Der SuperMUC NG des Leibniz-Rechenzentrums zieht auf Platz 8 in die Top500-Liste ein. Er konnte aber noch nicht mit allen geplanten Prozessoren rechnen.
(Bild: MMM/LRZ)
Lesezeit:
10 Min.
Von
Andreas Stiller
Inhaltsverzeichnis
Die 52. Top500-Liste der weltweit schnellsten Supercomputer birgt einige Überraschungen, vor allem von Seiten der Intel-Konkurrenten ARM beziehungsweise Cavium und von AMD beziehungsweise dessen chinesischem Joint-Venture-Partner THATIC. Der erste Top500-Rechner mit Epyc-Architektur ist nämlich nicht mit Prozessoren von AMD bestückt, sondern wartet mit dem Hygon Dhyana auf.
Weiterlesen nach der Anzeige
Hygon ist Teil des von THATIC, also von Tianjin Haiguang Advanced Technology Investment Corporation und hat die Lizenz zum Epyc-Nachbau. Im Oktober gab der Hersteller Sugon (Dawning) bekannt, dass der dritte Prototyp der chinesischen ExaFlops-Initiative mit eben diesem Epyc-Nachbau installiert ist, der mit den rein chinesischen Lösungen um den Zuschlag zum geplanten Exascale-System konkurrieren soll.
Dass man den ersten ARM-Rechner Astra mit Cavium Thunder X2 (mit 1,5 PFlops auf Platz 203) jetzt begrüßen kann, war hingegen nach den Vorankündigungen von HPE schon vor ein paar Monaten zu erwarten.
Sugon (Dawning) expandiert noch vornehmlich in China. Nun bringt die Firma den ersten Epyc-Prozessor in die Top500-Liste - ein in Lizenz nachgebauter 7501. Hier das wassergekühlte Servermodul i980-G30.
(Bild: Sugon)
Epyc aus China
Die chinesischen Hygon-Dhyana-Prozessoren mit AMD-Epyc-Technik stecken im Advanced Computing System (PreE) genannten Supercomputer von Sugon, zu der die Marke Dawning gehört. Die ordentliche Performance von 4,3 PFlops Linpack-Performance (Platz 38) in der Top500-Liste dürfte allerdings weniger von den lediglich 1024 CPUs (Epyc 7501 mit 32 Kernen) herrühren, als vielmehr von speziellen Beschleunigern namens "Deep Computing Processors", von denen man bislang noch nichts weiter weiß. Vielleicht handelt es sich um eine für HPC optimierte Variante der AI-Chips des chinesischen Startups Cambricon, mit dem Sugon bereits zusammenarbeitet? Cambricon jedenfalls hatte auch die NPU des Smartphone-Prozessors Kirin von Huawei designt. Vermutlich wird man auf der SC18 mehr dazu erfahren.
Die Energieeffizienz des Advanced Computing System (PreE) ist mit 11,4 GFlops/Watt recht gut, reicht fast an einige der Power9/Tesla-V100-Systeme heran. Dabei konnte Top500-Spitzenreiter Summit aber noch einmal zulegen konnte und setzte mit 14,7 GFlops/Watt einen neuen Maßstab für Systeme, die nicht speziell auf Energieeffizienz optimiert wurden (Platz 3). Spitzenreiter ist weiterhin der in Immersions-Tanks arbeitende Shoubu von Pezy Computing mit dem Pezy-SC2-Beschleunigern, der 17,6 GFlops pro Watt erzielt.
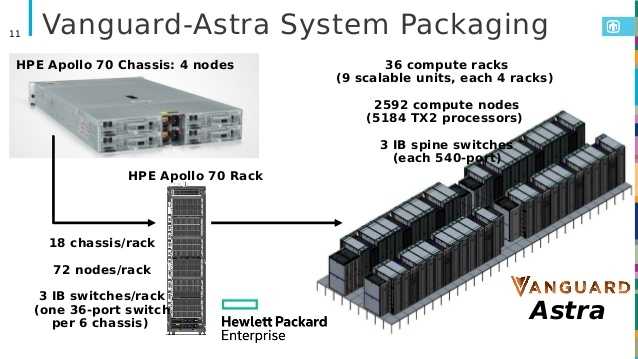
Jetzt wirds ernst: HPE hat den Supercomputer Astra mit Cavium Thunder X2 bei den Sandia National Labs aufgebaut, der erste mit ARM-Architektur in der Top500-Liste.
