

Plat_Forms 2011: Web-Entwicklungsplattformen im direkten Projektvergleich
Immer noch wird die Diskussion darüber, was die beste technische Plattform für die Webentwicklung sei, kaum mit sauberer Datengrundlage geführt. Plat_Forms ist ein wissenschaftlicher Wettbewerb, der das ändern will. Erstmals durchgeführt wurde er 2007, dieser Artikel berichtet von den Ergebnissen von 2011.
- Lutz Prechelt
- Ulrich Stärk

Immer noch wird die Diskussion darüber, was die beste technische Plattform für die Webentwicklung sei, kaum mit sauberer Datengrundlage geführt. Es gibt viel zu wenig Fälle, bei denen dieselbe Anwendung mehrmals mit unterschiedlichen Plattformen entwickelt wird – bestenfalls bekommt man isolierte Anekdoten geboten. Plat_Forms ist ein wissenschaftlicher Wettbewerb, der das ändern will. Erstmals durchgeführt wurde er 2007, dieser Artikel berichtet von den Ergebnissen von 2011, und im Oktober findet Plat_Forms 2012 statt.
An Plat_Forms 2011 nahmen pro Plattform (Java, Perl, PHP und Ruby) drei oder bevorzugt vier Teams von je drei professionellen Webentwicklern teil; nur hoch qualifizierte Teams wurden zugelassen. .NET, Python, Smalltalk und was auch immer man sonst vermissen mag fehlten nur deshalb, weil dafür nur ein, zwei beziehungsweise keine Bewerbungen eingegangen waren. Neben vier Java-, drei Perl-, vier PHP- und vier Ruby-Teams mit Teilnehmern aus vier Ländern haben die Ausrichter aus Neugierde ausnahmsweise und außer Konkurrenz ein einzelnes JavaScript-Team zugelassen, das sich achtbar schlug. Von serverseitigem Javascript wird zukünftig wohl noch mehr hören zu sein – der Artikel geht aber nicht darauf ein.
Alle Teams arbeiteten am selben Ort zur gleichen Zeit von 9 Uhr morgens bis am nächsten Tag 18 Uhr, mit acht Stunden Schlafpause, also 25 Stunden insgesamt; pro Team kamen also knapp zwei Personenwochen Arbeitsleistung zusammen. Alle Teams implementierten die gleiche, genau
spezifizierte Anwendung namens "Conferences and Participants" (CaP), ein kleines Community-Portal. Die Aufgabe bestand aus acht Use Cases:
- Benutzer registriert sich: das Übliche.
- Benutzer erzeugt eine Konferenz: mit Name, Zeitraum, Beschreibung, Kategorie und Ort inklusive GPS-Koordinaten.
- Benutzer browst Konferenzen: Durchstöbern der Listen von Kategorien, Unterkategorien und Konferenzen.
- Benutzer arbeitet mit Konferenzseite: Das zeigt die Daten einer einzelnen Konferenz samt einer Google-Maps-Karte an und erlaubt das Herunterladen als PDF und als iCalendar sowie das Abonnieren eines RSS-Feeds für Updates. Kontakte (siehe unten) und beliebige Personen (per E-Mail-Adresse) lassen sich einladen.
- Benutzer sucht eine Konferenz: Hierfür gibt es sowohl ein Suchformular mit Stichwortsuche und fünf anderen Kriterien als auch ein Textfeld, in dem sich mit einer vorgegebenen Syntax gleichwertige Suchformeln eingeben lassen.
- Mitglied (d. h. angemeldeter Benutzer) sucht nach Mitgliedern: Ein Suchdialog mit Stichwortsuche plus zwei weiteren Kriterien; an gefundene Mitglieder kann man Freundschaftsanfragen schicken (soziales Netz).
- Mitglied arbeitet mit seiner Statusseite: persönliche Daten, gesendete und empfangene Freundschaftsanfragen, Freunde, Benachrichtigungen.
