nach Ziel – in einigen Fällen weicht es gleich zu Beginn vom Kurs ab:
A,AAA:ABBB,BBB,ABB,ABB,AA,ABBB,AAB,ABBBB,AAA,
A,BAAB:BBB,AB,BBBB,ABB,AA,ABBB,AAB,ABBBBE
A,ABBA:BBB,AB,BBBB,ABB,AA,ABBBB,AAB,ABBBBE
A,BBBBBBBBB;A,ABB,BBBB,ABB,AA,ABBB,AAB,ABBBB,AABB,ABBBBB,ABBBBBBEBBBE
A,BB:ABBB,ABEBE,ABB,ABBBE,AA,ABBB,A
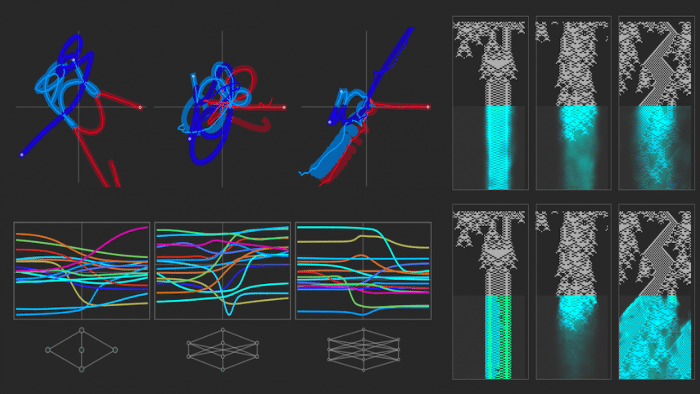
Wie lässt sich nun eine Verbesserung erzielen? Eine Möglichkeit besteht darin, bei jedem Schritt nicht nur das Token, das als am wahrscheinlichsten angesehen wird, zu behalten, sondern einen Stapel von Token – wodurch effektiv ein Mehrwegsystem generiert wird, das der LLM-Controller potenziell navigieren könnte. (Dies kann man sich etwas scherzhaft als einen "Quanten-LLM" vorstellen, der stets mehrere Pfade der Geschichte erkundet.)
(Übrigens könnte man sich auch vorstellen, mit vielen verschiedenen Regeln zu trainieren, um dann das zu tun, was im Wesentlichen einem Zero-Shot-Lernen entspricht, und einen Pre-Prompt zu geben, der angibt, welche Regel in einem bestimmten Fall verwendet werden soll.) Eines der Probleme bei diesem LLM-Ansatz ist, dass die generierten Sequenzen oft sogar "lokal falsch" sind: Das nächste Element kann laut den gegebenen Regeln nicht auf das vorherige folgen.
Dies legt jedoch einen anderen Ansatz nahe. Statt zu versuchen, die KI "sofort die gesamte Sequenz ausfüllen zu lassen", soll sie stattdessen nur auswählen, "wohin sie als Nächstes gehen soll", wobei sie stets einer der angegebenen Regeln folgt.
Ein einfaches Trainingsziel besteht dann im Wesentlichen darin, die KI die Distanzfunktion für den Graphen lernen zu lassen, oder mit anderen Worten, die KI in die Lage zu versetzen, zu schätzen, wie lang der kürzeste Pfad (falls vorhanden) von einem Knoten zum anderen ist. Mit einer solchen Funktion besteht eine typische Strategie darin, dem zu folgen, was im Wesentlichen einem Pfad des "steilsten Abstiegs" entspricht – bei jedem Schritt den Zug zu wählen, von dem die KI schätzt, dass er am besten dazu beiträgt, die Entfernung zum Ziel zu verringern.
Wie lässt sich dies tatsächlich mit neuronalen Netzen umsetzen? Ein Ansatz besteht darin, zwei Encoder zu verwenden (sagen wir, aufgebaut aus Transformern) – die effektiv zwei Einbettungen generieren, eine für Quellknoten und eine für Zielknoten. Das Netzwerk kombiniert dann diese Einbettungen und lernt eine "Metrik", die die Distanz zwischen den Knoten charakterisiert:
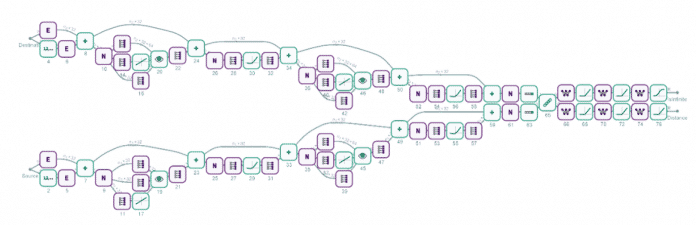
(Bild: Stephen Wolfram)
Durch das Training eines solchen Netzwerks mit dem Mehrwegsystem, das diskutiert wurde – indem ihm einige Millionen Beispiele für Quell-Ziel-Distanzen gegeben werden (zuzüglich eines Indikators, ob diese Distanz unendlich ist) –, lässt sich das Netzwerk verwenden, um einen Teil der Distanzmatrix für das Mehrwegsystem vorherzusagen. Und was sich zeigt, ist, dass diese vorhergesagte Matrix der tatsächlichen Matrix ähnlich, aber definitiv nicht identisch ist:
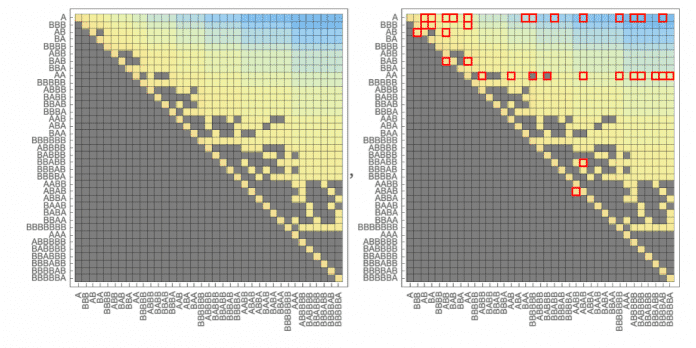
(Bild: Stephen Wolfram)
Dennoch kann man sich vorstellen, einen Pfad zu konstruieren, bei dem in jedem Schritt die vom neuronalen Netz vorhergesagten geschätzten Distanzen zum Ziel für jedes mögliche Ziel berechnet werden, um dann dasjenige auszuwählen, das "am weitesten führt“:
(Bild: Stephen Wolfram)
Jeder einzelne Zug hier ist garantiert gültig, und tatsächlich wird schließlich das Ziel BABA erreicht – allerdings in etwas mehr Schritten als der tatsächlich kürzeste Pfad. Auch wenn der optimale Pfad nicht ganz gefunden wird, hat es das neuronale Netz ermöglicht, den "Suchraum“ zumindest etwas zu beschneiden, indem Knoten priorisiert und nur die roten Kanten durchquert werden:
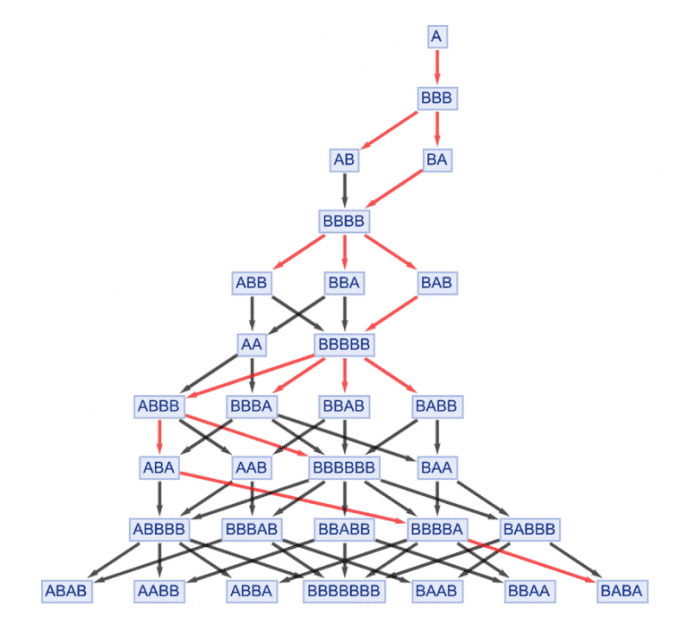
(Bild: Stephen Wolfram)
(Ein technischer Punkt ist, dass das spezielle neuronale Netz, das hier verwendet wurde, die Eigenschaft hat, dass alle Pfade zwischen einem gegebenen Paar von Knoten immer die gleiche Länge haben – wenn also ein Pfad gefunden wird, kann er als der "kürzeste" betrachtet werden. Eine Regel wie {A AAB, BBA B} hat diese Eigenschaft nicht, und ein neuronales Netz, das auf diese Regel trainiert wurde, kann Pfade finden, die das richtige Ziel erreichen, aber nicht so kurz sind, wie sie sein könnten).
Es ist jedoch nicht sicher, wie gut dies funktionieren wird. Das neuronale Netz könnte einen beliebig weit "vom Kurs abbringen" und sogar zu einem Knoten führen, von dem aus es keinen Weg zum Ziel gibt.
Aber zumindest in einfachen Fällen kann der Ansatz potenziell gut funktionieren – und die KI kann erfolgreich einen Pfad finden, der das Spiel gewinnt, den Beweis führt usw. Man kann jedoch nicht erwarten, dass es immer funktioniert. Der Grund dafür ist, dass man auf multikomputationale Irreduzibilität stoßen wird. So wie in einem einzelnen "Berechnungsstrang" die Irreduzibilität der Berechnung bedeuten kann, dass es keine Abkürzung gibt, einfach "die Schritte der Berechnung durchzugehen", so kann in einem Mehrwegsystem die multikomputationelle Irreduzibilität bedeuten, dass es keine Abkürzung gibt, einfach "allen Berechnungssträngen zu folgen", um dann zu sehen, welche sich z.B. vereinigen.
