Googles Model Card – der Beipackzettel für den AI-Algorithmus

Konkrete Hinweise auf Einschränkungen sollen Fehleinsätze hintanhalten.
(Bild: Daniel AJ Sokolov)
Automatisch erstellte Algorithmen müssen verantwortungsvoll eingesetzt werden. Das beginnt schon bei der Planung. Über den Erfolg kann Offenlegung entscheiden.
Es kommt darauf an, was man daraus macht. Dieser Beton-Werbespruch gilt auch für Algorithmen. Doch woher weiß man, wofür ein Algorithmus gedacht ist und wo seine Grenzen liegen? Genau weiß das niemand. Aber die bekannten Faktoren sollten doch bitte offengelegt werden, meint Google, damit die Algorithmen nicht vergeblich oder gar in schädlicher Weise eingesetzt werden. Der Datenkonzern hat für die Form der Offenlegung auch einen Vorschlag: sogenannte Model Cards.
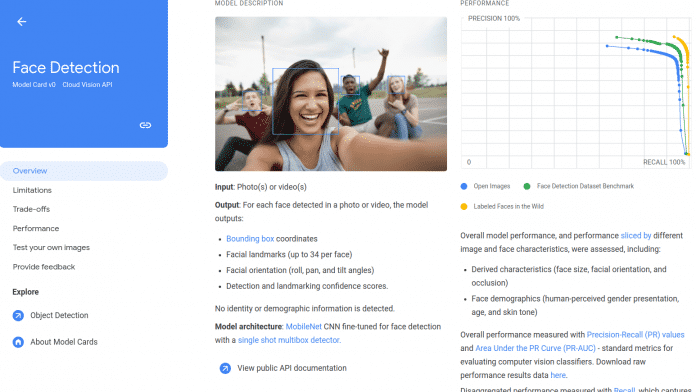
Model Cards für Algorithmen [1] sollen, ähnlich wie Nährwertangaben auf verpackten Lebensmitteln oder Beipackzettel bei Medikamenten, in strukturierter Form Auskunft über Leistungsmerkmale des jeweiligen Algorithmus geben. Eine Model Card für einen Algorithmus, der Hunderassen anhand von Hundefotos erkennen soll, könnte erklären, welche Art von Algorithmus eingesetzt wird, welche Art von Bildern die besten Resultate ermöglicht, und statistische Daten über die Genauigkeit in bestimmten Bildersammlungen machen.
Offenlegung ist aufwändig, aber wertvoll
Wurde beispielsweise ein Algorithmus zur Erkennung von Hautkrankheiten an Bildern isländischer Patienten trainiert, wäre das eine wichtige Information, da der Algorithmus womöglich bei australischen Ureinwohnern eine völlige andere Trefferquote an den Tag legt. Google lädt alle Machine-Learning-Entwickler dazu ein, bei der Definition der Model Cards wie bei der Entwicklung von Werkzeugen zur einfacheren Erstellung der Model Cards mitzuarbeiten. Denn eine Model Card zu befüllen, ist aufwändig.

(Bild: Google/Screenshot)
Das Konzept haben Google-Forscher vor zwei Jahren in einem wissenschaftlichen Aufsatz [2] vorgeschlagen; inzwischen gibt es eine Beta-Version der Model Cards. Der Datenkonzern selbst hat jüngst zwei Beispiele veröffentlicht: Eine Model Card für einen Algorithmus, der in Fotos und Videos Gesichter aufspürt [3], und eine Model Card für einen Algorithmus, der hunderte Objekte erkennen [4] soll.
Googles AI-Prinzipien
Laut Google sind die Model Cards Teil des Strebens nach fairen Algorithmen und deren verantwortungsbewusstem Einsatz. Seit über drei Jahren arbeitet Google an Prinzipien für verantwortungsbewusste Künstliche Intelligenz (KI). Nach aktuellem Stand hat sich Google sieben Prinzipien und vier Verbote verordnet, wie Mitarbeiter am Montag in einer Konferenz mit internationalen Journalisten erzählten.

