

Das Monitoring lernt selbst: KI in Überwachungsszenarien
Künstliche Intelligenz ist eines der großen Themen der digitalen Transformation. Auch im IT-Systemmanagement werden angesichts steigender Komplexität hohe Erwartungen an selbstlernende Systeme gestellt. Bei der frühzeitigen Prognose von Störungen kann KI bereits heute einiges leisten.

- Susanne Greiner
2017 schlug das alte Brettspiel Go in der IT-Welt große Wellen. Denn bislang galt: Nur Menschen können meisterlich das vor allem in Japan und Korea populäre igo spielen. Nicht mal sehr gute Amateure waren bislang von einem Algorithmus zu schlagen, von Profis ganz zu schweigen. Doch im vergangenen Jahr geschah das Unglaubliche. AlphaGo von DeepMind siegte nicht nur in 60 Online-Partien gegen Profis, sondern schlug auch die Nummer eins der Weltrangliste Ke Jie.
Die Basis von AlphaGo sind neuronale Netze. Und der Nachfolger AlphaGo Zero ist noch stärker, diese Version brachte sich das Spiel ohne externen Input bei. Das alles wäre bestenfalls eine Randnotiz in der Fachpresse, wenn nicht Künstliche Intelligenz (KI) eines der zentralen Themen der digitalen Transformation darstellen würde.
Die maschinelle, selbstständige Auswertung der allerorts erzeugten Datenmassen gewinnt an Bedeutung. Das IT-Systemmanagement bildet da keine Ausnahme. Denn nicht zuletzt mit dem Internet of Things (IoT) wächst das zu analysierende Datenvolumen auch im Monitoring massiv an. Zudem steigt der Business-Impact der IT; digitale Geschäftsmodelle und Unternehmensabläufe erlauben keine ungeplanten Downtimes.
Hier stoßen die herkömmlichen Monitoring-Ansätze auf Basis von Mittel- und Schwellenwerten rasch an ihre Grenzen. Denn eine Störung in der IT darf heute nicht zum Problem auswachsen, sie muss bereits vorher erkannt und beseitigt werden. Ein Alarm, der erst dann eintrifft, wenn die Endanwender bereits den Help Desk belagern, ist nichts wert.
Es geht darum, sich anbahnende Störungen möglichst frühzeitig zu bemerken, bevor sich das Netzwerk oder eine kritische Anwendung in die falsche Richtung bewegt. KI kann dazu im Monitoring neue Einblicke und Möglichkeiten bieten, die analog zur Wartung industrieller Anlagen unter dem Begriff "Predictive Maintenance" zusammengefasst werden.
Bessere Trainingsdaten
Auch wenn es grundsätzlich schwierig ist, natürliche und künstliche Intelligenz zu definieren, kann als Minimalkonsens gelten: KI-Systeme sind „quasi-intelligent“ und in der Lage, auf neue Situationen sinnvoll zu reagieren. Damit adressieren KI-Systeme prinzipiell zwei grundsätzliche Probleme im IT-Systemmanagement: Zum einen ist in einem idealen IT-Management jedes Problem neu. Denn im Idealfall wird bei einem auftretenden Problem der eigentliche Grund – der sogenannte Rootcause – erkannt und beseitigt.
Das Problem kann also theoretisch nicht nochmal in genau der bekannten Konstellation auftreten. Zum anderen kann die KI extrem schnell reagieren, wenn bestimmte antrainierte Muster auftreten. Wobei hier der Vollständigkeit halber auf das Problem des Klugen Hans (siehe Kasten) hingewiesen werden sollte.
Wie gut die KI bestimmte Muster innerhalb der im Monitoring erhobenen Daten erkennen kann, hängt zunächst einmal von der Qualität dieses Inputs ab. Die mit den heute üblichen Mittelwertmessungen erhobene Datenqualität reicht für das KI-basierende IT-Management jedoch nicht.