- Mitglied administriert das Portal: Bearbeitung des Kategorienbaums, Einrichtung von Konferenzserien, Rechtevergabe und Anderes.
Die Abläufe sind durch 175 funktionale Anforderungen feinkörnig beschrieben; 143 betreffen das HTML-GUI, 32 die RESTful-Webservice-Schnittstelle, die ungefähr die gleichen Funktionen bereitstellt. Hinzu kommen 23 nichtfunktionale Anforderungen. Jede Anforderung ist als MUST, SHOULD oder MAY priorisiert. Die Teams erhielten neben dem Pflichtenheft einen kleinen Beispieldatenbestand im JSON-Format zum Erstbefüllen ihrer Datenbank.
Für zwei Personenwochen Aufwand ist das Pensum eigentlich viel zu groß, aber manche Teams sind trotzdem beinahe damit fertig geworden. Am Ende lieferte jedes Team einen lauffähigen Server (VMware), eine Quellcode-Distribution und sein Versionsarchiv ab, und die Veranstalter werteten das Material viele Monate lang an der Freien Universität Berlin wissenschaftlich aus (der Wettbewerb war im Januar 2011, aber die Auswertung läuft immer noch weiter).
Ergebnisse
Aus wissenschaftlicher Sicht waren die Forscher bei der Auswertung an allen Eigenschaften interessiert, die innerhalb einer Plattform X ziemlich homogen sind, über Plattformgrenzen hinweg jedoch verschieden – also an emergenten Eigenschaften der Plattform X.
Produktivität
Für die meisten Webentwickler ist die spannendste Frage die nach der Produktivität. Hierfür haben für jede Entwicklung zwei Gutachter jede der GUI-Anforderungen sorgfältig durch Tests geprüft und in fünf Stufen bewertet:
- 0:fehlt,
- 1:unvollständig,
- 2:funktioniert schlecht,
- 3:funktioniert, und
- 4:funktioniert und ist toll.
Die Bewertungen 1, 2, und 4 wurden nur selten vergeben. Meinungsverschiedenheiten wurden ausdiskutiert. Für die Webservice-Schnittstelle wurde die Prüfung mit einem Testklienten voll automatisiert. Für die Produktivität haben die Forscher alle Anforderungen gezählt, die bei einer Entwicklung mindestens als Stufe 2 bewertet waren. Das Ergebnis ist in Abbildung 1 zu sehen.
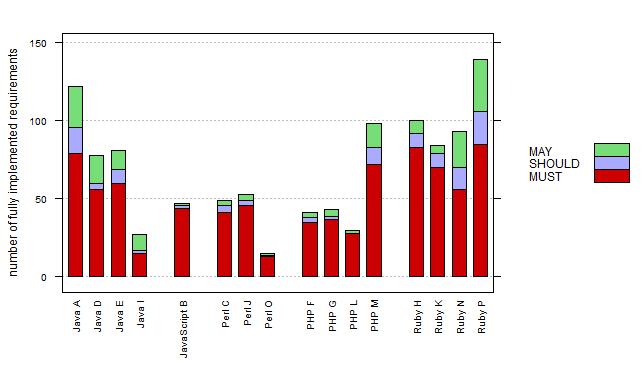
Erkenntnis 1: Ruby war die produktivste Plattform.
Das ist absichtlich in der Vergangenheitsform formuliert, damit man es hoffentlich nicht so leicht verallgemeinert, denn natürlich muss das mit anderen Teams, anderen Softwareanforderungen oder anderen Projektformaten nicht immer so aussehen.
