

Die hybride Cloud mit Docker Swarm und Ansible (2/2)
Nachdem die hybride Cloud aus Windows- und Linux-Systemen dank Packer und Vagrant zur Verfügung steht, soll Ansible jetzt einen Docker Swarm automatisiert initialisieren und das Deployment vorbereiten.

- Jonas Hecht
Im ersten Teil der Artikelserie ist die "Cloud in der Hosentasche" mit Packer und Vagrant so aufgebaut worden, dass alle Kombinationen aus Windows- und Linux-Maschinen in einer hybriden Cloud lokal für weitere Schritte zur Verfügung stehen. Darauf aufbauend zeigt dieser Artikel, wie Ansible einen Docker Swarm vollautomatisiert initialisiert und das spätere Applikations-Deployment vorbereitet.
Bevor Ansible Maschinen provisionieren kann, müssen sie zur Verfügung stehen und für die Verbindung per SSH oder WinRM vorbereitet sein. Mit den "Infrastructure-as-Code"-Werkzeugen Packer und Vagrant kann auch dieser Schritt automatisiert ablaufen. Sobald sich das Projekt mehr in Richtung Produktion bewegt, ist der Einsatz von zum Beispiel Terraform ebenfalls denkbar. Es stehen mehrere virtuelle Maschinen zur Verfügung, benannt nach ihrer späteren Verwendung im Docker Swarm. Nun kann Ansible das Zepter übernehmen.
Um einen Docker Swarm so bereitzustellen, dass danach alles für ein Applikations-Deployment bereitsteht, sind einige Schritte notwendig. Zuerst sollte Docker auf allen Cluster-Nodes installiert und konfiguriert sein. Dann ist die Initalisierung eines Docker Swarm möglich. Außerdem sollte man nicht vergessen, eine Docker Swarm Registry zu konfigurieren und als Docker Swarm Service zu starten. Denn über den Service läuft später die Bereitstellung der Docker-Images der Applikationen auf alle Cluster-Nodes. Nicht zuletzt darf eine Managementoberfläche für den einfachen Überblick über alle Docker-Nodes und den Swarm als Ganzes nicht fehlen.
Ansible stellt Docker auf allen Cluster-Nodes bereit
Alle beschriebenen Schritte sind wieder vollständig nachvollziehbar im Beispiel-GitHub-Projekt verfügbar. Dort findet sich das Verzeichnis step4-windows-linux-multimachine-vagrant-docker-swarm-setup, das wiederum das Ansible-Playbook prepare-docker-nodes.yml enthält. Ist die Abstrahierung der Details in den Playbooks sauber, kann praktisch jedes (Scrum-)Teammitglied sie lesen (und verstehen):
- hosts: all
tasks:
- name: Checking Ansible connectivity to Windows nodes
win_ping:
when: inventory_hostname in groups['windows']
- name: Checking Ansible connectivity to Linux nodes
ping:
when: inventory_hostname in groups['linux']
- name: Allow Ping requests on Windows nodes (which is by default disabled in Windows Server 2016)
win_shell: "netsh advfirewall firewall add rule name='ICMP Allow incoming V4 echo request' protocol=icmpv4:8,any
when: inventory_hostname in groups['windows']
- name: Prepare Docker on Windows nodes
include: "../step1-prepare-docker-windows/prepare-docker-windows.yml host=windows"
- name: Prepare Docker on Linux nodes
include: prepare-docker-linux.yml host=linux
- name: Allow local http Docker registry
include: allow-http-docker-registry.yml
Aufgrund der Abstraktion der Details der Provisionierung gibt es das Phänomen, dass es keine besseren How-to-Beschreibungen als Ansible-Playbooks gibt. Die notwendigen Befehle sind in Form eines Blog-Posts nacheinander aufgelistet – mit dem Unterschied, dass ein Ansible-Playbook ausführbar ist. Damit ist nachgewiesen, dass das im Playbook beschriebene Verfahren funktioniert.
