

Fermis goldene Regel
Nicht ganz zufällig stellte Nvidia einigen ausgewählten Journalisten die Architektur der nächsten GPU-Generation schon drei Wochen vor der hauseigenen GPU-Konferenz vor, just als AMD seine DirectX11-Karten auf dem Flugzeugträger USS Hornett präsentierte und nur wenige Tage vor Beginn des Intel Developer Forums. Als „Störoperator“ besonderer Art soll Nvidias Tesla-Nachfolger namens Fermi die Konkurrenz geradezu schocken.
- Andreas Stiller
Während AMD/ATI seine Architektur im Wesentlichen durch Verdopplung der Einheiten hochskaliert, krempelt Nvidia seine GPU-Architektur kräftig um. Sie soll insbesondere auch im Rechenmodus mehr brillieren, etwa bei doppeltgenauen Gleitkommaberechnungen. Hier hat Nvidia mit einer Verachtfachung der Performance massiv nachgelegt. Auch bei anderen Features ist die Firma aus Santa Clara den Wünschen aus dem High Performance Computing (HPC) weit entgegengekommen – allein, man befindet sich noch im frühen Prototyp-Stadium, das erste Tapeout des gigantischen Chips mit drei Milliarden Transistoren (hergestellt von TSMC im 40-nm-Prozess) soll laut Charly Demerjian von semiaccurate.com erst Mitte Juli gewesen sein. Auch wenn Nvidia von ersten GeForce-Karten Ende des Jahres spricht, dauert es erfahrungsgemäß meist länger als ein halbes Jahr bis zu den ersten marktreifen Produkten. Wenn sich die Nvidia-Chips jedoch erst einmal materialisiert haben, dürften sie sich gut gegen ATIs RV800 platzieren können.
Im HPC-Umfeld könnten sie trotz weniger Recheneinheiten gar dominieren. Gegen die beiden GPU-Firmen sieht dann vor allem Intel mit seinem Larrabee recht alt aus – dass Larrabee-Protagonist Pat Gelsinger deshalb vor lauter Frust seinen Hut genommen hat, ist jedoch eine schöne Legende.
Reichlich Zuwachs
Bislang umfasste die GT200-Architektur zehn Thread Processing Cluster (TPC). Jeder dieser Cluster bestand aus drei Streaming Multiprocessors (SM), die sich einen kleinen Write-Through-Cache von 24 KByte teilten. Jeder SM wiederum enthält acht skalare Recheneinheiten (Streaming Processors SP), eine Gleitkommaeinheit für doppeltgenaue Multiplikation und Addition (FMA) sowie zwei Special Function Units (SFU), die mit Tabellen und quadratischer Interpolation arbeiten, um Kehrwert, inverse Wurzel, 2x, log2, sin und cos auszurechnen. Die SFUs arbeiten allerdings nur in einfacher Genauigkeit (sowohl bei GT200/Tesla auch jetzt bei Fermi), für doppelte Genauigkeit müssen diese Funktionen mühsam per Bibliothek berechnet werden.

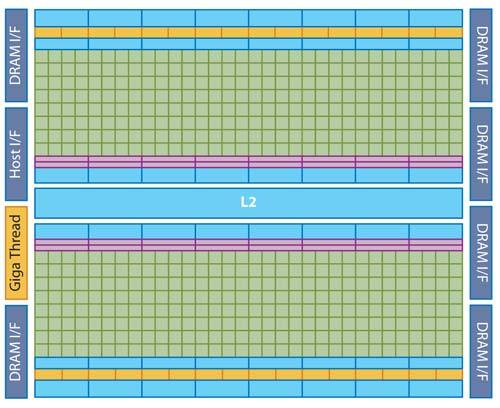
Die neue Architektur besitzt keine Cluster mehr, sondern ein Feld von zwei mal acht SMs, die sich einen L2-Cache (WB) von insgesamt 768 KByte und sechs 64-Bit-Speicherkanäle teilen.
