

Unternehmens-APIs mit Microservices
Der immer beliebter werdende Microservices-Ansatz kann eine hohe Anzahl an APIs produzieren: Es gibt verschiedene Optionen, diese über Unternehmensgrenzen hinweg zu präsentieren.

- Jörg Adler
Das Microservice-Architektur-Pattern erfreut sich großer Beliebtheit. Da weniger Businesscode durch einen Service behandelt wird, steigt dabei zwangsläufig die Anzahl der Services. Jeder dieser kleinen Services hat wiederum eine API. Dadurch produziert man eine hohe Anzahl dieser Programmierschnittstellen.
Zusätzlich rückt das Erstellen von REST-APIs in den Fokus von Unternehmen. Solche APIs sollen allumfassend sein und wie aus einem Guss wirken. Das heißt, es soll einheitliche Formate, Verlinkungen und Dokumentationen geben. Man will es dem Kunden nicht zumuten, sich in viele kleine Microservice-APIs einzudenken, von denen alle unterschiedliche Auffassungen von fachlichen Entitäten haben. Vor allem wenn man als Grenze eines Services einen Bounded Context aus dem Domain-driven Design wählt, ist diese Dopplung von Begriffen mit jeweils unterschiedlichen Bedeutungen in verschiedenen Kontexten (und damit Services) nicht zu vermeiden.
Diese Diskrepanz von fachlichen und technischen Anforderungen gilt es zu lösen. Der Einfachheit halber beschränkt sich der Artikel vornehmlich auf REST-Services mit HATEOAS.
Zur Illustration hilft zunächst ein kleines Beispiel. Service A ist ein Service für das Ausliefern von Artikelinhalten. Service B ist ein Service für Artikelbewertungen.
Die REST-Schnittstelle von Service A liefert unter der URL A/articles/{id} eine reichhaltige Beschreibung eines Artikels inklusive Bildern, Preis und weiteren Informationen. Bei Service B findet man unter der URL B/articles/{id} nur die id, eine Gesamtbewertung ("Sterne") und mehrere Links. Zum Beispiel den Link "ratings", der auf B/articles/{id}/ratings zeigt. Dazu kommen unter anderem noch Links zum Anlegen neuer Bewertungen.
In den APIs beider Services existieren Root-Ressourcen, die jeweils einen Link "article" enthalten, der auf .../articles/{id} zeigt. Die Existenz der Artikel leitet Service B aus einem zentralen Eventstream ab. Aus diesem bezieht Service A ebenfalls seine Daten.
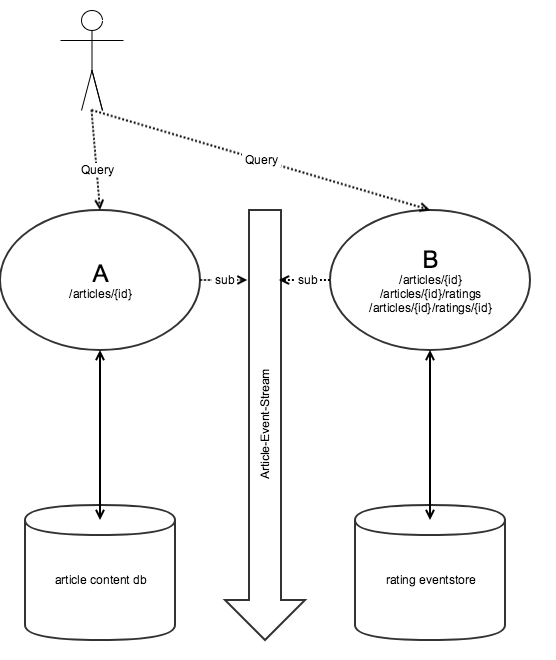
Mit diesem Setup haben Entwickler erst einmal nichts falsch gemacht. Jeder Microservice korrespondiert schön mit einem Bounded Context. Die jeweiligen APIs sind in sich geschlossen. Um allerdings aus den APIs der beiden Services eine API nach außen zu bilden, hat man unterschiedliche Optionen.
