Qualitätssicherung ausgewogen
Eine zentrale Maßnahme zur Sicherung der Qualität während der Softwareentwicklung ist das Testen. Wichtig ist hierbei eine passende Mischung aus automatisierten und manuell durchgeführten Tests zu finden - Techniken wie TDD und ATDD können helfen.


Die Geschichte der Softwareentwicklung ist eine Geschichte voller Missverständnisse. Diese drehen sich besonders um den Begriff Qualität und wie man sie absichert. Eine der wichtigsten Maßnahmen ist es, die richtigen Tests zu automatisieren und die richtigen Tests weiterhin manuell durchzuführen. Um den passenden Kompromiss zwischen beidem zu finden, können Techniken wie Test-, Acceptance-Test- und Behaviour-Driven-Development in Kombination mit explorativem Testen helfen.
Im 21. Jahrhundert gelten andere Standards für Softwareentwicklung als in den Pionierjahren der Informationstechnik. Lange schon arbeiten Softwareentwickler nicht mehr mit 0en und 1en, Lochkarten oder prozeduralem Code. Stattdessen gehören objektorientierte Programmiersprachen mit ihren zahlreichen Frameworks zum Berufsalltag.
In der Frühzeit der Computerevolution war vieles ganz anders. Durch niedrige Personal- im Verhältnis zu den Hardwarekosten war Rechenzeit wertvoll, und Programme wurden akribisch von Hand geprüft [1]. Hier bereits entstanden die ersten Ansätze zum Unit-Testing. Der einzige Unterschied zur heutigen Praxis ist, dass die Programme von Hand durchgespielt wurden und Entwickler kein komfortables Unit-Test- Framework wie JUnit zur Verfügung hatten, das die Arbeit automatisieren konnte.
Doch warum testen Entwickler heute überhaupt noch? Schließlich ist die Rechenzeit um einiges günstiger geworden, und sollte die Möglichkeit bestehen, auf eine eigene Testabteilung zurückgreifen zu können, muss sich auch nicht mehr um die Qualität gesorgt werden. Allerdings wäre das ein wenig kurz gedacht: Eine nachgelagerte Testabteilung nimmt vielleicht ein wenig Arbeit ab, dafür kommt aber die Information, dass etwas am vorgelegten Programm kaputt ist, viel zu spät beim Entwickler an. Bis zur Rückmeldung ist er vielleicht schon drei Aufgaben weiter und kann sich vermutlich nur noch vage an den alten Code erinnern. Aus diesem Grund sollte die abgelieferte Arbeit bereits größtmögliche Qualität besitzen und die Qualitätssicherung im Idealfall keine Fehler mehr finden.
Das klingt alles schön und gut. Aber wie ist dem im echten Leben nachzukommen? Dort gibt es Projektdeadlines, Druck von oben und vom Kunden und eine Menge Fehler, die dem Produktivsystem entspringen. Zusätzliche Zeit zum Testen ist da kaum vorhanden. Langfristig ist es aber schwer, ohne Testen dem Teufelskreis zu entfliehen, denn je mehr Bugs produziert werden, desto mehr Druck baut sich auf. Umso wahrscheinlicher wird es auch, dass Entwickler mehr "Abkürzungen" im Code und in den Tests nehmen und mehr Fehler einbauen, was wiederum mehr Druck verursacht.
Auf lange Sicht hilft es nur, Abkürzungen zu vermeiden, da so zwar kurzfristig Deadlines eingehalten und Kunden milde gestimmt werden können, aber die Arbeit an Rückläufern und Ähnlichem wieder länger dauert. Werden hingegen die Zeit und der Aufwand in Kauf genommen, die eigene Arbeit mit Tests zu versehen und zu einem vernünftigen Design zu kommen, verringert sich die Arbeit merklich.