Schon 2007 waren die großen Unterschiede zwischen den Java-Teams ähnlich aufgetreten. Die vermeintliche Katastrophe bei Team Perl O ist hingegen ein Ausrutscher: Die Perl-Teams kamen nicht komplett von einzelnen Firmen, sondern hatten sich im Netz zusammengefunden, und Team O bestand versehentlich nur aus Backend-Spezialisten. Prompt sind zwar unter der Haube viele Funktionen angelegt, fast nichts davon aber in der GUI auch zugreifbar; der Balken zeigt fast nur Webservice-Anforderungen. Interessant ist die Entwicklung bei PHP: Es hatte 2007 durch eine faszinierend gleichmäßige Produktivität der damals drei Teams bestochen, sogar noch mehr als hier bei Teams F, G und L zu sehen. Team PHP M durchbricht diesen Effekt gründlich. Diese und noch andere Beobachtungen interpretieren die Forscher als
Erkenntnis 2: Die Plattformen haben sich seit 2007 erheblich verändert.
Das bedeutet zum Beispiel, dass man Vorurteile, die noch aus der Bronzezeit der Webentwicklung stammen, dringend aufgeben sollte. Auf der Suche nach der Erklärung für die hohe Produktivität bei Team PHP M stößt man auf das Framework als wahrscheinliche Ursache: Einzig Team M hat Symfony 1 eingesetzt, und dieses Framework eifert dem für das CaP-Portal offenbar hoch produktiven Vorbild Ruby on Rails nach. Aus der Natur dieses Ausreißers PHP M ergibt sich also die
Erkenntnis 3: Man sollte Plattformen eigentlich nicht einfach nach der Programmiersprache unterteilen.
Als Konsequenz daraus arbeiten die Organisatoren für Plat_Forms 2012 derzeit an einer Klassifizierung nach Framework-Typ. Leider weiß bislang niemand, was das konkret heißen soll ...
Robustheit/Sicherheit
Als ein zweites wichtiges Kriterium interessiert bei Webanwendung deren Sicherheit. Leider ist eine White-Box-Sicherheitsprüfung (d. h. durch Analyse des Quellcodes) nicht so hinzubekommen, dass sie garantiert über alle Plattformen hinweg gleich gründlich ist. Ungleiche Gründlichkeit wäre jedoch unfair. Etwas schwächer gilt das gleiche Argument für Penetrationstests durch Experten, denn auch hierfür wird eine genaue Kenntnis der Funktionsweise der Plattform (z. B. API der Datenbankanbindung) eingesetzt.
Folglich hat man sich auf eine viel einfachere Teillösung zurückgezogen: Es wurden lediglich strikt standardisierte Robustheitsprüfungen auf der GUI durchgeführt und die beobachteten Symptome berichtet. Das Ergebnis ist in Abbildung 2 gezeigt.
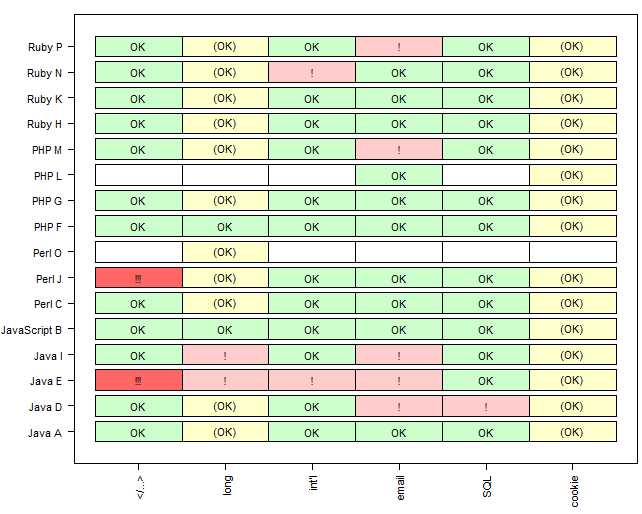
Keine Plattform kommt ganz ohne Makel davon, aber insgesamt ist die Robustheit klar besser gegenüber den Resultaten des gleichen Tests 2007. An Plattformunterschieden lesen die Forscher aus dem Bild die:
Erkenntnis 4: Hohe Robustheit scheint bei Java mühseliger zu sein als auf den Skriptsprachen-Plattformen.