(Bild: HPE)
ARM-Erstling
Von HPEs Astra an den Sandia National Labs fehlen hingegen jegliche Angaben zur Energieeffizienz. Das System ist mit 5184 Cavium-Thunder-X2-CN99xx-Prozessoren bestückt, ein jeder mit 28 Kernen. Für den Linpack-Benchmark liefen aber nur 4476 Prozessoren mit, die 1,53 PFlops erzielten. Da Sandia den generellen Energiebedarf für das Gesamtsystem mit 1,2 MWatt spezifiziert, lassen sich etwa Effizienzwerte von 1,5 bis 2 GFlops/Watt vermuten.
Weiterlesen nach der Anzeige
Wie Epyc oder Power9 trumpft auch der Thunder X2 mit 8 Speicherkanälen auf. Er sollte dann beim stark von der Speicherperformance abhängigen HPCG-Benchmark punkten können. Mit 66 TFlops ist der Wert für reine CPU-Systeme auch nicht schlecht: so erreicht Astra Platz 38 auf der mit 67 Einträgen gefüllten HPCG-Liste, deren Spitzenposition natürlich ebenfalls der Summit mit 2926 TFlops hält. Von Sugons Epyc-System fehlen indes die Vergleichswerte.
Top 10
In den Top10 der Top500-Liste hat sich im Vergleich zum Juni (51. Top500-Liste) nicht arg viel getan außer leichten Verschiebungen durch Aufrüstung einiger Systeme. Hinter Summit liegt jetzt mit Sierra auch auf Platz zwei ein amerikanisches System mit Power9/Nvidia V100, das mit 94,6 Pflops ganz knapp den schon etwas betagten chinesischen Sunway Taihulight mit 93 PFlops auf Platz 3 verdrängt hat.
Die alte, neue Nummer 1 aus den USA: Summit am Oak Ridge National Laboratory (ORNL) mit IBM POWER9 und Nvidia Tesla V100
(Bild: ORNL)
Schnellster Deutscher
Ein bisschen enttäuschend war aus deutscher Sicht der Einstieg des im September in Betrieb genommenen SuperMUC-NG des Leibniz-Rechenzentrums in die Top500-Liste. Eigentlich waren für seine 311.040 Xeon Xeon-Platinum-8174-Kerne 20,4 Linpack-PFlops projektiert. Die hat er jedoch nicht ganz erzielt, sondern nur 19,5 [–] Lenovo hat es offenbar nicht rechtzeitig geschafft, in der kurzen Zeit alle Knoten zum Fliegen zu bringen, denn 108 Knoten und mithin 5184 Kerne fehlten für den Linpack-Lauf noch.
Das reicht zwar immer noch, um weltweit in die Top 10 als schnellstes deutsches System auf Platz 8 einzumarschieren, nur schaffte er es nicht, Europas Nummer 1 zu werden. Aber selbst mit 20,4 PFlops hätte er dieses Ziel verfehlt, denn das Schweizer Supercomputer-Zentrum CSCS verteidigte die europäische Spitzenposition des Cray-XC50-Rechners Piz Daint, indem es flugs noch einmal 384 weitere Knoten mit Nvidia-Tesla-P100 installiert hat und so auf 21,2 PFlops (Platz 5) kam.
Dafür hat das Leibniz-Rechenzentrum mit dem alten SuperMUC und dem SuperMUC Phase 2 noch zwei weitere Rechner mit jeweils knapp unter 3 PFlops auf Platz 64 und 65 in der Liste. Immerhin läge man also in der Summe vorn. Der alte SuperMUC, der vor sechs Jahren auf Platz 4 in die Liste einstieg, wird allerdings in den nächsten Wochen abgeschaltet und demontiert.
Weitere deutsche HPC-Systeme
Das zweitschnellste System in Deutschland, der von Bull/Atos aufgebaute Juwels am Jülicher SC, wurde inzwischen weiter ausgebaut, aber man verzichtete auf eine erneute Einreichung – schließlich bedeutet ein Linpack-Lauf immer ein paar Wochen Ausfall des Normalbetriebs und wird daher zumeist nur als Stabilitätstest und Burnin für die Systemabnahme vorgenommen. So bleibt Juwels mit seinen 114.480 Xeon-Platinum-Kernen bei 6,2 PFlops, verliert 3 Plätze und liegt nun auf Platz 26.
