Data Science: Warenkorbanalyse in 30 Minuten

Einkaufsmuster von Waren zu analysieren und daraus Vorhersagen abzuleiten, ist kein Privileg großer Unternehmen. Mit einfachen Modellierungstechniken zur Warenkorbanalyse können auch Mittelständler wertvolle Erkenntnisse gewinnen, wie diese Einführung in Data Science am Beispiel einer Bäckerei zeigt.
Den Schlagworten Künstliche Intelligenz und Data Science begegnet man in allen Ecken der IT-Branche. Dabei reden viele über Big Data im Großunternehmen und lassen die kleineren Unternehmen außer Acht. Die rasche Weiterentwicklung bei Hardware und Software hat allerdings dafür gesorgt, dass auch kleinere Unternehmen in der Lage sind, sich mit (Massendaten-)Analyse zu beschäftigen und mithilfe der Mathematik und Statistik wertvolle Erkenntnisse aus ihren Daten zu ziehen.
In den meisten Fällen reicht ein leistungsfähiger PC oder ein Notebook aus, damit sogar Kleinstunternehmen wie eine Bäckerei durch Data Science aus ihren Daten wichtige Entscheidungen ableiten können. Einen möglichen Ansatz für die Warenkorbanalyse zeigt der Autor im Folgenden auf.
Einführung in Data Science
Nahezu jedes Unternehmen, das Waren verkauft, verfügt automatisch über die für eine Warenkorbanalyse erforderlichen Daten – egal ob im elektronischen Format oder auf Papier. Da machen auch Bäckereien keine Ausnahme. Für die nachfolgende Einführung kommt der Beispieldatensatz einer Bäckerei aus Edinburgh (Transactions from a bakery) zum Einsatz, der auf dem Kaggle-Portal frei zur Verfügung steht [1].
Die Idee der Warenkorbanalyse-Modellierungstechnik (engl. Market Basket Analysis) ist es, ein übergreifendes Einkaufsmuster aller angebotenen Artikel zu ermitteln, aus dem sich ableiten lässt, wie gefragt die einzelnen Waren bei den Kunden sind. Dabei geht es auch darum, etwaige Verbindung zwischen gekauften Artikeln zu finden. Wenn beispielsweise ein Kunde Produkt_1 kauft, wie wahrscheinlich ist dann, dass er auch Produkt_2 kauft?
Um solche Zusammenhänge zu ermitteln, soll ein Data-Mining-Verfahren [2] auf Basis des Apriori-Algorithmus zur Analyse der Einkaufsprozesses zum Einsatz kommen. Der Einkaufprozess besteht aus Transaktionen. Jede Transaktion entspricht einem Warenkorb mit den gekauften Produkten (Items). Jeder Warenkorb lässt sich eindeutig anhand des Kassenbons mit Belegnummer beschreiben (siehe Abb. 1).


Theoretische Grundlagen
Die zentralen Kennzahlen für den Apriori-Algorithmus sind: Support, Konfidenz und Lift. Der Support liefert den Wert für den prozentualen Anteil eines Produkts am Verkauf sämtlicher Waren des Unternehmens. Damit spiegelt er die Wahrscheinlichkeit wider, mit der ein Produkt gekauft wird beziehungsweise wie oft ein Item in der Summe aller Transaktionen vorkommt:
Support(Produkt_1) = (Anzahl Transakt. mit dem Produkt_1) / (Gesamte Anzahl der Transakt.)
