

KI optimiert Compiler in Googles MLGO-Framework für LLVM
Das MLGO-Framework nutzt Reinforcement Learning, um beim Kompilieren die Codegröße zu reduzieren und die Performance der übersetzten Anwendung zu verbessern.

(Bild: Phonlamai Photo/Shutterstock.com)
Google hat mit MLGO ein Framework veröffentlicht, das die Compilerarchitektur LLVM mit Methoden des Machine Learning (ML) optimiert. Es ersetzt unter anderem beim Inlining die heuristischen Ansätze durch Reinforcement Learning (RL). Das "GO" im Namen hat nichts mit Googles Programmiersprache Go zu tun, sondern steht für "Guided Optimizations".
Gut beobachtete Strategie
Reinforcement Learning oder bestärkendes Lernen arbeitet mit einem ML-Agenten, der seine Umgebung beobachtet und über eine Art Belohnungssystem erkennt, wie effizient sein Vorgehen für die Aufgabenstellung ist. Es verfolgt einen Trial-and-Error-Ansatz und kann unter anderem effizient Strategien für Brett- und Videospiele erarbeiten. AlphaGo hat RL genutzt, um die Auswirkung seiner Züge auf den Ausgang der Partie zu bewerten.
Videos by heise
Die auf arxiv zu findende Abhandlung "MLGO: a Machine Learning Guided Compiler Optimizations Framework" sieht in RL zwei Vorteile gegenüber den von Menschen erstellten Heuristiken, die LLVM derzeit zum Optimieren nutzt. Zum einen fehle es für die Heuristiken an Beispielen zum Optimieren und zum anderen ließen sich mit RL unterschiedliche Strategien ausprobieren und die Ergebnisse in den Lernprozess des Modells einbeziehen.
Inline statt Funktionsaufruf
Zum Start zielt MLGO auf zwei Bereiche der Compileroptimierung: die Inline-Ersetzung (Inlining) und die Registerzuteilung (Register Allocation, regalloc). Ersterer Ansatz ersetzt Funktionsaufrufe durch den Funktionskörper und kopiert dessen Code direkt in den Ablauf. Damit entfällt der Overhead vom Aufruf. Je nach Struktur kann Inlining die Performance verbessern und die Größe des Builds verringern, allerdings kann es auch dazu führen, dass das Kompilat durch häufiges Kopieren derselben Codezeilen an unterschiedliche Stellen deutlich umfangreicher wird.
Verschachtelte Funktionsaufrufe erschweren das Abwägen zwischen Kosten und Nutzen. Hier setzt bisher die Heuristik und mit MLGO das Reinforcement Learning an, um zu erkennen, ob die Inline-Ersetzung den kompilierten Code verbessert oder verschlechtert. Im Google-Blog findet sich ein Beispiel, das eine Steilvorlage für Inling ist:
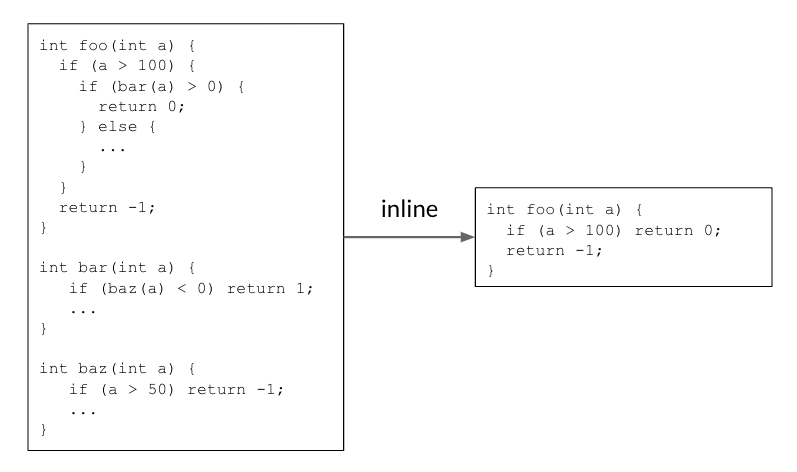
(Bild: Google)
Der Compiler fragt beim Abarbeiten des Call-Graph, der den Ablauf der Funktionsaufrufe repräsentiert, jeweils das RL-Modell, ob es Inlining für einen bestimmten Aufruf als sinnvoll erachtet. Das Modell setzt auf gradientbasierte Optimierung (Policy Gradient) und Evolutionsstrategien (Evolution Strategies). Für das Training des RL-Modells führt der Compiler Buch über die getroffenen Entscheidungen und das Ergebnis der Optimierung. Das Log dient nach dem Kompilieren dem Trainer zum Update des Modells.

(Bild: Google)
Schlank registriert
Die Registerzuteilung versucht die Performance zu verbessern, indem es die Zuteilung lokaler automatischer Variablen auf die begrenzte Zahl der Register im Prozessor optimiert. Auch hierfür existieren heuristische Ansätze, die MLGO durch Reinforcement Learning ersetzt.
Google hat für das regalloc-Training den Code für die hauseigene Software genutzt. Laut dem Blogbeitrag zu MLGO lassen sich die Ergebnisse soweit generalisieren, dass das Modell für unterschiedliche Software im Rechenzentrum des Internetriesen einen um 0,3 Prozent bis 1,5 Prozent verbesserten Wert der Abfragen pro Sekunde (Query per Second, QPS) erreicht hat. Für das Inlining diente Googles Open-Source-Betriebssystem Fuchsia als Testkandidat, und nach den Angaben des Blogbeitrags verringerte die MLGO-Optimierungen die Größe der C++-Übersetzungseinheiten um 6,3 Prozent.
Offen für alles
MLGO ist als Open-Source-Projekt auf GitHub verfügbar. Laut Google ist es für beliebige Anpassungen offen, seien es bessere RL-Algorithmen oder Compileroptimierungen jenseits von Inlining und Register Allocation. Teil des GitHub-Repositories ist eine Demo, die gradientbasierte Optimierung für das Inline-Ersetzen nutzt.
(rme)
