
Spring for GraphQL in der Praxis: Eine GraphQL-API für die Tierklinik
Dank Spring for GraphQL lassen sich GraphQL-APIs mit Spring (Boot) entwickeln und bereitstellen. Ein Beispiel für die Anwendung Spring PetClinic zeigt wie.

(Bild: Robert Eastman/Shutterstock.com)
- Nils Hartmann
Die fiktive Tierklinik Spring PetClinic dient der Spring-Community seit Langem dazu, verschiedene Technologien der Spring-Projektfamilie anhand einer Demoanwendung vorzustellen. Dazu gibt es verschiedene Implementierungen, die fachliche Domain ist aber stets die gleiche: In der Tierklink kann ein Haustierbesitzer (Owner) sein Haustier (Pet) zur Untersuchung (Visit) anmelden. Die Untersuchung führt eine Tierärztin (Vetenarian bzw. Vet) durch, die über ein oder mehrere Fachgebiete (Specialty) verfügt. Es gibt ein Web-Frontend, mit dem Mitarbeitende der Tierklinik diese Entitäten verwalten können, also zum Beispiel neue Untersuchungstermine anlegen.
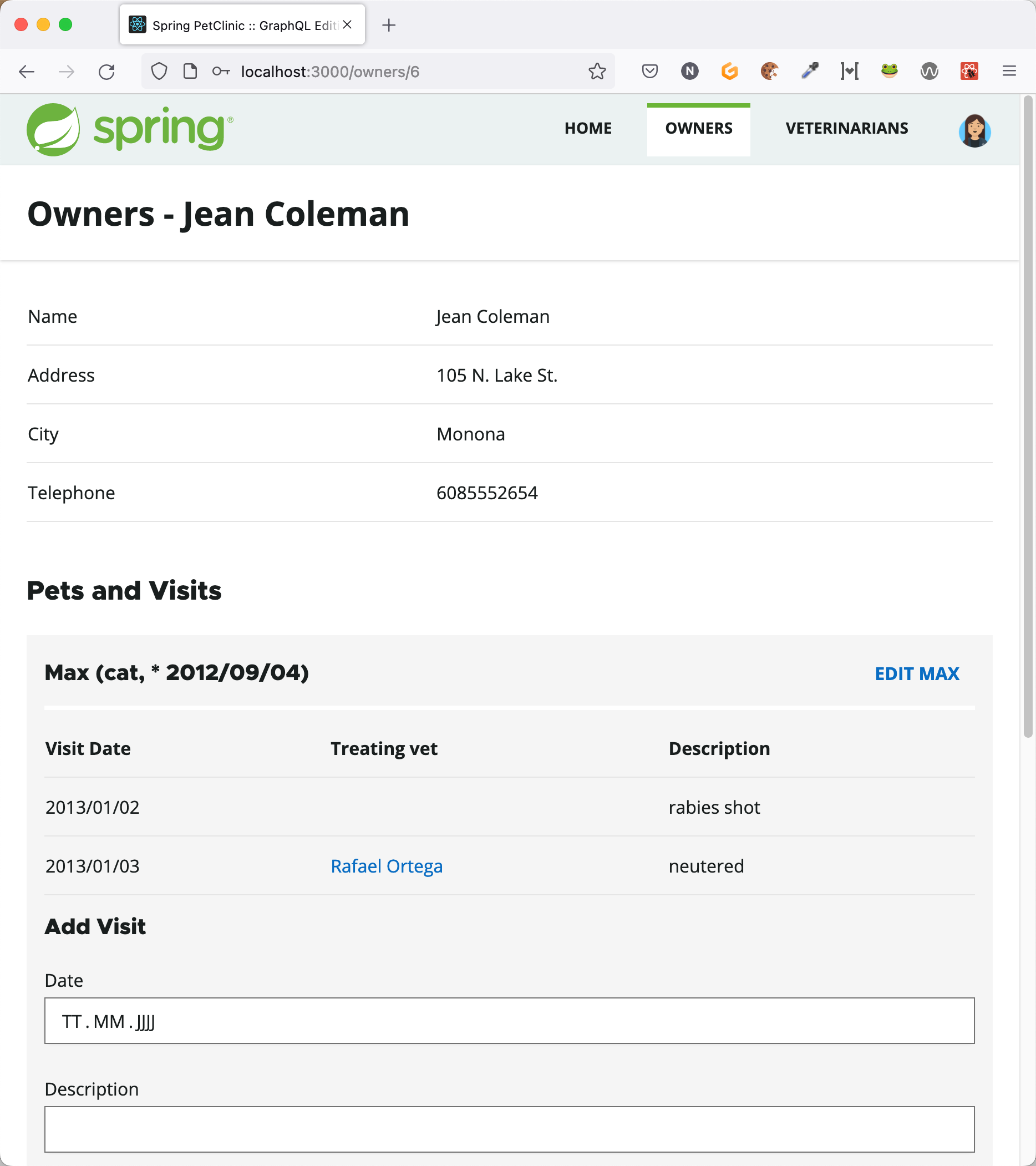
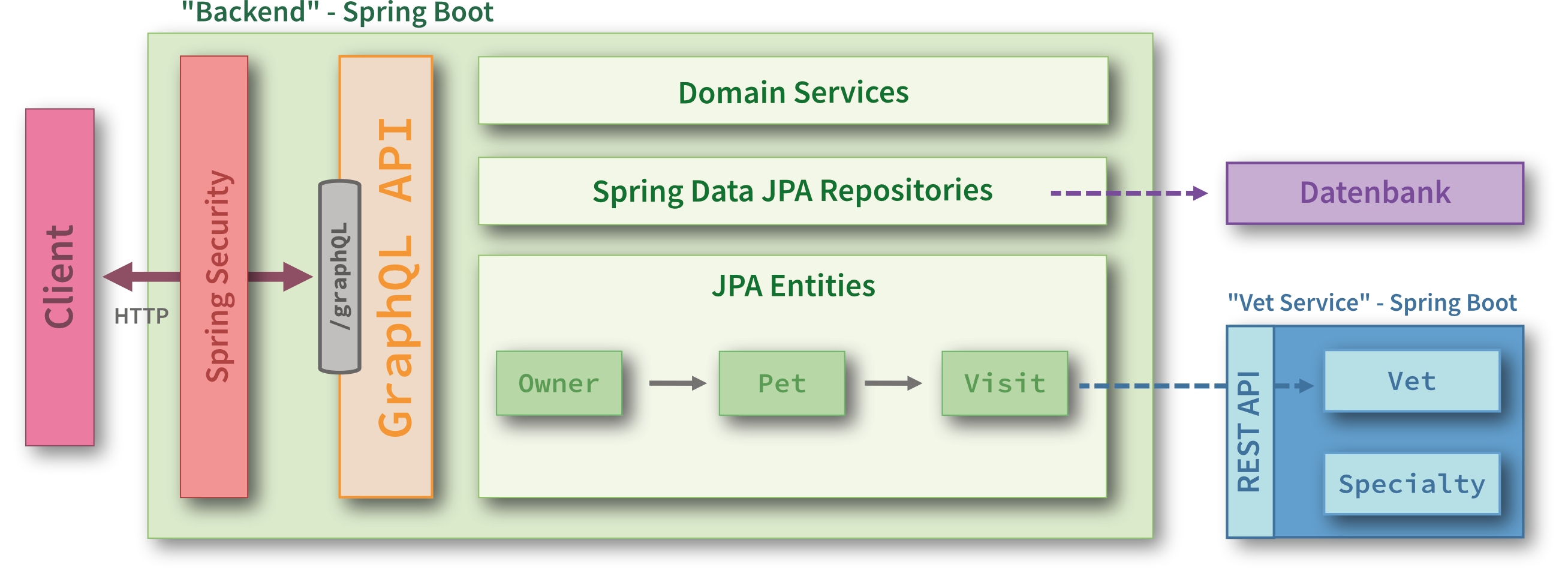
Im Folgenden ist exemplarisch beschrieben, wie sich für diese Domain mit fertig implementierten Datenmodell eine GraphQL-API umsetzen lässt, die beispielsweise zum Entwickeln des Frontends dienen könnte. Die Anwendung ist in zwei Prozesse aufgeteilt: das "Backend", in dem auch die GraphQL-API laufen soll, und ein Microservice ("Vet Service"), der die Tierärzte verwaltet und über eine REST API verfügt. Das Backend verwaltet alle anderen Daten und speichert diese in einer Datenbank, die Zugriff über Spring Data JPA bietet. Der Sourcecode der fertigen API liegt auf GitHub parat. Von Spring for Graph QL 1.0 ist kürzlich der erste Release Candidate erschienen.