Die Mischung macht's
Das kritische Feedback vom Kunden bleibt nach wie vor wichtig, da sich häufig nur so Fehler in der Software aufdecken lassen. Allerdings wären möglichst frühe Rückmeldungen wünschenswert, denn je eher der Entwickler auf Softwarefehler stößt, desto geringer sind die Kosten durch Kontextwechsel und desto präsenter ist ihm der Code, der das Problem verursacht.
Wie lässt sich dieses Dilemma lösen? Maßnahmen wie Testautomatisierung, Continuous Integration, Test-driven Development und Acceptance Test-driven Development sowie exploratives Testen sind ein guter Ansatz. Testautomatisierung gibt hierbei kurzfristig das Feedback, das benötigt wird, um notwendige Verbesserungen einzuleiten. Durch Continuous Integration erhält der Entwickler regelmäßiges Feedback über den derzeitigen Stand des Projekts.
Testautomatisierung löst nicht alle Probleme, denn es lässt sich weder alles testen noch alles automatisieren. Beim sogenannten explorativen Testen geht es darum, die Fähigkeiten des menschlichen Gehirns - Assoziationsvermögen, Adaption und Lernen - beim Testen direkt einzusetzen. Die Lücken der Testautomatiserung können damit häufig geschlossen werden.
Durch einen Ansatz, der beides kombiniert, lässt sich sicherstellen, dass alle Risiken vor der Auslieferung adressiert wurden. Hat er sich etabliert, kann sogar damit begonnen werden, Tests zu entwickeln, bevor der entsprechende Code geschrieben ist.
Testgetriebene Entwicklung beeinflusst das Design des Codes, während Akzeptanztests das eigene Verständnis im Code durchzusetzender Anforderungen voranbringen. Richtig angewandt können alle diese Praktiken dabei helfen, langfristig die Qualität einer Arbeit zu erhöhen und der Zeitfalle zu entkommen.
Testautomatisierung
Arbeiten lassen
Testautomatisierung ist immer noch keine Praktik, die ausreichend weit verbreitet ist. Hintergrund dafür sind vermutlich schlechte Erfahrungen mit automatisierten Tests. Gerard Meszaros listet in seinem Buch "xUnit Test Patterns – Refactoring Test Code" [2] einige sogenannte Test Smells auf, die Probleme mit schlecht automatisierten Tests verdeutlichen.
Fragile Tests haben dabei vielerlei Ursachen. Zum einen können automatisierte Tests zu stark an die getesteten Klassen gebunden sein. Zum anderen sind zu viele Abhängigkeiten beispielsweise zum Dateisystem oder zu Drittsystemen wie der Datenbank ein häufiges Problem. Tests werden dadurch nicht nur langsam, sondern sind auch an die spezifischen Implementierungsdetails der Datenbank oder der Dateisystemstruktur gebunden. In einigen Fällen verhindern sie sogar notwendige Umstrukturierungen des Codes, wie bei Refactorings, statt diese mit konstruktivem Feedback zu unterstützen.
In der Praxis zeigt sich außerdem, dass Tests lesbar und ihre Ergebnisse eindeutig sein müssen. Ein Unit-Test, bei dem mehrere Minuten nachzuforschen ist, warum er nicht durchlaufen konnte, kann bei einer Testsuite von 2000 Testfällen schnell zu einem Problem werden. Schlagen dann noch mehrere Unit-Tests auf einmal fehl, ist häufig vergleichsweise viel Zeit in das Finden der Ursachen zu stecken. Tests, die ein einfaches Feedback darüber liefern, was an einer Software kaputt gegangen ist, helfen hingegen dabei, Fehler schnell zu beheben. Werden sie stets lauffähig gehalten, liegt auch kontinuierlich eine funktionierende Softwareversion vor, wodurch stets aktuelle Software lieferbar ist.