Jeder SM enthält Instruktions-Cache, Decoder, Scheduler, Dispatcher und Registersatz für zwei Pipelines, die die nunmehr 32 Recheneinheiten – bei Nvidia jetzt als Cores bezeichnet – sowie vier Special Function Units versorgen. Hinzu kommt ein Zwischenspeicher von 64 KByte, der sich in zwei Konfigurationen in einen gemeinsamen lokalen Speicher oder L1-Cache aufteilen lässt: 48 KByte zu 16 KByte oder umgekehrt. 16 Load/Store-Einheiten sorgen für den Datentransfer zwischen den Caches und den Cores.
Insgesamt kommen so 512 Cores und 64 SFUs zusammen, zuvor bei Tesla waren es derer 240 respektive 60.
Mehr Flops
Zwei Cores werden mit weiterer Logik verschaltet, um doppeltgenaue FMA-Operationen auszuführen. Das Performanceverhältnis zwischen einfachen und doppeltgenauen Berechnungen steigt dadurch von derzeit 1 : 8 auf 1 : 2. Berücksichtigt man die mehr als verdoppelte Anzahl der Cores, so hat sich die doppeltgenaue Gleitkommaleistung bei gleichem Takt also mehr als verachtfacht. Statt der theoretischen Spitzenleistung von 78 GFlop/s einer Tesla C1060 bei FMA (Gleitkommamultiplikation und -addition) müsste Fermi also bei gleichem Takt etwa 640 GFlop/s erzielen – das sind etwas mehr als die 544 GFlop/s, die ATI für die Radeon HD5870 spezifiziert hat. Wie viel davon im realen Betrieb etwa bei der Matrixmultiplikation übrig bleiben, ist eine andere Frage. Nvidia spricht hier vom Faktor 4,2 gegenüber der GT200.
Bei einfacher Genauigkeit steht indes Nvidas 512 skalaren Recheneinheiten (Cores) die Übermacht von 1600 Recheneinheiten (Streaming Processing Units) bei ATI RV800 gegenüber, die zu fünft in 320 SIMD-Einheiten verschaltet sind. Um hier besser auszusehen, rechnet Nvidia üblicherweise recht kunstvoll zu der FMA-Leistung der SPs oder Cores noch die Gleitkommaleistung der möglicherweise zusätzlich parallel arbeitenden SFUs (nur einfache Genauigkeit) hinzu. Für die ohnehin sehr theoretische Spitzenleistung ist das zwar legitim, aber sinnvoller wäre die Angabe der theoretischen maximalen FMA-Spitzenleistung. Die reduziert sich dann bei der Tesla C1060 von den beworbenen 933 auf 622 GFlop/s. Fermi würde bei gleichem Takt von 1,3 GHz dann 1,33 TFlop/s FMA-Spitzenleistung abliefern – allerdings weiß man noch nicht, mit welchem Takt Fermi antreten wird.
ATI bezieht zwar auch die Spezialeinheit in der SIMD-Einheit mit in den Spitzenwert ein, aber die kann bei FMA auch tatsächlich als fünftes Rad am Wagen mitwirken. Mit 2,72 TFlops FMA-Spitzenleistung sind ATIs GPUs in diesem Punkt demnach weiterhin klar in Front. Dank niedrigerem Takt von derzeit 850 MHz dürften sie auch erheblich effizienter sein; Angaben zum Energieverbrauch der nächsten Generation hat Nvidia allerdings noch nicht gemacht.
