Sorgfältiger als ChatGPT: Embeddings mit Azure OpenAI, Qdrant und Rust

(Bild: Shutterstock.com/calimedia)
Embeddings dienen dazu, die Essenz von Inhalten als Vektoren darzustellen. Vektordatenbanken helfen unter anderem dabei, ähnliche Inhalte effizient zu finden.
Wenn Menschen zum ersten Mal mit Large Language Models (kurz LLM) in Kontakt kommen, versteckt meist eine Benutzerschnittstelle die technischen Details der jeweiligen Umsetzung. Jemand gibt eine Frage in natürlicher Sprache ein und erhält als Ergebnis typischerweise eine Antwort in Textform oder ein generiertes Bild. Bei ChatGPT von OpenAI ermöglicht das LLM sogar das Führen eines Dialogs, bei dem der Computer den Chatverlauf kennt und bei Folgefragen berücksichtigt.
Hinter den Kulissen
Hinter der Fassade repräsentieren bei Sprachmodellen wie denen von OpenAI Zahlen die sprachlichen Zusammenhänge. Dabei spielt das Konzept der Embeddings eine entscheidende Rolle. Embedding-Vektoren stehen im Bereich der Künstlichen Intelligenz für die Zahlen-Repräsentationen des Inhalts wie Text, Bilder oder Musik. Technisch gesehen handelt es sich um Vektoren im n-dimensionalen Raum. Das Geheimnis der Qualität von Systemen wie ChatGPT ist, dass es ihnen äußerst gut gelingt, nicht nur die Wörter eines Textes oder einer Frage, sondern den Sinnzusammenhang in Vektoren umzuwandeln. Texte, deren Sinnzusammenhänge sich ähneln, führen zu Vektoren, die ähnlich sind. Texte, die nichts miteinander zu tun haben, resultieren in deutlich unterschiedlichen Vektoren.
Menschen können sich recht gut Vektoren im dreidimensionalen Raum vorstellen. Wenn die LLMs von OpenAI mit drei Dimensionen auskämen, was bei Weitem nicht der Fall ist, entstünden aus zwei Texten mit ähnlichem Inhalt zwei Vektoren, die in etwa an der gleichen Stelle im Raum enden. Das lässt sich beim Entwickeln von KI-Anwendungen nutzen. Anwendungen können Vektoren vergleichen, gruppieren oder sortieren, um beispielsweise Duplikate, Anomalien oder relevante Texte auf Basis von Fragen zu finden.
Im Folgenden dient eine praxisnahe Problemstellung dazu, das Konzept der Embeddings näher zu erläutern. Der skizzierte Lösungsansatz basiert auf den Sprachmodellen von OpenAI. Die entsprechenden Web-APIs holt sich die Anwendung nicht direkt bei OpenAI, sondern verwendet die im Januar 2023 vorgestellten Azure OpenAI Services [1], die speziell im Unternehmenseinsatz einige Vorteile haben. Unter anderem können Unternehmen den Ort der Datenverarbeitung auswählen (ein Rechenzentrum in der EU steht zur Verfügung) und die Anwendung in Enterprise-Netzwerkstrukturen einbinden – beispielsweise über Private Endpoints in virtuellen Netzwerken. Außerdem erfolgt die Abrechnung über bestehende Azure-Verträge und -Guthaben. Zum Speichern und Suchen der Embeddings nutzt das Anwendungsbeispiel die Open-Source-Vektordatenbank Qdrant der Berliner Firma Qdrant Solutions.
Gute Textgeneratoren mit Schwächen
Modelle wie ChatGPT haben bewiesen, dass sie Texte gut generieren und sogar Fragen beantworten können. Bei den Antworten zeigen sie jedoch Schwächen, da sie von Natur aus Textgeneratoren sind und daher nicht selten Dinge erfinden, die dank ihrer hoch entwickelten Generatorfähigkeiten sogar plausibel klingen. Ihre zweite Schwäche besteht darin, dass sie nicht allwissend sind. Erstens sind in das Training der Sprachmodelle naturgemäß keine Daten eingeflossen, die Firmen geheim halten, und zweitens haben die LLMs sogenannte Cut-off Dates. Darunter versteht man den Zeitpunkt, zu dem das jeweilige Modell trainiert wurde. Informationen, die erst später öffentlich geworden sind, könnte das System nur mit Plug-ins berücksichtigen, die ChatGPT in die Lage versetzen, Internetsuchen durchzuführen oder auf externe Web APIs zuzugreifen.
