

Die Zukunft der Archive: Ein Gedächtnis fürs Internet und Quellcode
Und das Netz vergisst doch: Die Lebensdauer einer Webseite beträgt im Schnitt 100 Tage, sagt der Gründer des Internet Archive.

(Bild: rawf8/Shutterstock.com)
Tatsächlich ist das Internet allen anders lautenden Aussagen zum Trotz ziemlich vergesslich. Projekte wie das Internet Archive bemühen sich daher um langfristige Bewahrung und Bereitstellung. Das Thema Web-Archivierung bildete auch einen Schwerpunkt auf der Konferenz zur "Bewahrung digitalen kulturellen Erbes" an der Deutschen Nationalbibliothek in Frankfurt am Main Ende November.
Dissertationen und Katzenvideos
Der Begriff "kulturelles Erbe" wurde von den Konferenzteilnehmern mit gutem Recht sehr weit gefasst, im Prinzip gehört dazu jede Spur, die Menschen hinterlassen und meint damit alles, was potentiell von einer Generation auf die andere übertragbar ist. Das sind im Hinblick auf das Netz nicht nur Nachrichtenseiten, Dissertationen oder Lehrvideos, sondern eben auch Katzenvideos, Beiträge in Modelleisenbahnforen oder das "Techno Viking"-Meme in all seinen Varianten und Verästelungen.
In seinem Konferenzbeitrag machte der Historiker Peter Webster deutlich: Das Internet ist nicht sein eigenes Archiv. Er verwies dabei auf eine Studie der British Library, die anhand umfangreicher Stichproben belegte, dass nach 10 Jahren lediglich wenige Prozent der erfassten Webseiten unverändert unter der ursprünglich erfassten URL abrufbar waren.
Das 1996 gegründete und in San Francisco ansässige Internet Archive geht dieses Problem an. Mit aktuell 345 Milliarden Webseiten und einem Speichervolumen von bald 20 Petabytes ist es das umfangreichste Webarchiv weltweit. Daneben stellt das Archiv Bücher, Musik, Videos, Zeitschriften und sogar im Browser spielbare Games bereit.
Die rechtliche Grundlage der Arbeit des Internet Archive ist die in den USA gültige Regelung "Fair Use", die "bestimmte, nicht autorisierte Nutzungen von geschütztem Material zugesteht, sofern sie der öffentlichen Bildung und der Anregung geistiger Produktionen dienen". Diese Regelung gilt in Europa zum großen Bedauern vieler Kulturbewahrer nicht.
Spielarten der Datenernte
Eine vollständige Archivierung des Web ist schon angesichts der schieren Datenmenge, der fortwährenden Wandlung und dynamisch generierter Inhalte nicht machbar. Es stellt sich also die Frage: welche Auswahlmechanismen steuern die Datenernte?
Mehrmals im Jahr ernten sogenannte "wide crawls" ausgehend von einer umfangreichen "seed list" von Einstiegspunkten. Der kostenpflichtige Service Archive-It und "contract crawls" bieten zudem die Möglichkeit, definierte Ernten zu fahren. So sucht und sichert das Internet Archive für die Neuseeländische Nationalbibliothek regelmäßig alle auf .nz endende Domains sowie Seiten, die Texte in Maori enthalten.
Nicht zuletzt bietet ein "Save Page Now” Formular jedem Nutzer die Möglichkeit, einzelne Seiten zu speichern. Dieses Angebot sichert eine Demokratisierung der Webarchivierung. Es ist zudem für Wissenschaftlerinnen und Wissenschaftler von Nutzen, die eine Internetquelle wasserdicht zitieren möchten. Weiterhin tragen auf diesem Weg auch Bots dazu bei, verschiedene Interessen zu wahren und die gezielte Archivierung bestimmter Webseiten sicherzustellen.