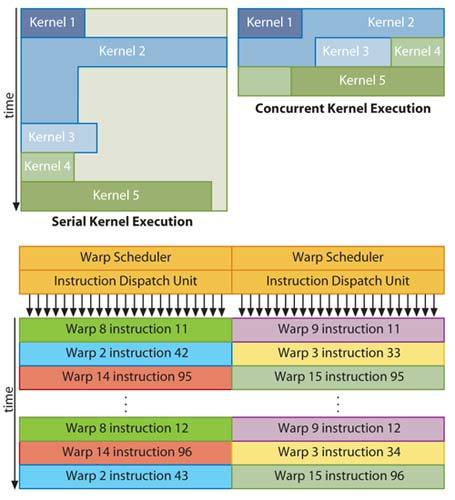
Wichtig für die Performance im praktischen Rechenbetrieb ist außerdem, dass, wie von DirectCompute und OpenCL für Multithreading-Betrieb gefordert, nun auch einzelne Rechenprozeduren (sogenannte Kernels) parallel ausgeführt werden können. Das gilt für kleinere Kernels, die nur einen Teil der Hardware-Ressourcen ausnutzen. Bislang mussten diese einzeln nacheinander ausgeführt werden. Im Grafikbetrieb ist das weniger von Belang, da hier die Kernels typischerweise groß genug sind, um die ganze Hardware auszulasten. Ein SM muss immer den gleichen Code ausführen, sodass maximal 16 Kernels gleichzeitig auf Fermi laufen können.
Bei ATIs RV8xx soll nach den Angaben von AMDs Direktor für Stream Computing, Patricia Harrell, ebenfalls die parallele Ausführung möglich sein, in den bislang veröffentlichten Unterlagen findet man zum Thema „concurrent kernels“ allerdings kein Wort, vielleicht ist das Feature bei ATI einfach selbstverständlich.
Hier wie dort werden die Jobs auf größere Thread-Bündel verteilt: Warps mit 32 Threads bei Nvidia, Wavefronts mit 64 Threads bei ATI. Nvidias „GigaThread-3.0-Engine“ arbeitet zudem mit zwei Warp Schedulers und kann zehnmal schneller den Kontext wechseln als die GT200. Bei jener wurde pro Takt immer nur ein halber Warp auf die Reise geschickt, das geht jetzt über die zwei Dispatch Units doppelt so schnell. FP64- und SFU-Operationen lassen sich allerdings nicht auf zwei Pipelines verteilen. Immerhin blockieren nun SFU-Operationen den SM nicht mehr für ewig lange acht Takte, der zweite Dispatcher kann weiterhin Int32- oder FP32-Befehle verteilen.
Die Zahl der maximal gleichzeitig in Bearbeitung befindlichen Warps in einer SM stieg von 32 auf 48, also auf 1536 Threads pro SM. Andererseits gibt es nun weniger SMs, so sinkt die Gesamtzahl der Threads „in flight“ im Chip von 30 720 auf 24 576. Wichtiger – so Nvidia – ist ohnehin, das Speicherkonzept zu verbessern, als übermäßig viele Threads zur Überbrückung von Wartezeiten vorrätig zu halten. Zusätzlich wurde die Synchronisierung zwischen den Threads bei den atomaren Operationen um Faktor 5 bis 10 schneller. Wenn mehrere Threads auf gemeinsame Daten zugreifen, benötigt man diese atomaren Operationen, um sicherzustellen, dass bei Read-Modify-Write-Zyklen niemand dazwischenfunkt.
Breitere Integers
Nicht nur bei Gleitkomma, auch bei Integer hat Nvidia eine wichtige Erweiterung eingeführt: Die Einheiten rechnen jetzt 32-bittig, zuvor waren es nur 24 Bit (so wie bei ATI weiterhin). Auch zum Rechnen mit 64-Bit-Integern ist die Core-Hardware besser vorbereitet.
Ein weiterer Wunsch der HPC-Szene war der nach mehr Zuverlässigkeit. Dem kommt Nvidia ebenfalls nach: bei Fermi sind alle Caches, Busse und das Register-File (4096 Register à 32 Bit) durch ECC geschützt. Auch der Speicherkanal lässt sich per ECC absichern. Das erfordert mehr Speicherbits und kostet etwas Performance, sodass es für die GeForce-Line nicht genutzt wird.