Aber selbst wenn dies prinzipiell möglich wäre, passiert es in der Praxis in den Fällen, die für uns Menschen interessant sind? Bei Spielen oder Rätseln neigen wir dazu, es schwierig – aber nicht zu schwierig – zu machen, um zu "gewinnen". Und wenn es um Mathematik und das Beweisen von Theoremen geht, möchten wir auch, dass die Fälle, die wir für Übungen oder Wettbewerbe verwenden, schwer, aber nicht zu schwer sind. Aber wenn es um mathematische Forschung und die Grenzen der Mathematik geht, erwartet man eine solche Einschränkung nicht sofort. Und das Ergebnis ist dann, dass man erwarten kann, direkt mit multikomputationaler Irreduzibilität konfrontiert zu werden – was es schwierig macht, dass KI zu viel hilft.
Es gibt jedoch eine Fußnote zu dieser Geschichte, die damit zu tun hat, wie wir neue Richtungen in der Mathematik wählen. Man kann von einem metamathematischen Raum ausgehen, der durch die Konstruktion von Theoremen aus anderen Theoremen auf alle möglichen Arten in einem riesigen Mehrweggraphen gebildet wird. Aber wie wir weiter unten sehen werden, sind die meisten Details davon weit entfernt von dem, was menschliche Mathematiker als "Mathematik betreiben" ansehen würden. Stattdessen scheinen Mathematiker implizit Mathematik auf einer "höheren Ebene" zu betreiben, auf der sie diese "mikroskopische Metamathematik" vergröbert haben – so wie wir eine physikalische Flüssigkeit im Hinblick auf ihre relativ einfach zu beschreibende kontinuierliche Dynamik untersuchen könnten, obwohl "darunter" viele komplizierte molekulare Bewegungen liegen.
Kann die KI bei dieser "fluiddynamischen" Mathematik helfen? Potenziell ja, aber hauptsächlich in Form von Code-Unterstützung. Es gibt etwas, das ausgedrückt werden will, sagen wir in Wolfram Language [6]. Aber es wird Hilfe benötigt – im Stil eines LLM – um von unserem informellen Konzept zu einer expliziten Berechnungssprache zu gelangen. Und in dem Maße, in dem das, was getan wird, den strukturellen Mustern dessen folgt, was zuvor getan wurde, kann man erwarten, dass so etwas wie ein LLM helfen wird. Aber in dem Maße, in dem das, was ausgedrückt wird, "wirklich neu" ist und unsere Sprache nicht viel "Boilerplate" enthält, ist es schwer vorstellbar, dass eine KI, die auf dem basiert, was bereits getan wurde, viel helfen wird. Stattdessen muss eine irreduzible Multicomputerberechnung durchgeführt werden, die es ermöglicht, einen neuen Teil des Rechenuniversums und des Ruliad [7] zu erforschen.
Erforschung von Systemräumen
"Kann man ein System finden, das X ausführt?" Das könnt beispielsweise eine Turingmaschine sein, die sehr lange läuft, bevor sie hält, oder ein zellulärer Automat, der wächst, aber nur sehr langsam, oder eine Chemikalie mit einer bestimmten Eigenschaft.
Dies ist eine etwas andere Art von Fragestellung als die, die bisher diskutiert wurden. Es geht nicht darum, eine bestimmte Regel zu nehmen und zu sehen, welche Konsequenzen sie hat. Es geht darum, zu identifizieren, welche Regel existieren könnte, die bestimmte Konsequenzen hat.
Angesichts eines Raums möglicher Regeln ist ein Ansatz die erschöpfende Suche. In gewissem Sinne ist dies letztlich der einzige wirklich unvoreingenommene Ansatz, der entdecken wird, was es zu entdecken gibt, selbst wenn man es nicht erwartet. Natürlich benötigt man selbst bei der erschöpfenden Suche noch eine Möglichkeit, zu bestimmen, ob ein bestimmtes Kandidatensystem das festgelegte Kriterium erfüllt. Aber jetzt ist dies das Problem der Vorhersage einer Berechnung – wobei das oben Gesagte gilt.
Aber kann man besser als die erschöpfende Suche vorgehen? Und kann man etwa einen Weg finden, herauszufinden, welche Regeln erkundet werden sollen, ohne jede Regel anschauen zu müssen? Ein Ansatz ist, so etwas wie das zu tun, was in der biologischen Evolution durch natürliche Selektion geschieht: Man beginnt, sagen wir, mit einer bestimmten Regel und ändert sie dann schrittweise (möglicherweise zufällig), indem man bei jedem Schritt die Regel oder Regeln behält, die am besten abschneiden, und die anderen verwirft.
Dies ist keine KI im hier operationell definierten Sinne (es ähnelt mehr einem genetischen Algorithmus) – obwohl es etwas wie die innere Trainingsschleife eines neuronalen Netzes ist. Aber wird es funktionieren? Nun, das hängt von der Struktur des Regelraums ab – und, wie man im maschinellen Lernen sieht, funktioniert es tendenziell besser in höherdimensionalen Regelräumen als in niedrigerdimensionalen. Denn mit mehr Dimensionen besteht eine geringere Chance, dass man „in einem lokalen Minimum stecken bleibt“ und keinen Weg heraus zu einer "besseren Regel“ findet.
Im Allgemeinen, wenn der Kontrollraum wie eine komplizierte fraktale Berglandschaft ist, kann man vernünftigerweise erwarten, dass schrittweise Fortschritte gemacht werden. KI-Methoden, wie beispielsweise das Lernen durch Verstärkung, können dabei helfen, die zu unternehmenden Schritte zu verfeinern. Ist das Gelände jedoch eher flach, beispielsweise mit nur einem Loch irgendwo ("Golfplatz-Stil“), kann nicht erwartet werden, dass das Loch schrittweise gefunden wird. Wie sieht also die typische Struktur von Regelräumen aus? Sicherlich gibt es viele Fälle, in denen der Regelraum insgesamt ziemlich groß ist, aber die Anzahl der Dimensionen bescheiden ist. Und in solchen Fällen (ein Beispiel ist die Suche nach kleinen Turingmaschinen mit langen Haltezeiten) scheint es oft "isolierte Lösungen“ zu geben, die nicht schrittweise erreicht werden können. Aber wenn es mehr Dimensionen gibt, scheint es wahrscheinlich, dass das, was im Wesentlichen die rechnerische Irreduzibilität darstellt, mehr oder weniger garantiert, dass es eine "ausreichend zufällige Landschaft“ gibt, in der schrittweise Methoden gut funktionieren können, wie wir es in den vergangenen Jahren im maschinellen Lernen gesehen haben.
Und was ist mit KI? Könnte es einen Weg geben, dass KI lernt, wie man direkt im Regelraum "Gewinner auswählt“, ohne irgendeinen inkrementellen Prozess? Könnten wir vielleicht einen Einbettungsraum finden, in dem die gewünschten Regeln auf einfache Weise angeordnet sind – und somit effektiv „vorab für uns identifiziert“ werden? Letztendlich hängt es davon ab, wie der Regelraum beschaffen ist und
ob der Prozess seiner Erkundung notwendigerweise (multi)computational irreduzibel ist, oder ob zumindest die Aspekte davon, die uns interessieren, durch einen reduzierbaren Prozess erkundet werden können. (Übrigens versucht man, KI direkt zu verwenden, um Systeme mit bestimmten Eigenschaften zu finden, ist ein wenig so, als würde man versuchen, KI direkt zu verwenden, um neuronale Netze aus Daten ohne inkrementelles Training zu generieren.)
Betrachten wir ein einfaches Beispiel auf Basis von zellulären Automaten. Angenommen, Sie möchten eine Regel für zelluläre Automaten finden, die – ausgehend von einer einzigen Zellen-Anfangsbedingung – eine Weile wächst, aber dann nach einer bestimmten, genauen Anzahl von Schritten ausstirbt. Sie können versuchen, dies mit einem sehr minimalen KI-ähnlichen evolutionären Ansatz zu lösen: Beginnend mit einer zufällig ausgewählten Regel, dann in jeder Generation eine bestimmte Anzahl von "Nachkommen“-Regeln erzeugen, bei denen jeweils ein Element zufällig geändert wird – dann die "beste" dieser Regeln behalten. Wenn Sie eine Regel finden wollen, die genau 50 Schritte lebt, definieren Sie "beste" als diejenige, die eine Verlustfunktion minimiert, die gleich der Entfernung von 50 der Anzahl der Schritte ist, die eine Regel tatsächlich "lebt".
So könnte man beispielsweise von der zufällig ausgewählten (Drei-Farben-)Regel starten:

(Bild: Stephen Wolfram)
Die evolutionäre Abfolge von Regeln (hier nur die Ergebniswerte gezeigt) könnte wie folgt aussehen:
(Bild: Stephen Wolfram)
Wenn das Verhalten dieser Regeln betrachtet wird, zeigt sich, dass sie – nach einem wenig vielversprechenden Start – erfolgreich eine Regel entwickeln, die das Kriterium "genau 50 Schritte zu leben“ erfüllt:
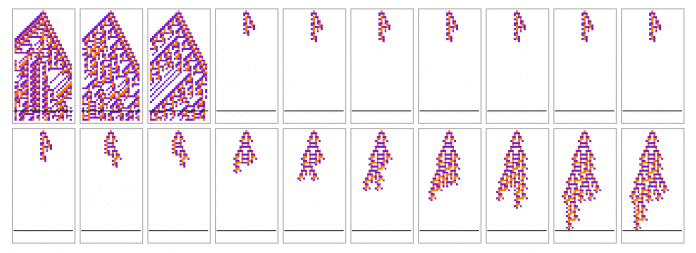
(Bild: Stephen Wolfram)
Im Bild sieht man ein zufällig gewählter Evolutionspfad. Doch was geschieht auf anderen Pfaden? Hier ist die Entwicklung des Verlusts (über den Verlauf von 100 Generationen) für eine Sammlung von Pfaden:
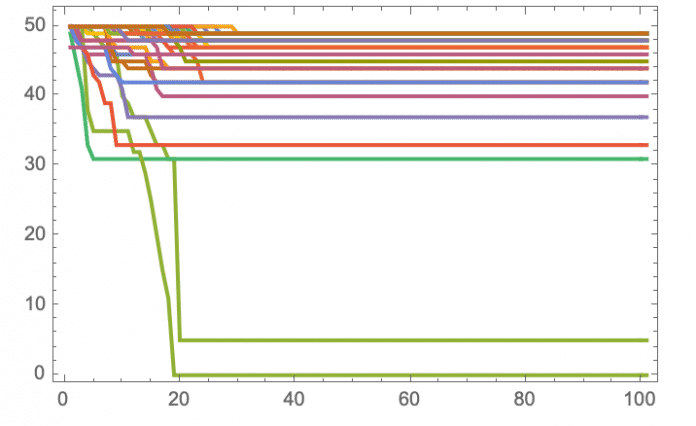
(Bild: Stephen Wolfram)
Und wir sehen, dass es hier nur einen "Gewinner" gibt, der keinen Verlust erleidet; auf allen anderen Wegen bleibt die Evolution "stecken".