Zur näheren Untersuchung von Embeddings dient im Folgenden eine fiktive KI-Anwendung, die beide Nachteile weitgehend ausgleichen oder zumindest abmindern soll. Ziel ist es, auf Basis einer Frage in natürlicher Sprache die relevantesten Einträge in einer Wissensdatenbank zu finden. Anschließend dient Prompt Design dazu [2], die KI über ein LLM dazu zu bringen, die Frage anhand der Wissensdatenbank zu beantworten. Das Konzept, mithilfe eines vortrainierten LLM relevante Dokumente aus einer Datenbasis zu identifizieren und anschließend die Informationen als Kontext zum Beantworten einer Frage zu verwenden, wird oft als Retrieval-Augmented Generation (kurz RAG) bezeichnet. Der technische Aufbau sieht folgendermaßen aus:


Die Anwendung soll Embeddings für Textabschnitte aus einer Wissensdatenbank berechnen und in einer Vektordatenbank speichern. Zu Testzwecken dienen Ausschnitte aus dem Stanford Question Answering Dataset (SQuAD). Die Daten des Datensatzes finden sich bei Hugging Face [3]. SQuAD enthält eine umfangreiche Auswahl an Passagen aus Wikipedia-Artikeln mit jeweils zugehörigen Fragen und Antworten.
Unternehmen können für ihre Anwendung stattdessen eine firmenintern aufgebaute Wissensdatenbank verwenden. Der Autor hat dem SQuAD-Dataset Informationen über ein fiktives, chemisches Element namens Froxium hinzugefügt, weil das ChatGPT-LLM Fragen, die sich auf Wikipedia-Artikel beziehen, von Haus aus gut beantworten kann. Da Froxium frei erfunden ist, kann das LLM keine Informationen dazu haben. Der Testaufbau simuliert ein Szenario mit firmeninternen, nicht im Internet verfügbaren Informationen.
Folgenden Text hat das Sprachmodell dazu beispielhaft erzeugt, wohlgemerkt ohne die Angabe, dass die Eigenschaften sinnvoll sein müssen:
"Froxium is a member of the sideron family, a hypothetical group of super-heavy elements theorized to reside beyond the existing periodic table. Froxium exhibits a vibrant, iridescent hue that changes depending on the observer's emotional state. While it is a solid at room temperature, its melting point lies at a remarkable -42.7°C, which subsequently turns it into a shimmering, pearlescent liquid."
Nach dem Ermitteln der Embeddings für die Wissensdatenbank können User ihre Fragen eingeben. Die Anwendung gibt die Fragen jedoch nicht einfach unverändert an ein LLM wie ChatGPT. Stattdessen ermittelt sie den Embedding-Vektor für die Frage und sucht anhand eines Vektorvergleichs jene Einträge aus der Wissensdatenbank, die der Frage am ähnlichsten sind und daher aller Wahrscheinlichkeit nach die Antwort auf die Frage enthalten.
Den Textabschnitt aus der Wissensdatenbank gibt die Anwendung gemeinsam mit der eingegebenen Frage über Prompt Design an OpenAIs jüngstes, aktuell in der Preview-Phase befindliches Text-Completion-Modell GPT-4 weiter, um eine Antwort zu finden. Falls das LLM die Antwort nicht von den Fakten ableiten kann, soll das Modell keine Antwort geben.
Abbildung 2 zeigt das Prinzip der Abfrage mit Prompt Design im Azure OpenAI Studio. Aus der Abbildung geht hervor, dass das Modell-Deployment in den USA erfolgt. Der Grund dafür ist, dass das GPT-4-Modell in der aktuellen Preview-Phase nur dort zum Testen bereitsteht. Die produktiv verfügbaren Modelle sind dagegen ebenfalls im Azure-Rechenzentrum "West Europe" verwendbar.
