Machine Learning: Free Software Foundation nimmt GitHub Copilot ins Visier

(Bild: sdecoret/Shutterstock.com)
Die Organisation fördert Abhandlungen über die Auswirkungen des "inakzeptablen und ungerechten" ML-gestützten Dienstes für Developer auf Freie Software.
Die Free Software Foundation (FSF) hat einen Call for White Papers rund um GitHub Copilot eingeleitet. Die eingereichten Abhandlungen sollen die Auswirkungen des Machine-Learning-Assistenten auf die Free Software Community analysieren, die mit zahlreichen Fragen verbunden sei. Der Blogbeitrag zum Aufruf verspricht, dass die Organisation alle eingereichten White Papers liest und für jedes veröffentlichte 500 US-Dollar Belohnung zahlt.
Gleichzeitig stellt der Beitrag klar, dass Copilot aus Sicht der FSF "inakzeptabel und ungerecht" sei, da für den Einsatz mit den Microsoft-Produkten Visual Studio oder Visual Studio Code Software erforderlich ist, die aus ihrer Sicht keine Freie/Libre Software ist. An der Stelle sei erwähnt, dass der Sourcecode-Editor Visual Studio Code zwar kostenfrei und im Kern Open Source, aber weit von Freier Software im Verständnis der FSF entfernt ist.
Kopilot als Paarprogrammierer
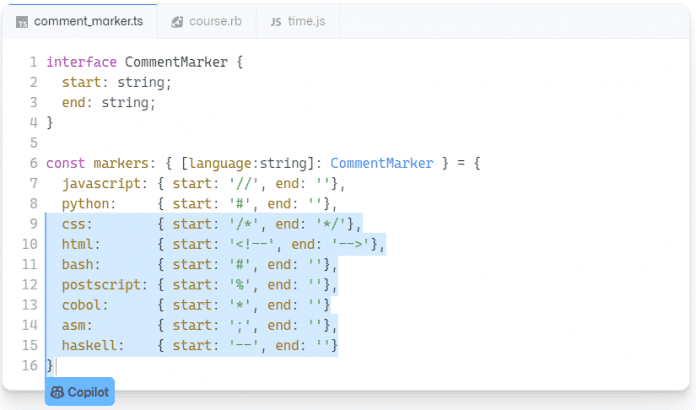
Die Abhandlungen sollen sich aber nicht mit den Werkzeugen, sondern mit den offenen Fragen rund um den Einsatz von Machine Learning (ML) als Codehilfe beschäftigen. Der im Juni vorgestellte Dienst Copilot [1] hilft beim Schreiben von Code; GitHub bezeichnet ihn als "AI Pair Programmer", der wie bei der Paarprogrammierung Vorschläge zum Verbessern und Ergänzen des Sourcecodes gibt.
Die technische Grundlage ist das von OpenAI entwickelte ML-System Codex, das natürliche Sprache in Sourcecode überführt. So versucht Copilot beispielsweise anhand eines Kommentars wie // Get average runtime of successful runs in seconds passenden Sourcecode zu erstellen. Außerdem erstellt er Boilerplate-Code wie Getter und Setter, ergänzt sich wiederholende Definitionen und schlägt passende Unit-Tests vor.

(Bild: GitHub)
Copyright und rechtliche Aspekte
Sein "Wissen" bezieht der Copilot aus zahlreichen offen zugänglichen Repositories, ohne dass GitHub die jeweiligen Verantwortlichen explizit fragt. Dieses "Scrapen von Code" [2] brachte schnell einige Vorwürfe unter anderem auf Twitter [3]. Zwar greift der FSF-Blogbeitrag GitHub Copilot in dieser Hinsicht nicht direkt an, aber die gestellten Fragen lassen durchaus die Intention durchscheinen und wirken daher zu einem guten Teil rhetorisch.
Motivation für den nun gestarteten Call for White Papers ist laut der FSF eine Flut von Anfragen bezüglich der Position der Foundation zu den offenen Fragen um Copilot. Entwicklerinnen und Entwickler wollen demnach wissen, ob das Training eines künstlichen neuronalen Netzes mit ihrer Software als Fair Use bezeichnet werden könne. Umgekehrt fragen sich wohl diejenigen, die grundsätzlich an Copilot interessiert sind, ob von GitHub-Repositories kopierte Elemente wie Code-Snippets potenziell zu Urheberrechtsverletzungen führen. Außerdem gäbe es unter Aktivisten die Fragestellung, ob es nicht grundlegend unfair sei, einen kommerziellen Dienst auf Basis ihrer Arbeit aufzubauen.