Wie bereits erwähnt, sinkt die Wahrscheinlichkeit, stecken zu bleiben, mit mehr Dimensionen. Wenn man sich etwa die Regeln für vierfarbige zelluläre Automaten ansieht, gibt es jetzt 64 statt 27 mögliche Elemente (oder effektiv Dimensionen), die verändert werden können, und in diesem Fall kommen viele Wege der Evolution weiter
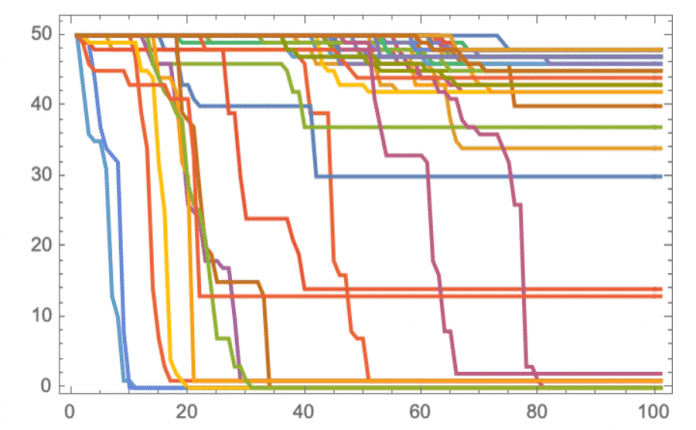
(Bild: Stephen Wolfram)
und es gibt noch mehr "Gewinner" wie in diesem Beispiel:

(Bild: Stephen Wolfram)
Neuronale Netze könnten helfen, die Evolution von zellulären Automaten schneller zu verstehen, indem sie die Berechnung des Verlusts für Regeln beschleunigen. Allerdings könnte die Komplexität der Berechnungen ein Hindernis sein. Eine Idee ist, neuronale Netze zu nutzen, um zu entscheiden, welche Änderungen bei jeder Generation gemacht werden sollen. Aber die Komplexität der Berechnungen macht es schwierig für neuronale Netze, uns genau zu sagen, was wir tun sollen, auch wenn sie helfen, nicht festzustecken.
Wissenschaft als Narrativ
Traditionell geht es in der Wissenschaft darum, das, was in der Welt existiert, auf eine Weise zu interpretieren, die für uns Menschen verständlich ist. Wir möchten, dass die Wissenschaft eine für den Menschen zugängliche Erzählung darüber liefert, was beispielsweise in der natürlichen Welt geschieht.
Das Phänomen der rechnerischen Irreduzibilität zeigt uns jedoch, dass dies oft letztendlich nicht möglich sein wird. Doch wenn es eine Nische der rechnerischen Reduzierbarkeit gibt, bedeutet das, dass es eine Art vereinfachter Beschreibung für zumindest einen Teil des Geschehens gibt. Aber kann eine solche vereinfachte Beschreibung von einem Menschen vernünftigerweise verstanden werden? Kann sie etwa knapp in Worten, Formeln oder in einer Computersprache dargestellt werden? Wenn ja, dann kann sie als eine erfolgreiche "wissenschaftliche Erklärung auf menschlicher Ebene" angesehen werden.
Kann also KI uns helfen, solche Erklärungen automatisch zu erstellen? Dazu müsste sie gewissermaßen ein Modell dafür haben, was wir Menschen verstehen – und wie wir dieses Verständnis in Worten ausdrücken usw. Es nützt wenig zu sagen: "Hier sind 100 Rechenschritte, die dieses Ergebnis erzeugen." Um eine "Erklärung auf menschlicher Ebene" zu erhalten, müssen wir dies in Teile zerlegen, die Menschen aufnehmen können.
Als Beispiel sei ein mathematischer Beweis angeführt, der maschinenunterstützt erzeugt wurde:

(Bild: Stephen Wolfram)
Ein Computer kann leicht überprüfen, ob dies korrekt ist, da jeder Schritt logisch aus dem vorherigen folgt. Aber das Ergebnis ist sehr "unmenschlich" – es fehlt ein realistisches "menschliches Narrativ". Um eine solche Erzählung zu erstellen, wären "Wegpunkte" erforderlich, die irgendwie vertraut sind – vielleicht berühmte Theoreme, die leicht zu erkennen sind. Allerdings könnten solche möglicherweise nicht existieren. Der Beweis könnte durch "unerschlossenes metamathematisches Gebiet [8]" führen. Daher könnte die menschliche Mathematik, wie sie heute existiert, möglicherweise nicht das notwendige Rohmaterial besitzen, um ein menschliches Narrativ zu erschaffen, unabhängig von einer KI-Unterstützung.
In der Praxis, wenn die "metamathematische Distanz" zwischen den Schritten eines Beweises recht kurz ist, erscheint es realistisch, dass eine Erklärung auf menschlicher Ebene möglich ist. Genau das wird benötigt, ähnlich wie Wolfram|Alpha, wenn es schrittweise Erklärungen für seine Antworten erzeugt. Kann KI helfen? Potenziell ja, mit Methoden ähnlich dem zweiten Ansatz zur KI-gestützten Multikomputation, wie oben beschrieben.
Übrigens tragen auch die Bemühungen mit der Wolfram Language bei. Denn die gesamte Idee unserer Berechnungssprache ist es, "häufige Blöcke der Berechnungsarbeit" als eingebaute Konstrukte zu erfassen – und im Grunde geht es beim Entwerfen der Sprache genau darum, "für Menschen assimilierbare Wegpunkte" für Berechnungen zu identifizieren. Die rechnerische Irreduzibilität sagt uns, dass es nie möglich sein wird, solche Wegpunkte für alle Berechnungen zu finden. Aber das Ziel ist es, Wegpunkte zu finden, die aktuelle Paradigmen und aktuelle Praktiken erfassen, sowie Richtungen und Rahmenwerke für deren Erweiterung zu definieren – obwohl letztlich "was wir Menschen wissen" durch den Stand des menschlichen Wissens bestimmt wird, wie es sich historisch entwickelt hat.
Beweise und Programme in Programmiersprachen für Berechnungen sind zwei Beispiele für strukturierte "wissenschaftliche Narrative". Ein möglicherweise einfacheres Beispiel, das sich an der mathematischen Tradition in der Wissenschaft orientiert, ist eine reine Formel. "Es handelt sich um ein Potenzgesetz." "Es ist eine Summe von Exponentialfunktionen." Und so weiter. Kann KI dabei unterstützen? Eine Funktion wie FindFormula nutzt bereits von maschinellem Lernen inspirierte Techniken, um Daten zu analysieren und zu versuchen, eine "sinnvolle Formel dafür" zu finden.
Dies ist das recht einfache Ergebnis für die ersten 100 Primzahlen und das deutlich kompliziertere für die ersten 10.000:

(Bild: Stephen Wolfram / Bearbeitung: heise online)
Fragt man stattdessen nach dem Verhältnis zwischen Bruttoinlandsprodukt und der Bevölkerung eines Landes, bekommt man Formeln wie:
BIP ≈ $ 340 Bevölkerung0.033 Bevölkerungswachstum [% / Jahr]+1.3 pro Jahr
Aber was bedeuten diese Formeln überhaupt? Es ist ein wenig wie mit den Beweisschritten und so weiter. Solange sich der Inhalt der Formeln nicht mit bekannten Dingen in Verbindung bringen lässt (sei es in der Zahlentheorie oder in der Wirtschaft), ist es in der Regel schwierig, etwas daraus zu schließen. Außer vielleicht in einigen seltenen Fällen, in denen man sagen kann: "Ja, das ist ein neues, nützliches Gesetz" – wie in dieser "Ableitung" des dritten Keplerschen Gesetzes (wobei 0,7 eine ziemlich gute Annäherung an 2/3 ist):

(Bild: Stephen Wolfram)
Es gibt ein noch einfacheres Beispiel dafür, wenn es um die Erkennung von Zahlen geht. Geben Sie eine Zahl in Wolfram|Alpha ein und es wird versuchen, Ihnen zu sagen, welche "möglichen geschlossenen Formen" für die Zahl infrage kommen:

(Bild: Stephen Wolfram)
Hier gibt es alle möglichen Kompromisse, von denen einige sehr KI-basiert sind. Wie wichtig ist es, mehr Stellen richtig zu haben im Vergleich zu einer einfachen Formel? Was ist mit einfachen Zahlen in der Formel im Vergleich zu "obskureren" mathematischen Konstanten (beispielsweise π im Vergleich zur Champernowne [9]-Zahl)? Als wir vor 15 Jahren dieses System für Wolfram|Alpha einführten, verwendeten wir die negative logarithmische Häufigkeit von Konstanten in der mathematischen Literatur als Indikator für ihren "Informationsgehalt". Mit modernen LLM-Techniken ist es vielleicht möglich, ganzheitlicher zu arbeiten, um das zu finden, was einer "guten wissenschaftlichen Erzählung" für eine Zahl entspricht.