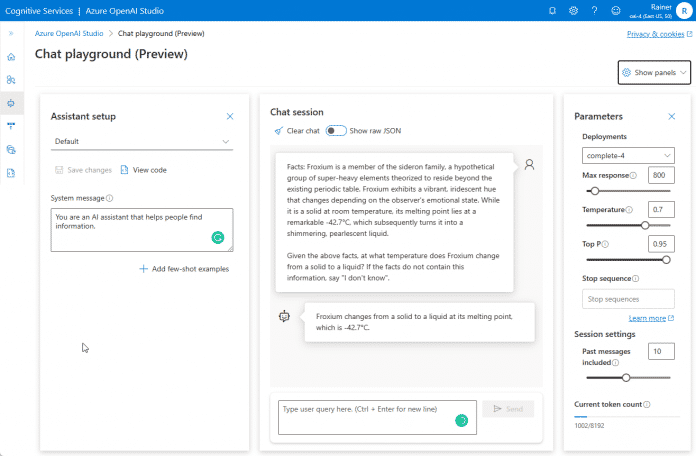
Im gegebenen Textabschnitt sind Informationen über Froxium enthalten. Fragt man das LLM nach einem Faktum über das fiktive Element, das nicht im Text enthalten ist, antwortet es korrekt mit "I don't know":
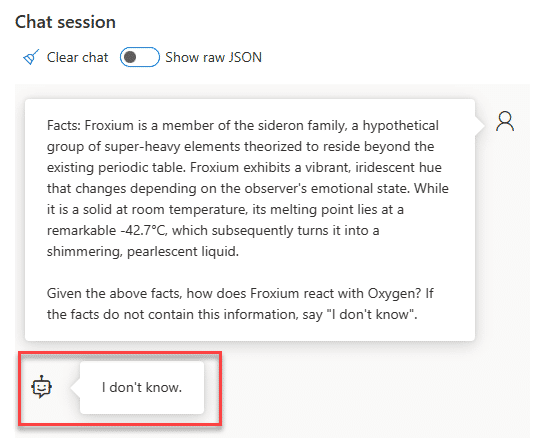
Die Einschränkung auf vorgegebene Informationen sollen das Erfinden vermeintlicher Fakten und den Missbrauch des Abfragesystems verhindern. Das Konzept, LLMs bei der Beantwortung von Fragen auf vorgegebene Informationsquellen zu beschränken, wird oft als Response Grounding bezeichnet. In einem echten Projekt wären umfangreiche Tests erforderlich, um die Abfrageparameter zu optimieren. Um solche Tests zu erleichtern, integriert Microsoft unter anderem strukturierte und automatisierte Prompt-Tests in kommende KI-Produkte wie Prompt Flow [4].
Ermitteln der Embeddings in Azure
Im ersten Schritt ermittelt die Beispielanwendung die Embeddings für die Textabschnitte aus dem SQuAD-Dataset. OpenAI empfiehlt derzeit für Embeddings das LLM "text-embedding-ada-002" [5]. Daneben stellt das Unternehmen die API Create Embeddings bereit [6], um Embeddings automatisch zu generieren.
Die in der Beispielanwendung genutzten Azure-OpenAI-Dienste sind funktional identisch mit den Web-APIs von OpenAI. Um Erstere statt Letztere zu verwenden, ist lediglich eine Anpassung eines Teils der URL erforderlich. Die konkrete Azure-URL findet sich im Azure-Portal. In der Azure-Dokumentation [7] beschreibt Microsoft, wie die APIs zu verwenden sind.
Auch preislich existiert bezüglich des "text-embedding-ada-002"-Modells zum Generieren von Embeddings praktisch keinen Unterschied. Der Preis pro 1000 Token lag beim Schreiben dieses Artikels bei 0,000363 Euro. Der oben gezeigte Artikelausschnitt über das chemische Element Froxium benötigt etwa 170 Token, um einen Embedding-Vektor zu erzeugen und käme somit auf 0,006171 Cent. Für eine Wissensdatenbank mit 10.000 solcher Textabschnitte lägen die Kosten zum Generieren der Embeddings bei rund 62 Cent. Das ist vernachlässigbar gering: Da die Anwendung die Embeddings in einer Vektordatenbank speichert, fallen die Kosten nur einmalig an.
Damit die OpenAI-Embeddings-API in Azure bereitstehen, ist es erforderlich, das gewünschte LLM in Azure auszurollen.

Anschließend steht in Azure ein Playground zur Verfügung, der dem von OpenAI entspricht. Microsoft nennt ihn Azure OpenAI Studio.
