

Server-Beschleuniger AMD Instinct MI100: Ohne Radeon, aber mit 11,5 FP64-TFlops
AMDs Beschleunigerkarte Instinct MI100 verzichtet auf Grafikfunktionen und Radeon-Namen, rechnet dafür mit FP32-Genauigkeit aber schneller als Nvidias A100.

AMD Instinct MI100: PCIe-4-Karte mit 11,5 TFlops (FP64)
(Bild: AMD)
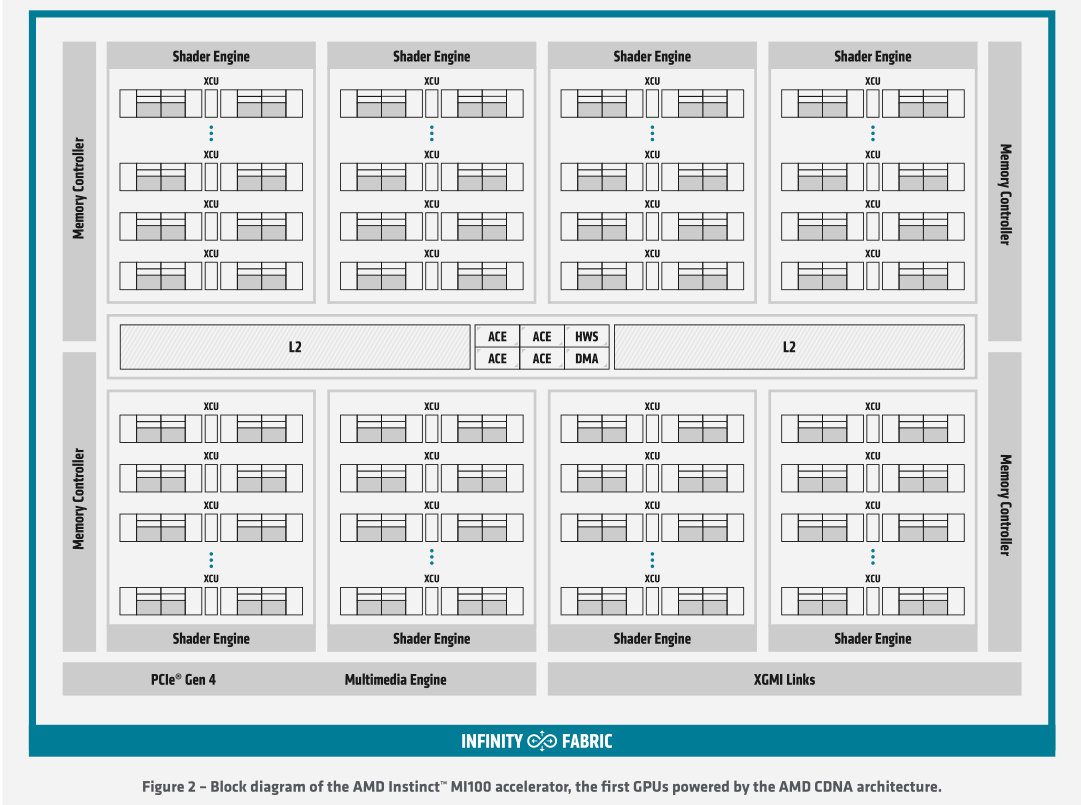
Die AMD Instinct MI100 ist die erste Compute-Beschleunigerkarte mit der neuen CDNA-Architektur und wird in 7-Nanometer-Technik bei TSMC produziert. AMD will mit der PCIe-4.0-Karte und ihren 32 GByte HBM2-Speicher Nvidias A100 Konkurrenz machen und hat dafür nicht nur die aus der GCN-Architektur bekannten Compute Units überarbeitet, sondern auch deutlich mehr davon in den Chip eingebaut. Die Karte soll für Systemintegratoren ab 6400 US-Dollar zu haben sein und unterbietet damit Nvidias A100 PCIe-Version deutlich, die ab 10.700 Euro lieferbar ist.
Videos by heise
Viel Flops, viel Ehr
Bei den technischen Spezifikationen lässt AMD es wieder einmal krachen - wohl auch, um Konkurrent Nvidia mit dem A100-Beschleuniger in einigen Bereichen in die Schranken zu verweisen.
Der CDNA-Chip "Arcturus" hat auf der MI100 120 aktive Compute Units (CUs) und auch wenn AMD auf Nachfrage bestätigte, dass es sich dabei um den Vollausbau handele, legen Aufnahmen des Chips nahe, dass es noch 8 CUs mehr sind. Wir haben zur Klärung noch einmal bei AMD nachgefragt und erwarten derzeit die Antwort.
(Bild: AMD)
Die 120 CUs haben wie bei den eng verwandten Grafikchips mit GCN-Architektur (GraphicsCore Next) jeweils 64 Shader-Rechenkerne, was für den gesamten Chip 7680 ALUs ergibt. Zusammen mit einer maximalen Boost-Taktrate von 1502 MHz errechnet sich daraus ein Durchsatz von 23,07 TFlops bei einfacher Genauigkeit (FP32). Wie es sich für einen HPC-Beschleuniger geziemt, liegt die FP64-Rate bei der Hälfte, also 11,5 TFlops – und damit nicht nur über der 10-TFlops-Marke sondern auch rund 19 Prozent über dem vergleichbaren Wert von Nvidias A100-Beschleuniger im SXM4-Format.