Aber zurück zu Themen wie der Vorhersage des Ergebnisses von Prozessen wie der Evolution zellulärer Automaten. In einem früheren Abschnitt [10] sprach ich darüber, wie neuronale Netze in der Lage sind, solche Vorhersagen zu treffen. Ich betrachtete dies im Wesentlichen als einen "Black-Box"-Ansatz: Ich wollte sehen, ob ich ein neuronales Netz erfolgreich für Vorhersagen einsetzen kann, ohne ein "menschliches Verständnis" dieser Vorhersagen erlangen zu müssen.
Es ist eine alltägliche Erfahrung beim maschinellen Lernen. Man trainiert ein neuronales Netz, um erfolgreich Vorhersagen zu treffen, zu klassifizieren, oder was auch immer. Aber wenn man "hineinschaut", ist es schwierig zu erkennen, was vor sich geht. Hier ist das Endergebnis der Anwendung eines neuronalen Netzes zur Bilderkennung [11]. Oben das Ergebnis, darunter einige "Zwischengedanken", die nach dem Durchlaufen von etwa der Hälfte der Schichten des Netzes entstehen:

(Bild: Stephen Wolfram / Bearbeitung: heise online)
Vielleicht gibt es hier eine "definitive Signatur der Katzenart". Aber es ist nicht Teil unseres derzeitigen wissenschaftlichen Vokabulars – also können wir es nicht sinnvoll nutzen, um eine "wissenschaftliche Erzählung" zu entwickeln, die erklärt, wie das Bild zu interpretieren ist.
Aber was wäre, wenn wir unsere Bilder auf einige wenige Parameter reduzieren könnten – etwa mit einem Auto-Encoder, wie wir ihn oben beschrieben haben? Es ist denkbar, dass wir die Dinge so einrichten, dass wir am Ende "interpretierbare Parameter" haben - oder anders gesagt, Parameter, deren Bedeutung wir mit einer Erzählung erklären können. Wir könnten uns zum Beispiel vorstellen, dass wir so etwas wie ein LLM verwenden, um Parameter auszuwählen, die in irgendeiner Weise mit Wörtern oder Ausdrücken ("Pointiness", "fraktale Dimension" und so weiter) übereinstimmen, die in erklärenden Texten im Internet auftauchen. Und ja, diese Wörter oder Ausdrücke könnten auf Analogien beruhen ("kaktusförmig", "zirruswolkenähnlich", ...) - und etwas wie ein LLM könnte sich diese Namen "kreativ" ausdenken.
Letztlich spricht aber nichts dafür, dass ein von einem bestimmten Autoencoder aufgespürter Bereich rechnerischer Reduzibilität in irgendeiner Weise mit (wissenschaftlichen oder anderen) Konzepten in Einklang zu bringen ist, die wir Menschen bisher erforscht oder in Worte gefasst haben. In der Tat ist es sehr wahrscheinlich, dass wir uns im Großen und Ganzen in einem "Zwischenbegriffsraum" befinden – unfähig, etwas zu schaffen, was wir als nützliche wissenschaftliche Erzählung betrachten würden.
Dies hängt jedoch ein wenig davon ab, wie wir das, was wir betrachten, einschränken. Wir könnten Wissenschaft implizit als die Untersuchung von Phänomenen definieren, für die wir – zu einem bestimmten Zeitpunkt – erfolgreich ein wissenschaftliches Narrativ entwickelt haben. Und in diesem Fall ist es natürlich unvermeidlich, dass es eine solche Erzählung gibt. Aber selbst bei einer festen Beobachtungs- oder Messmethode ist es im Grunde unvermeidlich, dass die rechnerische Irreduzibilität bei der Erforschung zu "Überraschungen" führt, die aus dem wissenschaftlichen Narrativ, das wir verwendet haben, ausbrechen. Mit anderen Worten: Wenn wir wirklich eine neue Wissenschaft entdecken wollen, dann können wir – KI hin oder her – nicht erwarten, dass wir ein wissenschaftliches Narrativ haben, das auf bereits existierenden Konzepten beruht. Vielleicht ist das Beste, was wir erwarten können, dass wir kleine Bereiche finden, in denen komplexe Dinge erleichtert werden können. Wir hoffen, dass Künstliche Intelligenz (KI) genug über uns und die Geschichte unseres Denkens lernt. Damit könnte sie uns einen klaren Weg vorschlagen, neue Ideen zu lernen. Diese neuen Ideen helfen uns, eine schlüssige wissenschaftliche Erklärung für unsere Entdeckungen zu entwickeln.
Herausfinden, was interessant ist
Ein zentraler Bestandteil einer ergebnisoffenen Wissenschaft ist es, herauszufinden, "was interessant ist". Angenommen, man zählt einfach eine Sammlung von zellulären Automaten auf:

(Bild: Stephen Wolfram)
Diejenigen, die einfach verschwinden – oder gleichförmige Muster bilden – "scheinen nicht interessant zu sein". Wenn man zum ersten Mal ein verschachteltes Muster sieht, das von einem zellulären Automaten erzeugt wurde, mag es interessant erscheinen (so wie es mir 1981 erschien). Aber schon bald wird es zur Routine. Und zumindest in der grundlegenden Ruliologie ist das, wonach man letztlich sucht, die "Überraschung": ein qualitativ neues Verhalten, das man vorher nicht gesehen hat. (Wenn man sich mit spezifischen Anwendungen beschäftigt, etwa mit der Modellierung bestimmter Systeme in der Welt, dann möchte man vielleicht eher Regeln mit einer bestimmten Struktur betrachten, unabhängig davon, ob ihr Verhalten "abstrakt interessant" erscheint oder nicht).
Die Tatsache, dass man "Überraschungen" erwarten kann (und überhaupt in der Lage ist, nützliche, wirklich ergebnisoffene Wissenschaft zu betreiben), ist eine Folge der rechnerischen Irreduzibilität. Und das Ausbleiben von "Überraschungen" ist im Grunde ein Zeichen für rechnerische Reduzibilität. Dies macht es plausibel, dass KI – und neuronale Netze – lernen könnten, zumindest bestimmte Arten von "Anomalien" oder "Überraschungen" zu erkennen und damit eine Version dessen zu entdecken, "was interessant ist".
Normalerweise besteht die Grundidee darin, dass ein neuronales Netz die "typische Verteilung" von Daten lernt und dann Ausreißer in Bezug auf diese Verteilung erkennt. Beispielsweise könnte man eine große Anzahl von zellularen Automatenmustern untersuchen und dann eine Projektion dieser Verteilung auf einen 2D-Merkmalsraum erstellen, die anzeigt, wo sich bestimmte Muster befinden:
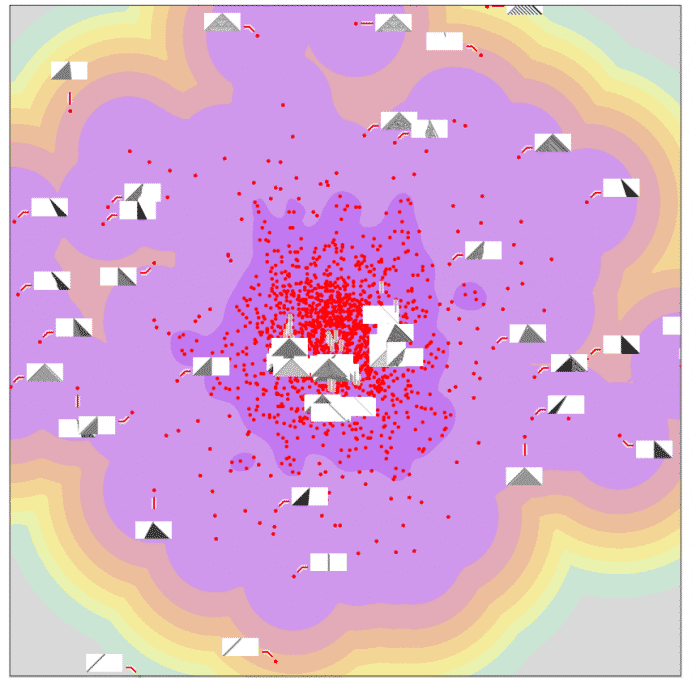
(Bild: Stephen Wolfram)
Einige der Muster treten in Teilen der Verteilung auf, in denen ihre Wahrscheinlichkeiten hoch sind, andere hingegen in Bereichen, in denen die Wahrscheinlichkeiten niedrig sind - dies sind die Ausreißer:

(Bild: Stephen Wolfram)
Sind diese Ausreißer "interessant"? Nun, das hängt von Ihrer Definition von ab. Und die liegt letztlich im Auge des Betrachters, in diesem Fall ein neuronales Netz. Und, ja, diese speziellen Muster wären nicht das, was ich ausgewählt hätte. Aber im Vergleich zu den typischen Mustern scheinen sie zumindest etwas anders zu sein. Und vermutlich ist es im Grunde eine Geschichte wie die mit den neuronalen Netzen, die Bilder von Katzen und Hunden unterscheiden: Neuronale Netze fällen zumindest einigermaßen ähnliche Urteile wie wir – vielleicht weil unsere Gehirne strukturell wie neuronale Netze aufgebaut sind.