Support(Produkt_1 und Produkt_2) = (Anzahl Transakt. mit Produkt_1 und Produkt_2) / (Gesamte Anzahl der Transakt)
oder
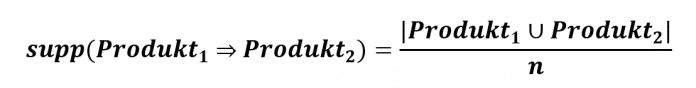
Die Konfidenz (Produkt_1 -> Produkt_2) beziffert die Wahrscheinlichkeit, mit der ein Kunde zusätzlich Produkt_2 kauft, wenn er bereits Produkt_1 gekauft hat:
Konfidenz(Produkt_1 -> Produkt_2) = Support(Produkt_1 und Produkt_2) / Support(Produkt_1)
oder
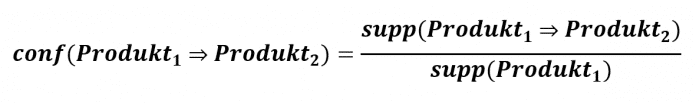
Lift, die dritte wichtige Kennzahl des Apriori-Algorithmus, liefert eine Antwort auf die Frage, um wie viel wahrscheinlicher das Produkt_1 den Kauf des Produkts_2 macht:
Lift(Produkt_1 -> Produkt_2) = Support(Produkt_1 und Produkt_2) / (Support(Produkt_1) * Support(Produkt_2))
oder
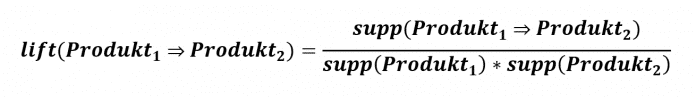
Ein Lift von 1 beziehungsweise 100 Prozent bedeutet, dass keine erkennbare Verbindung zwischen Produkt_1 und Produkt_2 besteht. Ein Lift größer 1 (über 100 Prozent) bedeutet, dass Kunden Produkt_1 und Produkt_2 häufiger zusammen kaufen. Ein Lift kleiner 1 (weniger als 100 Prozent) zeigt, dass es unwahrscheinlich ist, dass Kunden die beiden Produkte zusammen kaufen.
Untersuchen der Daten
Der Beispieldatensatz aus dem Kaggle-Portal beschreibt die Transaktionen der Edinburgher Bäckerei "The Bread Basket".
Die über 20.000 Datensätze decken mehr als 9000 eindeutige Transaktionen mit den folgenden Feldern ab:
- Date: Die Variable beschreibt das Datum der Transaktionen im Format JJJJ-MM-TT. Die Spalte enthält Daten vom 30.10.2016 bis zum 09.04.2017.
- Time: Die Variable beschreibt die Zeit der Transaktionen im Format HH:MM:SS.
- Transaction: Variable, mit der sich die Transaktionen unterscheiden lassen. Zeilen, die in diesem Feld den gleichen Wert haben, gehören zu derselben Transaktion.
- Item: Variable mit den während einer Transaktion gekauften Produkten.
Da in kleineren Unternehmen wie Bäckereien typischerweise die Produktpalette überschaubar und die Anzahl der Transaktionen begrenzt ist, lässt sich die Analyse prinzipiell auch einfach in einer Tabellenkalkulation (Excel) umsetzen. Das ist in der Regel mit hohem manuellen Aufwand verbunden und daher fehleranfällig. Deswegen greift der Autor zur Programmiersprache Python, die sich für die Analyse des vorliegenden Datensatzes wahlweise in den Distributionen Canopy [3] oder Anaconda [4] anbietet. Beide Varianten lassen sich leicht installieren und verfügen über die Developer-Umgebungen Spider beziehungsweise Jupyter Notebook.
Im ersten Schritt gilt es, die für die Analyse der Daten benötigten Python-Bibliotheken zu importieren und anschließend den Datensatz in das Pandas-DataFrame-Objekt einzulesen:
# Import der Data Science Pakete (pandas etc.)
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
import os
%matplotlib inline
# Warnings ignorieren
import warnings
warnings.filterwarnings('ignore')
# Style festlegen
sns.set(style='darkgrid')
plt.rcParams["patch.force_edgecolor"] = True
# Verzeichnis auflisten das Daten-Set 'BreadBasket_DMS.csv' sollte im Verzeicnis liegen
print(os.listdir("./"))
Darauf folgen die Auflistung und Analyse des Datenbestandes im Pandas-DataFrame-Objekt:
# Lesen der 'BreadBasket_DMS.csv'-Datei ins pandas's DataFrame-Objekt
df = pd.read_csv('./BreadBasket_DMS.csv')
print('Data-Set Information: \n')
print(df.info())
Data-Set Information:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 21293 entries, 0 to 21292
Data columns (total 4 columns):
Date 21293 non-null object
Time 21293 non-null object
Transaction 21293 non-null int64
Item 21293 non-null object
dtypes: int64(1), object(3)
memory usage: 665.5+ KB
None
print('Die ersten zehn Zeilen aus dem Datenbestand: \n')
print(df.head(10))
Die ersten zehn Zeilen aus dem Datenbestand:
Date Time Transaction Item
0 2016-10-30 09:58:11 1 Bread
1 2016-10-30 10:05:34 2 Scandinavian
2 2016-10-30 10:05:34 2 Scandinavian
3 2016-10-30 10:07:57 3 Hot chocolate
4 2016-10-30 10:07:57 3 Jam
5 2016-10-30 10:07:57 3 Cookies
6 2016-10-30 10:08:41 4 Muffin
7 2016-10-30 10:13:03 5 Coffee
8 2016-10-30 10:13:03 5 Pastry
9 2016-10-30 10:13:03 5 Bread
Wie bereits erwähnt, enthält der Datensatz vier Variablen: Date, Time, Transaction und Item. Da die schottische Bäckerei auch zahlreiche argentinische und spanische Produkte in ihrem Angebot führt, lässt sich die Benennung der Produkte nur mühsam auf eine "durchschnittliche" deutsche Bäckerei übertragen. Daher behalten die insgesamt 95 eindeutig verkauften Produkte im weiteren Verlauf ihren ursprünglichen Namen:
print('Eindeutige verkaufte Produkte: ', df['Item'].nunique())
print( '\n', df['Item'].unique())
Eindeutige verkaufte Produkte: 95
['Bread' 'Scandinavian' 'Hot chocolate' 'Jam' 'Cookies' 'Muffin' 'Coffee'
'Pastry' 'Medialuna' 'Tea' 'NONE' 'Tartine' 'Basket' 'Mineral water'
'Farm House' 'Fudge' 'Juice' "Ella's Kitchen Pouches" 'Victorian Sponge'
'Frittata' 'Hearty & Seasonal' 'Soup' 'Pick and Mix Bowls' 'Smoothies'
'Cake' 'Mighty Protein' 'Chicken sand' 'Coke' 'My-5 Fruit Shoot'
'Focaccia' 'Sandwich' 'Alfajores' 'Eggs' 'Brownie' 'Dulce de Leche'
'Honey' 'The BART' 'Granola' 'Fairy Doors' 'Empanadas' 'Keeping It Local'
'Art Tray' 'Bowl Nic Pitt' 'Bread Pudding' 'Adjustment' 'Truffles'
'Chimichurri Oil' 'Bacon' 'Spread' 'Kids biscuit' 'Siblings'
'Caramel bites' 'Jammie Dodgers' 'Tiffin' 'Olum & polenta' 'Polenta'
'The Nomad' 'Hack the stack' 'Bakewell' 'Lemon and coconut' 'Toast'
'Scone' 'Crepes' 'Vegan mincepie' 'Bare Popcorn' 'Muesli' 'Crisps'
'Pintxos' 'Gingerbread syrup' 'Panatone' 'Brioche and salami'
'Afternoon with the baker' 'Salad' 'Chicken Stew' 'Spanish Brunch'
'Raspberry shortbread sandwich' 'Extra Salami or Feta' 'Duck egg'
'Baguette' "Valentine's card" 'Tshirt' 'Vegan Feast' 'Postcard'
'Nomad bag' 'Chocolates' 'Coffee granules ' 'Drinking chocolate spoons '