Und die HPC-Welt hatte noch einen großen Wunsch: mehr Speicherkapazität. Der Speicher ist nämlich der eigentliche Flaschenhals: Wenn Daten laufend zwischen CPU-Hauptspeicher und Kartenspeicher transferiert werden müssen, nützt einem die hohe Rechenperformance auf der Karte gar nichts.
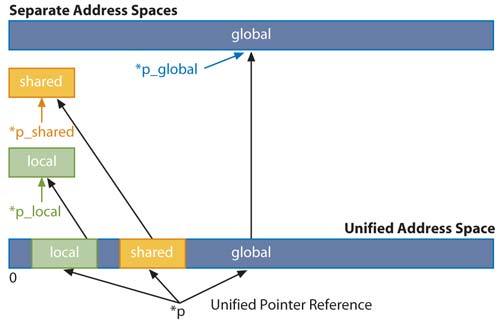
Nvidia hat nun reagiert und die Adressierung von 32 auf 40 Bit – virtuell und physisch – erweitert. Der Adressraum beträgt damit ein Terabyte, was erst einmal ausreichen dürfte. Ein paar Bits in den nun 64 Bit breiten Pointern werden genutzt, um den Speicherort festzulegen, sei es global (_device_ int), lokal (int) oder gemeinsam (_shared_ int) in einer SM. Nvidia nennt das Unified Address Space.
Mit den sechs GDDR5-Speicherkanälen à 64 Bit Breite müsste je nach Speichertakt die Speicherperformance um die Hälfte höher ausfallen als bei der mit vier GDDR5-Kanälen ausgestatteten ATI RV8xx, also theoretisch etwa 240 GByte/s betragen. Zudem fügte Nvidia eine zweite Data Transfer Engine hinzu, die überlappend mit der ersten Datentransfers sowohl zwischen den Speichern von GPU und CPU als auch zwischen zwei Bereichen des GPU-Speichers durchführen kann.
Softes
Ältere Programme dürften wegen der vielen Neuerungen, etwa der erweiterten Integer-Breite nur bedingt und wegen der gegebenenfalls notwendigen Maskierung mit Performanceverlust lauffähig sein, sie sollten mit der neuen CUDA-3.0-Version samt PTX-Assembler 2.0 neu kompiliert werden. CUDA 3.0 unterstützt jetzt auch C++ (mit kleineren Ausnahmen) mit Objekten und Exception-Handling. Fortran, Java und Python für CUDA sind in Arbeit, zum Teil bereis in Betaversion verfügbar (siehe S. 47).
Da die Hardware nun mit Breakpoints arbeiten kann, ist Debugging und Profiling erheblich erleichtert. Ob der neue Debugger Nexus, der sich in Microsofts Visual Studio 2005/8 einklinken kann, auch disassemblieren soll, wird bei Nvidia derzeit noch diskutiert. CUDA 3.0 unterstützt 64-Bit-Adressierung, erzeugt hierfür Standarddateiformate (ELF, Dwarf) und erfüllt die Gleitkomma-Spielregeln gemäß IEEE 754-2008. Berechnungen in einfacher Genauigkeit sollen sogar präziser sein als bei SSE oder Cell. Damit erfüllt es die OpenCL-1.0-Anforderungen und die von DirectCompute von DirectX 11; beide Schnittstellen hatten sich ohnehin weitgehend an CUDA ausgerichtet. Dumm nur, dass das bei Nvidia alles bislang nur auf dem Papier steht und Nvidia zum Windows-7-Start keine Hardware vorweisen kann. Konkurrent AMD/ATI ist da ganz erheblich weiter und wartet rechtzeitig mit DirectX-11-tauglichen RV8xx-Karten auf. Dieses Rennen hat Nvidia also erst einmal verloren. Zudem werden die Nvidia-Chips um ein Drittel größer und dementsprechend teurer sein. Dennoch, wenn alles gut verläuft, dürften in ein paar Monaten die (Grafik-) Karten wieder neu gemischt werden.
Siehe auch den Artikel "Fermissimo" in c't 22/2009 auf Seite 28.