Gerade die Copyright-Fragen kommen immer wieder im Zusammenhang mit Machine-Learning-Anwendungen auf. Damit solche Systeme etwas erstellen können, müssen sie zunächst ein Training durchlaufen. Was für Copilot die Sourcecode-Repositories sind, sind für Sprachmodelle wie den Generative Pre-trained Transformer 3 (GPT-3) von OpenAI Texte. Im Bereich der Bildgenerierung wie beispielsweise mit dem ebenfalls von OpenAI entwickelten, an GPT-3 angelehnten DALL-E [4] dürften ähnliche Fragen aufkommen.
GitHub ist sich der Problematik wohl bewusst und adressiert einige Punkte in den FAQ am Ende der Copilot-Seite [5]. Demnach betrachten weite Teile der ML-Community das Training auf Basis öffentlich verfügbarer Daten zwar als Fair Use. Da der Bereich jedoch Neuland sei, ist GitHub an einer Diskussion mit Entwicklerinnen und Entwicklern zu Urheberrechts- und anderen Fragen interessiert, um angemessene Standards für das Trainieren von ML-Modellen zu entwickeln.
Ein Fragenkatalog als Vorlage
Die Free Software Foundation überlässt die konkrete Ausformulierung der Antworten denjenigen, die White Papers zum Thema beisteuern. Sie sollen unter anderem folgende Fragen beantworten:
- Verletzt das Training auf Basis öffentlicher Repositories das Urheberrecht? Ist es Fair Use?
- Wie wahrscheinlich ist es, dass die Ausgabe von Copilot zu einklagbaren Ansprüchen wegen Verstößen gegen GPL-lizenzierte Werke führt?
- Wie können Developer sicherstellen, dass jeglicher Code, zu dem sie ein Copyright halten, gegen Verstöße durch Copilot geschützt ist?
- Verletzt Copilot die AGPL (GNU Affero General Public License), wenn es von AGPL-geschütztem Code lernt?
- Ist das trainierte KI/ML-Modell urheberrechtlich geschützt, und wenn ja: Wer hält das Copyright?
Der Call for White Papers läuft bis zum 23. August, die Beiträge sollen über die E-Mail-Adresse licensing@fsf.org [6] eingereicht werden. Die Abhandlungen sollten maximal 3000 Wörter lang sein und möglichst die Free-Software-Bewegung als Zielpublikum adressieren, aber die Organisation zieht auch Texte in Betracht, die für Juristen geschrieben sind.
Bis zum 20. September will die Free Software Foundation die Einreichungen begutachten und Benachrichtigungen darüber verschicken, ob sie die jeweiligen Abhandlungen für die Veröffentlichung akzeptiert. Weitere Details und der vollständige Fragenkatalog lassen sich dem FSF-Blog entnehmen [7].
- Das Titelthema der aktuellen iX 8/2021 "Besserer Code mit KI" [8] beleuchtet die ML-gestützte Softwareentwicklung unter anderem mit GitHub Copilot: Wie hilft Machine Learning beim Programmieren, wo sind die Grenzen und wo die Risiken?
(rme [9])
URL dieses Artikels:
https://www.heise.de/-6153598
Links in diesem Artikel:
[1] https://www.heise.de/news/Machine-Learning-GitHub-startet-Testfluege-mit-KI-Kopiloten-zum-Programmieren-6123461.html
[2] https://twitter.com/bphogan/status/1411097686854488067
[3] https://twitter.com/eevee/status/1410037309848752128
[4] https://www.heise.de/news/Machine-Learning-GPT-3-erstellt-unter-dem-Kuenstlernamen-DALL-E-Bilder-5005847.html
[5] https://copilot.github.com/
[6] mailto:licensing@fsf.org
[7] https://www.fsf.org/blogs/licensing/fsf-funded-call-for-white-papers-on-philosophical-and-legal-questions-around-copilot
[8] https://www.heise.de/select/ix/2021/8
[9] mailto:rme@ix.de
Copyright © 2021 Heise Medien