Ein Muster für gute Testautomatisierung ist das Arrange-Act-Assert-Muster, wobei ein Test in drei bis vier Phasen aufgeteilt wird. In der ersten Phase, dem Arrange, sind alle Vorbereitungen für den Test zu treffen: Der Entwickler baut die Testfixture zusammen, instanziiert alle abhängigen Objekte und bereitet den Test insgesamt vor. Danach folgt der Act-Teil des Tests, in dem es darum geht, eine Aktion auf dem zu testenden Objekt auszuführen. Dabei ist es wichtig, dass es sich um eine einzelne Aktion handeln sollte. Sonst hat der Test wieder mehrere Stellen, an denen er fehlschlagen kann, und ist im Fehlerfall aufwendiger zu analysieren. In der dritten Phase, Assert, helfen Assertions sicherzustellen, dass alle Nachbedingungen einer Funktion eingetroffen sind. In der Regel sollte ein guter Unit-Test nicht mehr als eine Assertion verwenden. Hin und wieder findet außerdem noch eine vierte Phase Verwendung: der TearDown. Hier müssen einige persistente Objekte nach dem Testlauf wieder aufgeräumt werden. Häufig ist das bei funktionalen Tests der Fall, die mehr als ein Objekt auf einmal heranziehen. Das kann beispielsweise bei Akzeptanztests der Fall sein oder bei Tests, die mehrere Schichten der Applikation durchlaufen. In dieser Phase ist durch das Wiederherstellen des Zustands, wie er vor dem Test war, dafür zu sorgen, dass alle folgenden Durchgänge fehlerfrei laufen können.
In der Act-Phase lässt sich zudem zwischen sogenannten Query- und Command-Methoden unterscheiden. Idealerweise sollte eine Funktion nur eines von beiden tun: entweder einen Wert zurückliefern oder das Objekt intern verändern. Bei den Query-Methoden speichert der Test den zurückgelieferten Wert in einer Variablen und prüft ihr gegenüber die Nachbedingungen. Bei einer Command-Methode verändert er den internen Zustand des Objekts und muss anschließend – gegebenenfalls unter Ausnutzung vorhandener Query-Methoden – die Nachbedingungen überprüfen.
Nicht zuletzt sind gute Unit-Tests kurz: Idealerweise sollten sie 20 Zeilen nicht übersteigen. So bleiben Tests auf einen Teilaspekt der Applikation fokussiert und im Fehlerfall lässt sich der Wirkungsort schnell feststellen (Abb. 1). In den meisten Fällen, in denen eine dieser Regeln – eine Assertion pro Testmethode, mehr als 20 Zeilen – verletzt wird, deutete der schlechte Test auf eine Designschwäche hin.
Meistens dauert es auch nicht lange, diese Schwäche zu entdecken und sie zu beheben. Die Unit-Tests sind hier ein Spiegel für die gute oder schlechte Qualität der Schnittstellen. Der erste Nutzer einer Klasse findet sich stets in den Unit-Tests, und wenn diese unfokussiert erscheinen, also viele offenbar unbeteiligte Objekte heranziehen müssen, deutet das darauf hin, dass auch der Produktivcode unfokussiert wird, sollte er die neue Klasse verwenden.
Die richtigen Schlüsse ziehen
Testautomatisierung allein ist bereits ein wichtiger Schritt in Richtung Softwarequalität. Langfristig wollen Entwickler jedoch häufig mit kontinuierlichem Feedback zu aktuellen Änderungen im Code arbeiten. Dies funktioniert im Team nur durch das regelmäßige Integrieren eigener Änderungen mit denen der Kollegen (Abb. 2). Continuous-Integration-Systems (CI) liefern dabei nicht nur Feedback darüber, ob die Software gebaut werden kann, sondern sind auch in der Lage, viele lästige Tätigkeiten zu übernehmen.
Neben dem Bauen von Applikationen können heutige CI-Systeme durch zusätzliche Plug-ins Metriken und Analysen ausführen. Ein Mindestmaß dabei ist, dass die Applikation gebaut werden können sollte und alle Unit-Tests ausgeführt werden. Teams, die schon firmer in Continuous Integration sind, setzen zudem auf Code-Abdeckung durch die Unit-Tests sowie statische Code-Analyse und lassen gegebenenfalls Artefakte nach einem erfolgreichen Build vom CI-System erzeugen und publizieren.