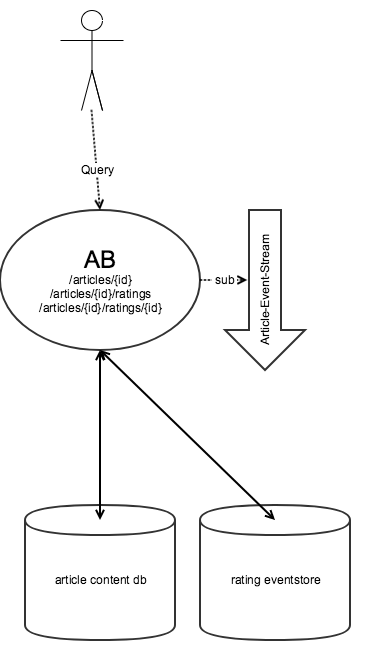
Option 1: Zusammenlegen der beiden Services
In obigem Beispiel sollte man zunächst überlegen, ob das Zerteilen der Services mit dem Setup überhaupt Sinn ergibt. Schließlich setzt man auf Microservices, um unabhängige Deploybarkeit zu erreichen und dadurch schneller zu werden. Koppelt man aber nun die beiden APIs wieder eng aneinander und lässt die eigentlichen Services trotzdem getrennt, läuft man schnell Gefahr, dass man einen verteilten Monolithen baut. Nicht umsonst gehen bei Ansätzen wie Self-Contained Systems die Tendenzen eher dahin, größere Deployables zu haben. Auf einer Infoseite zum Thema sprechen die Autoren beispielsweise von 5-25 Services für einen kompletten Onlineshop.
Nachteil der Zusammenlegung ist, dass es nicht vollkommen freigestellt ist, den Service weiter zu vergrößern. Spätestens, wenn Entwickler einen Service über Teamgrenzen hinweg betreiben, wird es schwierig. Man mutet dem Kunden damit zu, eine handvoll APIs zu kennen.
Im Beispielfall lassen sich beide Services in eine Komponente legen und damit die Trennung aufheben. Der "article"-Endpunkt der neuen API enthält dann sowohl Artikelinhalt als auch die Gesamtbewertungen und "rating"-Links. Damit ergibt sich der Vorteil, dass Routing, Versionshandling und Authentifizierung nachvollziehbar in einer Komponente liegen. Auch die Dokumentation korrespondiert 1:1 mit einer Komponente.
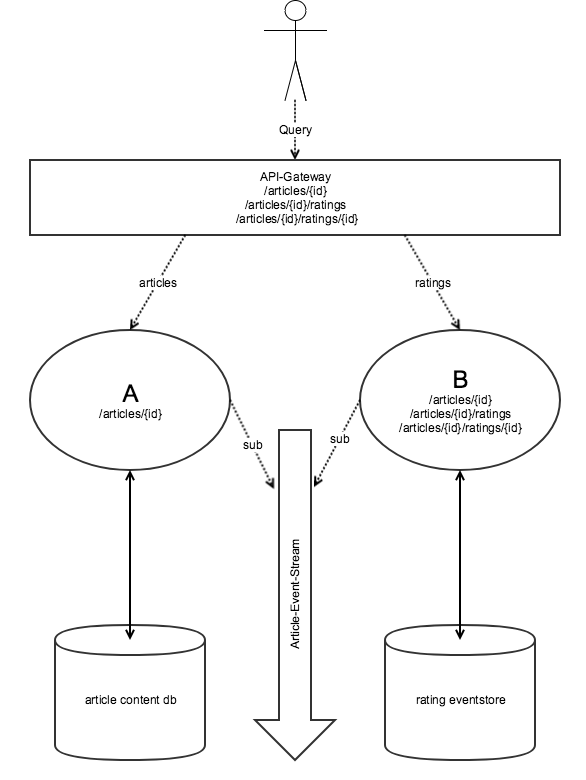
Option 2: API-Gateway
Sollte die Überarbeitung des Schnitts keine Option sein, bleibt immer noch die Möglichkeit, vor die Mircroservices einen API-Service zu stellen, der das Mapping der Sprache aller Microservices auf die API-Sprache übernimmt. Routing und Versionsmanagement sind damit auch erschlagen. In gewisser Hinsicht gelten auch hier die Einschränkungen aus Option 1, jedoch mit einer entscheidenden Änderung.