Diese Sicht auf die IT ist nicht exakt genug: Geht man im Monitoring von einem Mittelwert aus, der als normal angenommen wird, kommt es durch die gesetzten Zeitintervalle bei der Messung zu Informationsverlusten. Peaks können untergehen und damit Probleme unerkannt bleiben. Man erhält eine eindimensionale Abbildung eines einzelnen Messwerts, der mit einem mehr oder minder willkürlichen Schwellwert verglichen wird.
Ein Beispiel aus der Praxis macht das Problem deutlich. Die Aufgabe war, eine Umstellung an einem SAP-System in einem großen Unternehmen zu begleiten und die sogenannte Real User Experience (RUE) zu ermitteln – also die wahrgenommene Performance aus Anwendersicht. Dazu sollten vor, während und nach der Umstellung Daten erhoben werden. Das klassische Monitoring liefert Daten wie in der folgenden Tabelle dargestellt:

(Bild: Würth Phoenix)
Es ist nicht möglich, aus dieser Tabelle abzuleiten, ob sich die IT aus Sicht der Anwender verbessert hat oder nicht. Die Server-Latenz liegt durchgängig in einem schmalen, homogenen Bereich, die Client-Latenz hat sich signifikant verändert. Der Trend scheint offensichtlich, aber der Blick auf das große Ganze ist so nicht möglich. Augenfällig wird dies, wenn die Messung verfeinert und grafisch aufbereitet wird:

(Bild: Würth Phoenix)
Dichte statt Mittelwert
Um eine KI mit besserem Input zu versorgen, ist also eine andere, genauere Betrachtungsweise notwendig. Ein in der Praxis erfolgreich erprobter Ansatz ist die statistische Methode der Wahrscheinlichkeitsdichte, ein Verfahren zur Beschreibung einer Wahrscheinlichkeitsverteilung innerhalb eines gegebenen Intervalls. Anstatt den Standard-Traffic als "Datenverkehr innerhalb eines bestimmten Durchschnittsbereichs" zu definieren, wird versucht, die als normal anzusehende Datenverteilung durch eine Funktion der Wahrscheinlichkeitsdichte abzuschätzen. Die daraus resultierende Definition des Standard-Datenverkehrs ist damit "Datenverkehr innerhalb einer bestimmten Bandbreite eines der deutlichsten Maximalwerte der Wahrscheinlichkeitsdichtefunktion".
Damit erhält man statt des Mittelwerts eine Dichte, die anzeigt, wie sich der Datenverkehr und die Datenmenge verteilen. Client-Latenz und Datendurchsatz können somit in einen Zusammenhang gebracht werden. Man erhält eine informationsreichere Abbildung der Daten, die man zu Clustern zusammenfassen kann. Sinnvoll ist hier, die Cluster anhand der Dichte des Traffic im Netz zu bilden. Dabei geht man davon aus, dass dichter Traffic dem normalen Betrieb entspricht. Bereiche mit wenig Traffic – man spricht hier von Sparse Traffic – sind dagegen ein Hinweis auf Probleme.

(Bild: Würth Phoenix)
Die dichtebasierende Überwachung zeigt ihre Vorteile vor allem dann, wenn eine oder mehrere der Performance-Metriken unterschiedliche Zustände einnehmen können, die zudem zeitgleich existieren. Das kommt zum Beispiel vor, wenn Veränderungen an Anwendungen über das gesamte Netzwerk hinweg betrachtet werden: Betriebssysteme und Geräteklassen haben meist spezifische Maxima, um die herum sich die Performance-Metriken gruppieren. Beim herkömmlichen Monitoring wird alles in einen Topf geworfen, die Informationen sagen nichts über das Verhalten der Untergruppen aus.