Für die Code-Abdeckung ist weniger das prozentuale Ziel sinnvoll, sondern die kontinuierliche Verbesserung. Allgemein unterscheidet man zwischen Line- und Branch-Coverage. Darüber hinaus gibt es die Klassen- und Methoden-Abdeckung, die in der Praxis aber häufig als weniger aussagekräftig angesehen wird.
Bei der Line-Coverage handelt es sich um den Prozentsatz an Codezeilen, den die Unit-Tests abdecken. Die Branch-Coverage hingegen beschreibt die Abdeckung von Zweigen, die im Ausführungspfad der Anwendung möglich sind. Hierbei wird darauf geachtet, dass bei jeder Bedingung im Code jeder alternative Pfad ebenfalls mit abgedeckt wird.
Eine Falle, in die viele Teams mit Coverage-Metriken laufen, ist, dass die Metrik selbst nichts darüber aussagt, ob für das Ergebnis einer Zeile Code auch eine entsprechende Assertion auftaucht. Zwar lassen sich durch Mutationen in den Unit-Tests deren Güte bewerten, allerdings sind derartige Messungen aufwendig, da das gesamte Testset mehrfach zu durchlaufen ist. Beim Mutationstesten werden einzelne Werte im Unit-Test, beziehungsweise dessen Assertions, verändert. Funktioniert der Test weiterhin, handelt es sich um ein sogenanntes False Positive – der Test läuft durch, obwohl er fehlschlagen müsste. Scheitert der Test jedoch, fängt er genau den Fehler ab, den er finden soll.
TDD und ATDD
Bei statischer Codeanalyse werden häufig Tools wie FindBugs, FXCop oder Checkstyle eingesetzt, um den Code gegen applikationsunabhängige Fehler zu prüfen. Nicht abgedeckte Exceptions, offensichtliche Null-Pointer-Referenzen und ungenutzte Code-Fragmente lassen sich so gezielt finden. In der Regel sollte man sich jedoch nicht allein auf die statischen Codeanalysen beschränken, sondern die Metriken durch Paarprogrammierung ergänzen. Dadurch wird auch langfristig der Wissensaustausch im Team gefördert und Collective Code Ownership ermöglicht. Wenn jeder Programmierer im Team in der Lage ist, jede andere Codestelle zu ändern, entsteht eine ganze neue Form der Zusammenarbeit, da auf einmal nicht mehr Peters Code nicht mehr geht, sondern es sich um den Code aller Teammitglieder handelt.
Wie bei allen Metriken ist jedoch im Auge zu behalten, dass es nicht darum geht, die individuelle Leistung von Teammitgliedern zu messen oder beispielsweise Coverage-Metriken als Zielvorgabe für das Softwareentwicklungsteam zu verwenden. Cem Kaner und Walter P. Bond führen in "Software Engineering Metrics - What do they measure and how do we know?" [3] an, dass ein solches Verhalten zum Verfälschen und Austricksen der Metriken führt. So lassen sich Unit-Tests gezielt so anlegen, dass die prozentuale Abdeckung erreicht wird. Sie sind dann meist stark an die Applikationslogik gebunden, sodass es im Nachhinein schwer ist, den Code zu ändern, ohne den Test zu brechen. Stattdessen schlagen die Autoren vor, in die Ausbildung der Entwickler zu investieren und direkt mit ihnen am Code zu arbeiten.
Genug ist nicht genug
Wenn einmal ein Netz automatisierter Tests zusammen mit der kontinuierlichen Integration in Position gebracht ist, ist es nur noch ein kleiner Schritt zur testgetriebenen Entwicklung (TDD). Der Entwicklungszyklus beginnt dann mit einem kleinen, fehlschlagenden Test: Läuft ein Test nicht durch, darf gerade so viel Produktionscode geschrieben werden, dass er sich erfolgreich abschließen lässt. Anschließend sind Redundanzen im Code durch Refaktorisierungen zu reduzieren (Abb. 3). Den meisten Teams ist nicht bewusst, dass es sich auch bei Testautomatisierung um Softwareentwicklung handelt, wo der Testcode aufzuräumen ist, da man sonst schnell wieder vor dem Problem schlecht wartbarer Tests steht.
