

NorthPole: IBM Research enthüllt ungewöhnlichen KI-Beschleuniger
NorthPole soll KI-Inferenz besonders effizient erledigen, doch einige wichtige Vergleichscharakteristika behält IBM noch für sich.
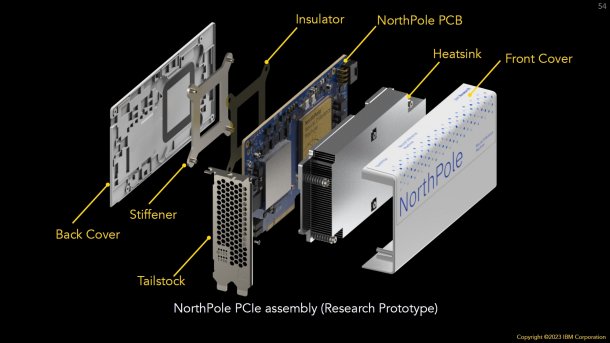
(Bild: IBM)
Auf der Fachkonferenz Hot Chips hat IBMs Forschungsabteilung den KI-Beschleuniger NorthPole vorgestellt, der IBMs bisheriges Vorzeigeprodukt TrueNorth beerbt. Bei seiner Präsentation enthüllte Dharmendra Modha den ungewöhnlichen Ansatz: Viele kleine Kerne werden eng mit lokalem Speicher verknüpft, sodass energieaufwändige Kopieraktionen zu und von den Rechenwerken entfallen. Die zugehörige Software unterstützt eine große Anzahl gängige ML-Modelle und sorgt dafür, dass diese bestmöglich auf die Kerne verteilt werden.

(Bild: IBM)
Das beinhaltet nicht nur die Verteilung der Rechenlast an sich, sondern auch eine Optimierung dahingehend, dass es zu keinerlei bedingten Sprüngen bei der Codeausführung oder zu spekulativer Ausführung kommt, welche ein Nachladen oder Verwerfen von Daten zur Folge hätten – ein Bruch zu dem, wie Turing-Maschinen üblicherweise implementiert sind. Im Gegenzug soll NorthPole um ein Vielfaches effizienter agieren als alle anderen derzeit verfügbaren KI-Beschleuniger.
Videos by heise
Wichtige Charakteristika fehlen noch
Harte Zahlen, die die hervorgehobene Effizienz des gewählten Ansatzes untermauern würden, blieb Modha schuldig: Er nannte in seinem Vortrag weder Ergebnisse von branchenüblichen Benchmarks wie MLperf, noch machte er Angaben zur Leistungsaufnahme. Rückfragen anwesender Pressevertreter blockte er pauschal unter Hinweis auf deren journalistische Tätigkeit ab.
Das Interesse an diesen wichtigen, aber fehlenden Kenngrößen liegt nicht nur in der proklamierten Effizienz an sich: Anders als etwa Nvidias 700-Watt-Chip H100 (Hopper), der bei TSMC im modernen N4-Prozess vom Band läuft, wird das 800 mm² große Die mit 22 Milliarden Transistoren bei IBM selbst mit betagteren 12 Nanometern Strukturbreite gefertigt. Einen feineren Prozess kann IBM wie sein Technologiepartner Global Foundries derzeit nicht bieten.

Die Geheimniskrämerei verwundert auch dahingehend, da die auf Bildern gezeigte Implementierung bereits Rückschlüsse erlaubt, in welchem Leistungsaufnahmefenster sie sich bewegt: Es handelt sich um eine PCIe-Karte mit zusätzlicher 8-poligen Buchse. Über den PCIe-Konnektor kommen bis zu 75 Watt und über den zusätzlichen Anschluss weitere 150 Watt, sodass spezifikationsgemäß potenziell bis zu 225 Watt verheizt werden können. Und es werden sicherlich mehr als 150 Watt sein, denn sonst hätte es eine 6-polige Zusatzbuchse (75 Watt) getan.


Wann und wie NorthPole später einmal zum Einsatz kommen wird, ist unklar. Es liegt freilich die Vermutung nahe, dass IBM den Chip im Rahmen seiner WatsonX-Plattform anbieten wird. (mue)
