

MosaicML veröffentlicht großes Open-Source-Sprachmodell für kommerzielle Nutzung
Das KI-Startup MosaicML hat sein eigenes großes Sprachmodell MPT-7B herausgebracht und will es für die kommerzielle Nutzung verfügbar machen.

(Bild: whiteMocca/Shutterstock.com)
Das KI-Startup MosaicML hat sein eigenes großes Sprachmodell (Large Language Model, LLM) MosaicML Pretrained Transformer (MPT-7B) als Open Source veröffentlicht. Im Gegensatz zu bisherigen Modellen ist MPT-7B für die kommerzielle Nutzung vorgesehen.
MosaicML hat das Modell nach eigenen Angaben auf der hauseigenen Plattform in 9,5 Tagen mit einer Billion Token aus englischen Texten und Code trainiert. Damit weist es denselben Umfang auf wie Metas LLaMA 7B, das erst auf Anfrage hin für einzelne Personen freigegeben wird.
MPT ist laut MosaicML für schnelles Training und Inferenz optimiert. Dazu nutzt das Unternehmen den Algorithmus FlashAttention sowie Nvidias FasterTransformer-Bibliothek. Die MPT-Modelle können jedoch auch außerhalb von Foundry, dem von MosaicML entwickelten Framework, mit Standard-Pipelines von HuggingFace trainiert werden.
Kontextlänge von 65.000 Token
Neben dem Basis-Modell MPT-7B hat MosaicML drei auf verschiedene Anforderungen abgestimmte Modelle veröffentlicht: MPT-7B Instruct, MPT-7B Chat und MPT-7B StoryWriter. Instruct wurde mit dem Anweisungsdatensatz Dolly von Databricks und HH-RLHF (Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback) von Anthrophics darauf trainiert, einfache Anweisungen auszuführen und Fragen zu beantworten.
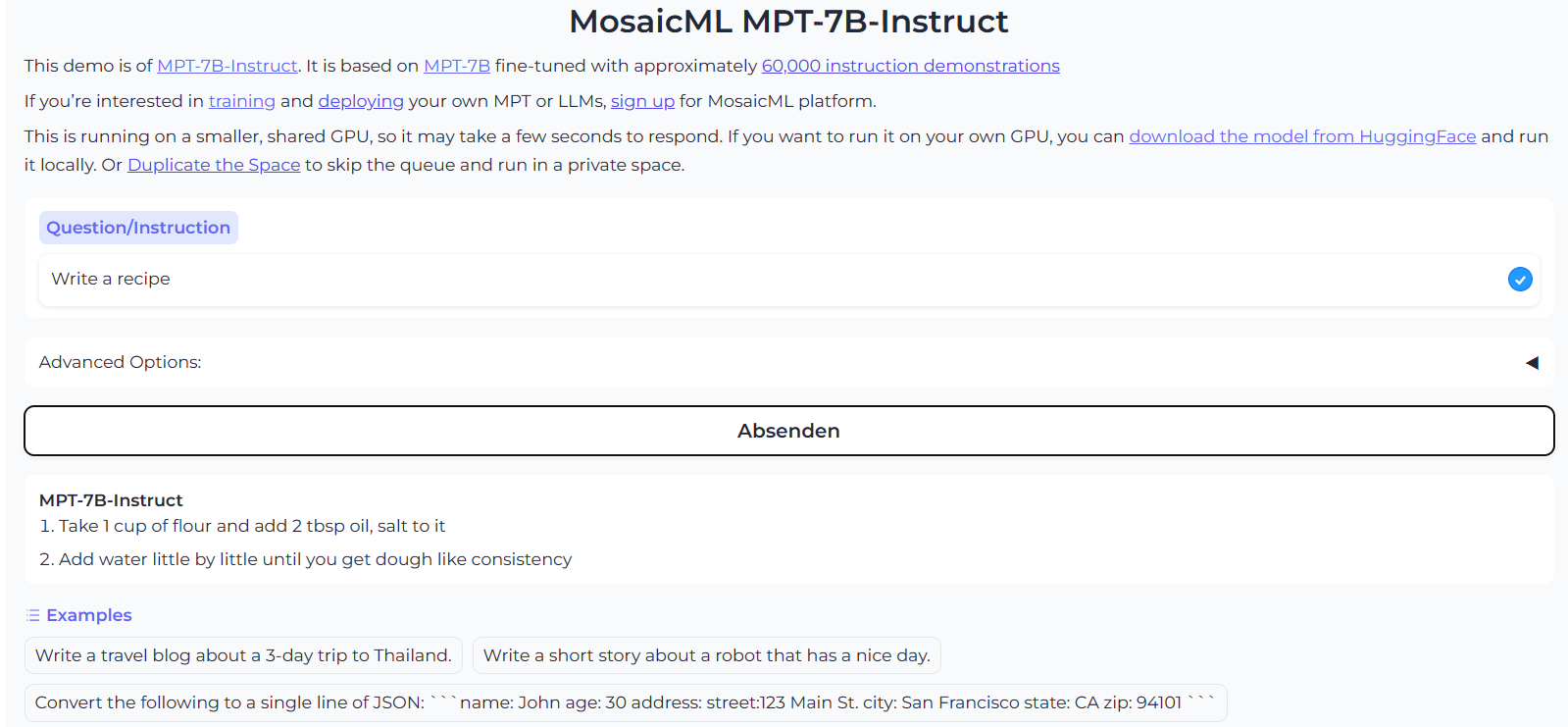
(Bild: MosaicML)
MPT-7B Chat ist eine konversationelle Version des Modells. MosaicML hat sie mit den Datensätzen von HH-RLHF, Vicuna-13B, Human ChatGPT Comparison Corpus (HC3), Alpaca und Evol-Instruct fein abgestimmt.
Videos by heise
StoryWriter liest und schreibt Geschichten mit einer sehr großen Kontextlänge von 65.000 Token. Andere Modelle wie GPT verfügen über geringere Kontextlängen und können entsprechend weniger lange auf zuvor erzeugte Inhalte Bezug nehmen. Zu der großen Kontextlänge verhilft bei StoryWriter ALiBI (Attention with Linear Biases). Für das Training des Modells verwendete MosaicML den books3-Datensatz.