Embedding-Vektoren mit vielen Dimensionen
Die vom "text-embedding-ada-002"-Modell erzeugten Embedding-Vektoren haben 1.536 Dimensionen. Sie sind von Haus aus normalisiert, haben also immer eine Länge von 1. Das ist für den Vergleich von Embedding-Vektoren wichtig. Die Ähnlichkeit von Vektoren ergibt sich in der Regel über die Kosinus-Ähnlichkeit [8] (Cosine Similarity) beziehungsweise der Kosinus-Distanz (Cosine Distance). Da die vom OpenAI-LLM erzeugten Embeddings normalisiert sind, entspricht die Kosinus-Ähnlichkeit dem Standardskalarprodukt (Dot Product). Das vereinfacht und beschleunigt das Berechnen der Distanz.
Zur Veranschaulichung soll ein Codebeispiel zum Berechnen der Kosinusdistanz der Embedding-Vektoren zweier Texte (input1 und input2) in Rust dienen. Die Methode generate_embeddings dient dazu, die Embeddings mit der Azure-OpenAI-Web-API zu berechnen. Da sie nur einen simplen Web-Request durchführt, fehlt die Methode im folgenden Codeausschnitt:
async fn get_distance(input1: String,
input2: String,
model: String) -> Result<()> {
// Generate the embeddings for both
// input strings in parallel
let (r1, r2) = join!(
generate_embeddings(input1, model.clone()),
generate_embeddings(input2, model)
);
// Extract embedding vectors from API results
let d1 = &r1?.data[0].embedding;
let d2 = &r2?.data[0].embedding;
// Definition of cosine distance - see
// https://en.wikipedia.org/wiki/Cosine_similarity
// Embeddings from OpenAI are always normalized
// to length of 1. Therefore, the cosine
// similarity is equal to the dot product.
let dot_prod = d1
.into_iter()
.enumerate()
.map(|(ix, v)| v * d2[ix])
.sum::<f32>();
// Cosine distance is 1 - cosine similiarity.
println!("{}", 1f32 - dot_prod);
Ok(())
}
Der Code dient lediglich zur Veranschaulichung des Prinzips und nicht als Vorlage für den Praxiseinsatz. Es gibt Bibliotheken wie nalgebra [9], die die entsprechende Logik eingebaut haben. Sie sind bedeutend schneller als diese naive Umsetzung, da sie SIMD (Single instruction, multiple data) einsetzen. Für das Beispiel ist es allerdings nicht erforderlich, die Distanz manuell zu berechnen: Das übernimmt die Vektordatenbank Qdrant.
Datenbanken zum Speichern von Vektordaten
Für das Beispiel lohnt es sich schon aus Kostengründen, die aus den Einträgen der Wissensdatenbank erstellten Embeddings zu speichern. Sie bei jeder Anfrage neu zu generieren, würde viel zu lange dauern und hohe Kosten verursachen. Theoretisch ist es möglich, die Vektoren in einer relationalen Datenbank, einer NoSQL-Datenbank oder in einfachen Dateien zu speichern. Um anhand eines Embedding-Vektors ähnliche Einträge zu suchen, müsste eine Anwendung jedoch die Distanzen des Vektors zu allen gespeicherten Embeddings ausrechnen und die Ergebnisse nach der Distanz sortieren. Bei mehr als 1500-dimensionalen Vektoren und zahlreichen Einträgen in der Wissensdatenbank entsteht eine Menge Rechenarbeit. Erforderlich ist ein spezialisiertes System, das zum einen Vektordistanzen effizient berechnen kann und zum anderen über Indexfunktionen verfügt, um performantes Suchen über große Sammlungen von Vektoren durchzuführen.
Dabei helfen spezialisierte Vektordatenbanken oder auf Vektorsuche spezialisierte Erweiterungen bestehender Datenbanksysteme wie das auf der Microsoft Build 23 angekündigte Vector Search in Azure CosmosDB [10]. Vektordatenbanken sind darauf optimiert, vieldimensionale Vektoren zu speichern und bieten optimierte Suchfunktionen an. OpenAI führt auf seiner Webseite einige Vektordatenbanken auf [11], darunter die aus Deutschland stammende Qdrant. Sie bietet sich für die Integration in das Beispielprojekt an. Qdrant ist eine in Rust programmierte Open-Source-Vektordatenbank, die Unternehmen lokal betreiben oder als verwaltetes Cloud-Service von Qdrant beziehen können. Im Februar 2023 erschien das erste Major Release 1.0 [12] von Qdrant, und kurz darauf erhielt das Berliner Start-up eine Seed-Finanzierung [13]. Die Qdrant Cloud befindet sich jedoch noch in der Betaphase.
