

DarkBERT is trained with data from the Dark Web – ChatGPT's dark brother?
Researchers have developed an AI model trained with data from the Darknet – DarkBERT's source are hackers, cybercriminals, and the politically persecuted.

(Bild: BeeBright/Shutterstock.com)
- Silke Hahn
(Dieser Artikel existiert auch auf Deutsch.)
A South Korean research team has combed the Tor network for a dataset to train large language models (LLMs). The unconventionally sourced data comes exclusively from the darknet, potentially hackers, cybercriminals, and fraudsters – as well as the politically persecuted and others who value or need anonymity, whether for opaque business or for the unsupervised exchange of information under, say, a repressive regime.
The DarkBERT model is created with this sort of training data, and, in terms of its capabilities, it is said to be "equal or slightly superior" to other Large Language Models (LLM) of the same architecture type (BERT and RoBERTa). Such are the results of initial tests, as the team reports in a preliminary research report at arXiv.org. It is better not to entrust it with atomic code or confidential information in general – but the same applies to generative AI systems in general.
Dark Web speaks differently than the Clear Web

(Bild: DarkBERT: A Language Model for the Dark Side of the Internet)
Here are the facts: According to their own statements, DarkBERT's creators have no intention of usurping world domination or pouring content from the hidden internet into the visible realm of the internet (Clear Web), although they have given their work a dark note by naming it so. With DarkBERT, they want to investigate the advantages and disadvantages of a domain-specific model for the Deep Web in various use cases.
DarkBERT should shed light on the Darknet
The goal of the research is to further open up the language of the Darknet, the report's preface states. Language models developed specifically for the dark web could "provide valuable insights". The South Korean team considers an appropriate representation of the darknet in a large language model important to tame the lexical and structural diversity that apparently distinguishes this space from the visible realm of the clear web. The goal, according to the researchers, is security research and the creation of an AI model with contextual understanding for the Darknet domain.
Videos by heise
The initial question of the project was whether targeted training on data from the Darknet gives an LLM better contextual understanding of the language of this domain than training with data from the freely accessible "near-surface" internet. To obtain the data, the team connected a language model to the dark web using Tor and collected raw data via crawl, which they used to create a model in a second step. The researchers then compared the new model with existing AI models of the type BERT (Bidirectional Encoder Representations from Transformers) developed by Google and its improved architecture RoBERTa (Robustly Optimized BERT Pre-training Approach).

(Bild: DarkBERT: A Language Model for the Dark Side of the Internet)
Target Group: Cybersecurity Authorities and Law Enforcement
As expected, DarkBERT outperformed them both in tests on the Darknet through its domain knowledge – at least slightly. BERT is now considered slightly outdated in the face of powerful GPT-type transformer models, but has been made open source by Google and researchers continue to use the model type for replication studies. DarkBERT is a post-trained RoBERTa, according to the preprint, into which two datasets were fed over two weeks: once the crawled raw data and the second time a pre-processed form of the dataset.
The target group is not cybercriminals, but law enforcement agencies that search the darknet to fight cybercrime. Most prevalent on the darknet, according to the preprint, are fraud and data theft, and allegedly the darknet is also used for anonymous organized crime conversations. What is interesting about the approach is that the Dark or Deep Web is an area of the internet that search engines like Google hide and where the majority of people do not (or do not regularly) browse because special software is needed to do so.
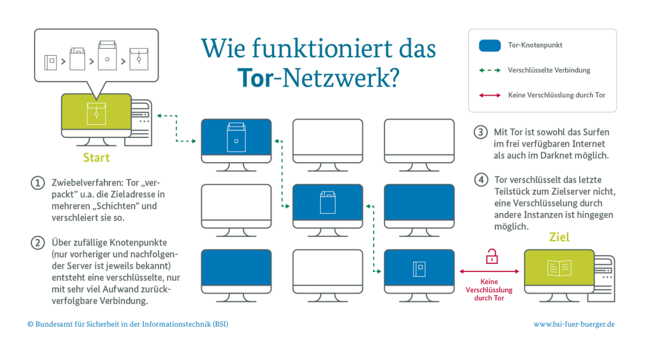
(Bild: BSI)
Anonymity also important for Journalists and Opposition
In principle, anonymous surfing on the net would be interesting for all people who care about their privacy and do not want to flush their data into the pool of big tech companies that have made data collection or targeting through personalized advertising their business model (like Google). Journalists, opposition activists and politically persecuted people also use the darknet, for example, to access regionally blocked and censored content. The Tor browser is initially nothing more than an overlay network for anonymizing connection data; its logo and acronym stand for the onion principle (written out in full, the acronym is "The Onion Router"). Tor protects its users from having their data traffic analysed, for example when browsing, chatting and sending mail.
Empfohlener redaktioneller Inhalt
Mit Ihrer Zustimmung wird hier ein externes YouTube-Video (Google Ireland Limited) geladen.
Ich bin damit einverstanden, dass mir externe Inhalte angezeigt werden. Damit können personenbezogene Daten an Drittplattformen (Google Ireland Limited) übermittelt werden. Mehr dazu in unserer Datenschutzerklärung.
Those who find the available models too soft-pedalled and empathetic due to Reinforcement Training with Human Feedback (RLHF) might enjoy DarkBERT – or would be disappointed in the end if the "dark" variant destroys myths about the nature of the Dark Web and the output turns out to be more trivial than expected. Moreover, the near-surface internet is not famous for niceness. DarkBERT is not freely available and there are no plans to make the model available to the public, the arXiv preprint reveals.

(Bild: DarkBERT: A Language Model for the Dark Side of the Internet)
No Publication Planned
For cybersecurity agencies, similar approaches could be interesting if combined with real-time search, for example to monitor relevant forums or illegal activities. It is to be hoped that such approaches do not fall victim to the last protected spaces of the internet, where surveillance and censorship are not yet effective.
It is not known whether law enforcement agencies will be granted access, but requests for academic research purposes will be accepted. Considering that LLaMA was also made accessible in this form by Meta AI / FAIR (Facebook AI Research) and quickly leaked, it is conceivable that DarkBERT could circulate unofficially in the foreseeable future - for example on the Darknet.
(sih)