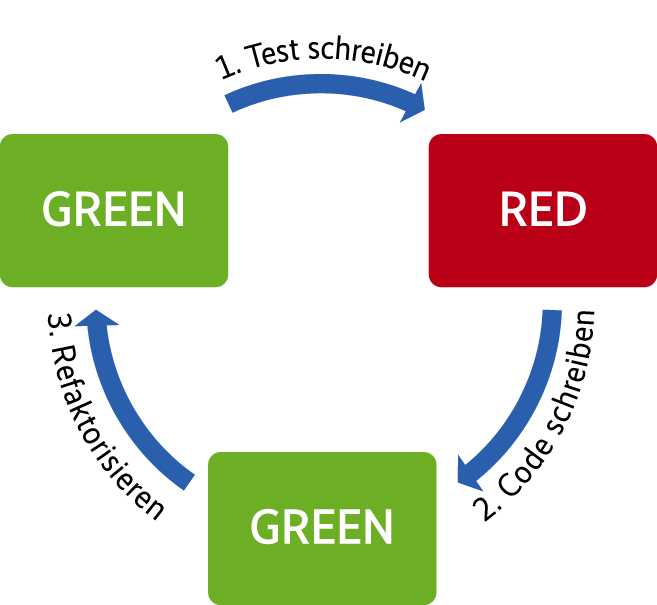
Dieser Ansatz erscheint zunächst dogmatisch, doch zum Lernen von testgetriebener Entwicklung ist er bewusst so gewählt. Wenn nach einiger Zeit Sicherheit in gewissen Bereichen eintritt, lässt sich auch versuchen, in größeren Schritten zu implementieren. Es sollte jedoch klar sein, dass ein zu großer Schritt das Risiko birgt, sich zu verrennen, und der Test dann nicht schnell wieder zum Laufen kommt. Tritt dieser Fall ein, sollte das Problem wieder in kleinere Einheiten heruntergebrochen und so gelöst werden.
Spezifikation mit Beispielen
Ein neuer Trend in den Entwicklungsmethoden geht derzeit in Richtung Acceptancetest-driven Development (ATDD) und Behavior-driven Development (BDD). Im Kern bezeichnet BDD die Vereinigung von TDD, ATDD, Domain-driven Design, Outside-In Development und der Verwendung einer ubiquitären Sprache, die durch Instrumente wie Spezifikations-Workshops entsteht. In der Praxis wird leider häufig ATDD mit BDD verwechselt.