Die Frage nach den relevanten Merkmalen
Mit der Datenqualität, die sich durch komplexere statistische Ansätze wie Wahrscheinlichkeitsdichte erzielen lässt, verfügt man über eine gute Ausgangsbasis für den Einsatz von KI-Systemen. Denn beim maschinellen Lernen kommt es darauf an, ein mathematisches Modell mit Beispielen zu füttern, deren Output – auch Label genannt – bekannt ist. Hier wird das Verhältnis von Statistik und maschinellem Lernen deutlich: Der statistische Ansatz ist darauf ausgerichtet, mittels Interferenzen den Prozess zu identifizieren, der die Daten erzeugt hat. Das maschinelle Lernen hingegen soll Prognosen abgeben, wann bestimmte Daten mit einer hohen Wahrscheinlichkeit auftreten werden. Dabei stößt man unweigerlich auf ein sehr grundsätzliches Problem des maschinellen Lernens: Welches sind die relevanten Merkmale und wie können diese hinreichend exakt beschrieben werden?
Die Herausforderung ist, dem Algorithmus die richtigen Features als Input bereitzustellen – nicht zuletzt, um auch nach der initialen Trainingsphase eine fortlaufende Optimierung des Systems zu ermöglichen. Diese Optimierung ist besonders im IT-Monitoring extrem wichtig. Denn IT-Infrastrukturen sind sehr heterogen. Jede Geräteart, jedes Betriebssystem hat bestimmte Eigenarten, welche sich in den Monitoring-Daten widerspiegeln und die bei der Auswertung berücksichtigt werden müssen. Zudem ändern sich Infrastrukturen immer schneller, die KI muss adaptiv darauf reagieren können.
Die Frage nach den relevanten Merkmalen einer "gesunden" IT-Infrastruktur kann durch das sogenannte Deep Learning entschärft werden. Dieser Ansatz, der auch bei AlphaGo zum Einsatz kam, basiert auf einer fortlaufenden Optimierung der KI, die die relevanten Merkmale selbst spezifiziert. Dabei werden neuronale Netze gebildet, die einen ähnlichen Aufbau haben wie das menschliche Gehirn und in mehreren Schichten angeordnet sind. Selbstverständlich geht das nicht von allein, auch dieses System erfordert Training mittels Labels.
Ein anderer, in der Monitoring-Praxis erprobter Ansatz ist das unüberwachte Lernen. Dieses kommt in einigen Marktangeboten wie NetEye von Würth Phoenix zum Einsatz. Hierbei versucht der Algorithmus, in dem ansonsten strukturlosen Datenrauschen des Monitorings Muster zu erkennen. Dazu müssen die Daten anhand ähnlicher Merkmale kategorisiert, also zu Clustern zusammengefasst werden. Die Klassifikatoren erstellt das System selbstständig, Parameter und Kategorien justiert der Algorithmus fortlaufend nach. Bei Bedarf lassen sich neue Kategorien hinzufügen. Alternativ zur Kategorisierung gibt es zudem Verfahren, die die Daten in einfachere Darstellungen übertragen und dabei einen gewissen Informationsverlust in Kauf nehmen. Grundsätzlich sind selbstlernende Systeme sehr adaptiv und können schnell neue Situationen erfassen.
Clustering der Performance-Daten
Da der Ansatz der Wahrscheinlichkeitsdichte bereits Daten zu Clustern gruppiert, bietet sich das unbeaufsichtigte Lernen im Monitoring an. Der Datenverkehr wird vom Algorithmus in Sparse und Dense Traffic aufgeteilt. In der Praxis ergeben sich daraus interessante Einblicke, etwa im Fall des oben erwähnten SAP-Projekts. In einem 2D-Plot der Daten zeigen sich deutliche Unterschiede zwischen Dense und Sparse Traffic. So hat der reguläre Dense Traffic (im Bild grün dargestellt) deutlich schärfere Grenzen, während der Sparse Traffic (rot) eine wesentlich breitere Streuung zeigt.