API-Schema beschreiben
Als Basis für den Objekt-Graphen einer GraphQL-APIs sind Objekte mit Feldern und deren Typen zu definieren – die zugehörige Beschreibung ist in einem Schema hinterlegt. Aus dem Objekt-Graphen können Clients per GraphQL-Operation Daten abfragen und verändern. Dabei sind drei Operationstypen zu unterscheiden: Query, Mutation und Subscription. Für eine GraphQL-API ist allerdings nur Query zwingend erforderlich, Mutation und Subscription sind optional.
Das Schema der API lässt sich mit der Schema Definition Language (SDL) in einer oder mehreren Dateien in der Anwendung festlegen. Spring-GraphQL liest alle im Projekt vorhandenen SDL-Dateien ein und erzeugt daraus zur Laufzeit das Schema.
Ein Objekt in der API wird mit dem Schlüsselwort type beschrieben und enthält Felder, die ebenfalls einen Typ haben – ähnlich wie Felder an einer Java-Klasse. Es gibt dabei einige standardisierte primitive (skalare) Typen (z. B. String oder Int) und Anwendungen können bei Bedarf auch eigene skalare Typen definieren. Bei jedem Feld bedarf es neben dem Typ auch der Angabe, ob das Feld "nullable" ist – es also auch Null zurückliefern darf (was der Default ist) oder, ob es immer einen Wert zurückliefert (gekennzeichnet mit einem Ausrufezeichen hinter dem Typen).
Videos by heise
Ein erster Entwurf für das Schema der PetClinic könnte wie im folgenden Listing aussehen. Es besteht aus einem GraphQL-Typ für einen Owner, dessen Haustiere und die Untersuchungen der einzelnen Tiere. Mit den dreifachen Anführungszeichen ist die Dokumentation im Markdown-Format für die Felder und Typen hinterlegt.
Listing: Erster Schema-Entwurf
"""Represents a Pet that is known in the PetClinic"""
type Pet {
id: Int!
name: String!
owner: Owner!
visits: [Visit!]!
}
type Visit {
id: Int!
"""What was the result of the visit"""
description: String!
"""When will/has happend this Visit"""
date: Date!
}
type Owner {
id: Int!
firstName: String!
lastName: String!
"""List of all Pets this Owner owns"""
pets: [Pet!]!
}Das Schema verwendet dieselben Namen für die GraphQL-API und die JPA-Entitäten. Das ist allerdings nicht zwingend notwendig. GraphQL macht keine Aussage darüber, woher die Daten kommen, und so müssen sie auch gar nicht aus einer Datenbank entnommen sein. Daher lassen sich zum Beispiel auch Daten über die API anbieten, die gar nicht im Entity-Modell der Anwendung vorhanden sind, etwa berechnete Daten.
Root-Typen: Der Einstieg in den Objekt-Graphen
Ein GraphQL-Schema beschreibt immer einen Objekt-Graphen, der genau einen Einstiegspunkt pro GraphQL-Operation (Query, Mutation oder Subscription) kennt. Mit einer Query lassen sich ausschließlich Daten lesen, via Mutation kann der Client Daten verändern und sich per Subscription über neue Daten vom Server informieren lassen. Der Grundgedanke ist bei allen Operationstypen gleich: Der Client schickt eine Anfrage an den Server, mit der er eine Menge von Feldern aus dem Objekt-Graphen auswählt. Dabei kann der Client Felder nur in der Form auswählen, wie sie im Schema beschrieben sind und muss zudem von einem sogenannten Root-Typ ausgehen. Ein Root-Typ sieht genauso aus wie ein fachlicher Typ, enthält also ebenfalls zahlreiche Felder, hat aber einen vorgegebenen Namen, der sich nach dem Operation-Typen richtet ("Query", "Mutation" oder "Subscription"). In der ersten Version der GraphQL-API für die PetClinic könnte der Query-Typ zum Beispiel wie folgt aussehen:
Listing: Die Root Type Query
type Query {
owners: [Owner!]!