Googles KI soll sozial nützlich sein, keine unfairen Vorurteile verstärken oder kreieren, von Beginn an auf Sicherheit ausgerichtet und auch überprüft worden sein. Ferner sollen sie Menschen gegenüber Rechenschaft ablegen müssen, von Anfang an auf Datenschutz ausgerichtet sein, hohe wissenschaftliche Standards erfüllen und für Anwendungen zur Verfügung gestellt werden, die diese Prinzipien ebenfalls beachten. Nicht willkommen ist KI-Einsatz, wenn er mehr schadet als nützt, wenn Verletzungen bezweckt werden, wenn er der Überwachung über "international akzeptierte Normen" hinaus dient, oder wenn der Zweck internationales Recht oder Menschenrechte verletzt.
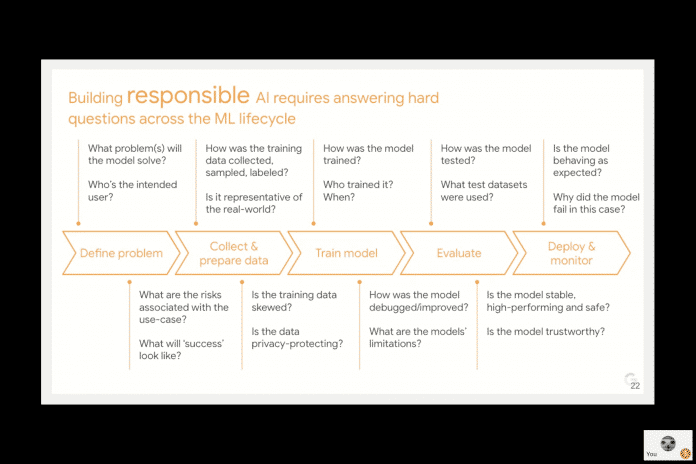
Bevor Google einen Algorithmus freigibt, muss er ein aufwändiges Verfahren durchlaufen. Am Anfang steht die Frage, wer damit welche Probleme lösen soll, am Ende die Frage, ob sich der Algorithmus so verhält, wie erwartet. Dazwischen liegen viele Schritte.
So manches wird eingestampft
Dieser Prozess führt auch dazu, dass manche Ergebnisse des Machine Learning nie oder in anderer Form freigegeben werden, oder auch wieder zurückgezogen werden. So berichtete Tracy Frey, die bei Google für die Produktstrategie der Cloud-KI verantwortlich ist, über einen Algorithmus zur Bestimmung des Geschlechts abgebildeter Personen. Dieses Angebot wurde bewusst eingestellt. "Auf das Geschlecht kann von visuellen Bildern nicht (verlässlich) geschlossen werden", sagte Frey. Weder von Menschen noch von Computern. "Der voraussichtliche Schaden hat die voraussichtlichen Vorteile des Klassifizierungsalgorithmus übertroffen."
Das gilt auch für Sprachausgabe-Software, die Google mit Machine Learning entwickelt hat. Sie wird zwar eingesetzt; allerdings wurde der Plan, sie als Open Source zu veröffentlichen und damit jedermann zugänglich zu machen, aus ethischen Überlegungen fallen gelassen. Warum genau verriet Google nicht. Ein Gesichtserkennungsdienst wurde ebenfalls entwickelt, aber nach einer Menschenrechtsüberprüfung nicht eingeführt. Ganz vergeblich war die Arbeit nicht: Ein auf Prominente beschränkter Gesichtserkennungsdienst hat die Prüfung bestanden, denn diese Antlitze sind sowieso weit und breit bekannt.
(Bild: Google/Screenshot)
Ein Dienst der Alphabet-Firma Jigsaw soll bei Texten, insbesondere Diskussionsbeiträgen in Foren, erkennen, wie toxisch sie sind. Das hilft großen Medienunternehmen bei der Moderation von Leserforen. Hunderte Klassifizierungsalgorithmen sind dabei im Einsatz. Bisweilen arbeiten sie fehlerhaft. So wurde der Satz "Ich bin heterosexuell" als kaum toxisch eingestuft, der Satz "Ich bin schwul" aber als sehr toxisch. "Das ist etwas, was wir nicht sehen wollen", betonte Tulsee Doshi, die bei Google für faires Machine Learning und verantwortungsbewusste KI zuständig ist. Dieser Klassifizierungsalgorithmus musste durch Adversarial Training korrigiert werden.
Global statt regional
Nun sind sowohl ethische Parameter als auch die Bedeutung von Ausdrücken, Bildern und anderen Zeichen stark von der jeweiligen Region und Kultur abhängig, vom Kontext ganz zu schweigen. heise online wollte daher wissen, wie Google seine ethischen Richtlinien und die daran erarbeiteten konkreten Algorithmen regionalisiert.
Gar nicht, wie sich herausstellt: "Es gibt keine ethischen Regeln. Es gib keine Checkliste. Die Realität ist, dass es immer eine einzigartige Kombination von Anwendungsfall, Branche, Trainingsdatensatz, Technik und der Art der konkreten Anwendung ist", sagte Frey, "Unsere KI-Prinzipien sind absichtlich breit gehalten. Das ist unsere gemeinsame Verpflichtung, wie wir KI einsetzen." Die einschlägigen Google-Teams würden sehr wohl daran arbeiten, ihr Verständnis unterschiedlicher Kulturen zu verbessern, "aber das ändert nicht, wofür wir stehen und wie wir unsere Programme bauen."

 [5]
[5](ds [6])
URL dieses Artikels:
https://www.heise.de/-4932939
Links in diesem Artikel:
[1] https://modelcards.withgoogle.com/about
[2] https://arxiv.org/abs/1810.03993
[3] https://modelcards.withgoogle.com/face-detection
[4] https://modelcards.withgoogle.com/object-detection
[5] https://www.heise.de/newsletter/anmeldung.html?id=ki-update&wt_mc=intern.red.ho.ho_nl_ki.ho.markenbanner.markenbanner
[6] mailto:ds@heise.de
Copyright © 2020 Heise Medien