(Bild: AMD)
Gefüttert wird das Rechen-Biest wie schon bei der MI50/MI60 von vier HBM2-Stapeln. Diese fassen jeweils 8 GByte und sind mit 1200 MHz getaktet, was für eine Transferrate von 1,228 TByte/s gut ist. Ein 8 MByte großer Level-2-Cache (6 TByte/s) soll die Speicherzugriffe abfedern. Vom den Registern bis zum HBM2 ist dabei alles per ECC (SECDED) abgesichert.
Neben PCI-Express 4.0 verfügt jede MI100-Karte über drei Infinity-Links à 92 GByte/s - zusammen also 276 GByte/s. Damit sind nun direkt vernetzte Vierergruppen von MI100 möglich, die einen kohärenten Speicherbereich bilden können.


Matrix Core Engines: Ein bisschen Tensor
Die Compute Units der MI100 ähneln denen der Vorgängergeneration Graphics Core Next, sind aber von AMD für den Compute-Einsatz weiter aufgewertet worden. Um auf einen höheren Durchsatz bei Matrix-Matrix-Multiplikationen zu kommen, hat AMD die Schaltungen und Registerports erweitert und nennt das Ergebnis Matrix Core Engine.
AMD hat dabei einen anderen Weg als Nvidia mit ihren Tensor Cores gewählt. Die Core Matrix Engines arbeiten durchweg mit voller FP32-Genauigkeit. Dafür ist ihr maximaler Durchsatz allerdings geringer und sie eignen sich nicht für FP64-Berechnungen. Deshalb lässt sich der Maximaldurchsatz zwischen den beiden Ansätzen nur schwer vergleichen. Wer durchweg auf volle FP32-Genauigkeit angewiesen ist, fährt mit AMD besser, wer auch das alternative TF32 oder geringere Genauigkeiten nutzen kann, dem versprechen die Nvidia-Beschleuniger mehr Leistung.
Beiden Ansätzen gemein ist, dass sie das Format BFloat16 (BF16) unterstützen, welches mit den Wertebereich von FP32 (8-Bit-Exponent) mit der Genauigkeit von FP16 (7-Bit Mantisse, plus 1 Vorzeichen-Bit) kombiniert und sich als de facto Alternative zu vollem FP32 beim KI-Training etabliert hat. AMD gibt im CDNA-Whitepaper für BFloat16 allerdings 10 Bit Mantisse und 5 Bit Exponent an, was eigentlich FP16 entspricht. Update 17.11.2020: AMD hat bestätigt, dass es sich um einen Tippfehler handelt, bFloat16 wird mit 8-Bit-Exponent und 7-Bit-Mantisse unterstützt.
| Instinct MI100 (PCIe) | A100 (SXM) | Tesla V100 | Tesla P100 | |
| Hersteller | AMD | Nvidia | Nvidia | Nvidia |
| GPU | CDNA Arcturus | A100 (Ampere) | GV100 (Volta) | GP100 (Pascal) |
| CUs/SMs | 120 | 108 | 80 | 56 |