Die Zeitlichkeit des Web
Das prominenteste Werkzeug zur Suche im Webarchiv ist die Wayback Machine. Ausgehend von einer gegebenen URL versammelt sie alle im Archiv verfügbaren Snapshots. Auf diese Weise lässt sich etwa die Geschichte von heise.de gründlich studieren. Die URLs der mittels Wayback Machine aufgerufene Snapshots haben grundsätzlich diese Struktur: https:/web.archive.org/web/[Zeitstempel]/[URL].
heise online in der Wayback Machine (7 Bilder)
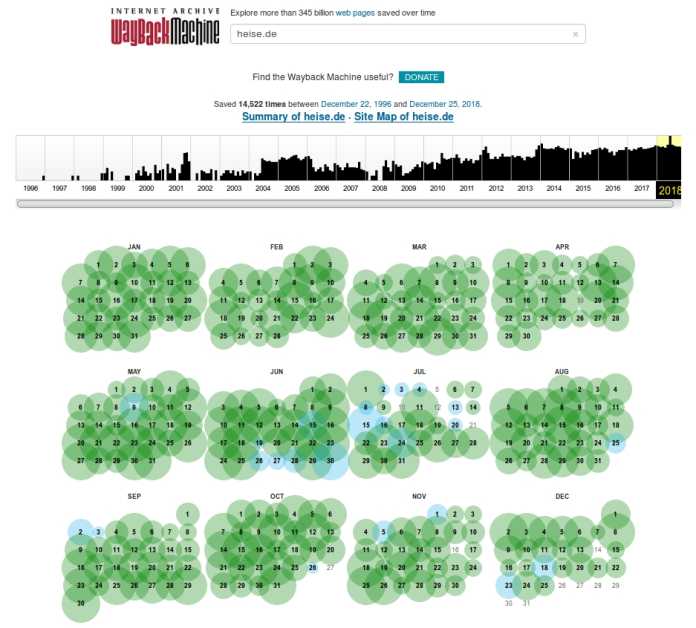
Die Wayback Machine öffnet historische Webseiten im jeweils aktuell verwendeten Browser. Das ist dann ein Problem, wenn die Webseiten veraltende Technologien wie Flash oder eingebettetes Java verwenden. Nebenbei bemerkt: Der nicht zum Internet Archive gehörende Webrecorder bietet angemeldeten Nutzern die interessante Möglichkeit, aufgerufene Webseiten einschließlich des dabei verwendeten Browsers aufzuzeichnen.
Der für das Internet Archive tätige Softwareentwickler Helge Holzmann machte darauf aufmerksam, dass Webarchive dem Netz eine Zeitdimension hinzufügen. Ein gewöhnliches Browsen ruft immer aktuelle Zustände des Web auf. Das komplette Web stellt so gesehen die Umwelt einer bestimmten Webseite dar. Die Nutzung eines Webarchives hat etwas von einer Zeitreise, die sogar schrittweise vorwärts und rückwärts ablaufen kann: Wenn Sie einen Link auf einer archivierten Webseite anklicken, verweist dieser auf einen weiteren archivierten Inhalt. In den seltensten Fällen besitzt dieser einen identischen Timestamp. Es wird dann jeweils der zeitlich nächstgelegenen Snapshot aufgerufen.
Zeitbasierte Suche mit Tempas
Diese Zeitlichkeit kann bei Suchen in Webarchiven insbesondere dann Schwierigkeiten aufwerfen, wenn der Suchbegriff auf Seiten auftaucht, die besonders häufig gespeichert wurden. Eine Suche kann unter diesen Umständen hunderte von sehr ähnlichen Seiten liefern – ein Rankingverfahren für die Relevanz muss her.
In seinem Konferenzbeitrag stellte Holzmann Werkzeuge zur Arbeit mit Webarchiven vor, an deren Entwicklung er beteiligt war.
Ein Rankingverfahren stellt das von Holzmann vorgestellte Tool Tempas aus dem Alexandria Projekt bereit. Die erste Version von Tempas verwendete Daten der Social Bookmarking Seite Delicious. Version zwei nutzt Webgraphen zur Bewertung. Das adressiert zugleich ein weiteres Problem der Webarchivsuche: Wer nicht weiß, dass etwa die primäre Webpräsenz von Angela Merkel mehrmals umgezogen ist, findet bei einer Suche in der Wayback Machine nach www.angela-merkel.de relevante Inhalte unter Umständen nicht. Tempas erkennt Webseiten, die gesuchte Entitäten repräsentieren, und erleichtert hier die Suche.