OK, aber was findet ein neuronales Netz "an sich interessant"? Wenn das neuronale Netz trainiert wird, wird es sehr stark von dem beeinflusst, was man als "kulturellen Hintergrund" bezeichnet. Was aber, wenn man einfach neuronale Netze mit einer bestimmten Architektur einrichtet und ihre Gewichte zufällig auswählt? Angenommen, die neuronalen Netze sollen Funktionen berechnen, beispielsweise:
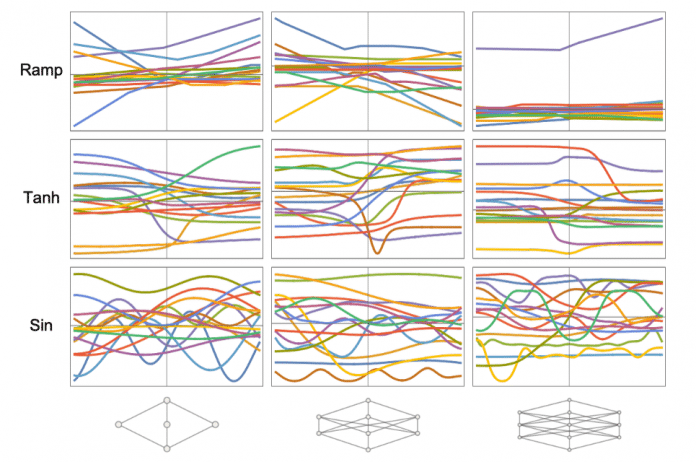
(Bild: Stephen Wolfram)
Es ist nicht allzu überraschend, dass die Funktionen, die dabei herauskommen, die zugrundeliegenden Aktivierungsfunktionen, die an den Knoten der neuronalen Netze auftreten, sehr gut widerspiegeln. Aber wir können sehen, dass – ähnlich wie bei einem Random-Walk-Prozess – "extremere" Funktionen weniger wahrscheinlich von neuronalen Netzen mit zufälligen Gewichten erzeugt werden, sodass man sie als "an sich überraschender" für neuronale Netze betrachten kann.
Überraschung kann ein Kriterium für Interessantheit sein, es gibt jedoch auch andere. Um zu bestimmen, was interessant ist, kann man verschiedene Konstrukte betrachten und entscheiden, welche davon einer genaueren Untersuchung, Benennung oder Erfassung würdig sind.
Betrachtet man erstes Beispiel eine Familie von Kohlenwasserstoffmolekülen: Alkane. Jedes dieser Moleküle kann durch einen Baumgraphen dargestellt werden, dessen Knoten den Kohlenstoffatomen entsprechen und eine Wertigkeit von höchstens 4 haben. Es gibt insgesamt 75 Alkane mit zehn oder weniger Kohlenstoffen, und alle von ihnen tauchen typischerweise in Standardlisten von Chemikalien (und in der Wolfram Knowledgebase [12]) auf. Aber mit zehn Kohlenstoffen sind nur einige Alkane "interessant genug", um in der Knowledgebase aufgeführt zu werden (wenn man verschiedene Register zusammenfasst, findet man mehr aufgelistete Alkane, aber bei elf Kohlenstoffen scheinen immer mindestens 42 von 159 zu "fehlen" – und werden hier nicht hervorgehoben):
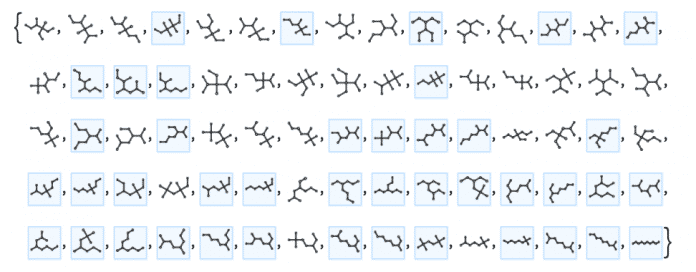
(Bild: Stephen Wolfram)
Was macht einige dieser Alkane in diesem Sinne "interessanter" als andere? Operativ gesehen ist es eine Frage, ob sie, beispielsweise in der wissenschaftlichen Literatur, untersucht wurden. Aber was bestimmt dies?
Zum Teil hängt es davon ab, ob sie "in der Natur vorkommen". Manchmal – etwa in Erdöl oder Kohle – entstehen Alkane durch sogenannte "Zufallsreaktionen", bei denen unverzweigte Moleküle bevorzugt werden. Aber auch in biologischen Systemen können Alkane durch sorgfältige Orchestrierung, beispielsweise durch Enzyme, entstehen. Aber wo auch immer sie herkommen, es scheint, als ob die bekannteren Alkane auch die "interessanteren" sind. Wie steht es also mit der "Überraschung"? Ob ein "Überraschungsalkan" – beispielsweise durch explizite Synthese im Labor hergestellt – als interessant gilt, hängt wahrscheinlich in erster Linie davon ab, ob man ihm ebensolche Eigenschaften zuschreibt. Und das wiederum ist in der Regel eine Frage der Einordnung seiner Eigenschaften in das gesamte Netz menschlichen Wissens und menschlicher Technologie.
Kann die künstliche Intelligenz also dabei helfen, herauszufinden, welche Alkane für uns interessant sein könnten? Herkömmliche chemische Berechnungen – vielleicht beschleunigt durch KI – können die Raten bestimmen, mit denen verschiedene Alkane zufällig produziert werden. Und in einer ganz anderen Richtung kann die Analyse der akademischen Literatur – beispielsweise mit einem LLM – potenziell vorhersagen, wie viel ein bestimmtes Alkan voraussichtlich untersucht oder besprochen wird. Oder (und das ist besonders relevant für Arzneimittelkandidaten), ob es Hinweise auf "wenn wir nur ein Molekül finden könnten, das ___ tut" gibt, die man aus der akademischen Literatur ableiten kann.
Ein weiteres Beispiel sind mathematische Theoreme. Ähnlich wie bei Chemikalien kann man im Prinzip mögliche mathematische Theoreme aufzählen, indem man von Axiomen ausgeht und dann sieht, welche Theoreme sich daraus ableiten lassen. Dies geschieht in nur zwei Schritten, ausgehend von einigen typischen Axiomen für die Logik:
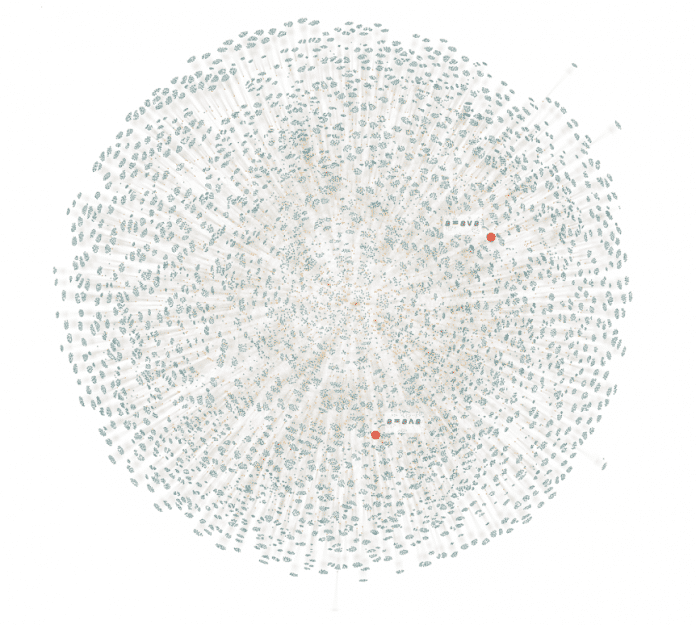
(Bild: Stephen Wolfram)
Es gibt eine große Anzahl von "uninteressanten" (und oft sehr pedantisch anmutenden) Sätzen. Aber unter all diesen Sätzen gibt es zwei, die so interessant sind, dass sie in den Lehrbüchern der Logik typischerweise mit Namen versehen werden (Idempotenzgesetze [13]). Kann man feststellen, ob ein Theorem einen Namen bekommen wird? Man könnte meinen, das sei eine rein historische Frage. Aber zumindest im Fall der Logik scheint es ein systematisches Muster zu geben. Nehmen wir an, man zählt die Theoreme der Logik auf, beginnend mit den einfachsten und dann in lexikografischer Reihenfolge. Die meisten Theoreme in der Liste lassen sich aus früheren Theoremen ableiten. Aber einige wenige sind es nicht. Und diese stellen sich im Grunde als genau die heraus, die üblicherweise mit Namen versehen (und hier hervorgehoben) werden:

(Bild: Stephen Wolfram)
Ein Blick in den "metamathematischen Raum" erlaubt es, empirisch zu erkennen, wo die als "interessant" geltenden Theoreme liegen:
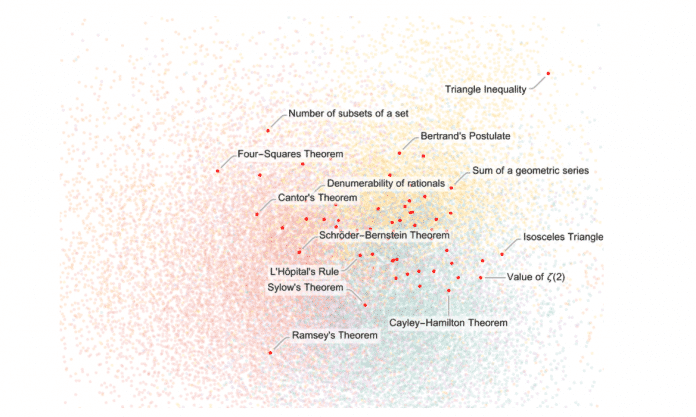
(Bild: Stephen Wolfram)
Könnte eine KI dies vorhersagen? Es lässt sich sicherlich ein neuronales Netz entwickeln, das auf Basis der vorhandenen mathematischen Literatur und ihrer wenigen Millionen Theoreme trainiert wird. Dieses neuronale Netz ließe sich dann mit Theoremen füttern, die durch systematische Aufzählung gefunden wurden, um zu bewerten, wie plausibel ihr Erscheinen in der mathematischen Literatur wäre. Bei einer systematischen Aufzählung könnte das neuronale Netz auch dazu angehalten werden, zu bestimmen, welche "Richtungen" wahrscheinlich als "interessant" gelten könnten – ähnlich wie bei der zweiten Methode des "KI-gestützten Durchquerens von Mehrwegesystemen".