'Christmas common' 'Argentina Night' 'Half slice Monster ' 'Gift voucher'
'Cherry me Dried fruit' 'Mortimer' 'Raw bars' 'Tacos/Fajita']
Vorbereiten der Daten
Ein wichtiger Schritt bei der Vorbereitung der Daten ist die Suche nach fehlenden Werten, also Einträgen mit den Werten "NULL" beziehungsweise "NONE" (undefinierte Daten). Im vorliegenden Datensatz sind über 700 Zeilen mit "NONE" markiert, das entspricht circa 3 Prozent des Gesamtbestands. Um das Ergebnis der Analyse dadurch nicht zu verfälschen, müssen die fehlenden Werte entweder befüllt oder gelöscht werden. Der Einfachheit halber löscht der Autor die betreffenden Zeilen im Datensatz:
df.drop(df[df['Item']=='NONE'].index, inplace=True)
print(df.info())
<class 'pandas.core.frame.DataFrame'>
Int64Index: 20507 entries, 0 to 21292
Data columns (total 7 columns):
Date 20507 non-null object
Time 20507 non-null object
Transaction 20507 non-null int64
Item 20507 non-null object
Jahr 20507 non-null object
Monat 20507 non-null object
Tag 20507 non-null object
dtypes: int64(1), object(6)
memory usage: 1.3+ MB
None
Im nächsten Schritt sollten Datums- und Zeitangaben in numerische Werte umgewandelt werden, um sowohl die Analyse als auch die Visualisierung der Daten zu erleichtern:
# Year
df['Jahr'] = df['Date'].apply(lambda x: x.split("-")[0])
# Month
df['Monat'] = df['Date'].apply(lambda x: x.split("-")[1])
# Day
df['Tag'] = df['Date'].apply(lambda x: x.split("-")[2])
print(df.info())
print(df.head())
<class 'pandas.core.frame.DataFrame'>
Int64Index: 20507 entries, 0 to 21292
Data columns (total 7 columns):
Date 20507 non-null object
Time 20507 non-null object
Transaction 20507 non-null int64
Item 20507 non-null object
Jahr 20507 non-null object
Monat 20507 non-null object
Tag 20507 non-null object
dtypes: int64(1), object(6)
memory usage: 1.3+ MB
None
Date Time Transaction Item Jahr Monat Tag
0 2016-10-30 09:58:11 1 Bread 2016 10 30
1 2016-10-30 10:05:34 2 Scandinavian 2016 10 30
2 2016-10-30 10:05:34 2 Scandinavian 2016 10 30
3 2016-10-30 10:07:57 3 Hot chocolate 2016 10 30
4 2016-10-30 10:07:57 3 Jam 2016 10 30
Visualisierung der Daten
Damit ist die Vorbereitung der Daten abgeschlossen. Der Datenbestand enthält nun aufbereitete Transaktionen für den Zeitraum vom 30. Oktober 2016 bis zum 9. April 2017. Von besonderem Interesse für die Analyse ist die Frage, welche Artikel Kunden am meisten kaufen:
# Die ersten 15 meistverkauften Produkte
most_sold = df['Item'].value_counts().head(15)
# print('Meistverkaufte Produkte: \n')
# print(most_sold)
plt.figure(figsize=(15,5))
# Meistverkaufte Produkte als Linie
plt.subplot(1,3,1)
most_sold.plot(kind='line')
plt.title('Meistverkaufte Produkte')
# Meistverkaufte Produkte als Balkendiagramm
plt.subplot(1,3,2)
most_sold.plot(kind='bar')
plt.title('Meistverkaufte Produkte')
# Meistverkaufte Produkte als Kreisdiagramm
plt.subplot(1,3,3)
most_sold.plot(kind='pie')
plt.title('Meistverkaufte Produkte')
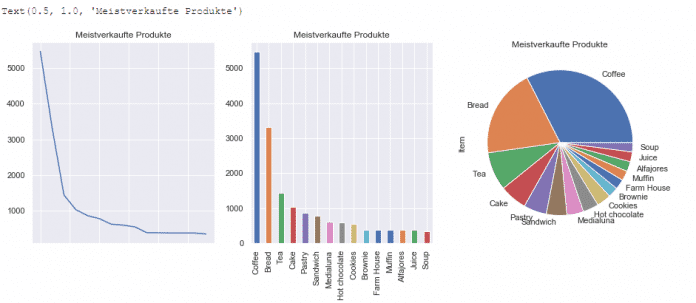
Kaffee ist überraschenderweise das meistverkaufte Produkt – erst danach folgt Brot. Auf den weiteren Plätzen finden sich Tee, Kuchen und Gebäck – wie man es für eine typische Bäckerei erwarten sollte.