Ein weiteres Werkzeug aus dem Alexandria Projekt ist ArchiveSpark, ein Big Data Processing Tool speziell für Webarchive. ArchiveSpark widmet sich dem Problem, dass die Archive oft eine Größe von mehreren Petabyte haben, so dass eine effiziente Suche direkt auf den Daten kaum möglich ist. Stattdessen operiert das Tool auf leichtgewichtigen CDX-Dateien, die lediglich Metainformationen enthalten.
Archivierung von Quellcode
Auf der Frankfurter Konferenz stellte Stefano Zacchiroli die Arbeit der Initiative Software Heritage vor. Deren Ziel ist nichts Geringeres als "allen Quellcode, der jemals geschrieben wurde zu sammeln, zu konservieren und zu teilen".
Die Motivation dieses gewaltigen Vorhabens ist die von Zacchiroli vertretene Auffassung, dass ein rapide wachsender Teil des Menschheitswissens in Software und den zugehörigen Quellcodes verkörpert ist. Versionskontrollsysteme bieten sogar die Möglichkeit, die Evolution des so bezeichneten Wissens nachzuvollziehen.
Das Archiv von Software Heritage umfasst aktuell rund 5 Milliarden Quellcodedateien von rund 20 Millionen Autoren. Mittels der Suchfunktion finden Sie zum Beispiel den Code des Egoshooters Quake III.
Bei aktuellen Open Source Projekten ist eine ergiebige und automatisierte Datenernte über das Mitschneiden von Diensten wie GitHub und GitLab gut möglich. Die Sicherung von Quellen proprietärer und historischer Anwendungen stellt eine ungleich größere Herausforderung dar.
"Quellcode als Teil des kulturellen Gedächtnisses der Menschheit"
Interview mit Stefano Zacchiroli von Software Heritage
heise online: Bei digitaler Langzeitarchivierung sind Fragen nach der Struktur des Archives und der Werkzeuge für Zugriff, Analyse und Auswertung entscheidend. Welche Leitlinien verfolgen Sie bei der Entwicklung von Archiv, Tools und API?

(Bild: Ralf.treinen, CC BY-SA 3.0 )
Stefano Zacchiroli: Wir möchten sicherstellen, dass unser Quellcodearchiv auch in Jahrtausenden noch nutzbar ist – also wenn alle Personen und Institutionen, die das Archiv gegründet haben, längst verschwunden sind. Um das wahrscheinlicher zu machen, verfolgen wir zwei grundlegende Prinzipien: Transparenz und Redundanz.
Transparenz heißt ganz praktisch: Alle Software, die wir selbst für das Projekt schreiben, ist Open Source und wird es immer bleiben; wir halten uns dabei an die bewährten Praktiken der Open-Source-Entwicklung mit öffentlichen Bugtrackern und dergleichen.
Was die Redundanz angeht: Wir bauen an einem weltweiten Netzwerk von unabhängigen Kopien, gehostet von unterschiedlichen Institutionen und in verschiedenen Ländern. Auf diese verhindern wir, dass die Entscheidungen einzelner Personen, Institutionen oder Regierungen die Existenz des gesamten Archives gefährden können.
Sie sagen, dass Quellcode einen wachsenden Anteil des Wissens der Menschheit verkörpert. Das ist offensichtlich, wenn wir über Informatik oder Technikgeschichte sprechen. Was sind Beispiele für Forschungsfragen aus anderen Wissensgebieten, die man mittels Ihres Archiven untersuchen kann?
Forschungsprojekte, die Quellcodes untersuchen, sind in der Regel tatsächlich im Bereich der Informatik angesiedelt. Aber ganz allgemein ist Software ein wesentlicher Bestandteil der meisten wissenschaftlichen Untersuchungen, egal in welchem Bereich: Das gilt für die Mathematik, wo man einen wachsenden Anteil von komplexen Theoremen mittels halbautomatischer Verfahren beweist. Es gilt aber auch für die exakten Wissenschaften, wo man oft riesige Datenmengen prozessiert, um Resultate zu finden. Auch in den Sozialwissenschaften nimmt die Bedeutung von Software zu.