Allerdings zeigt Team Java A (das mit einem kommerziellen Framework antrat), dass das kein grundsätzliches Problem ist.
Umfang des Codes
Ein drittes wichtiges Kriterium ist die Wartbarkeit und Fortentwickelbarkeit einer Anwendung. Leider ist hierfür eine plattformübergreifend faire Bewertung eher noch schwieriger als bei der Sicherheit. Deshalb sei auch hier auf ein einfaches Kriterium zurückgezogen, das sich fair analysieren lässt und zumindest einen Hinweis gibt, und zwar den Umfang des Quellcodes. Ein großer Code verursacht tendenziell mehr Verstehensaufwand während späterer Änderungen. (Überkompakten, unlesbaren Write-only-Code haben Teams nicht produziert.)
Da der Codeumfang mit der Menge implementierter Funktionen ansteigt, wurde er nicht direkt, sondern in Beziehung zur Zahl realisierter Anforderungen betrachtet. Gezählt haben die Forscher Zeilen, ohne Leer- und Kommentarzeilen, und das nur für Dateien, an die die Teams wirklich Hand anlegten; unverändert wiederverwendete oder generierte und dann nicht modifizierte Dateien zählen also nicht mit. Diese Klassifikation der Dateien erfordert wieder viel sorgfältige Fleißarbeit. Das Ergebnis zeigt die Abbildung 3.
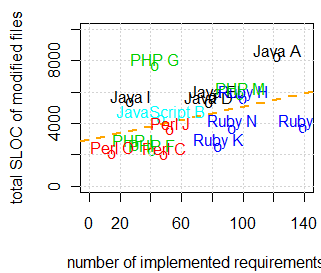
Entscheidend ist hier die Lage relativ zur Trendlinie: 'Darüber' heißt, es gibt relativ viel Code, 'darunter' bedeutet relativ wenig Code.
Erkenntnis 5: Die Umsetzungen in Perl und Ruby haben eher wenig Codeumfang, die in Java eher viel.
Interessant ist auch die relativ geringe Steigung der Trendlinie: Rechnerisch sind Entwicklungen mit null Funktionen immer noch halb so groß wie solche mit 140 erfüllten Anforderungen. Das ergibt die
Erkenntnis 6: Noch immer erfordern Webanwendungen im Durchschnitt ziemlich viel Gerüstcode.
Fazit
Einzelheiten des Entwicklungsprozesses
Sicherlich gibt es noch eine Menge interessanter Eigenschaften, die man untersuchen könnte. Bei einigen davon haben das die Forscher getan, aber nichts Berichtenswertes gefunden. Bei anderen ist die Untersuchung zu aufwendig oder scheitert an den Randbedingungen. Zum Beispiel ließ sich die Effizienz und Skalierbarkeit der Entwicklungen deshalb nicht untersuchen, weil es keine sinnvollen Benutzungsszenarien gibt, deren Funktionen in allen 16 Anwendungen umgesetzt sind.
Was hingegen mit interessantem Ergebnis noch ausgewertet wurde, sind ein paar Facetten des Verhaltens der Teams während der zwei Tage Entwicklungszeit. Zum Beispiel konnten die Teams zur Klärung der Anforderungen jederzeit Rückfragen an den Anforderungslieferanten stellen. Die Betreiber haben die Anzahl dieser Fragen gezählt, mit dem in Abbildung 4 zusammengefassten Ergebnis.