Wie sich die Verkäufe der einzelnen Produkte im zeitlichen Verlauf darstellen, lässt sich am besten durch die visuelle Darstellung im monatlichen Vergleich erkennen:
df.groupby('Monat')['Transaction'].nunique().plot(kind='bar', title='Monatliche Verkäufe')
plt.show()
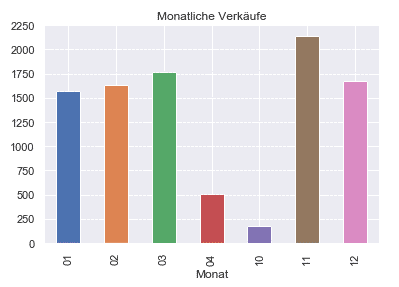
Die Monate Oktober und April stechen bei der Umsatzverteilung heraus. Woran könnte das liegen? Litt die Bäckerei in diesen Monaten unter einbrechenden Verkäufen? Um das zu prüfen, hilft ein Blick auf die Anzahl der Transaktionen im monatlichen Verlauf:
print(df.groupby('Monat')['Tag'].nunique())
Monat
01 30
02 28
03 31
04 9
10 2
11 30
12 29
Name: Tag, dtype: int64
Oktober und April entpuppen sich dabei tatsächlich als Ausreißermonate. Wie bereits in der Beschreibung des Datenbestandes vermerkt, wurden für den Datensatz im April nur 9 Tage und im Oktober sogar nur 2 Tage erfasst. Die zwei Monate sollten daher auf Grund mangelnder Relevanz bei der Analyse unberücksichtigt bleiben.
Warenkorbanalyse im Detail
Für die eigentliche Warenkorbanalyse kommt das Paket apriori [5] aus der Python-Bibliothek mlxtend (machine learning extensions) zum Einsatz. Die von dem Machine-Learning-Wissenschaftler Sebastian Raschka gut mit Beispielen beschriebene Bibliothek lässt sich leicht installieren – unter Anaconda beispielsweise mit dem Befehl conda install mlxtend.
Bevor apriori eingesetzt werden kann, müssen die Transaktionen für die Berechnung passend formatiert sein. Für den Fall, dass die Einkäufe in der Bäckerei in einer Tabellenkalkulation bearbeitet werden sollten, müsste die Liste der Transaktionen als Pivot-Tabelle vorliegen, in der jede Zeile den zu einem bestimmten Zeitpunkt abgeschlossenen Transaktion und jede Spalte einem von Kunden gekauften (1 oder True) oder nicht gekauften (0 oder False) Produkt entspricht:

Im Fall der schottischen Bäckerei ist der Datensatz mit 95 eindeutig verkauften Produkten und über 20.000 Transaktionen für eine Analyse in einer Tabellenkalkulation zu umfassend. Bei diesem Umfang der Daten geht leicht der Überblick für zusammengehörige Käufe verloren – ganz unabhängig vom hohen manuellen Rechenaufwand, der anfällt, wenn für jedes mögliche Produktpaar Support, Konfidenz und Lift zu ermitteln sind. In Python lässt sich der Aufwand auf wenige Zeilen Code reduzieren:
from mlxtend.preprocessing import TransactionEncoder
from mlxtend.frequent_patterns import association_rules, apriori
transaction_list = []
# FOR-Schleife zum Erstellen einer Liste der eindeutigen Transaktionen im Data-Set:
for i in df['Transaction'].unique():
tlist = list(set(df[df['Transaction']==i]['Item']))
if len(tlist)>0:
transaction_list.append(tlist)
print(len(transaction_list))
9465
te = TransactionEncoder()
te_ary = te.fit(transaction_list).transform(transaction_list)
df_ary = pd.DataFrame(te_ary, columns=te.columns_)
# print(df_ary)
Die Liste der eindeutigen Transaktionen lässt sich im TransactionEncoder für den späteren Einsatz des Apriori-Algorithmus formatieren. Der TransactionEncoder erstellt die Pivot-Matrix, in der jede Spalte einem Produkt entspricht, das gekauft (True) oder nicht gekauft (False) wurde. Die Python-Bibliothek mlxtend enthält außerdem einige Beispiele, an denen sich die im vorliegenden Artikel beschriebenen Manipulationen leichter nachvollziehen lassen.