}Er enthält in diesem Fall nur ein einziges Feld, mit dem der Client eine Liste aller Owner abfragen kann. Ein Client könnte mit dem nun definierten Schema beispielsweise folgende Query ausführen:
Listing: Eine GraphQL-Query, um Daten der Owner abzufragen
query {
owners {
firstName lastName
pets { name }
}
}Damit fragt der Client jeweils den firstName und lastName jedes Owners sowie die Namen der jeweiligen Haustiere eines Owners ab. Es wäre dem Client aber nicht möglich, nur die Haustiere abzufragen, weil dazu kein entsprechendes Feld am Root-Typ definiert ist. Auch kann der Client die Liste der Owner nicht sortieren oder filtern, weil die dafür erforderliche Funktionalität ebenfalls nicht im Schema definiert ist.


Im Rahmen der Konferenz betterCode() API liefert Nils Hartmann am 18. Mai 2022 mit seinem ganztägigen Workshop "Loslegen mit GraphQL – ein praktischer Einstieg mit Java und Spring Boot" eine detaillierte Anleitung zum Bau eigener GraphQL APIs.
Darüber hinaus stehen bei der heise Academy noch zwei Videokurse mit Nils Hartmann parat: GraphQL – Die praktische Einführung behandelt die Grundlagen und Konzepte der Abfragesprache GraphQL. Im zweiten Kurs findet sich eine Schritt-für-Schritt-Anleitung zu GraphQL – APIs mit Spring Boot entwickeln.
Die API untersuchen: der GraphQL Explorer GraphiQL
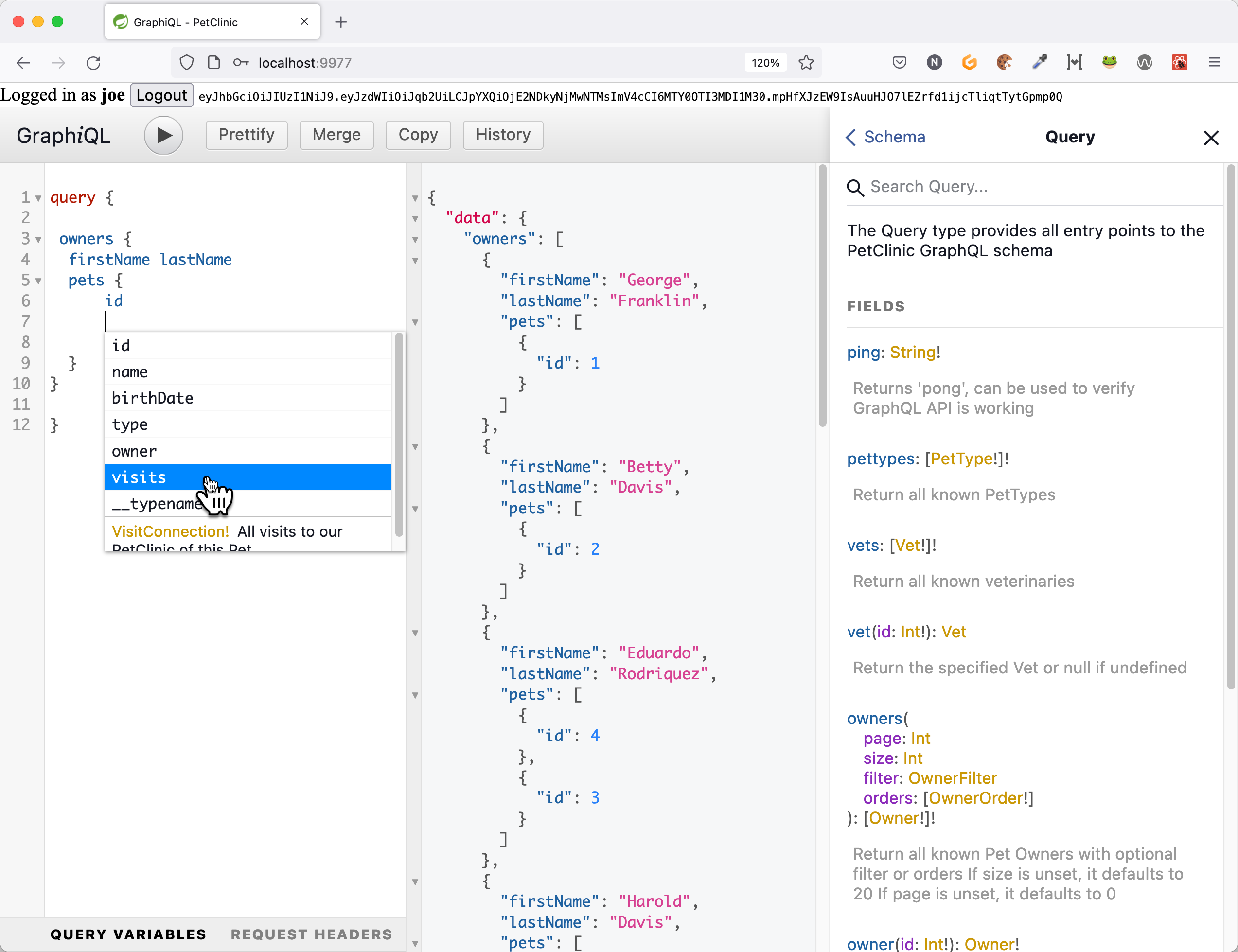
Welche Möglichkeiten dem Client zur Verfügung stehen und wie das Schema einer API aussieht, verrät das Tool GraphiQL. Die Webanwendung liest das Schema einer beliebigen GraphQL ein und stellt anschließend neben der Dokumentation der API auch einen Editor bereit, in dem sich Queries eingeben und ausführen lassen (vergleichbar mit einem SQL Explorer). Da sich das Schema einer GraphQL-API mittels einer speziellen GraphQL Query (Introspection Query) selbst abfragen lässt, kann GraphiQL beim Formulieren von Abfragen mit Code-Vervollständigung (Code Completion) unterstützen. GraphiQL lässt sich für die eigene API mit einem einzigen Property in der application.properties-Datei ganz einfach ein- oder ausschalten.