Denn natürlich spricht man an den Services "nach hinten" auch REST (inklusive HATEOAS) – somit ist die eigentliche Businesslogik kapselbar. Der Backend-Service gibt über das Schema ebenfalls aus, was er genau erwartet und was er ausliefert. Somit bleiben nur bestimmte feste Transformationen der Schemata und Relationen, die im API-Service fest sind. Sie sind für gewöhnlich dokumentiert und dürfen sich deshalb nicht ändern.
Bei einem Breaking Change eines beteiligten Service ist klar, dass man unter Umständen den betreffenden Microservice und die API releasen muss. Man hat zusätzlich noch die Möglichkeit, die Änderung vor den Kunden zu verbergen, indem der API-Service sie abfedert. Dies bedeutet im Zweifelsfalle aber mehr Aufwand. Ein weiterer Vorteil wäre, dass es möglich ist, unterschiedliche Microservices zu neuen APIs zusammenzusetzen.
Der Nachteil ist, dass solche Services über Teamgrenzen hinweg problematisch sind, wie ein Erfahrungsbericht von Netflix eindrucksvoll beschreibt. Wenn die einzelnen Microservices auch von außerhalb der Organisation erreichbar sind, bezeichnet man die Konstellation gerne als Backend-For-Frontend. Die generelle Erreichbarkeit der Backend-Services von Außen ist aber eigentlich nicht erforderlich. Sie führt allerdings meist zu besserem Code, da sich auch der Entwickler in "zweiter Reihe" Gedanken machen muss, wie der Kunde seinen Service benutzt. Somit hilft ein solcher Aufbau dabei, reine CRUD-Services (Create, Read, Update and Delete) von vornherein zu vermeiden. Im allgemeinen Fall wird der API-Service als API-Gateway bezeichnet.
Am konkreten Beispiel sieht ein API-Gateway so aus: Es gibt einen API-Service C. Dieser liefert unter C/articles/{id} den Payload von Service A aus, ergänzt aber dort einen "ratings"-Link, den er von Service B holt. Dabei schreibt er allerdings die URL auf seine eigene C/articles/{id}/ratings-URL um. Er übernimmt außerdem das Schema von B. Dazu muss er wissen, wie er bei Service B an die "ratings"-Links für einen Artikel kommt.
Das geschieht, indem er von der Root-Ressource von B den Template-Link "article" entsprechend ausfüllt und von dort den "ratings"-Link nimmt. Die API C kann sich, was Rechte und Schemata betrifft, komplett am Service B orientieren und beispielsweise cachen. Es wäre auch vorstellbar, dass die API immer die Gesamtbewertungen als Teil des Artikels sieht. Es wäre somit für C problemlos möglich, sie zum eigentlichen Payload von A vor der Auslieferung hinzuzufügen.