(Bild: Würth Phoenix)
Der Einsatz des maschinellen Lernens und komplexerer statistischer Ansätze bringt im Monitoring einige Vorteile. Besonders augenfällig: Zeichnen sich Störungen ab, äußern diese sich im Sparse Traffic. Bei der Suche nach dem Roocause können sich die Administratoren auf diesen Bereich konzentrieren. Das erspart viel Zeit und erlaubt es, die Fehlerquelle genauer aufzuspüren. Das Konzept dahinter ist einfach: Der Dense Traffic, der das Gros des Datenverkehrs ausmacht, kann dazu genutzt werden, Baselines oder multidimensionale Base Areas feiner zu justieren. Der Sparse Traffic enthält die Informationen zu möglichen Störungen und sollte deswegen genau bis auf Query-Ebene unter die Lupe genommen werden. Hier zeigen sich potenzielle Probleme zudem lang bevor sie zu Störungen werden.
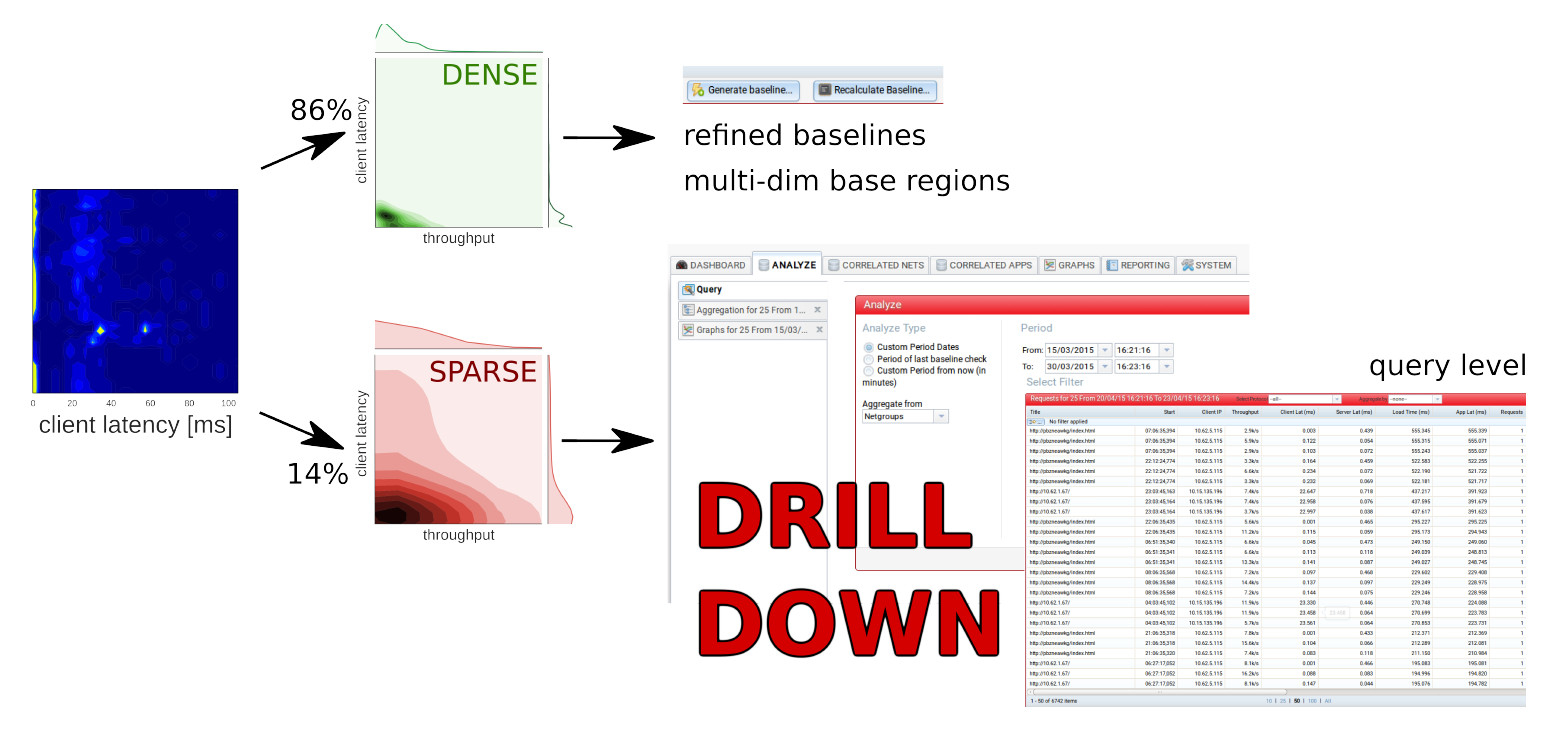
(Bild: Würth Phoenix)
User Experience als Metrik
Grundsätzlich gilt im Monitoring wie auch in allen anderen Einsatzbereichen von KI: Entscheidend für den Erfolg ist die Datenqualität. Neben den klassischen Performance-Daten wie CPU-Last, Netzwerklatenz oder I/O-Auslastung hat sich in der Praxis gezeigt, dass auch die Sicht der Anwender einen wertvollen Beitrag leistet, um Unregelmäßigkeiten in der IT schnell zu erkennen. Die User Experience weicht oft von den im Rechenzentrum erfassten Metriken ab. Um auch diesen Ausschnitt des großen Gesamtbildes in das IT-Servicemanagement einfließen zu lassen, gibt es heute einige Tools. Im Bereich der Open-Source-Software ist hier zum Beispiel das Projekt Alyvix zu nennen.