Mit dem Befehl ansible-playbook -i hostsfile prepare-docker-nodes.yml ist das vorliegende Playbook einfach im Verzeichnis step4-windows-linux-multimachine-vagrant-docker-swarm-setup ausführbar. Während der Ausführung steht genug Zeit zur Verfügung, sich mit den Details des Skripts vertraut zu machen. Bereits die erste Zeile ist dabei beachtenswert. Die Anweisung hosts: all beauftragt Ansible, alle zur Verfügung stehenden Maschinen parallel zu provisionieren. Das heißt, dass die Skriptausführung praktisch gleichzeitig auf den Cluster-Nodes masterlinux01 , masterwindows01 , workerlinux01 und workerwindows01 läuft.
Die folgenden zwei tasks stellen eine Empfehlung beim Umgang mit Ansible dar – besonders in hybriden Umgebungen. Zuerst sollte immer eine Prüfung der Verbindung stehen. Nur, wenn Ansible auf alle Maschinen Zugriff hat, sollte man die Skriptausführung fortsetzen.
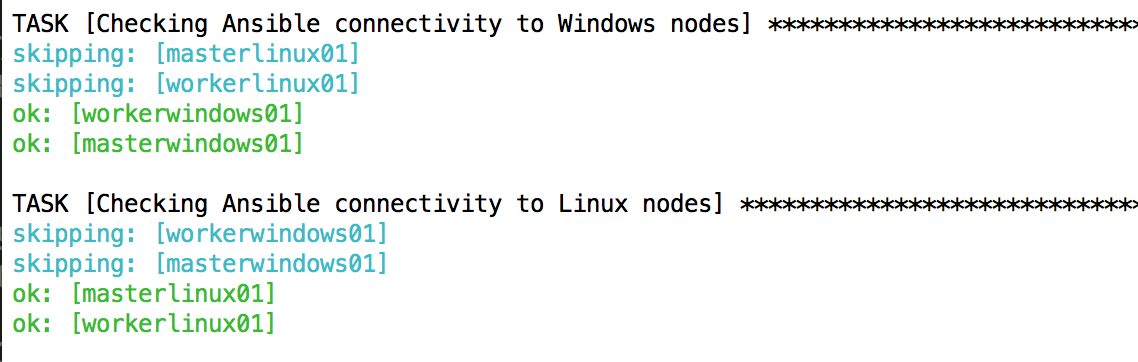
Erste Schritte zeigen eine wichtige Erkenntnis mit Ansible im Umgang mit hybriden Clustern auf. Da die meisten Ansible-Module strikt nach Linux und Windows getrennt und zueinander inkompatibel sind, muss immer sichergestellt sein, welche Art von Maschine man gerade aufrufen möchte. Die sogenannten Ansible conditionals und die Anweisung when können hierbei helfen. Die folgende Bedingung stellt sicher, dass das definierte Ansible-Modul sich ausschließlich auf einem Host der Gruppe linux ausführen lässt:
when: inventory_hostname in groups['linux']
Damit findet das Modul nur auf den Hosts masterlinux01 und workerlinux01 Anwendung und es ignoriert die Windows-Hosts masterwindows01 und workerwindows01. Entsprechend funktioniert das auch genau entgegengesetzt:
when: inventory_hostname in groups['windows']
Im Ansible-Playbook prepare-docker-nodes.yml folgt auf die Verbindungstests ein Windows-exklusiver task. Denn Windows Server 2016 blockiert im Auslieferungszustand den ping. Damit das im späteren Verlauf nicht zu Problemen führt, steht ein Powershell-Kommando bereit, das mit Ansible-Moduls win_shell ausführbar ist:
- name: Allow Ping requests on Windows nodes (which is by default disabled in Windows Server 2016)
win_shell: "netsh advfirewall firewall add rule name='ICMP Allow incoming V4 echo request' protocol=icmpv4:8,any
when: inventory_hostname in groups['windows']
Mit den nachfolgenden tasks folgt eine Docker-Installation auf allen Cluster-Nodes. Glücklicherweise können Entwickler wieder auf den letzten Artikel "Docker-Windows-Container mit Ansible managen" aufbauen. Der Artikel beschreibt im Detail, wie die Installation und Konfiguration der aktuellen Inkarnationsstufe von Docker unter Windows (auch "Docker native" genannt) per Ansible funktioniert. Das entsprechende Playbook kann einfach Wiederverwendung finden. Nur die Anweisung host=windows benötigt eine Konfiguration, damit das Skript im aktuellen Kontext funktioniert:
- name: Prepare Docker on Windows nodes
include:"../step1-prepare-docker-windows/prepare-docker-windows.yml
host=windows"
Genau den Anweisungen des offiziellen "Get Docker CE for Ubuntu"-Guide zufolge funktioniert die Bereitstellung von Docker auf den Ubuntu-Nodes. Das aufgerufene Playbook prepare-docker-linux.yml schließt wiederum mit der Anweisung host=linux ab, damit nur die Linux-Nodes nach diesem Verfahren mit Docker bestückt sind.