Daten ermitteln mit Handler-Funktionen
Damit das Backend die Daten für eine Query zurückliefern kann, muss die entsprechende Funktionalität implementiert sein. Die grundlegende Idee ist bei nahezu allen GraphQL-Frameworks unabhängig von der verwendeten Programmiersprache gleich: es gibt pro Feld im Schema eine Resolver-Funktion (in den Java-basierten Frameworks auch Data Fetcher oder Handler-Funktion genannt). Wenn eine GraphQL Query am Backend ankommt, wird sie vom Framework zunächst geparst und gegen das Schema validiert. Nur syntaktisch korrekte Queries werden dann verarbeitet. Dazu ruft das Framework im einfachsten Fall für alle abgefragten Felder nacheinander die Resolver-Funktionen auf. In der Praxis ist es allerdings meist nicht nötig, für alle Felder derartige Funktionen zu schreiben, da Spring-GraphQL zum Beispiel Daten auch per Reflection aus einer Entity-Klasse oder einer Map ermitteln kann. Zwingend erforderlich sind jedoch Resolver-Funktionen für alle Felder der Root-Typen.
In Spring-GraphQL sind dazu Handler-Funktionen zu schreiben und in einer Klasse zu implementieren, die mit der von Spring bekannten @Controller-Annotation markiert ist. Die einzelnen Handler-Funktionen erhalten ihrerseits eine @QueryMapping-Annotation und heißen im einfachsten Fall wie das Feld im Schema, dessen Wert sie ermitteln sollen.
Eine sehr einfache Implementierung für das owners-Feld am Query-Typen zeigt das folgende Listing:
Listing: Handler-Funktion für das owners-Feld
@Controller
public class OwnerController {
private OwnerRepository repository;
public OwnerController(OwnerRepository repository) {
this.repository = repository;
}
@QueryMapping
public List<Owner> owners() {
return repository.findAll();
}
}Die Handler-Funktion verwendet das Spring Data Repository, um alle Owner aus der Datenbank zu lesen und zurückzugeben. Diese Implementierung wäre in der Praxis sicherlich zu trivial, da sie unter anderem die Anzahl der zurück gelieferten Objekte in keiner Weise begrenzt, zeigt aber die grundsätzliche Funktionsweise einer Handler-Funktion.