Neben dem SuperMUC NG zog als weiteres deutsches Neusystem Goethe HLR der Universität Frankfurt mit 959 TFlops (Platz 447, Xeon Gold 6148) in die Liste ein. Das ist jetzt nach dem Mogon II der Universität Mainz (1,97 PFlops, Platz 99) der zweitschnellste Uni-Rechner in Deutschland. Er wurde erst im Januar für 4,5 Millionen Euro ausgeschrieben, wobei, ungewöhnlich für solche Ausschreibungen, der Auftraggeber Racks mit Rücktür-Kühlung und die Stromversorgung in den Racks stellt. Klar, der Rechner soll mit dem effizienten, vom Prof. Volker Lindenstruth entwickelten Kühlkonzept arbeiten. Aber viele arrivierte Hersteller wollen ihre Systeme nicht in fremde Racks mit anderen Kühlsystemen einbauen. Megware aus Chemnitz hingegen ist da flexibel und bekam den Zuschlag.
Chinesische Top500-Dominanz
Dank "unendlich" vieler anonymer Industriesysteme von Lenovo, Inspur, Sugon/Dawning ... konnte China seine Dominanz in der halbjährlich herausgegebenen Top500-Liste bezüglich Stückzahl weiter ausbauen (229, zuvor 206). Die USA haben nur noch 108 (zuvor 124) vor Japan (31/36), Großbritannien (20/22) Frankreich (18/18) und Deutschland (17/21). Dahinter folgt überraschenderweise Irland mit 12 baugleichen Lenovo C1040 – die alle bei anonymen Software-Firmen stehen ...
In Gesamtperformance ausgedrückt bringen Summit und Sierra die USA allerdings deutlich an die Spitze: 532 PFlops gegenüber 440 PFlops, so wie der SuperMUC-NG Deutschland in Europa brillieren lässt mit zusammen 60,5 PFlops vor Frankreich (43,5 PFlops) und Großbritannien (41,7 PFlops).
Über die Hälfte aller Systeme sind inzwischen Industrie- oder Bank-Rechner. Es gibt nur wenige löbliche Ausnahmen etwa bei HPE, IBM, Dell oder Bull, darunter ENI in Italien (der schnellste dieser Gattung auf Platz 15) , EDF in Frankreich (Platz 96) und Curiosity von BASF in Deutschland (Platz 115)
HPE fällt zurück
Bei den Herstellern fällt der langjährige Markführer HPE jetzt sehr weit zurück, hat seinen Marktanteil binnen eines halben Jahres fast halbiert (45, zuvor 79). Die drei Großen kommen jetzt aus China: Lenovo (140/120), Inspur (86/68) und Sugon (57/55) Auch Firma Cray, die mehr auf Großsysteme spezialisiert ist, konnte erstmals HPE überholen (49/56).
Bei den Prozessoren konnten IBM und Nvidia zwei weitere Systeme mit Power9/Tesla V100 platzieren (Lassen auf Platz 10 mit 15,4 PFlops und Ansel auf Platz 246 mit 1,7 PFlops, beide am Lawrence Livermore National Laboratory/LLNL). Ansonsten dominiert weiter Intel total. Inzwischen sind rund ein Viertel aller Systeme mit Intel Skylake bestückt (Xeon-SP). Anders als noch vor einem halben Jahr gibt es jedoch kein einziges Neusystem mit dem abgekündigten Xeon Phi mehr.
Die Speicherperformance eines damit bestückten Zweisockelsystems soll beim Stream-Triad gegenüber einem System mit zwei mit je 28 Kernen ausgestattetem Platinum 8180 bei Faktor 1,83 liegen, also bei etwa 370 GFlops. Die Performance-Steigerung beim Linpack auf etwa 4 TFlops hält sich demgegenüber mit 21 Prozent in Grenzen.
Nvidia Tesla allerorten
Was Intel bei den CPUs ist Nvidia bei den Beschleunigern: 127 der 137 beschleunigten Systeme nutzen Nvidia-GPUs, 46 davon bereits Nvidia Volta alias Tesla V100.
Die Gesamtperformance aller Systeme stieg diesmal nur wenig um 16 Prozent auf 1,41 Exaflops. Insgesamt 428 (zuvor 272) Systeme schaffen inzwischen mehr als ein Petaflops. Um überhaupt noch auf die Liste zu kommen, stieg die Einstiegsperformance um 22 Prozent auf 874,1 TFlops. Man kann also davon ausgehen, dass in der nächsten Top500-Liste im Juni 2019 nur noch Petaflops-Rechner verzeichnet sind.