- name: Prepare Docker on Linux nodes
include: prepare-docker-linux.yml host=linux
Falls jetzt eine andere Linux-Distribution zum Einsatz kommen soll, sind die jeweiligen Anweisungen im inkludierten Playbook prepare-docker-linux.yml anzupassen oder eine entsprechende Ansible-Rolle aus der Ansible Galaxy zu nutzen.
HTTP-basierte Docker-Registries erlauben
Der letzte Schritt des Playbooks prepare-docker-nodes.yml – und damit in der Konfiguration von Docker auf allen Cluster- Nodes – kann im ersten Moment für Verwunderung sorgen. Wie bereits erwähnt, soll der finale Docker Swarm für das spätere Applikations-Deployment vorbereitet sein. Der im Vorartikel "Docker-Windows-Container mit Ansible managen" verwendete Ansatz sorgt im aktuellen Kontext allerdings für viel Zusatzaufwand. Er basiert nämlich darauf, die Docker-Images auf einer Windows-Vagrant-Box zu bauen. In einer hybriden Cloud-Umgebung sind allerdings viel mehr als eine Maschine im Einsatz, wie im vorliegenden Beispielszenario mit vier Vagrant-Boxen. Die Docker-Images auf jeder Maschine neu zu bauen, ist nicht praktikabel.
Besser gelingt das Bereitstellen der Docker-Images für jeden Cluster-Node mit einer lokalen Docker Registry. Mit ihr muss man das Docker-Image nur einmal bauen und allen anderen Cluster-Nodes über die Registry verfügbar machen.
Eine lokale Docker Registry als Docker Swarm Service zu starten, benötigt an dieser Stelle etwas Vorbereitung. Die einfachste Art, eine lokale Docker Registry bereitzustellen, ist die sogenannte plain-htp-Registry. Sie sollte im vorliegenden isoliert deployten Beispiel kein großes Sicherheitsrisiko darstellen – genauso wie in vielen On-Premise-Installationen. Wichtig ist allerdings das Update auf eine per TLS-Zertifikate gesicherte Registry, sobald diese von außen zugreifbar sein soll, und etwa das Deployment des Docker Swarm auf den Systemen eines Cloud-Providers stattfindet.
Für den einfachen Fall einer plain-http-Registry muss jede Docker-Engine auf jedem Cluster-Node die Ausführung solcher "ungesicherter" Registries erlauben. Die Konfiguration ist mit der Datei daemon.json möglich, die die folgenden Zeilen enthalten muss:
{
"insecure-registries" : ["172.16.2.10:5000"]
}
Da die Ausführung der Docker Swarm Registry später auf dem Linux-Manager-Node stattfindet, enthält die Zeile dessen IP-Adresse 172.16.2.10. Zur Erinnerung: die IP-Adresse ist explizit im Vagrantfile für diese Maschine konfiguriert.
Natürlich ist die korrekte Ablage der Datei im vorliegenden Beispielprojekt per Ansible automatisiert. Das dafür inkludierte Playbook allow-http-docker-registry.yml gibt dann auch die für das jeweilige Betriebssystem passenden Pfade der Datei daemon.json preis:
- name: Template daemon.json to /etc/docker/daemon.json on Linux nodes for later Registry access
template:
src: "templates/daemon.j2"
dest: "/etc/docker/daemon.json"
become: yes
when: inventory_hostname in groups['linux']
- name: Template daemon.json to C:\ProgramData\docker\config\daemon.json on Windows nodes for later Registry access
win_template:
src: "templates/daemon.j2"
dest: "C:\\ProgramData\\docker\\config\\daemon.json"
when: inventory_hostname in groups['windows']
Damit sind die Docker-Engines auf allen Cluster-Nodes bereit für den Einsatz im Docker Swarm.