Aus den zurückgelieferten Owner-Entitäten ermittelt Spring GraphQL nun per Reflection die vom Client abgefragten Felder. Da im Beispiel der PetClinic-API die Felder am Schema genauso heißen wie die Felder (bzw. getter-Methoden) an den Entity-Klassen, sind an dieser Stelle keine weiteren Maßnahmen nötig, und die oben stehende Query lässt sich unmittelbar ausführen. Dazu stellt Spring GraphQL automatisch einen HTTP-Endpunkt über Spring MVC oder Spring WebFlux zur Verfügung, an den Clients die Query schicken können.
Zugriff auf Microservices
In der PetClinic ist die Verwaltung der Tierärzte (Vets) in einem eigenen Microservice abgelegt. Da es keine Beschränkungen gibt, was in einer Handler-Funktion implementiert ist, lassen sie sich auch nutzen, um auf externe Services zuzugreifen. Daher lässt sich das Schema um ein weiteres Feld im Query-Typen erweitern, um darüber einen Tierarzt anhand seiner ID abzufragen:
Listing: Das vet-Feld am Query-Typ
type Query {
owners: [Owner!]!
"""
Return the Vet with the given id or null,
if no such Vet exists
"""
vet(id: ID!): Vet
}Da eine Handler-Funktion ein Mono- oder Flux-Objekt aus dem Reactor-Projekt zurückliefern kann, steht der Implementierung auch der reaktive Spring WebClient zur Verfügung, um die angefragten Daten aus dem Microservice zu lesen. Auf das Argument, dass der Client an den Server sendet, um anzugeben, welcher Tierarzt gelesen werden soll, kann die Handler-Funktion über die @Argument-Annotation kommen:
Listing: Laden von Daten aus einem externen Service
@Controller
public class VetController {
private WebClient webClient;
public VetController() {
this.webClient = WebClient.builder()
.baseUrl("...")
.build();
}
@QueryMapping
public Mono<VetResource> vet(@Argument("/vets/{id}") int id) {
return webClient.get()
.uri(b -> b
.path("/vets/{id}")
.build(visit.getVetId()))
.retrieve()
.bodyToMono(VetResource.class);
}
}Handler-Funktionen für Felder an beliebigen Objekten
Lässt sich der Wert eines Feldes, das nicht in einem Root-Typ definiert ist, von Spring GraphQL nicht per Reflection ermitteln, bedarf es für dieses Feld ebenfalls einer Handler-Funktion. Dazu sind das Schema erneut zu erweitern und der Visit-Typ um das Feld treatingVet zu ergänzen, das aussagt, welcher Tierarzt die Untersuchung durchgeführt hat. Ein treatingVet-Feld gibt es allerdings an der Vet-Entity nicht, die über den Pfad Owner.Pet.Visit referenziert wird, sodass hierfür eine eigene Handler-Funktion implementiert werden muss:
Listing: Erweiterung der API um den Vet
type Vet {
id: Int!
firstName: String!
lastName: String!
specialties: [String!]!
}
type Visit {
# ...Felder wie oben gesehen...
treatingVet: Vet
}Handler-Funktionen für Felder an Nicht-Root-Typen sind mit @SchemaMapping annotiert. Dieser Annotation wird der Typname übergeben, auf den sich das Schema-Mapping bezieht. Der Methoden-Name entspricht dem Feld-Namen aus dem GraphQL-Schema. Spring GraphQL übergibt der Methode das "Source"-Objekt, also jenes, auf dem der Wert des Feldes ermittelt werden soll. Im Beispiel ist das eine Instanz der Visit-Klasse. Zur Erinnerung: GraphQL Java ermittelt die Liste der Owner über die QueryMapping-Funktion, navigiert dann per Reflection über die Pets, auf die Visits, ruft für jedes Visit-Objekt die neue Handler-Funktion auf und übergibt das jeweilige Visit-Objekt als Methoden-Parameter. Da auch diese Handler-Funktion ein reaktives Mono-Objekt zurückgibt, werden mehrere dieser Handler-Funktionen parallel ausgeführt, wenn der Tierarzt für mehr als einen Visit ermittelt werden soll:
Listing: Daten aus einem Microservice ermitteln
@Controller
public class VisitController {
private WebClient webClient;
public OwnerController() {
this.webClient = WebClient.builder()
.baseUrl(". . .")