Wer will, kann die MPT-Modelle mit eigenen Datensätzen trainieren und einsetzen – entweder komplett autark oder ausgehend von MosaicMLs Checkpoints. Das MosaicML-Framework zum Weitertrainieren der Modelle steht unter Apache-2.0-Lizenz frei zur Verfügung. Das MPT-7B-Basismodell ist ebenso wie StoryWriter unter Apache-2.0-Lizenz frei verfügbar – Instruct unter CC-By-SA-3.0-Lizenz und das Chat-Modell für die nicht kommerzielle Nutzung unter CC-By-NC-SA-4.0-Lizenz.
Lizenzierung für kommerzielle Nutzung umstritten
Einige kritisieren die freie Verfügbarkeit zur kommerziellen Nutzung bei StoryWriter. "Wenn Sie das Modell auf Basis des books3-Datensatzes mit 197.000 urheberrechtlich geschützten Werken optimieren, sind Sie dann sicher, dass Sie das Recht haben, das Modell kommerziell zu relizenzieren? Meta konnte LLaMA nicht lizenzieren, weil sie das Copyright-Gesetz kennen", schreibt beispielsweise der Twitter-Nutzer alexjc.
Das Framework MosaicML basiert auf einer Spark-Plattform von Databricks und stellt verschiedene Machine-Learning-Algorithmen bereit. Es unterstützt auch die Erstellung von Modellen mit einem Jupyter Notebook oder einer JupyterLab-Instanz.
Trainieren von KI-Modellen teuer
Naveen Rao hatte MosaicML 2020 mitgegründet. Zuvor hatte er sein 2016 gegründetes, unter anderem auf Deep Learning spezialisiertes KI-Unternehmen Nervana Systems, für ungefähr 408 Millionen US-Dollar an Intel verkauft. Damit wollte er auch kleineren Unternehmen ermöglichen, ihre eigenen Daten zu trainieren.
Da gerade das Trainieren von großen KI-Modellen teuer und zeitaufwendig ist, hat Rao zusammen mit seinen Kollegen ein Cloud-basiertes Trainingssystem auf den Markt gebracht. Damit soll das maschinelle Lernen durch ein "Mosaik" verschiedener Methoden effizienter gemacht und das Training somit beschleunigt werden. MosaicML fungiert dabei unter anderem als Dienstleister für die Cloud-Infrastruktur und setzt bei Bedarf Google Cloud, AWS, aber auch On-Premises-Architekturen ein.

"Wir entwickeln Methoden, die das Trainingsverfahren modifizieren, um Kompromisse zwischen der endgültigen Modellqualität und dem Zeit- oder Kostenaufwand für das Trainieren des Modells zu optimieren", schreibt MosaicML in einem Blogpost. Mögliche Methoden stellt das Unternehmen in einer Open-Source-Bibliothek "Composer" bereit, die zu schnelleren und kostengünstigen Training neuronaler Netze verhelfen soll.
Mit dem Visualisierungstool "Explorer" sollen Entwickler die Ausführung der Modelle simulieren, kartieren und auswählen können. Dabei vergleiche Mosaic "Kosten, Qualität und die Zeit", die für die Ausführung nötig ist.


(mack)