Sobald der Datensatz formatiert ist, kommt der Apriori-Algorithmus mit den assoziativen Regeln zur Anwendung. Dabei wird für den Lift min_threshold = 1,0 festgelegt. Liegt der Lift-Wert unter 1,0, bedeutet das wie oben beschrieben, dass die beiden Produkte wahrscheinlich nicht zusammen gekauft werden.
Um die Wahrscheinlichkeiten erkennen zu können, ob ein Produkt gekauft wird, wenn sein "Vorgänger" gekauft wurde, sind die Ergebnisse nach der Konfidenz absteigend sortiert:
frequent_itemsets = apriori(df_ary, min_support=0.01, use_colnames=True)
rules = association_rules(frequent_itemsets, metric='lift', min_threshold=1.0)
# Nur die 'support', 'confidence', 'lift' Spalten anzeigen
result = rules[['antecedents', 'consequents', 'support', 'confidence', 'lift']]
result.sort_values('confidence', ascending=False)
# alles anzeigen
# rules.sort_values('confidence', ascending=False)
Die Warenkorbanalyse offenbart, dass Kunden mit 70-prozentiger Wahrscheinlichkeit (Konfidenz) auch einen Kaffee kaufen, wenn sie zuvor bereits ein Toast gewählt haben. Der Kauf eines Toasts macht den Kauf eines Kaffees also um 47 Prozent wahrscheinlicher (Lift 147 Prozent). Je höher also der Lift, desto stärker die Korrelation zwischen den beiden Produkten. Aus diesem Grund sind alle Beziehungen zwischen Produkten interessant, die ein hoher Lift verbindet – auch wenn die Konfidenz niedrig ist (Format: Vorgänger (antecedents) -> Folger (consequents)). Um solche Paare besser identifizieren zu können, lassen sich die Daten nach Lift absteigend sortieren.
Fazit
Die Analyse der Daten aus der schottischen Bäckerei zeigen, dass Kaffee insgesamt das beliebteste Produkt ist. Auch wenn Backwaren das Kernprodukt sind, ist das Ergebnis keine große Überraschung. Daher ist die Frage berechtigt, welchen Nutzen die Bäckerei aus einer solchen Warenkorbanalyse konkret ziehen kann?
Wie andere Handelsunternehmen sind auch Bäckereien bestrebt, ihr Angebot zu optimieren und den Umsatz zu steigern. Die Warenkorbanalyse liefert dafür Anhaltspunkte, mit welchen konkreten Maßnahmen sich erwünschte Effekte beeinflussen lassen:
- Der Umsatz pro Kunden lässt sich erhöhen, in dem gezielt jene Produkte angeboten werden, die bevorzugt zusammen gekauft werden.
- Optimierung in der Auslage: Produkte, die häufiger zusammen gekauft werden, lassen sich näher beieinander platzieren, um sie Kunden auch optisch "näherzubringen".
- Preisgestaltung: Für Kombiangebote lassen sich die Preise anhand der Konfidenz leichter spezifizieren. So sind Rabatte auf "beliebte" Produktkombinationen denkbar, die Kunden zum Kauf reizen, ohne den Gewinn der Bäckerei zu gefährden – beispielsweise eine "Guten Abend"-Tüte mit den meistgekauften Produkten.
Vladimir Poliakov
absolvierte 1995 das Studium an der Russian State Hydrometeorological University (RSHU) in St. Petersburg und arbeitete im Forschungsinstitut für Arktis und Antarktis. Nach seiner Auswanderung nach Deutschland war er seit 1998 in der IT-Branche als Entwickler, DBA, System Architekt, BI- und Big Data-Spezialist aktiv und ist zurzeit hauptberuflich als Data Engineer bei der TeamBank AG tätig.
(map [6])
URL dieses Artikels:
https://www.heise.de/-4425737
Links in diesem Artikel:
[1] https://www.kaggle.com/sulmansarwar/transactions-from-a-bakery
[2] https://de.wikipedia.org/wiki/Data-Mining
[3] https://www.enthought.com/product/canopy/
[4] https://www.anaconda.com/distribution/
[5] https://rasbt.github.io/mlxtend/user_guide/frequent_patterns/apriori/
[6] mailto:map@ix.de
Copyright © 2019 Heise Medien