Wenig überraschender Mainstream
Die Suche nach "wirklich neuer Wissenschaft" (oder Mathematik) stößt auf ein Problem, wenn ein neuronales Netz, trainiert auf vorhandener Literatur, im Wesentlichen nach mehr vom Gleichen sucht. Ähnlich wie in einem Peer-Review-Verfahren wird nur das "akzeptiert", was als "Mainstream" und "nicht allzu überraschend" gilt. Doch wie verhält es sich mit den Überraschungen, die aus rechnerischer Irreduzibilität resultieren? Sie sind definitionsgemäß leicht auf Bekanntes reduzierbar.
Sie können neue Fakten liefern und sogar wichtige Anwendungen haben. Oft gibt es jedoch zumindest anfangs kein "menschlich zugängliches Narrativ" für sie. Um dies zu erreichen, müssen neue Konzepte verinnerlicht werden.
Letztendlich herrscht eine gewisse Willkür darüber, welche "neuen Fakten" oder "neuen Richtungen" verinnerlicht werden sollen. Die Wahl einer bestimmten Richtung kann zu spezifischen Ideen, Technologien oder Aktivitäten führen. Doch abstrakt betrachtet bleibt unklar, welche Richtung "richtig" ist; zunächst scheint dies eine Frage der menschlichen Entscheidung.
Es gibt allerdings eine Überlegung: Was, wenn eine KI genug über menschliche Psychologie und Gesellschaft wüsste, um vorherzusagen, "was gewollt wird"? Auf den ersten Blick könnte sie dann erfolgreich "Richtungen wählen". Doch die rechnerische Irreduzibilität stellt ein Hindernis dar, denn letztendlich ist nicht vorhersehbar, "was gefallen wird", bevor das Ziel erreicht ist.
Dies lässt sich auf generative KI, beispielsweise für Bilder oder Texte, übertragen. Anfangs könnte man sich vorstellen, Bilder zu erzeugen, die aus beliebigen Pixelanordnungen bestehen. Doch ein überwältigender Anteil davon wird nicht "interessant" wirken; sie erscheinen lediglich als "zufälliges Rauschen".

(Bild: Stephen Wolfram)
Durch das Training eines neuronalen Netzes mit Milliarden von Menschen ausgewählten Bildern kann es dazu gebracht werden, Bilder zu erzeugen, die irgendwie "im Allgemeinen dem ähneln, was wir als interessant empfinden". Manchmal werden die erzeugten Bilder so erkennbar sein, dass eine "narrative Erklärung" dafür gegeben werden kann, wie sie aussehen:

(Bild: Stephen Wolfram)
Aber häufig werden wir uns mit Bildern "im Zwischenkonzept-Raum [14]“ wiederfinden:

(Bild: Stephen Wolfram)
Sind diese "interessant"? Es lässt sich schwer sagen. Beim Scannen des Gehirns einer Person, die sie betrachtet, könnte ein bestimmtes Signal auffallen – und vielleicht könnte eine KI lernen, dies vorherzusagen. Doch unweigerlich würde sich dieses Signal ändern, sollte eine Art "Zwischenkonzept-Bild" populär werden und beginnen, beispielsweise als eine Kunstform anerkannt zu werden, mit der Menschen vertraut sind.
Am Ende kehrt die Diskussion zum selben Punkt zurück: Dinge sind letztlich "interessant", wenn sie durch die Entscheidungen einer Zivilisation dazu gemacht werden. Es gibt kein abstraktes Konzept von "Interessantheit", das eine KI oder irgendetwas vor unseren Entscheidungen "entdecken" kann.
Das gilt auch für die Wissenschaft. Es gibt keinen abstrakten Weg zu wissen, "was interessant ist", aus allen Möglichkeiten im Ruliad; das wird letztlich durch die Entscheidungen bestimmt, die bei der "Kolonisierung" des Ruliads getroffen werden. Der Ruliad, ein Konzept, das alle möglichen durch computergestützte Regeln generierten Universen umfasst, bietet keinen direkten Weg zur Erkennung von "Interessantheit" außerhalb menschlicher Entscheidungen.
Die Wildnis des Ruliad
Was aber, wenn – anstatt in die "Wildnis des Ruliads" vorzustoßen – nahe bei dem geblieben wird, was bereits in der Wissenschaft getan und als "interessant angesehen" wurde? Kann KI dabei helfen, das Vorhandene zu erweitern? Zumindest praktisch gesehen ist die Antwort auf gewisser Ebene sicherlich ja. LLMs sollten beispielsweise in der Lage sein, Inhalte zu produzieren, die dem Muster akademischer Arbeiten folgen – mit Spuren von "Originalität", die aus der verwendeten Zufälligkeit im LLM resultieren.
Wie weit kann ein solcher Ansatz führen? Die existierende akademische Literatur ist sicherlich voller Lücken. Phänomen A wurde in System X untersucht und B in Y, aber nicht umgekehrt, usw. Es kann erwartet werden, dass KIs – und insbesondere LLMs – nützlich sind, um diese Lücken zu identifizieren und effektiv "zu planen", welche Wissenschaft (nach diesem Kriterium) interessant zu betreiben ist. Ferner können Dinge wie LLMs hilfreich sein, um "übliche und gewöhnliche" Wege aufzuzeigen, wie die Wissenschaft durchgeführt werden sollte. Beim eigentlichen "Betreiben der Wissenschaft" werden jedoch die tatsächlichen computergestützten Sprachwerkzeuge – zusammen mit Dingen wie computergesteuerten Experimentiergeräten – vermutlich zentraler sein.
Aber nehmen wir an, ein großes Ziel für die Wissenschaft wurde definiert ("herausfinden, wie man das Altern umkehren kann", oder, etwas bescheidener, "Kryonik lösen"). Mit einem solchen Ziel wird etwas als "interessant" spezifiziert. Und dann ist das Problem, dieses Ziel zu erreichen, zumindest konzeptionell wie das Finden eines Beweises für ein Theorem oder eines Synthesewegs für eine Chemikalie. Es gibt bestimmte "Schritte, die unternommen werden können", und es muss herausgefunden werden, wie diese "aneinandergereiht werden" können, um das gewünschte Ziel zu erreichen. Unvermeidlich gibt es jedoch ein Problem mit (multi-)komputationaler Irreduzibilität: Es kann eine irreduzible Anzahl von Schritten erforderlich sein, um zum Ergebnis zu gelangen. Und auch wenn das endgültige Ziel als "interessant" betrachtet wird, gibt es keine Garantie, dass die Zwischenschritte auch nur annähernd interessant gefunden werden. Tatsächlich benötigt man in vielen Beweisen – sowie in vielen technischen Systemen – eine immense Anzahl quälender Details, um zum finalen "interessanten Ergebnis" zu gelangen.
Aber mehr zur Frage, was untersucht werden soll – oder effektiv, was "interessant zu untersuchen" ist. "Normale Wissenschaft" tendiert dazu, inkrementellen Fortschritt zu machen, innerhalb bestehender Paradigmen zu bleiben, aber allmählich das Vorhandene auszufüllen und zu erweitern. Normalerweise sind die fruchtbarsten Bereiche an den Schnittstellen zwischen bestehenden, gut entwickelten Bereichen. Anfangs ist es überhaupt nicht offensichtlich, dass verschiedene Wissenschaftsbereiche überhaupt zusammenpassen sollten. Aber mit dem Konzept des Ruliads als ultimative zugrundeliegende Struktur beginnt dies weniger überraschend zu erscheinen. Dennoch, um tatsächlich zu sehen, wie verschiedene Wissenschaftsbereiche zusammengestrickt werden können, muss man oft – vielleicht zunächst überraschende – Analogien zwischen sehr unterschiedlichen Beschreibungsrahmen identifizieren. „Eine entscheidbare Theorie in der Metamathematik ist wie ein schwarzes Loch in der Physik“; „Konzepte in der Sprache sind wie Partikel im rulialen Raum“; et cetera.
Und dies ist ein Bereich, in dem LLMs hilfreich sein können. Hat man das „linguistische Muster“ eines Bereichs gesehen, kann man erwarten, dass sie dessen Entsprechung in einem anderen Bereich erkennen können – potenziell mit wichtigen Folgen.
Aber was ist mit völlig neuen Richtungen in der Wissenschaft? Historisch gesehen waren diese oft das Ergebnis der Anwendung einer neuen praktischen Methodik (sagen wir, für die Durchführung einer neuen Art von Experiment oder Messung) – die zufällig einen "neuen Ort zum Hinsehen“ eröffnet, wo vorher noch nie hingeschaut wurde. Aber oft ist eine der großen Herausforderungen zu erkennen, dass das, was man sieht, tatsächlich „interessant“ ist. Und dies enthält oft effektiv die Schaffung eines neuen konzeptuellen Rahmens oder Paradigmas.
Kann also KI – wie hier besprochen – dies leisten? Es scheint unwahrscheinlich. KI ist typischerweise etwas, das auf bestehendem menschlichem Material trainiert wird, um direkt daraus zu extrapolieren. Es ist nichts, das dazu gebaut ist, "in die Wildnis des Ruliads" vorzustoßen, weit entfernt von allem, was bereits mit Menschen verbunden ist.
