

Benchmark: Welche KI taugt am besten für Cybersecurity?
Sicherheitsforscher von Sophos haben Kriterien für den Sicherheitsnutzen großer Sprachmodelle aufgestellt und die Modelle anschließend miteinander verglichen.

(Bild: sdecoret/Shutterstock.com)
Damit man den Nutzen der einzelnen Large Language Models (LLM) für Cybersicherheit bemessen kann, haben Forscher des Sicherheitsunternehmens Sophos Kriterien für die Vergleichbarkeit solcher Modelle entwickelt. Dazu haben sie Benchmark-Aufgaben erstellt, also typische Probleme, mit denen sich die Fähigkeiten eines Modells einfach und schnell beurteilen lassen. Die Auswahl der Modelle erfolgte nach Kriterien wie Modellgröße, Beliebtheit, Kontextgröße und Aktualität. Getestet wurden unterschiedlich große Versionen der Modelle Llama 2 und Code Llama von Meta, Amazons Titan Large und GPT-4.
Die Aufgaben bestanden aus drei Szenarien. Im ersten sollte das LLM als Assistent bei der Untersuchung von Sicherheitsvorfällen fungieren. Dazu sollte es relevante Telemetrieinformationen auf der Basis von Abfragen in natürlicher Sprache abrufen. Bewertet wurde die Fähigkeit, diese Abfragen in SQL-Anweisungen umzuwandeln.
Videos by heise
Vorfälle zusammenfassen und bewerten
Im zweiten Szenario sollte das LLM aus den Daten eines Security Operations Center (SOC) Vorfallzusammenfassungen generieren. Hintergrund sind die großen Mengen an Ereignissen, die in Netzwerken und Benutzerendpunkten im Zusammenhang mit verdächtigen Vorgängen auftreten. Für SOC-Analysten sind sie der Ausgangspunkt für weitere Untersuchungen, ob es sich tatsächlich um einen Sicherheitsvorfall handelt. Da die Abfolgen der Ereignisse oft unübersichtlich sind, können hier Sprachmodelle unterstützen, indem sie die Ereignisdaten identifizieren und organisieren. Auf dieser Grundlage können die Analysten ihre weiteren Schritte planen.

(Bild: Sophos)
Im dritten Szenario musste das LLM den Schweregrad des Vorfalls bewerten, was einer modifizierten Version des klassischen ML-Problems in der IT-Sicherheit entspricht: Ist ein beobachtetes Phänomen harmlos oder Teil eines Angriffs? Dafür verwendete Sophos einen Datensatz von 310 Vorfällen aus dem eigenen MDR-SOC (Managed Detection and Response), die jeweils als eine Reihe von JSON-Ereignissen mit unterschiedlichen Schemata und Attributen je nach dem erfassenden Sensor formatiert waren. Diese Daten wurden dem Modell zusammen mit Anweisungen zur Zusammenfassung der Daten und einer vordefinierten Vorlage für den Zusammenfassungsprozess übergeben.
Spitzenreiter GPT-4 und Claude v2
Zwar kann der Benchmark-Test nicht alle potenziellen Problemstellungen berücksichtigen, so das Resümee der Forscher, LLMs können jedoch bei der Untersuchung von Sicherheitsvorfällen eine wirksame Unterstützung sein und als Assistenten eingesetzt werden – dafür sind allerdings weitere Leitplanken und Anleitungen nötig.
Die meisten LLMs erbringen bei der Zusammenfassung von Vorfallinformationen aus Rohdaten eine ausreichende Leistung, allerdings gibt es noch Raum für Verbesserungen durch Feinabstimmung. Insbesondere die Bewertung einzelner Artefakte oder Gruppen von Artefakten sind eine herausfordernde Aufgabe für schon trainierte öffentlich verfügbare LLMs. Um dieses Problem anzugehen, ist möglicherweise ein spezialisiertes LLM erforderlich, das auf Cybersicherheitsdaten geschult ist.
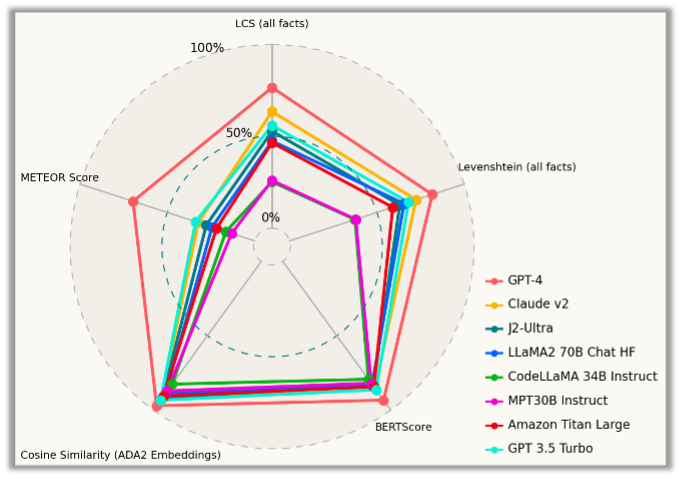
(Bild: Sophos)
Nach reiner Leistung am besten abgeschnitten haben bei allen Benchmarks GPT-4 und Claude v2. Bei der ersten Aufgabe erhält außerdem das Modell CodeLlama-34B eine lobende Erwähnung für sein gutes Abschneiden. Nach Ansicht der Forscher ist es ein konkurrenzfähiges Modell für den Einsatz als SOC-Assistent.
Weitere Details und Auswertungen der verschiedenen Aufgaben finden sich im englischen Blogbeitrag von Sophos.


(ur)