| FP32 Cores / SM | 64 | 64 | 64 | 64 |
| FP32 Cores / GPU | 7680 | 6912 | 5120 | 3584 |
| FP64 Cores / SM | 32 | 32 | 32 | 32 |
| FP64 Cores / GPU | 3840 | 3456 | 2560 | 1792 |
|
Matrix Multiply Engines / GPU (Matrix Core Engine / Tensor Cores) |
480 | 432 | 640 | -- |
| GPU Boost Clock | 1502 | k.A. | 1455 MHz | 1480 MHz |
| Peak FP32 / FP64 TFlops | 23,07 / 11,54 | 19,5 / 9,7 | 15 / 7,5 | 10,6 / 5,3 |
| Peak Tensor Core TFlops | -- | 156 (TF32) / 312 (TF32 Structural Sparsity) | 120 (Mixed Precision) | -- |
| Peak Matrix Core Engine TFlops | 46,1 (FP32) | -- | -- | -- |
| Peak FP16 / BF16 TFlops | 184,6 / 92,3 | 312 / 312 (624 / 624 Structural Sparsity) | 125 / 125 | 21,1 / -- |
| Peak INT8 / INT4 TOps | 184,6 / 184,6 | 624 / 1248 (1248 / 2496 Structural Sparsity) | 62 / -- | 21,1 / -- |
| Speicher-Interface | 4096 Bit HBM2 | 5120 Bit HBM2 | 4096 Bit HBM2 | 4096 Bit HBM2 |
| Speichergröße | 32 GByte | 40 GByte | 16 GByte | 16 GByte |
| Speichertransferrate | 1,2 TByte/s | 1,55 TByte/s | 0,9 TByte/s | 0,73 TByte/s |
| TDP | 300 Watt | 400 Watt (SXM) | 300 Watt | 300 Watt |
| Transistoren (Mrd.) | k.A. | 54 Mrd. | 21,1 Mrd. | 15,3 Mrd. |
| GPU Die Size | k.A. | 826 mm² | 815 mm² | 610 mm² |
| Fertigung | 7 nm | 7 nm | 12 nm FFN | 16 nm FinFET+ |

(Bild: AMD)
Ohne Radeon, ohne Displays
Nach Nvidias Tesla- und Quadro-Verzichtet ändert nun auch AMD auf das Branding der Beschleunigerkarten und streicht das Radeon aus der Produktbezeichnung. Die Karte heißt also nur noch AMD Instinct MI100 - wobei die Zahl, anders als bei früheren Instinct-Karten, auch nicht mehr für die FP16-Rechenleistung steht.
Um möglichst viel Rechenleistung im TDP-Rahmen von 300 Watt unterzubringen, hat AMD laut eigenen Angaben beim ersten CDNA-Chip "Arcturus" viele festverdrahtete Funktionen, die für eine Grafikkarte nötig sind, weggelassen. Darunter fallen die Rasterisierungseinheiten, Tesselator-Hardware, spezielle Grafik-Zwischenspeicher, die Blending-Einheiten in den Rasterendstufen und die Display-Engine. Als Grafikkarte lässt sich die MI100 also nicht einsetzen und Crysis läuft auf ihr auch nicht.
Nicht entfernt hat AMD jedoch die Video-Engines, also die spezialisierten De- und Encoder. Grund: Machine Learning wird häufig zur Analyse von Video-Streams oder Bilderkennung eingesetzt.

(Bild: AMD/Supermicro)
(csp)