Aber in einem Sinne ist das das Gebiet der "willkürlichen Berechnung" und von Dingen wie den einfachen Programmen, die in der Ruliologie aufgezählt oder zufällig ausgewählt werden könnten. Und ja, indem man in die "Wildnis des Ruliads" vordringt, ist es leicht genug, frische, neue Dinge zu finden, die aktuell nicht in die Wissenschaft integriert sind. Die Herausforderung besteht jedoch darin, sie mit irgendetwas zu verbinden, das Menschen aktuell "verstehen" oder "interessant finden". Und das, wie zuvor erwähnt, ist etwas, das quintessenziell menschliche Wahl und die Launen der menschlichen Geschichte betrifft. Es gibt eine unendliche Sammlung von Pfaden, die eingeschlagen werden könnten. (Und tatsächlich, in einer "Gesellschaft von KIs", könnten KIs eine bestimmte Sammlung davon verfolgen.) Aber am Ende zählt für uns Menschen und das Unternehmen, das wir normalerweise "Wissenschaft" nennen, unsere innere Erfahrung. Und das ist etwas, das wir letztendlich für uns selbst formen müssen.
Jenseits der "Exakten Wissenschaften"
In Bereichen wie den Naturwissenschaften ist die Entwicklung umfassender Theorien, die quantitative Vorhersagen machen können, eine vertraute Vorstellung. Doch viele Bereiche, zum Beispiel in den biologischen, humanen und sozialen Wissenschaften, haben tendenziell in viel weniger formalen Weisen operiert, und lange Ketten erfolgreicher theoretischer Schlussfolgerungen sind weitgehend unbekannt.
Könnte KI das ändern? Es scheinen sich interessante Möglichkeiten abzuzeichnen, insbesondere um die neuen Arten von "Messungen", die KI ermöglicht. "Wie ähnlich sind diese Kunstwerke?" "Wie nahe sind die Morphologien dieser Organismen?" "Wie unterschiedlich sind diese Mythen?" Das sind Fragen, die früher meist durch das Verfassen eines Essays angegangen wurden. Doch nun bietet KI potenziell einen Weg, solche Dinge definitiver und in gewissem Sinne quantitativer zu machen.
Typischerweise besteht die Schlüsselidee darin, herauszufinden, wie man "unstrukturierte Rohdaten" nimmt und "bedeutungsvolle Merkmale" daraus extrahiert, die auf formale, strukturierte Weisen gehandhabt werden können. Und das Hauptelement, das dies ermöglicht, ist, dass KIs vorhanden sind, die auf großen Korpora trainiert wurden, die das Typische in unserer Welt widerspiegeln – und die effektiv definitive interne Darstellungen der Welt gebildet haben, in Begriffen, in denen Dinge beispielsweise durch Listen von Zahlen beschrieben werden können.
Was bedeuten diese Zahlen? Am Anfang gibt es typischerweise keine Vorstellung; sie sind einfach das Ergebnis eines neuronalen Netzwerk-Encoders. Wichtig ist aber, dass sie eindeutig und wiederholbar sind. Bei gleichen Eingabedaten erhält man immer die gleichen Zahlen. Mehr noch, wenn Daten uns "ähnlich erscheinen", neigen wir dazu, ihnen Zahlen zuzuordnen, die nahe beieinander liegen.
In einem Bereich wie der Physik wird erwartet, spezifische Messgeräte zu bauen, die Größen messen, deren Interpretation "bekannt ist". Doch KI ist viel mehr eine Black Box: Es wird etwas gemessen, aber zumindest anfangs ist nicht notwendigerweise eine Interpretation davon vorhanden. Manchmal wird es möglich sein, ein Training durchzuführen, das eine bekannte Beschreibung verknüpft, sodass zumindest eine grobe Interpretation erhalten wird (wie im Fall einer Sentimentanalyse). Aber oft wird das nicht der Fall sein.
(Und es muss gesagt werden, dass etwas Ähnliches sogar in der Physik passieren kann. Angenommen, es wird getestet, ob ein Material die Oberfläche eines anderen kratzt. Vermutlich kann das als eine Art Härte des Materials interpretiert werden, aber wirklich ist es nur eine Messung, die Bedeutung erlangt, wenn sie erfolgreich mit anderen Dingen in Verbindung gebracht werden kann.)
Etwas, das besonders auffällig an "KI-Messungen" ist, ist, wie sie potenziell "kleine Signale" aus großen Mengen unstrukturierter Daten herausfiltern können. Man ist gewohnt, Methoden wie Statistik zu haben, um Ähnliches mit strukturierten, numerischen Daten zu tun. Doch es ist eine andere Geschichte, aus Milliarden von Webseiten zu fragen, ob etwa Kinder, die Wissenschaft mögen, typischerweise Katzen oder Hunde bevorzugen.
Doch gegeben eine KI-Messung, was kann damit erwartet werden zu tun? Nichts davon ist bisher sehr klar, doch es scheint zumindest möglich, dass formale Beziehungen gefunden werden können. Vielleicht wird es eine quantitative Beziehung involvierende Zahlen sein; vielleicht wird es besser durch ein Programm repräsentiert, das einen Berechnungsprozess beschreibt, durch den eine Messung zu anderen führt.
Es ist seit einiger Zeit üblich, in Bereichen wie der quantitativen Finanzwirtschaft, Beziehungen zwischen dem zu finden, was im Grunde einfache Formen von KI-Messungen sind – und hauptsächlich damit beschäftigt zu sein, ob sie funktionieren, anstatt warum sie funktionieren oder wie man sie narrativ beschreiben könnte.
In gewissem Sinne scheint es unbefriedigend, Wissenschaft auf "Black-Box"-KI-Messungen zu bauen, die nicht interpretiert werden können. Doch auf einer gewissen Ebene ist dies nur eine beschleunigte Version dessen, was oft gemacht wird, sagen wir mit alltäglicher Sprache. Eine neue Beobachtung oder Messung wird ausgesetzt und schließlich erfindet man Worte, um sie zu beschreiben ("es sieht aus wie ein Fraktal"). Und dann kann begonnen werden, "in Begriffen davon zu argumentieren", et cetera.
Doch KI-Messungen sind potenziell eine viel reichere Quelle formalisierbaren Materials. Doch wie sollte diese Formalisierung durchgeführt werden? Computergestützte Sprache scheint der Schlüssel zu sein. Und tatsächlich gibt es bereits Beispiele in der Wolfram Language – wo Funktionen wie ImageIdentity oder TextCases (oder, was das betrifft, LLMFunction) effektiv KI-Messungen machen können, aber dann können ihre Ergebnisse genommen und symbolisch damit gearbeitet werden.
In der Physik wird oft vorgestellt, nur mit "objektiven Messungen" zu arbeiten (obwohl meine jüngste Beobachtertheorie impliziert, dass eigentlich unsere Natur als Beobachter auch entscheidend ist). Doch KI-Messungen scheinen eine gewisse unmittelbare "Subjektivität" zu haben – und tatsächlich werden ihre Details (sagen wir, assoziiert mit den Besonderheiten eines neuronalen Netz-Encoders) für jede unterschiedliche KI, die verwendet wird, anders sein. Aber wichtig ist, dass, wenn die KI auf gewaltigen Mengen menschlicher Erfahrung trainiert wird, eine gewisse Robustheit zu ihr gehört. In gewissem Sinne können viele KI-Messungen wie die Ausgabe eines "gesellschaftlichen Beobachters" angesehen werden – der so etwas wie die gesamte Masse menschlicher Erfahrung nutzt und dadurch eine gewisse "Zentralität" und "Trägheit" gewinnt.
Welche Art von Wissenschaft kann erwartet werden, auf der Basis dessen zu bauen, was ein "gesellschaftlicher Beobachter" misst? Größtenteils ist das noch unbekannt. Es gibt einige Gründe zu denken, dass (wie im Fall der Physik und Metamathematik) solche Messungen in Taschen computergestützter Reduzibilität eindringen könnten. Und wenn das der Fall ist, kann erwartet werden, dass begonnen werden kann, Dinge wie Vorhersagen zu machen – wenn auch vielleicht nur für die Ergebnisse von KI-Messungen, die schwer zu interpretieren sein werden. Doch indem solche KI-Messungen mit computergestützter Sprache verbunden werden, scheint das Potenzial zu bestehen, "formalisierte Wissenschaft" an Orten zu konstruieren, wo das zuvor nie möglich war – und dadurch den Bereich dessen zu erweitern, was als "exakte Wissenschaften" bezeichnet werden könnte.
(Übrigens ist eine weitere vielversprechende Anwendung moderner KIs das Einrichten von "wiederholbaren Personas": Entitäten, die effektiv wie Menschen mit bestimmten Eigenschaften agieren, aber an denen großangelegte wiederholbare Experimente der Art, wie sie in der Physik typisch sind, durchgeführt werden können.)
Kann KI also Wissenschaft lösen?
Zu Beginn könnte es überraschend erscheinen, dass Wissenschaft überhaupt möglich ist. Warum gibt es Regelmäßigkeiten, die wir in der Welt identifizieren können, die es uns erlauben, "wissenschaftliche Narrative" zu bilden? Tatsächlich wissen wir heute durch Konzepte wie den Ruliad, dass die rechnerische Irreduzibilität unvermeidlich allgegenwärtig ist – und damit fundamentale Unregelmäßigkeit und Unvorhersehbarkeit. Es stellt sich jedoch heraus, dass die reine Präsenz der rechnerischen Irreduzibilität notwendigerweise impliziert, dass es Bereiche gibt, in denen zumindest bestimmte Dinge regelmäßig und vorhersagbar sind. Und es ist innerhalb dieser Bereiche der Vorhersagbarkeit, wo die Wissenschaft fundamental existiert – und tatsächlich versuchen wir, mit der Welt zu operieren und zu interagieren.
Wie steht es also um die Künstliche Intelligenz? Die Entwicklung trainierter neuronaler Netze, die hier besprochen wurde, basiert auf dem Nutzen rechnerischer Vorhersagbarkeit. Diese Form der Vorhersagbarkeit entspricht auf interessante Weise den Prozessen, die auch der menschliche Verstand anwendet. In der Vergangenheit war der Hauptweg, um rechnerische Vorhersagbarkeit zu erfassen – und davon zu profitieren –, formale Wege zu entwickeln, um Dinge zu beschreiben, typischerweise unter Verwendung von Mathematik und mathematischen Formeln. KI bietet effektiv eine neue Möglichkeit, rechnerische Vorhersagbarkeit zu nutzen. Normalerweise gibt es keine menschliche Narrative dazu, wie es funktioniert; es ist einfach so, dass irgendwie innerhalb eines trainierten neuronalen Netzes bestimmte Regelmäßigkeiten erfasst werden, die es uns ermöglichen, bestimmte Vorhersagen zu treffen.