In der Cloud-Variante ist die geografische Region zum Speichern der Daten wählbar. Unter anderem steht ein Rechenzentrum in der EU zur Auswahl. Beim Verfassen dieses Artikels hat Qdrant nur Hosting in der AWS-Cloud von Amazon angeboten, aber Azure und die Google Cloud Platform sollen bald folgen [14]. Zum Lernen und für Prototypen bietet Qdrant eine kostenlose Variante des Cloud-Angebots [15] an, die Einschränkungen bezüglich der zu speichernden und zu verarbeiteten Daten mitbringt. Wer Qdrant im eigenen Rechenzentrum betreiben möchte, greift am besten auf das passende Docker Image [16] zurück.
Eine vollständige Erläuterung aller Funktionen von Qdrant stellt der Hersteller in einer umfangreichen Dokumentation [17] zur Verfügung. Für das flexible Entwickeln von Software mit Qdrant existieren neben einer REST- und einer gRPC-API spezielle Bibliotheken für die Programmiersprachen Python, Rust und Go. Bei den Tests und Recherchen hat sich ergeben, dass der Python-Client am weitesten fortgeschritten ist.
Wer Qdrant in Kombination mit OpenAI in Python programmieren möchte, findet gute Einstiegsbeispiele im zugehörigen Abschnitt der Beispielsammlung OpenAI Cookbook [18]. Der Beispielcode für diesen Artikel ist primär in Rust geschrieben, und der Rust-Client von Qdrant funktionierte reibungslos. Leider gibt es dafür momentan lediglich eine spärliche Dokumentation und weit weniger Codebeispiele als für den Python-Client.
Qdrant gruppiert Embeddings in Collections. Alle Vektoren in einer Collection müssen dieselbe Dimensionalität aufweisen und benötigen die Angabe des zu verwendenden Distanzermittlungsalgorithmus. Für das Zusammenspiel mit dem LLM von OpenAI genügt "Dot Product", da es aufgrund der normalisierten Vektoren mit der Länge 1 der "Cosine Distance" entspricht. Qdrant kennt vor allem für das Indizieren der Vektoren eine Vielzahl weiterer Einstellungen. Die Beschreibung der Einstellungen findet sich in der Dokumentation [19].
Zu jedem Embedding-Vektor lassen sich in Qdrant ein Primärschlüssel (Zahlenwert oder UUID) und Key-Value-Paare als Metadaten speichern. Der Primärschlüssel ist wichtig, um später Bezüge zwischen dem Vektor und externen Datenbanken wie der Wissensdatenbank im Beispiel herstellen zu können. Anwendungen können die Metadaten bei Abfragen der Vektordatenbank zum Filtern verwenden [20].
Folgender Codeausschnitt importiert einen Abschnitt aus der JSON-Datei des SQuAD-Datensatzes in Qdrant:
async fn import_embeddings(
file: String,
collection_name: String,
section: String,
model: String,
) -> Result<()> {
// Read one section of the SQuAD dataset JSON file
let file = File::open(file)?;
let reader = BufReader::new(file);
let records: Root = serde_json::from_reader(reader)?;
let section = records
.data
.iter()
.enumerate()
.filter(|(_, r)| r.title == section)
.collect::<Vec<_>>()[0];
// Create Qdrant client
let client = create_qdrant_client().await?;
// Iterate through all the knowledge base
// entries. Each entry from the SQuAD dataset
// contains a section of a Wikipedia article.
for (ix, r)
in section.1.paragraphs.iter().enumerate() {
// Build the payload that is stored together
// with the embedding vector. The payload can
// consist of a number of key/value pairs.
// For the values, Qdrant supports a number
// of data types including strings, numeric
// values, structured data types, and lists.
let payload: Payload = vec![
("section", section.1.title.as_str().into()),
("ix", Value::from(ix as i64)),
]
.into_iter()
.collect::<HashMap<_, Value>>()
.into();
// Generate the embedding vector using
// Azure OpenAI services.
// Technically, this is a simple HTTP request.
let res =
generate_embeddings(r.context,
model.clone()).await?;
// Add the embedding vector to Qdrant.
let vector = res.data[0].embedding.clone();
let points = vec![PointStruct::new(
// Build a primary key with which we can
// correlate the entry in the SQuAD dataset
// and our embedding vector.