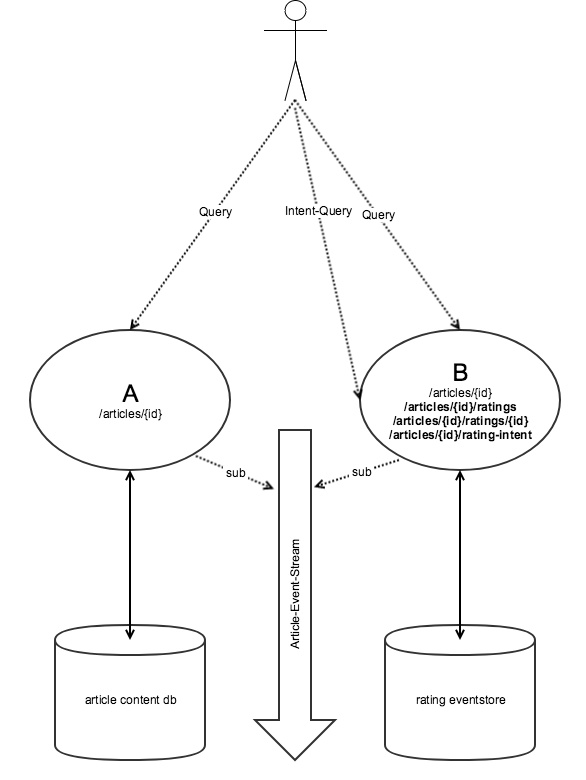
Option 3: Microservice-API
Eine weitere Möglichkeit wäre es, auf den zentralen Service zu verzichten. Dieser Ansatz lagert viele Aufgaben wie Routing, Versionshandling und Verfügbarkeitsangaben in komplexe Infrastrukturkomponenten aus. Hierzu muss in den Microservices das Wissen, Teil einer API zu sein, direkt enthalten sein. Auch machen unter anderem eine API-weite Versionierung, Routing und die Authentifizierung das Ganze herausfordernder.
Um eine Verlinkung zu etablieren, muss der verlinkende Microservice wissen, wo sein Linkziel liegt oder zumindest die Adresse nach Außen kennen. Dies kann durch statische Links oder durch eine Service-Discovery erfolgen. Danach kann man unterschiedlich vorgehen.
Serverseitiges Rendern der Links
Der verlinkende Service geht zum verlinkten Service und fragt dort die zu rendernden Links ab. Dazu muss der Aufrufer das Linkformat und Templating verstehen. Caching sollte hierfür erlaubt sein.
In unserem Beispiel bedeutet das konkret, dass Service A, um einen Link zu den Bewertungen auszuliefern, zur Root-Ressource des Service B geht und daraufhin in das Template B/articles/{articleId} des Service B die entsprechende Id einsetzt. Danach tätigt Service A den Call zum Artikel und kopiert die Links zu den Bewertungen dort in seinen Request.
Wohlbemerkt muss Service A nichts von B verstehen, abgesehen vom Linkpfad. Man beachte dabei die Analogie zu Option 2. Service A kann nun eigenverantwortlich cachen (das heißt zum Beispiel den Templatelink nur jede Minute aktualisieren). Die Abhängigkeiten der beiden Services kann man noch durch Service-Registries, Schema-Registries oder ähnliches abfedern.
In einer Dokumentation der API tauchen dann jedoch nicht alle Endpunkte auf. Man könnte sogar darauf verzichten, die Endpunkte, die nur Service A benötigt, für den Client erreichbar zu machen. Sollte nun in der API die Anforderung bestehen, dass im Artikel-Payload auch die Gesamtbewertungen mit ausgeliefert werden, müsste A diese ausliefern, indem er nicht nur den Link von B zu den Ratings, sondern auch dessen Payload mit in seinen zusammenführt. Auch ein asynchroner Weg ist denkbar.

Das führt jedoch über kurz oder lang dazu, dass die Grenze der beiden Services verwischt. Wenn man nicht aufpasst, weiß A auf einmal, was eine Gesamtbewertung ist, was eigentlich in der Domäne von B liegt. Hier besteht die große Gefahr eines verteilten Monolithen. Der Unterschied zum API-Gateway besteht darin, dass A noch für einen Teil des fachlichen Codes zuständig ist.
Clientseitige Verlinkung
In einem solchen Fall weiß der verlinkende Service nur wenig über den aufzurufenden Service und gibt dem Client nur den Hinweis, wo der andere Service liegt. Im anderen Service bildet man das fehlende Schema in den Links durch sogenannte Intent-Ressourcen ab. Der Client muss, bevor er einen schreibenden Request absetzt, die Absicht (Intent) bekunden. Er bekommt dann eine Antwort, in der das genaue Schema für den Schreib-Request und die URL steht (und auch die Information, dass ein Schreiben zur Zeit möglich ist).