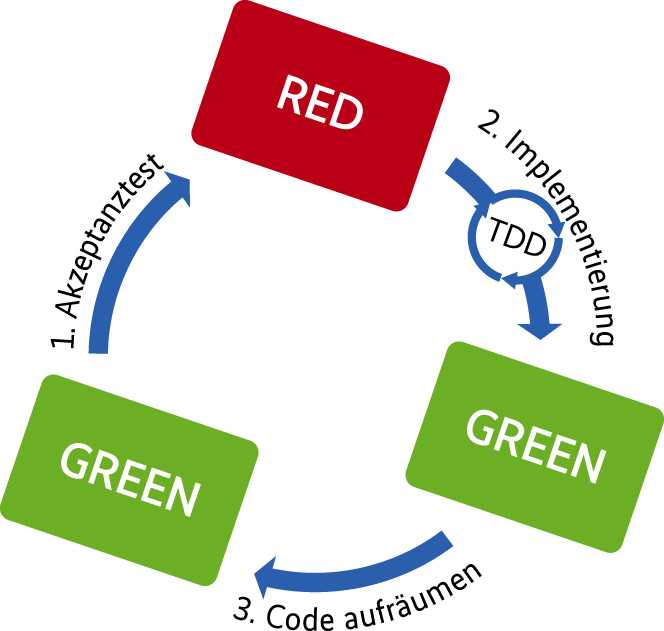
Bei ATDD (vgl. [4]) handelt es sich um eine Maßnahme, um Anforderungen möglichst korrekt im Code umzusetzen (Abb. 4). Die Arbeit beginnt hier bereits früh, noch während die eigentlichen Anforderungen definiert werden. Vertreter aus dem Entwicklungs- und dem Testteam kommen dann mit dem Kunden zusammen und identifizieren Akzeptanzkriterien für zukünftige Funktionen (Abb. 5). Dabei erlangen Tester und Programmierer ein gemeinsames Verständnis des Kundenbedürfnisses, wobei ein genügend großer Raum für unterschiedliche Designentscheidungen offen bleibt (vgl. [5]). Damit können Programmierer und Tester gemeinsam eine Lösung für das Problem des Kunden finden, mit der dieser langfristig zufrieden sein kann.
Ausgehend von den erwähnten Akzeptanzkriterien arbeitet das Entwicklungsteam zunächst an beschreibenden Beispielen, die sie vor dem Umsetzen der Funktion allerdings noch weiter verfeinern. Die Beispiele drücken dabei prägnant und exakt aus, was durch die Funktionen erreicht werden soll. Sie bewegen sich auf einem Level mit den Geschäftsanforderungen und sollten nichts mit Umsetzungsdetails wie der Position von GUI-Elementen zu tun haben.
Parallel zur Umsetzung der Funktionen arbeitet das Team dann daran, die Beispiele zu automatisieren. Einige Entwicklergruppen sind sogar in der Lage, die Geschäftslogik von den Geschäftsbeispielen ausgehend in ihren Domänencode zu integrieren. Die Literatur spricht hier von Outside-In Development: Die Entwicklung wird von außen nach innen getrieben. Dabei wird nur so viel Domänencode und Applikationslogik entworfen und geschrieben, wie unbedingt notwendig ist. Praktisch gibt es derzeit nur wenige Teams, die einen derartigen Reifegrad erreicht haben. Die Vorteile dieser Vorgehensweise sind allerdings nicht von der Hand zu weisen: Lässt sich schon vor dem Entwickeln belegen, dass die geplante Anwendung das ausführen wird, was sie soll, dann ist die Flexibilität gegenüber Änderungen in den Anforderungen langfristig gesichert.
Insgesamt bilden TDD und ATDD eine Symbiose, mit der sich ein hoher Grad an Testautomatisierung erreichen lässt. So ist durch ATDD eine Anforderungsabdeckung nahe 100 Prozent möglich, während mit TDD 100 Prozent Code-Abdeckung denkbar ist. In Kombination stellt TDD damit sicher, dass der Code richtig geschrieben wurde, während ATDD dafür sorgt, dass es auch der richtige Code ist.
Fazit
Gehirn einschalten nicht vergessen
Testautomatisierung und TDD sind kein Allheilmittel (vgl. [6]). Auch wenn sich ein hohes Maß an Abdeckung mit Techniken wie TDD und ATDD erreichen lässt, gibt es stets Risiken, die unabhängig davon anzugehen sind. Sie lassen sich nicht durch Automatisierung adressieren, sondern nur durch das kreative Gehirn eines guten Testers.
Beim explorativen Testen handelt es sich gleichzeitig um Testdesign, Testausführung und Lernen: Durch das Ausführen von Experimenten in Form von Tests ändert sich kontinuierlich das mentale Modell, dass der Entwickler von der zu testenden Software hat. Jede Aktion bestätigt oder widerlegt eine Hypothese, die zum Modell passt. Jede widerlegte Hypothese hingegen ist ein Signal, dass das Modell der Applikation noch nicht zu Ende gedacht ist.