(section.0 * 1000 + ix) as u64,
vector,
payload,
)];
client.upsert_points(collection_name.as_str(),
points, None).await?;
}
Ok(())
}
async fn create_qdrant_client() ->
Result<QdrantClient> {
let mut config = QdrantClientConfig::from_url(
env::var("QDRANT_URL")?.as_str()
);
config.set_api_key(env::var("QDRANT_PAT")?.as_str());
QdrantClient::new(Some(config)).await
}In der Praxis ist es möglich, den Code zu optimieren, da Qdrant für größere Importprozesse mehrere Embeddings pro API Call hochladen kann [21].
Die passende Antwort
Nachdem die Beispielanwendung die Embeddings der Wissensdatenbankeinträge inklusive zugehöriger Metadaten in die Vektordatenbank importiert, ist der nächste Schritt die Suchfunktion. Wenn die Anwendung eine Frage erhält, ermittelt sie dazu den Embedding-Vektor und sucht auf Basis der Vektordistanzen mithilfe von Qdrant jene Wissensdatenbankartikel, die inhaltlich am besten zu der Frage passen.
Das Suchen mit Qdrant ist komfortabel: Man ruft die Suchfunktion des Qdrant-Clients [22] mit dem Embedding-Vektor der Frage plus eventueller Filterkriterien für die Metadaten auf. Beispielsweise lässt sich darüber festlegen, dass Qdrant nur die mit einem bestimmten Schlagwort versehenen Wissensdatenbankeinträge berücksichtigt. Bei der Abfrage akzeptiert die Datenbank weitere Parameter wie die gewünschte Anzahl der Vektoren im Ergebnis. Das Resultat der Abfrage ist eine absteigend sortierte Liste von Embeddings mit ihren Primärschlüsseln und Metadaten, die dem gegebenen Embedding-Vektor am ähnlichsten sind. Die Beispielanwendung verwendet den Primärschlüssel der Ergebnis-Embeddings, um den Bezug zur Wissensdatenbank herzustellen und von dort die Textabschnitte zum Generieren der Antwort zu holen.
Es wäre in der Praxis möglich, der KI nicht nur den ähnlichsten Wissensdatenbankartikel zur Analyse zu übergeben, sondern mehrere zu verwenden. Neue LLMs wie GPT-4 sind für diese Vorgehensweise besonders geeignet, da sie lange Texte als Eingabe erlauben. Das Standardmodell von GPT 4 erlaubt 8.000 Token. Daneben steht ein erweitertes Modell mit 32.000 Token zur Verfügung. Bei langen zu analysierenden Texten gilt es die höheren Kosten zu berücksichtigen, da Azure OpenAI nach Token-Anzahl abrechnet.
Der letzte Schritt in der Beispielanwendung ist das Generieren der Antwort. Das hat nichts mehr mit Embeddings zu tun. Stattdessen kommt die reguläre Text-Completion-API von OpenAI zum Einsatz (siehe Abbildung 5). Beim Schreiben des Artikels war das fortgeschrittenste in Produktion befindliche LLM dafür "text-davinci-003". Das jüngste LLM "gpt-4" ist in der Preview-Phase.
Eine Abfrage von "text-davinci-003" über die Azure OpenAI Services kostet aktuell 1,8111 Cent pro 1000 Token. Die oben dargestellte Beispielabfrage nach dem Schmelzpunkt des fiktiven Elements Froxium verbraucht rund 150 Token, kostet daher in etwa 0,27 ct. "text-davinci-003" ist jedoch nicht in der Lage, die Frage "Given the above facts, at what temperature does Froxium change from a solid to a liquid?" zu beantworten. Erst wenn man explizit nach dem im Text erwähnten Schmelzpunkt ("melting point") fragt, erhält man eine Antwort.
Das *gpt-35-turbo* Modell und das neueste GPT-4-Modell beantworten auch die ursprüngliche Frage ohne explizit erwähnten Schmelzpunkt korrekt. "gpt-35-turbo" ist mit 0,19 Cent pro 1000 Token kostengünstig. GPT-4-Abfragen sind deutlich teurer. Unsere Beispielabfrage verursacht dabei Kosten von rund 3 bis 4 Cent. In der Praxis müssen Unternehmen auf Projektbasis eine gute Balance von Kosten und geforderter Funktionsweise finden.