Dies ist den meisten Lesern schon aus Zeiten von (HTML-) Webservern bekannt und ist durchaus damit vergleichbar. Nur muss man hierzu nicht zwingend HTML sprechen, sondern weicht eher auf JSON und JSON-(Hyper)Schema aus. Die Vorteile liegen darin, dass der verlinkende Service kein Schema in die Links schreiben muss, sondern die Kenntnis von Schema und/oder Berechtigungen auf den verlinkten Service geschoben werden. Der Nachteil ist dabei ganz klar der eine zusätzliche HTTP-Request pro anzulegendem Objekt.
In unserem Beispiel bietet Service B also eine weitere Ressource B/articles/{id}/rating-intent an. Diese liefert einen geeigneten Payload mit Metainformationen (zum Beispiel ein JSON-Schema) dazu aus, wie das Anlegen einer neuen Bewertung durchzuführen ist. Service A ist das Linktemplate bekannt und liefert es aus. Je nachdem, wie eng man diese Kopplung machen möchte, kann die Beurteilung der generellen Durchführbarkeit schon bei A erfolgen, oder man lagert sie nach B aus.
Als Weg des Informationstransports bietet sich zum Beispiel das serverseitige Rendern an. Obwohl sich dann die Frage stellt, warum nicht gleich die ganze Intent-Ressource von B durch A mit ausgeliefert wird. Alternativ zur Intent-Ressource kann man hier einen OPTIONS-Request auf B/articles/{id}/ratings anbieten, die sich dann wie die Intent-Ressource verhält.
Bei diesem Vorgehen ist es zunächst nicht vorgesehen, dass der Payload von A die Gesamtbewertungen mitausliefert. Man müsste im Verfahren wie oben die Gesamtbewertung vorher serverseitig abholen, was die Nachteile der losen Bindung aufhebt und keine weiteren Vorteile liefert. Somit bietet es sich an, wenn die beiden Services solche Teile auf anderem Wege, zum Beispiel asynchron, austauschen. Diese Variante eignet sich nur, wenn die verschiedenen Teile der API möglichst wenig aufeinander angewiesen sind. Das ist zum Beispiel bei Self-Contained Systems der Fall. Dort sind die einzelnen Services nur durch HTML-Links verbunden und Daten werden durch asynchrone Kommunikation ausgetauscht.
Außerdem muss man wieder genau überlegen, welche Ressourcen man in die API-Dokumentation aufnimmt und welche eigentlich nur für A verfügbar sein sollen, damit der Kunde den Eindruck einer durchgängigen API erhält.
Fazit
Jede der oben dargestellten Optionen hat ihre Berechtigung. Ihr Einsatz hängt stark von den Gegebenheiten ab. Den geringsten initialen Aufwand hat die erste Variante, da sie durchgeführt wird, bevor man auch nur eine Zeile Code geschrieben hat. Hieraus resultiert die Empfehlung, zunächst einen eher größeren Service zu schreiben. In diesem Service kann man durch eine geschickte Modularisierung ohne größeren Aufwand "Sollbruchstellen" einbauen. Das Zerlegen solcher Mikrolithen fällt meist einfacher als das Zusammenlegen von mehreren unabhängigen Komponenten. Aber bitte aufpassen: Spätestens an Teamgrenzen sollte auch eine Komponentengrenze im Code vorhanden sein.
Sollte eine Vergrößerung nicht möglich sein, kann man die anderen Varianten in Betracht ziehen. Hat man sehr eigenständige Services in einer API, sind die Möglichkeiten in Abschnitt 3 vielleicht praktikabel. Hat man größere Abhängigkeiten zwischen den Services, eigene Lebenszyklen von API und Backend-Services oder das Bedürfnis, mehrere APIs mit den gleichen Services zur Verfügung zu stellen, würde man zur zweiten Möglichkeit greifen. Die APIs wirken dadurch eher aus einem Guss und können mehr und schneller auf Kundenbedürfnisse eingehen, bringen aber die oben beschriebenen Nachteile mit.
Jörg Adler
ist zur Zeit bei der Mercateo AG als Softwareentwickler tätig. Aktuelle Schwerpunkte sind REST-Schnittstellen und interne Systeme.
(bbo)