Fehler in Forschungssoftware können schlimme Folgen haben, das hat etwa die "Excelgate Affäre" für den Bereich der Ökonomie gezeigt. Der Quellcode einer jeden Software, die in ein wissenschaftliches Experiment eingebunden ist, muss Gegenstand von Peer Review sein und für die Nachwelt erhalten werden. Das sollte eine sehr hohe Priorität haben. Es gibt keine Rechtfertigung dafür, dass Software aus wissenschaftlichen Experimenten anders behandelt wird als die Publikationen, die diese Experimente beschreiben.
Die Quellcodes von proprietärer Software zu sammeln, scheint eine der größten Herausforderungen Ihrer Arbeit zu sein. Wie gehen sie das Problem an? Sind Sie im Dialog mit Softwareherstellern?
In den ersten Jahren von Software Heritage haben wir uns auf die Sammlung öffentlich verfügbarer Quellcodes konzentriert. Wir haben da eine Dringlichkeit gesehen: Mehrere wichtige Filehostingdienste für Softwareprojekte wurden damals eingestellt oder kündigten die Einstellung an – wir hatten einfach Angst, Quellen zu verlieren.
Aber natürlich enthält auch Closed Source kostbares Wissen, es ist nur wesentlich schwieriger, das zu sammeln, zu bewahren und vor allem – aufgrund von Lizenzbeschränkungen – zu teilen. Unsere Langzeitstrategie für dieses Problem ist einerseits die Unterstützung von "embargoed source-code deposits" (in etwa "Quellcode-Archive unter Embargo"). Mit solchen Deposits kann die Wissensspeicherung auch für Closed Source erst einmal losgehen. Der öffentliche Zugriff wird auf einen Zeitpunkt verschoben, zu dem die lizenzrechtlichen Bestimmungen diesen erlauben.
Andererseits planen wir, die gezielte Suche nach historisch bedeutsamem Quellcode zu koordinieren und zu unterstützen. Der soll dann ins Software Heritage Archiv wandern und nach Möglichkeit "befreit", also öffentlich verfügbar gemacht werden.
Sie haben mit Milliarden Quelldateien zu tun und müssen dabei wohl eher das große Ganze im Blick behalten. Trotzdem: Gibt es ein File oder ein Projekt im Archiv, das sie besonders gern mögen?
Ein Lieblingsstück von den meisten hier bei Software Heritage ist der Code der Mondmission Apollo 11. Nicht nur weil dieser Code buchstäblich die ersten Menschen auf den Mond befördert hat. Sondern auch, weil dessen Entwicklung den Beginn des Software Engineering markiert. Diese Disziplin wurde von Margaret Hamilton begründet, der Leiterin des Entwicklungsteams der Apollo 11 Software.
Apollo 11 (5 Bilder)

Geisteswissenschaften operieren viel mit Texten, und Quellcode ist eine bestimmte Textsorte, vielleicht sogar eine bestimmte Sorte von Literatur. Ergibt die Aussage für Sie Sinn, dass ihre Arbeit Teil der "digital humanities", der digitalen Geisteswissenschaften ist?
Der Begriff "digital humanities" bezieht sich ganz allgemein auf den Gebrauch von Computern und Software zur automatisierten Auswertung menschlicher Artefakte. Aber Sie gebrauchen den Begriff hier in einer hübschen Wendung! Ganz sicher betrachten wir, gemeinsam mit der UNESCO, Quellcode als Teil des kulturellen Gedächtnisses der Menschheit, der bewahrt werden muss.
Wie können Privatpersonen, institutionelle und wirtschaftliche Akteure Ihre Arbeit unterstützen?
Danke für die Frage! Wir laden Programmierer dazu ein, uns bei der Entwicklung der Software zu unterstützen, die wir für das Projekt brauchen. Firmen und Institutionen können sich an unserem Unterstützungsprogramm beteiligen, und wir freuen uns auch über Spenden von Einzelpersonen. (mho)