Das Herz von KI-Systemen
Vieldimensionale Vektoren, sogenannte Embeddings, sind das Herz moderner, generativer KI-Systeme. Entscheidend für die Qualität dieser Systeme ist, die Sinnzusammenhänge der zu analysierenden Objekte wie Texte, Fragen oder Bilder in Embedding-Vektoren zusammenzufassen.
Für gewerbliche Anwendungen bietet Microsoft die OpenAI-Dienste Azure OpenAI Services an. Vektordatenbanken wie Qdrant helfen dabei, größere Mengen an Embeddings zu speichern und effizient zu durchsuchen. Ein wichtiger Aspekt für Anwendungen mit generativen KI-Systemen ist das Prompt Design, um die Antworten, die das KI-Modell erstellt, auf die gewünschten Fakten einzuschränken.
Entwicklerinnen und Entwickler, die sich auf den Einsatz von Embeddings verstehen, können innovative Software mit KI entwickeln, ohne tief in Data Science einzusteigen. Dazu müssen sie sich aber neue Fertigkeiten aneignen: Sie müssen mit Vektoren umgehen können und die zugehörigen Algorithmen und Rechenlogiken beherrschen.
Zusätzlich ist es nötig, dass sie den Umgang mit einer neuen Kategorie von Datenbanken lernen: den Vektordatenbanken. Prompt Design und bei komplexeren Anwendungen zusätzlich das Erstellen von Fine-Tuned Models sind in Zukunft wichtige Grundkenntnisse. Letztlich ist in der Praxis zumindest solides Basiswissen über Python notwendig, da diese Sprache in der Welt der KI die größte Verbreitung hat und zahlreiche Anleitungen und Beispiele auf Python setzen.
Rainer Stropek
ist seit 2008 Mitbegründer und CEO der Firma software architects. Zudem leitet Rainer die österreichische Niederlassung des Beratung- und Schulungsunternehmens IT-Visions. Er hat zahlreiche Bücher und Artikel über C#, Datenbankentwicklung, Microsoft Azure, XAML und Webentwicklung geschrieben. Außerdem hält er regelmäßig Vorträge auf Konferenzen, Workshops und Schulungen in Europa und den USA.
(rme [23])
URL dieses Artikels:
https://www.heise.de/-9066795
Links in diesem Artikel:
[1] https://azure.microsoft.com/en-us/blog/general-availability-of-azure-openai-service-expands-access-to-large-advanced-ai-models-with-added-enterprise-benefits/
[2] https://platform.openai.com/docs/guides/completion/prompt-design
[3] https://huggingface.co/datasets/squad
[4] https://techcommunity.microsoft.com/t5/ai-machine-learning-blog/harness-the-power-of-large-language-models-with-azure-machine/ba-p/3828459
[5] https://openai.com/blog/new-and-improved-embedding-model
[6] https://platform.openai.com/docs/api-reference/embeddings/create
[7] https://learn.microsoft.com/en-us/azure/cognitive-services/openai/reference
[8] https://de.wikipedia.org/wiki/Kosinus-%C3%84hnlichkeit
[9] https://crates.io/crates/nalgebra
[10] https://www.heise.de/news/Build-2023-Micrsoft-baut-sein-KI-Portfolio-fuer-Azure-aus-9063215.html
[11] https://platform.openai.com/docs/guides/embeddings/how-can-i-retrieve-k-nearest-embedding-vectors-quickly
[12] https://github.com/qdrant/qdrant/releases/tag/v1.0.0
[13] https://www.heise.de/news/KI-Vektordatenbank-Start-up-Qdrant-erhaelt-7-5-Million-US-Dollar-Investorengeld-8974828.html
[14] https://qdrant.tech/documentation/cloud/cloud-quick-start/#create-cluster
[15] https://qdrant.tech/documentation/cloud/cloud-quick-start/#free-tier
[16] https://hub.docker.com/r/qdrant/qdrant
[17] https://qdrant.tech/documentation/
[18] https://github.com/openai/openai-cookbook/tree/main/examples/vector_databases/qdrant
[19] https://qdrant.tech/documentation/collections/#create-collection
[20] https://qdrant.tech/documentation/search/#search-api
[21] https://qdrant.tech/documentation/points/#upload-points
[22] https://qdrant.tech/documentation/search/#similarity-search
[23] mailto:rme@ix.de
Copyright © 2023 Heise Medien