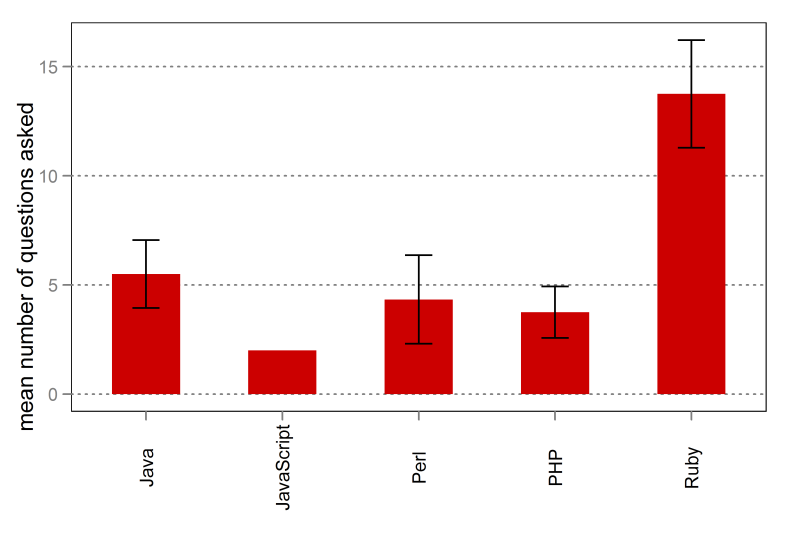
Wie man sieht, stellen die Ruby-Teams mit Abstand die meisten Fragen und die Java-Teams die zweitmeisten. Verblüffend daran: Das ist die gleiche Rangordnung wie bei der Produktivität. Die Bedeutung der Beobachtung ist allerdings mehrdeutig; von "Die hatten einfach mehr Zeit zum Fragen übrig" oder "Die sind besser zu den Feinheiten vorgedrungen, bei denen solche Fragen aufkamen" (d. h., Produktivität erzeugt quasi Fragen) über "kompetente Teams sind produktiv und stellen viele Rückfragen" (d. h., ein dritter Faktor erzeugt beides) bis hin zum radikalen "Wer seinen Kunden liebt und wirklich alles richtig machen will, ist auch produktiver" (d. h., Fragen erzeugen Produktivität) ist vieles denkbar.
Hochinteressant war noch ein Fundstück aus der Aktivitätsverfolgung. Die Forscher haben jeden Teilnehmer alle 15 Minuten gefragt: "Was haben Sie jetzt eben gerade getan", und die Antwort darauf war einer von 21 Aktivitätstypen wie "lese Anforderungen", "lese Dokumentation", "schreibe Code", "teste", "mache Pause" und "diskutiere mit Teamkollegen". Sowohl die Gesamthäufigkeit als auch der zeitliche Häufigkeitsverlauf waren bei den meisten Aktivitätstypen nicht auffällig verschieden zwischen den Plattformen. Eine Ausnahme bilden die drei Tätigkeiten "teste manuell", "schreibe automatisierten Test" und "lasse automatisierten Test ablaufen". Deren Häufigkeiten sahen nämlich aus wie in Abbildung 5 zusammengefasst.
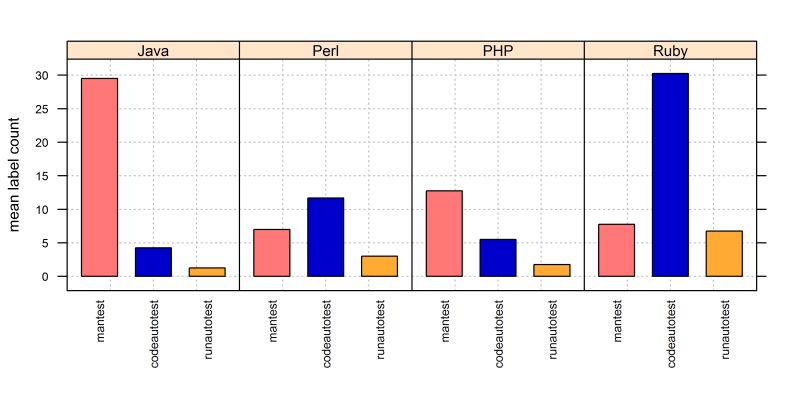
Zwei Beobachtungen stechen ins Auge:
- Die Ruby-Teams verwandten mehr Zeit auf automatische Tests als alle anderen zusammen.