Initialisierung des Docker Swarm
Nachdem sichergestellt ist, dass die Docker-Engines auf allen Nodes korrekt konfiguriert und lauffähig sind, kann nun die Initialisierung des Docker Swarm beginnen. Dazu enthält das Beispiel-Repository auf GitHub das Ansible-Playbook initialize-docker-swarm.yml mit allen Schritten, die für einen vollständig lauffähigen Docker Swarm notwendig sind. Wieder sollte sich das Playbook ohne tiefergehende Kenntnisse der Details erschließen:
- hosts: all
vars:
masterwindows_ip: 172.16.2.12
tasks:
- name: Checking Ansible connectivity to Windows nodes
win_ping:
when: inventory_hostname in groups['windows']
- name: Checking Ansible connectivity to Linux nodes
ping:
when: inventory_hostname in groups['linux']
- name: Open Ports in firewalls needed for Docker Swarm
include: prepare-firewalls-for-swarm.yml
- name: Initialize Swarm and join all Swarm nodes
include: initialize-swarm-and-join-all-nodes.yml
- name: Label underlying operation system to each node
include: label-os-specific-nodes.yml
- name: Run Portainer as Docker and Docker Swarm Visualizer
include: run-portainer.yml
- name: Run Docker Swarm local Registry
include: run-swarm-registry.yml
- name: Display the current Docker Swarm status
include: display-swarm-status.yml
Vor der genauen Betrachtung der Inhalte des Playbooks empfiehlt sich dessen Ausführung. So sind alle weiteren Schritte wieder lokal nachvollziehbar. Das geht am Einfachsten im bekannten Verzeichnis step4- windows-linux-multimachine-vagrant-docker-swarm-setup mit dem Befehl:
ansible-playbook -i hostsfile initialize-docker-swarm.yml
Am Ende der Ausführung des Playbooks steht ein vollständig initialisierter Docker Swarm für das Applikations-Deployment bereit. Wie gewohnt bietet ein Playbook immer eine genaue Beschreibung der notwendigen Schritte zur Installation, die selbst ohne Ansible-Kenntnisse durchführbar sind. Die ersten zwei tasks des Playbooks initialize-docker-swarm.yml sind nicht unbekannt. Sie überprüfen zu Beginn, ob Ansible mit allen Cluster-Nodes einwandfrei kommunizieren kann.
Direkt danach folgt der Aufruf des Playbooks prepare-firewalls-for-swarm.yml, das für den Swarm notwendige Ports öffnet. Innerhalb der Docker-Dokumentation findet der Punkt erst weit am Ende Erwähnung – auch wenn die geöffneten Ports eine Voraussetzung für den späteren Docker-Swarm-Betrieb sind. Über den geöffneten TCP-Port 2377 können die Docker-Swarm-Nodes mit dem Windows-Manager-Node kommunizieren und sich damit zu einem funktionierenden Schwarm zusammenfügen. Dazu verwendet man im Playbook die Bedingung when: inventory_hostname in groups['masterwindows']. Sie stellt sicher, dass der Port nur auf dem Windows-Manager-Node eine Freigabe erhält.
Die zwei folgenden Portfreischaltungen beschreibt die Dokumentation ebenfalls als essenziell für einen funktionierenden Docker Swarm: "[...] you need to have the following ports open between the swarm nodes before you enable swarm mode."
Verwunderlich, dass sie dort erst am Ende auftauchen. Denn die Freischaltungen müssen vor der Initialisierung des Docker Swarm passieren. Dabei ist der TCP/UDP-Port 7946 für die gegenseitige Erreichbarkeit der Container im Docker-Swarm-Netzwerk notwendig. Das Docker-Swarm-Overlay-Netzwerk benötigt den UDP-Port 4789.