Für exploratives Testen gibt es gute und weniger gute Vorgehensweisen, wobei sich gutes Testen durch die bewusste Nutzung von Testorakeln auszeichnet. Diese dienen dazu, eine Referenz für beobachtete Fehler zu haben. Beispielsweise kann eine Abweichung vom iOS-Plattform-Standard ein kritischer Fehler sein. Die Vorgaben von Apple dienen somit als Orakel für iOS-Applikationen. Außerdem existieren Fehler-Taxonomien, die applikationsunabhängige Fehlerquellen für verschiedene Anwendungsfelder beinhalten, wie unterschiedliche Zeichenketten, bei denen Fehler auftreten können.
Mehr Struktur erhalten explorative Tests durch sogenanntes Session-basiertes Testmanagement. Dabei wird die Testzeit in kleinere Abschnitte unterbrechungsfreien Testens geteilt. Diese Sessions können zwischen 30 und 120 Minuten lang sein. Damit in der Zeit der Fokus auf dem zu bearbeitenden Problem liegt, kann eine Testcharter helfen, die daran erinnert, wonach gerade zu suchen ist [7]. Jede Session hat dann einen gezielten Forschungsauftrag, der vor deren Beginn in der Charter hinterlegt wird – zum Beispiel am Ende einer Entwicklungsphase, vor dem Einchecken des Codes.

Qualität von Anfang an
Agile Softwareentwicklung hat das erste Jahrzehnt dieses Jahrhunderts geprägt. Vor allem durch die technischen Praktiken kann eine hohe Softwarequalität erzielt werden. Automatisierte Tests helfen dabei, den aktuellen Stand der Applikation stets transparent zu halten und Probleme in einer kurzen Feedbackschleife zu erkennen (Abb. 6).
Mit Hilfe von Continuous Integration lassen sich nicht nur die automatisierten Tests selbstständig ausführen, sondern auch Codemetriken über das Projekt ermitteln und Fortschritte – hoffentlich in positiver Richtung – beobachten. Mit TDD kann der Entwickler sicherstellen, dass der Code richtig implementiert ist, während ATDD oder BDD gewährleisten, dass am richtigen Code gearbeitet wird. Trotz massiver Automatisierung existieren noch Lücken in der Abdeckung. Sie lassen sich jedoch häufig durch gezielte explorative Tests schließen, womit letztlich viele Risiken in der Entwicklung vor der Auslieferung adressiert sind.
Markus [1] Gärtner [2]
arbeitet als testender Programmierer, Trainer, Coach und Berater für it-agile. Er gründete 2010 den German Agile Testing and Exploratory Workshop und steuert zur Softwerkskammer der deutschen Software-Craftsmanship-Bewegung bei.
Literatur
- Gerald M. Weinberg; How we used to do unit testing [3]; 2008
- Gerard Meszaros; xUnit Test Patterns – Refactoring Test Code; Addison-Wesley; 2007
- Cem Kaner, Walter P. Bond; Software Engineering Metrics – What do they measure and how do we know? [4]; 2004
- Markus Gärtner; ATDD by Example – A Practical Guide to Acceptance Test-driven Development; Addison- Wesley; 2012
- Gerald M. Weinberg, Don Gause; Exploring Requirements – Quality Before Design; Dorset House; 1989
- Frederick Brooks; The Mythical Man-Month; Addison-Wesley; 1985
- Elisabeth Hendrickson; Explore It! – Reduce Risk and Increase Confidence with Exploratory Testing; Pragmatic Programmers; 2012
(jul [5])
URL dieses Artikels:
https://www.heise.de/-1792246
Links in diesem Artikel:
[1] http://www.shino.de/blog
[2] http://www.mgaertne.de
[3] http://secretsofconsulting.blogspot.de/2008/12/how-we-used-to-do-unit-testing.html
[4] http://testingeducation.org/a/metrics2004.pdf
[5] mailto:jul@heise.de
Copyright © 2013 Heise Medien