- Die Java-Teams verwandten mehr Zeit auf manuelle Tests als alle anderen zusammen.
Zwei Schlussfolgerungen lassen sich daraus ableiten. Die erste ist interessant für alle, die hohe Testautomatisierung für oftmals zu aufwendig halten:
Erkenntnis 7: Selbst ohne längere Fortentwicklung des Produkts kann hohe Testautomatisierung offenbar sehr produktiv sein (siehe Ruby).
Die zweite richtet sich an die Gruppe all derer, die gegenteilig glaubt, allein automatische Tests machten selig:
Erkenntnis 8: Zumindest wenn längere Fortentwicklung des Produkts nicht nötig ist, kann manuelles Testen offenbar sehr produktiv sein (siehe Java).
Fazit
Im Datenmaterial steckt sicherlich noch einiges, das noch nicht zu Tage befördert wurde, aber von den bisher untersuchten Aspekten waren dies die wichtigsten Resultate. Wie 2007 fanden die Forscher, dass der Wettbewerb aus wissenschaftlicher Sicht ergiebig war, und auch die Teams waren von ihrer Teilnahme wieder begeistert. Mindestens die Siegerfirmen auf jeder Plattform freuen sich zudem über das tolle Marketingmaterial, das sie dadurch in Händen halten. Sponsoren für Plat_Forms 2011 waren Accenture, Microsoft, ICANS und vor allem die Deutsche Forschungsgemeinschaft.
Lutz Prechelt
ist Professor für Software Engineering am Institut für Informatik der Freien Universität Berlin. Seine Forschung betrifft überwiegend den Bereich Softwareprozesse, insbesondere agile Softwareprozesse, und darin vor allem die Paarprogrammierung, die verteilte Paarprogrammierung und das zugehörige Werkzeug Saros. Interessenschwerpunkt sind meist die psychologischen und soziologischen Aspekte.
Ulrich Stärk
ist wissenschaftlicher Mitarbeiter in der AG Software Engineering an der Freien Universität Berlin, war 2007 an der Auswertung von Plat_Forms beteiligt und ist verantwortlich für die Planung, Durchführung und Auswertung von Plat_Forms 2011 und 2012.
Plat_Forms 2012
Plat_Forms ist eine Kooperation von Freie Universität Berlin, Open Source Business Foundation und dem Heise Verlag. Bewerbungen für Plat_Forms 2012 sind noch bis 14. September möglich, für Einzelheiten siehe die Website. In diesem Jahr wird die Aufgabe weniger umfangreich sein, sodass der Fokus viel mehr auf der Qualität in ihren vielen Facetten als wie bisher vorrangig auf der Produktivität liegen wird.
Was alles dafür sprechen könnte, als Team dabei sein zu wollen:
- Plat_Forms ist lehrreich; das fanden bisher alle, die mitgemacht haben. Mehrere Teams sagten sogar, sie hätten in den dichten zwei Tagen des Wettbewerbs mehr über ihr Team und ihre Plattform gelernt als sonst in einem kompletten Projekt.
- Die wissenschaftliche Auswertung gibt glaubwürdiges Marketing-Material an die Hand.
- Die Einsichten aus dem Wettbewerb sind hoch relevant für die Praxis. Für Entwickler wie auch Entscheidungsträger beim Kunden oder Lieferanten ist das Wissen darüber, was beim Einsatz einer bestimmten Technik tatsächlich zu erwarten ist, unschätzbar. Teilnehmende Firmen verstehen die Einsichten sicherlich viel besser als Außenstehende.
- Und nicht zu vergessen der Spaßfaktor eines Wettkampfs: Die Teams können sich mit anderen Entwicklern messen.
(ane)
