

Machine Learning: CML schickt Daten und Modelltraining in die Pipeline
Die Entwickler des ML-Versionierungstool DVC haben mit CML ein Projekt für die Integration von Machine-Learning-Projekten in CI/CD-Pipelines gestartet.

(Bild: vs148/Shutterstock.com)
Kurz nach der Veröffentlichung von Data Version Control 1.0 (DVC) haben die Entwickler des Open-Source-Tools mit CML ein neues Werkzeug vorgestellt, das sich um die Integration von Machine-Learning-Anwendungen (ML) in die Prozesse von Continuous Integration und Continuous Delivery kümmert. Das quelloffene Projekt bietet eine Anbindung an die CI/CD-Prozesse von GitHub und GitLab.
Das Tool knüpft dort an, wo Data Version Control aufhört. Letzteres ist Ende Juni nach drei Jahren Entwicklungszeit in Version 1.0 erschienen und kümmert sich um die Versionierung von Machine-Learning-Anwendungen während der Entwicklung. DVC verwaltet nicht den Quellcode, sondern die in ML-Projekten benötigten umfangreichen Daten und die Machine-Learning-Modelle, aus denen es Metadaten in Textform erstellt. Entwickler können Letztere über Git verwalten und die eigentlichen Daten beispielsweise in der Cloud speichern.
Videos by heise
Herausforderungen für MLOps und CI/CD
Continuous Machine Learning (CML) heißt das neu gestartete Projekt, das den nächsten Schritt nach der Versionierung geht und ML-Projekte in CI/CD-Pipelines einbinden soll. Teams bekommen damit ein Werkzeug an die Hand, dass sie bei der Integration unterstützen soll und dabei die MLOps-Prozesse im Blick hat – die Zusammenarbeit zwischen Data Scientists und operativen Mitarbeiten analog zur Kooperation von Softwareentwicklern und Systemadministratoren im DevOps-Umfeld.
Ähnlich wie DVC einige Hindernisse bei der Versionierung wie das Verwalten der großen Datenmenge angeht, widmet sich CML den spezifischen Herausforderungen für Machine-Learning-Projekte bei der CI/CD-Integration, darunter die Abhängigkeit zu umfangreichen Datenmengen im Gigabyte-Bereich und den hohen Anforderungen an die Rechenleistung beim Training von Modellen.
(Bild: DVC.org)
Zudem können Teams in der herkömmlichen Softwareentwicklung klare Grenzen festlegen, wann ein Modul als gut gilt und in der Pipeline weiterfließt. ML-Projekte sind dagegen von flexibleren Metriken abhängig. Als Beispiel führt der Blogbeitrag zum CML-Start an, dass Werte wie +0,72 % Accuracy und -0,35 % Precision keine eindeutige Aussage darüber zuließen, ob ein ML-Modell nun gut oder schlecht sei.
Training in der Pipeline
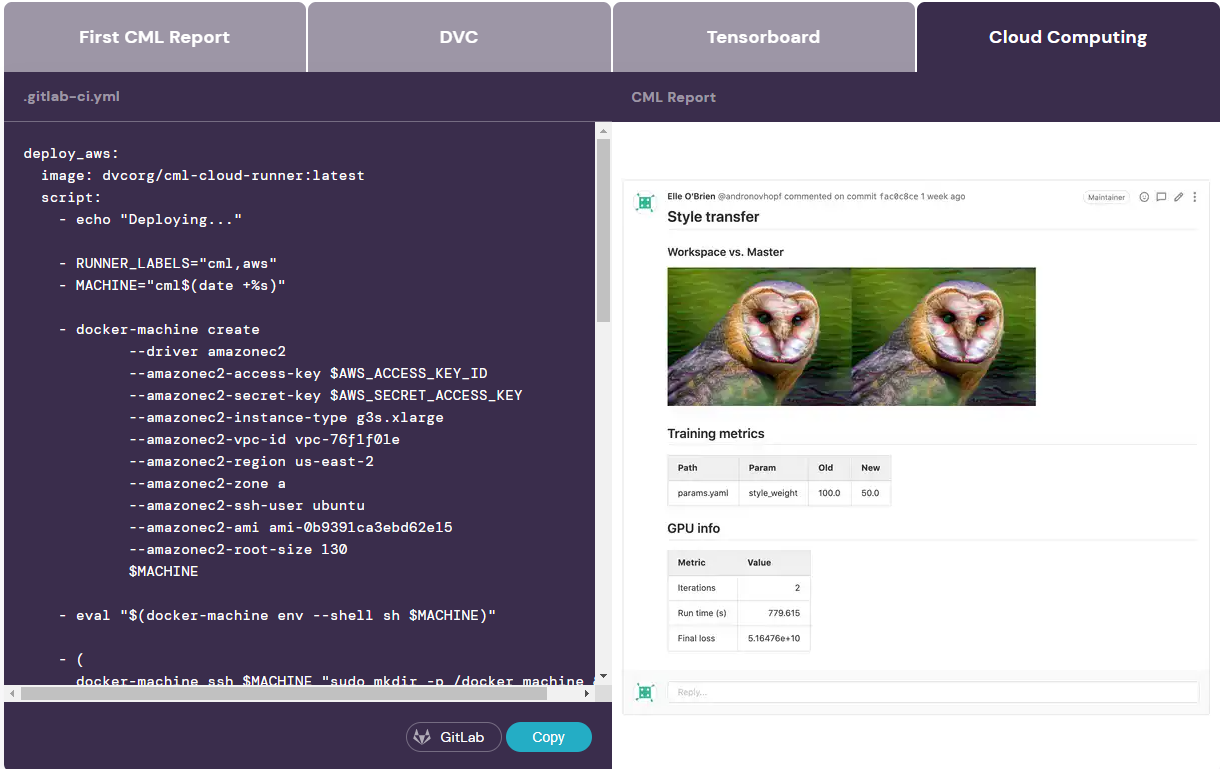
Continuous Machine Learning ist eine Library mit Funktionen für CI/CD-Runners, die sowohl mit GitHub Actions als auch mit GitLab CI zusammenarbeitet. Die Funktionen erstellen unter anderem Reports zu jedem Pull beziehungsweise Merge Request, die zahlreiche Metriken, Plots und Änderungen der Hyperparameter enthalten.
Um das Bereitstellen ausreichender Rechenleistung kümmert sich CML ebenfalls und provisioniert entsprechende GPU- beziehungsweise CPU-Ressourcen bei einer der Cloudplattformen AWS, GCP, Azure oder Alibaba. Die eigentlichen CI-Runners stellt es über Docker Machine bereit. Schließlich nutzt die Library DVC zum Einbinden der Datensätze für das Training und das anschließende Speichern der Modelle in der Cloud.
Data Scientists können die Arbeitsabläufe in den jeweiligen YAML-Dateien bei GitHub beziehungsweise GitLab anpassen. Sie können die CML-Funktionen mit eigenen Aufrufen für das Modelltraining und dem Ausführen von Testing-Skripten kombinieren.
Weitere Details zu CML lassen sich dem Beitrag im DVC-Blog entnehmen. Das Projekt ist auf der separaten Seite CML.dev zu finden. Der Sourcecode findet sich unter Apache-2-Lizenz auf GitHub.
(rme)