.build();
}
@SchemaMapping(typeName = "Visit")
public Mono<VetResource> treatingVet(Visit visit) {
return webClient.get()
.uri(b -> b
.path("/vets/{id}")
.build(visit.getVetId()))
.retrieve()
.bodyToMono(VetResource.class);
}
}Daten verändern mit Mutations
Mittels einer Mutation kann ein Client auch Daten verändern. Sowohl die Definition von Mutations im Schema als auch deren Implementierung entsprechen denen der Queries, nur dass sich die Namen ändern – der Root-Typ heißt im Schema Mapping und die entsprechende Annotation @MutationMapping. Im Folgenden ist die addVisit-Mutation beschrieben, mit der sich eine neue Untersuchung anlegen lässt. Die Mutation erwartet ein Input-Objekt, das die notwendigen Informationen enthält, die zum Erzeugen eine Visit notwendig sind:
Listing: Eine Mutation zum Erzeugen eines Visits
input AddVisitInput {
petId: Int!
description: String!
date: Date!
}
type Mutation {
addVisit(input: AddVisitInput!): Visit!
}Die Arbeit mit dem Input-Objekt setzt eine eigens anzulegende Java-Klasse voraus. Wie von den REST-Handler-Methoden in Spring gewohnt, erzeugt das Framework zur Laufzeit eine Instanz dieser Klasse und befüllt sie mit den Werten, die der Client übergeben hat. Die Gültigkeit der einzelnen Werte lässt sich dabei mit Bean Validation (Java-Spezifikation) sicherstellen. Im Beispiel der addVisit-Mutation etwa soll das description-Feld mindestens fünf Zeichen enthalten:
Listing: Implementierung der addVisit-Mutation
@Controller
public class VisitController {
private VisitService visitService;
public VisitController(VisitService visitService) {
this.visitService = visitService;
}
record AddVisitInput(
int petId,
Integer vetId,
LocalDate date,
@Size(min=5)
String description
) {}
@MutationMapping
public Visit addVisit(@Valid @Argument AddVisitInput input) {
return visitService.addVisit(
input.petId(),
input.description(),
input.date(),
input.vetId()
);
}
}Mit Sicherheit: Verwendung der API kontrollieren
Dank der Integration von Spring GraphQL in den kompletten Spring-Technologie-Stack stehen auch die Features von Spring Security bereit, um die GraphQL-API abzusichern. Dabei gibt es mindestens zwei Optionen: Zum einen lässt sich der GraphQL-HTTP-Endpunkt absichern, sodass Queries überhaupt nur dann ausgeführt werden, wenn sie eine gültige Autorisierung etwa in Form eines Cookies oder Tokens mitschicken. Eine feiner gegliederte Berechtigungsprüfung lässt sich dann entweder in den Handler-Funktionen oder der Domain-Schicht mit Spring-Security-Mechanismen wie der @PreAuthorize-Annotation durchführen. Im Fall einer öffentlichen API könnte sich die Security auf diese Prüfungen beschränken, der GraphQL-Endpunkt wäre dann grundsätzlich für alle Clients offen, für spezielle Funktionen müsste der Client aber eine Autorisierung mitschicken.
Da die PetClinic als interne Anwendung ausgelegt ist, ist hier der GraphQL-Endpunkt nur mit Autorisierung aufrufbar. Die passende Spring-Security-Konfiguration könnte wie folgt aussehen:
Listing: HTTP-Endpunkte absichern
@Configuration
@EnableGlobalMethodSecurity(prePostEnabled = true)
public class SecurityConfig {
@Bean
public SecurityFilterChain filterChain(HttpSecurity http) {
return http.authorizeRequests()
// Default-Login-Endpunkt von Spring Security ohne Authentifizierung
.antMatchers("/login").permitAll()
// Einschr�nken aller Endpunkte, inkl. /graphql
.anyRequest().authenticated()
.build();
}
}Innerhalb der Anwendung lässt sich nun anhand von Benutzerrollen festlegen, ob eine Handler-Funktion ausgeführt werden darf oder nicht. Das folgende Listing zeigt exemplarisch eine addVet-Mutation, die nur Benutzer ausführen dürfen, die eine Managerrolle besitzen:
Listing: Eine Mutation absichern
@Controller
public class VetController {
@MutationMapping
@PreAuthorize("hasRole('ROLE_MANAGER')")
public Vet addVet(@Argument AddVetInput input) {
// ...