Diese Tools simulieren typische Anwenderaktionen am Client wie etwa eine Buchung in SAP und geben so einen guten Eindruck, wie es um die IT-Performance am anderen Ende der Service-Kette steht. Ein weiterer Vorteil der Anwendersicht ist, dass darüber auch die Performance von Diensten erfasst werden kann, die nicht "on premise" erbracht werden. Mit der zunehmenden Cloud-Nutzung auch in unternehmenskritischen Bereichen ist es unvermeidlich, im Monitoring auch diese Services zu überwachen und in die Gesamtbeurteilung aufzunehmen.
Künstliche Intelligenz steckt im Monitoring noch in den Kinderschuhen. Die ersten Schritte sind gemacht, die ersten Systeme mit maschinellem Lernen und erweiterter Statistik sind bei innovationsfreudigen Kunden implementiert. Dabei zeigt sich, dass der Ansatz funktioniert und die gewünschten Ergebnisse liefert. Aber bis zur vollautomatischen und selbstheilenden IT-Systemmanagement-Anwendung ist es noch ein weiter Weg. Wobei die Forschung im Bereich des maschinellen Lernens rasante Fortschritte macht. Zudem ist der Bedarf in den Unternehmen da.
Es steht also zu erwarten, dass in den kommenden Monaten und Jahren zahlreiche neue Anwendungen und KI-Ansätze auf den Markt kommen werden. AlphaGo hat gezeigt, zu welchen Leistungen KI-Systeme heute fähig sind. Bis sie einen gut ausgebildeten, erfahrenen Administrator ersetzen können, wird noch viel Zeit vergehen – wenn dieses überhaupt eintritt. Stand heute erweitern sie jedoch die Werkzeugkiste der Administratoren um die Möglichkeit, in immer größeren, komplexen und verteilten IT-Umgebungen Probleme schnell zu beseitigen. Es bleibt also spannend.
Dr. Susanne Greiner
studierte Experimentalphysik an der Universität Erlangen. Um insbesondere die Aspekte des maschinellen Lernens zu vertiefen, promovierte Greiner nach dem Master-Abschluss an der Universität Trient im Bereich "Machine Learning for Neuroscience". Sie arbeitet seit 2015 als Data Scientist beim Software-Dienstleister Würth Phoenix im Bereich Performance Monitoring und User Experience.
(map)