Den Schwarm zusammenfügen
Nach den notwendigen Port-Freischaltungen folgt endlich die ersehnte Initialisierung des Docker Swarm. Dazu inkludiert das Haupt-Playbook initialize-docker-swarm.yml im nächsten task das Playbook initialize-swarm-and-join-all-nodes.yml. Wie das im Detail funktioniert, verrät es dem geneigten Leser:
- name: Leave Swarm on Windows master node, if there was a cluster before
win_shell: "docker swarm leave --force"
ignore_errors: yes
when: inventory_hostname == "masterwindows01"
- name: Initialize Docker Swarm cluster on Windows master node
win_shell: "docker swarm init --advertise-addr={{masterwindows_ip}} --listen-addr {{masterwindows_ip}}:2377"
ignore_errors: yes
when: inventory_hostname == "masterwindows01"
- name: Pause a few seconds after new Swarm cluster initialization to prevent later errors on obtaining tokens to ear
pause:
seconds: 5
...
Der erste Schritt mutet dabei etwas kurios an, denn er veranlasst den Windows-Manager-Node, zuallererst einen etwaig bestehenden Schwarm zu verlassen. Natürlich spielt dieser Schritt bei der ersten Ausführung des Playbooks keine Rolle – und erzeugt eine Fehlermeldung, dass ja kein Swarm vorhanden sei. Das Schlüsselwort ignore_errors: yes ignoriert den Fehler. Führt man das Playbook ein weiteres Mal aus, zeigt sich die Wichtigkeit des ersten Schritts. Denn nur in einer definierten Ausgangssituation lässt sich ein Docker Swarm initialisieren. Das heißt in dem vorliegenden Fall, dass der Windows-Manager-Node kein Teil eines "alten" Swarms ist. Damit ist ein wichtiges Design-Prinzip von Ansible-Playbooks umgesetzt: Am Ende der Ausführung lässt sich immer vom gleichen Stand ausgehen, im Beispiel also von einem korrekt initialisierten Docker Swarm. Ohne den ersten Schritt wäre dies nicht möglich, da alle Folgeschritte nicht durchführbar wären.
Danach folgt endlich der magische Moment: Der Windows-Manager-Node erhebt sich zum Docker-Swarm-Manager. Hierfür wurde im Beispielprojekt ein Windows-Node gewählt, um das volle Potenzial eines hybriden Docker-Swarm-Clusters zu zeigen. Im Befehl docker swarm init müssen sich beide Parameter advertise-addr und listen-addr auf den Windows-Manager-Node beziehen. Da die Ausführung des Befehls erfahrungsgemäß etwas Zeit in Anspruch nimmt, folgt im nächsten Schritt das Ansible-Modul pause, das dem Manager-Node ein paar Sekunden Zeit für die Initialisierung einräumt. Die folgenden Schritte laufen ohne diese Pausierung der Skript-Ausführung oftmals in einen Fehler.
In den nächsten Schritten geht es um das Auslesen der sogenannten Join-Tokens. Diese sind im weiteren Verlauf notwendig, um die anderen Cluster-Nodes zum Docker Swarm hinzuzufügen. Dabei gibt es eine Unterscheidung in Manager- und Worker-Join-Tokens, die sich mit dem Befehl docker swarm join-token manager -q und docker swarm join-token worker -q auslesen lassen:
...
- name: Obtain worker join-token from Windows master node
win_shell: "docker swarm join-token worker -q"
register: worker_token_result
ignore_errors: yes
when: inventory_hostname == "masterwindows01"
- name: Obtain manager join-token from Windows master node
win_shell: "docker swarm join-token manager -q"
register: manager_token_result
ignore_errors: yes
when: inventory_hostname == "masterwindows01"
- name: Syncing the worker and manager join-token results to the other hosts
set_fact:
worker_token_result_host_sync: "{{ hostvars['masterwindows01']['worker_token_result'] }}"
manager_token_result_host_sync: "{{ hostvars['masterwindows01']['manager_token_result'] }}"
- name: Extracting and saving worker and manager join-tokens in variables for joining other nodes later
set_fact:
worker_jointoken: "{{worker_token_result_host_sync.stdout.splitlines()[0]}}"
manager_jointoken: "{{manager_token_result_host_sync.stdout.splitlines()[0]}}"
- name: Join-tokens...
debug:
msg:
- "The worker join-token is: '{{worker_jointoken}}'"
- "The manager join-token is: '{{manager_jointoken}}'"
...