}
}Auf dem neuesten Stand bleiben: Daten über Subscriptions erhalten
Wie zuvor erwähnt, stellt Spring GraphQL auch GraphQL Subscriptions bereit. Die entsprechenden Daten lassen sich dabei über eine Websocket-Verbindung zum Client schicken, sobald sie auf dem Server erzeugt wurden. In der PetClinic-Anwendung können sich Clients über neue Visits automatisch vom Server informieren lassen, sofern im Schema eine onNewVisit-Subscription beschrieben ist:
Listing: Die onNewVisit-Subscription
type Subscription {
onNewVisit: Visit!
}Die Handler-Funktion dazu muss mit @SubscriptionMapping annotiert sein und ein reaktives Flux-Objekt zurückliefern. Die PetClinic-Anwendung verwendet dafür einen Publisher, der auf fachliche Spring Application Events ("Neuer Visit wurde angelegt") horcht und die erzeugten Visit-Objekte aussendet, die die Handler-Funktion anschließend an den Client zurückgibt. Die hier gezeigte Implementierung soll lediglich vermitteln, wie Subscriptions grundsätzlich mit Spring GraphQL anzulegen sind. In der Praxis ist es in der Regel erforderlich, weitere Anforderungen umzusetzen (z. B. was passiert, wenn mehrere Instanzen des Backends in einem Cluster laufen), die allerdings unabhängig von Spring GraphQL zu lösen sind.
Listing: Handler-Funktion für die onNewVisit-Subscription
@Controller
public class VisitController {
private VisitPublisher publisher;
public VisitController(VisitPublisher publisher) {
this.publisher = publisher;
}
@SubscriptionMapping
public Flux<Visit> onNewVisit() {
return visitPublisher.getPublisher();
}
}Ob’s funktioniert? GraphQL-APIs testen
Damit hat die Tierklinik nun eine einfache GraphQL-API, die auch automatisiert getestet werden soll. Dazu lassen sich unter anderem im Client über die Klasse WebGraphQlTester GraphQL Queries an den zu testenden Server schicken. Je nach Anforderungen sind dabei verschiedene Konfigurationen möglich. Beispielsweise lässt sich wie aus Spring gewohnt einstellen, ob die MVC-Schicht gemockt ist oder ob der richtige HTTP-Port geöffnet wird.
Der Query kann entweder direkt in der Test-Methode oder in einer eigenen Datei formuliert sein. Für IntelliJ gibt es ein GraphQL-Plug-in, das beim Formulieren von Queries Code Completion und syntaktische Überprüfung anbietet.

Nach dem Ausführen der Query stehen auf dem Ergebnisobjekt diverse Methoden zur Verfügung, um das Ergebnis zu überprüfen und das korrekte Verhalten sicherzustellen:
Listing: Ein Test für die GraphQL-API
@SpringBootTest
@AutoConfigureMockMvc
@AutoConfigureHttpGraphQlTester
public class OwnerControllerTests {
@Autowired
WebGraphQlTester graphQlTester;
@Test
void queryAllOwnersWorks() {
// language=GraphQL
String document = """
query {
owners {
id
firstName
}
}
""";
graphQlTester.mutate()
.headers(h -> h.setBearerAuth(". . ."))
.build()
.document(document)
.execute()
.path("owners[0].id")
.entity(String.class)
.isEqualTo("1")
.path("owners[0].firstName").
.entity(String.class)
.isEqualTo("George")
;
}
}Spring for GraphQL: Eine solide Basis für eigene GraphQL-APIs
Dank Spring GraphQL lassen sich im Spring-Framework und dessen kompletter Projektfamilie jetzt GraphQL-APIs aus erster Hand entwickeln. Da Spring GraphQL intern auf dem weitverbreiteten und vielfach eingesetzten Projekt graphql-java basiert, ist eine stabile Implementierung sichergestellt. Überdies können Entwicklerinnen und Entwickler auf das gewohnte Spring-Programmiermodell mit all seinen typischen Integrationen wie etwa Spring Data oder Spring Security zurückgreifen. Dem Entwickeln eigener GraphQL-APIs steht damit nichts mehr im Wege.
Nils Hartmann
ist freiberuflicher Softwareentwickler, -architekt und Trainer aus Hamburg. Er beschäftigt sich mit Java-Backends und React-Frontends.
(map)