In gewissem Sinne neigen die Vorhersagen dazu, sehr "menschlich" zu sein, oft wirken sie "ungefähr richtig" für uns, auch wenn sie auf der Ebene präziser formaler Details nicht ganz richtig sind. Und grundsätzlich verlassen sie sich auf rechnerische Vorhersagbarkeit – und wenn rechnerische Irreduzibilität vorhanden ist, scheitern sie mehr oder weniger unvermeidlich. In gewissem Sinne führt die KI "oberflächliche Berechnungen" durch, aber bei rechnerischer Irreduzibilität benötigt man irreduzible, tiefe Berechnungen, um herauszufinden, was passieren wird.
Und es gibt viele Bereiche – selbst beim Arbeiten mit traditionellen mathematischen Strukturen –, wo das, was KI tut, nicht ausreichen wird für das, was von der Wissenschaft erwartet wird. Aber es gibt auch Bereiche, wo "KI-Stil-Wissenschaft" Fortschritte machen kann, auch wenn traditionelle Methoden nicht können. Wenn man etwas wie das Lösen einer einzelnen Gleichung (sagen wir, eine ODE) präzise macht, ist KI wahrscheinlich nicht das beste Werkzeug. Aber wenn man eine große Sammlung von Gleichungen hat (sagen wir für etwas wie Robotik), kann KI erfolgreich in der Lage sein, eine nützliche "grobe Schätzung" dessen zu geben, was passieren wird, selbst wenn traditionelle Methoden völlig in Details stecken bleiben würden.
Es ist ein allgemeines Merkmal von Machine-Learning- und KI-Techniken, dass sie sehr nützlich sein können, wenn eine ungefähre ("80 %") Antwort gut genug ist. Aber sie tendieren dazu zu scheitern, wenn etwas präziser und "perfekter" benötigt wird. Und es gibt ziemlich viele Arbeitsabläufe in der Wissenschaft (und wahrscheinlich mehr, die identifiziert werden können), wo genau das benötigt wird. "Kandidatenfälle für etwas auswählen". "Ein Merkmal identifizieren, das wichtig sein könnte". "Eine mögliche Frage zum Erkunden vorschlagen".
Es gibt klare Grenzen, insbesondere wann immer rechnerische Irreduzibilität vorliegt. In gewissem Sinne beinhaltet der typische KI-Ansatz zur Wissenschaft nicht explizit "Dinge zu formalisieren". Aber in vielen Bereichen der Wissenschaft ist Formalisierung genau das, was am wertvollsten war, und was Türme von Ergebnissen ermöglicht hat. Und in letzter Zeit haben wir die kraftvolle neue Idee, Dinge rechnerisch zu formalisieren – und insbesondere computergestützte Sprache dafür zu nutzen.
Und mit einer solchen rechnerischen Formalisierung sind wir in der Lage, irreduzible Berechnungen zu starten, die uns Entdeckungen erreichen lassen, die wir nicht vorhersehen können. Wir können unter anderem mögliche rechnerische Systeme oder Prozesse aufzählen und "grundlegende Überraschungen" sehen. In typischer KI gibt es Zufälligkeit, die uns einen gewissen Grad an "Originalität" in unserer Erkundung gibt. Aber es ist von einem grundsätzlich niedrigeren Niveau, als wir mit tatsächlichen irreduziblen Berechnungen erreichen können.
Was können wir also von der KI in der Wissenschaft in Zukunft erwarten? Wir haben in gewissem Sinne eine neue – und eher menschenähnliche – Möglichkeit, rechnerische Vorhersagbarkeit zu nutzen. Es ist ein neues Werkzeug für die Wissenschaft, bestimmt, viele praktische Anwendungen zu haben. In Bezug auf das fundamentale Potenzial für Entdeckungen verblassen sie jedoch im Vergleich zu dem, was wir aus dem rechnerischen Paradigma und aus irreduziblen Berechnungen, die wir durchführen, aufbauen können. Aber wahrscheinlich wird uns die größte Möglichkeit, die Wissenschaft voranzubringen, die Kombination der Stärken von KI und des formalen rechnerischen Paradigmas bieten. Was, ja, Teil dessen ist, was wir in den letzten Jahren mit der Wolfram Language und ihren Verbindungen zum maschinellen Lernen und jetzt LLMs energisch verfolgt haben.
Abschließende Anmerkungen
Mein Ziel war es, meine derzeitigen Überlegungen über das grundlegende Potenzial (und die Grenzen) der KI in der Wissenschaft zu skizzieren. Ich habe meine Ideen entwickelt, indem ich die Wolfram Language und ihre KI-Funktionen für verschiedene einfache Experimente verwendet habe. Ich betrachte das, was ich hier getan habe, nur als einen Anfang. Im Grunde könnte jedes Experiment viel detaillierter und mit viel mehr Analysen durchgeführt werden. (Und klicken Sie einfach auf ein beliebiges Bild, um die Wolfram Language aufzurufen, mit der es gemacht wurde, damit Sie es wiederholen oder erweitern können).
"Künstliche Intelligenz in der Wissenschaft" ist heutzutage in der ganzen Welt ein heißes Thema, und ich bin mir sicher, dass ich nur einen kleinen Teil von all dem kenne, was gemacht worden ist. Ich selbst habe mich darauf konzentriert, "die offensichtlichen Experimente durchzuführen" und zu versuchen, mir ein Bild von dem zu machen, was vor sich geht. Ich sollte betonen, dass es in letzter Zeit einen regelmäßigen Strom herausragender und beeindruckender echnischer Innovationen im Bereich der KI gegeben hat. Ich wäre überhaupt nicht überrascht, wenn Experimente, die für mich nicht gut funktioniert haben, durch künftige derartige Innovationen dramatisch verbessert werden könnten, was möglicherweise sogar meine Schlussfolgerungen aus dem "großen Bild" verändern würde.
Ich muss mich auch entschuldigen. Obwohl ich – wenn auch oft nur "durch die Gerüchteküche" – von vielen Dingen erfahren habe, die sich mit "KI in der Wissenschaft" befassen, vor allem im letzten Jahr, habe ich keinen ernsthaften Versuch unternommen, die Literatur auf diesem Gebiet systematisch zu studieren. Ich habe es auch nicht versucht, seine Geschichte und die Herkunft der Ideen darin nachzuvollziehen.
Ich muss es also anderen überlassen, Verbindungen zwischen dem, was ich hier getan habe, und dem, was andere Leute anderswo getan haben (oder auch nicht), herzustellen. Es wäre faszinierend, eine ernsthafte Analyse der Geschichte der KI in der Wissenschaft vorzunehmen, aber dazu hatte ich bisher keine Gelegenheit.
Bei meinen Bemühungen wurde ich in hohem Maße von den Wolfram Institute-Stipendiaten Richard Assar ("Ruliad Fellow") und Nik Murzin ("Fourmilab Fellow") unterstützt. Ich bin auch den vielen Menschen dankbar, mit denen ich in letzter Zeit über KI in der Wissenschaft (und verwandte Themen) gesprochen oder von ihnen gehört habe, darunter Giulio Alessandrini, Mohammed AlQuraishi, Brian Frezza, Roger Germundsson, George Morgan, Michael Trott und Christopher Wolfram.
Ein Hinweis: Wenn Sie im englischsprachigen Originalartikel "Can AI Solve Science?" [15] auf ein beliebiges Diagramm klicken, erhalten Sie den Code in Wolfram Language, um die Ergebnisse zu reproduzieren. Der Code zum Trainieren der verwendeten neuronalen Netze ist ebenfalls verfügbar (setzt eine GPU voraus).

 [16]
[16](vza [17])
URL dieses Artikels:
https://www.heise.de/-9650643
Links in diesem Artikel:
[1] https://writings.stephenwolfram.com/2024/03/can-ai-solve-science/
[2] https://www.heise.de/hintergrund/Missing-Link-Stephen-Wolfram-ueber-die-Rolle-der-KI-in-der-Forschung-Teil-1-9649315.html
[3] https://www.heise.de/thema/Kuenstliche-Intelligenz
[4] https://www.heise.de/hintergrund/P-vs-NP-Wie-Forscher-die-letzte-Frage-der-Informatik-beantworten-wollen-6660037.html
[5] https://www.heise.de/thema/Missing-Link
[6] https://www.wolfram.com/language/
[7] https://writings.stephenwolfram.com/2021/11/the-concept-of-the-ruliad/
[8] https://www.wolframscience.com/metamathematics/
[9] https://de.wikipedia.org/wiki/Champernowne-Zahl
[10] https://www.heise.de/hintergrund/Missing-Link-Stephen-Wolfram-ueber-die-Rolle-der-KI-in-der-Forschung-Teil-1-9649315.html?seite=6
[11] https://reference.wolfram.com/language/ref/ImageIdentify.html
[12] https://www.wolfram.com/knowledgebase/
[13] https://de.wikipedia.org/wiki/Idempotenz
[14] https://writings.stephenwolfram.com/2023/07/generative-ai-space-and-the-mental-imagery-of-alien-minds/#the-images-of-interconcept-space
[15] https://writings.stephenwolfram.com/2024/03/can-ai-solve-science/
[16] https://www.heise.de/newsletter/anmeldung.html?id=ki-update&wt_mc=intern.red.ho.ho_nl_ki.ho.markenbanner.markenbanner
[17] mailto:vza@heise.de
Copyright © 2024 Heise Medien