Das Auslesen der Join-Tokens ist durch die Bedingung when: inventory_hostname == "masterwindows01" explizit auf den Windows-Manager-Node beschränkt. Das heißt ebenfalls, dass die per Schlüsselwort register gespeicherten Join-Tokens ausschließlich auf diesem Node zur Verfügung stehen. Doch für die Initialisierung sind die Join-Tokens natürlich auf den anderen Cluster-Nodes ebenfalls notwendig. Deshalb muss eine Weitergabe während der Ausführung des Ansible-Skripts an die anderen Ansible-hosts stattfinden. Dazu muss man etwas tiefer in die Ansible-Trickkiste greifen. Mit dem Ansible-Modul set_fact definiert man zur Lauftzeit Variablen, auf die später die anderen Ansible-hosts zugreifen können. Befüllt werden diese dynamischen Variablen mit dem hostvars-Schlüsselwort:
worker_token_result_host_sync: "{{ hostvars['masterwindows01']['worker_token_result'] }}"
Die Anweisung hostvars['masterwindows01'] ermöglicht direkten Zugriff auf die Windows-Manager-Node-exklusiven Variablen. Das angehängte ['worker_token_result'] ermöglicht den Zugriff auf das registrierte Ergebnis des docker swarm join-token-Kommandos. Im anschließenden Schritt gibt es eine Extraktion der eigentlichen Join-Tokens aus den nun synchronisierten Ergebnissen, denn sie enthalten eine ganze Reihe an Rückgabewerten, die Ansible definiert. Die Join-Tokens befinden sich im Rückgabewert stdout, der zusätzlich noch ein Zeilenende enthält, das per splitlines()[0]abgeschnitten werden muss.
Ein Blick in die Konsole, die das Ansible-Skript ausführt, zeigt die konkreten Join-Tokens, die dasdebug-Modul ausgibt.
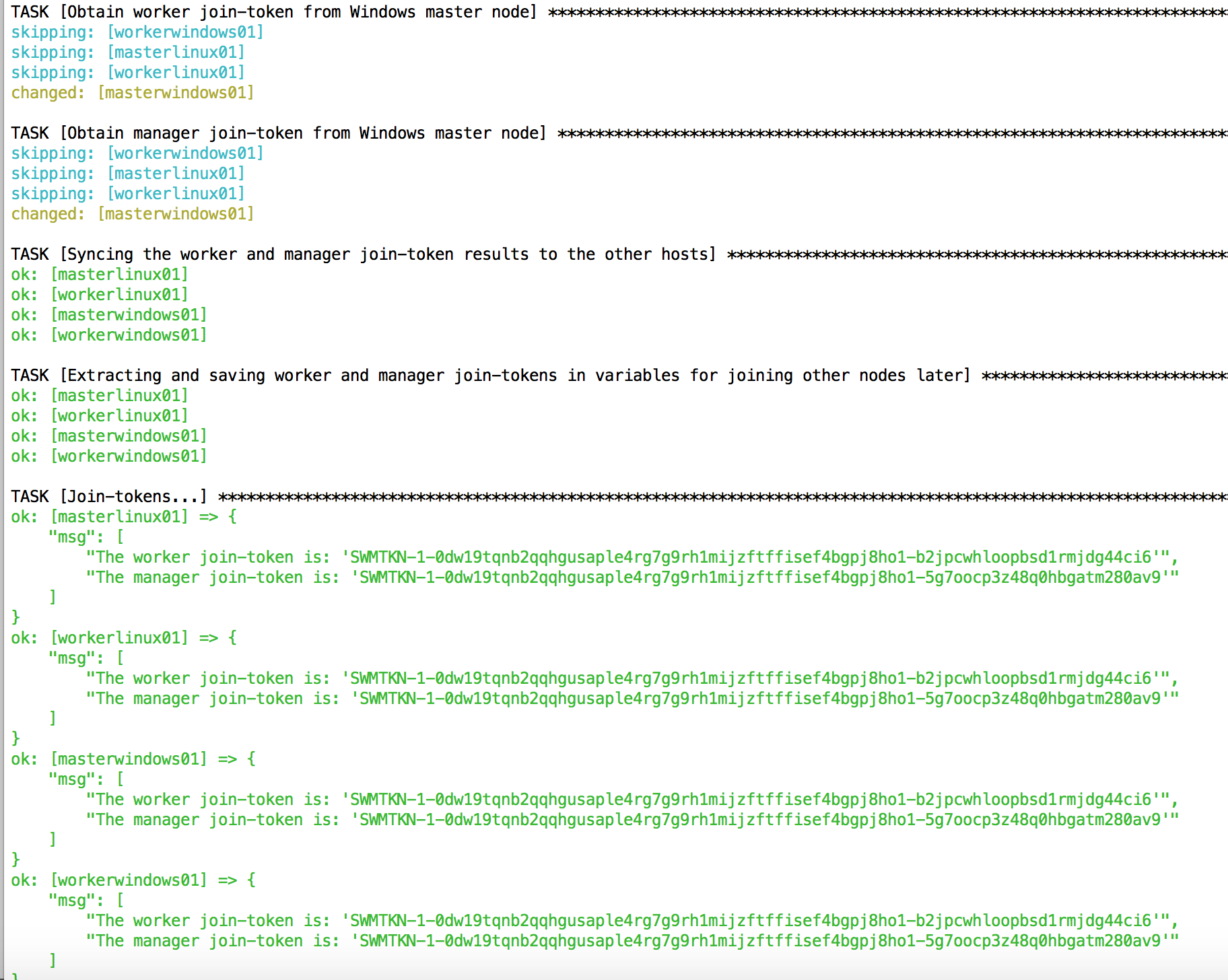
Alle weiteren Cluster-Nodes lassen sich mit den passenden Join-Tokens dem Schwarm hinzufügen. Hier ist wieder jedem docker swarm join-Kommando der Befehl zum Verlassen eines etwaig vorher bestandenen Schwarms vorangestellt. Um einen Worker-Node dem Schwarm hinzuzufügen, kommt das Kommando docker swarm join --token {{worker_jointoken}} {{masterwindows_ip}} zum Einsatz. Das Hinzufügen eines Manager-Nodes erledigt das sehr ähnliche docker swarm join --token {{manager_jointoken}} {{masterwindows_ip}} erledigt:
...
- name: Leave Swarm on Windows worker nodes, if there was a cluster before
win_shell: "docker swarm leave"
ignore_errors: yes
when: inventory_hostname in groups['workerwindows']
- name: Add Windows worker nodes to Docker Swarm cluster
win_shell: "docker swarm join --token {{worker_jointoken}} {{masterwindows_ip}}"
ignore_errors: yes
when: inventory_hostname in groups['workerwindows']
- name: Leave Swarm on Linux worker nodes, if there was a cluster before
shell: "docker swarm leave"
ignore_errors: yes
when: inventory_hostname in groups['workerlinux']
- name: Add Linux worker nodes to Docker Swarm cluster
shell: "docker swarm join --token {{worker_jointoken}} {{masterwindows_ip}}"
ignore_errors: yes
when: inventory_hostname in groups['workerlinux']
- name: Leave Swarm on Linux manager nodes, if there was a cluster before
shell: "docker swarm leave --force"
ignore_errors: yes
when: inventory_hostname in groups['masterlinux']
- name: Add Linux manager nodes to Docker Swarm cluster
shell: "docker swarm join --token {{manager_jointoken}} {{masterwindows_ip}}"
ignore_errors: yes
when: inventory_hostname in groups['masterlinux']
...
Mit der Ausführung dieser Zeilen steht ein voll funktionsfähiger Docker Swarm zur Verfügung!
Portainer visualisiert den Schwarm
Natürlich ist der Schwarm nun vollständig initialisiert. Mit dem Docker Swarm CLI steht die gesamte Bandbreite an Interaktionsmöglichkeiten zur Verfügung. Beispielsweise zeigt der Befehl docker service ls alle laufenden Docker Swarm Services und das Kommando docker service ps [ServiceName] die Interna eines solchen Services. Trotzdem kann es sicherlich nicht schaden, eine grafische Aufbereitung in Form einer Managementoberfläche zur Verfügung zu haben.
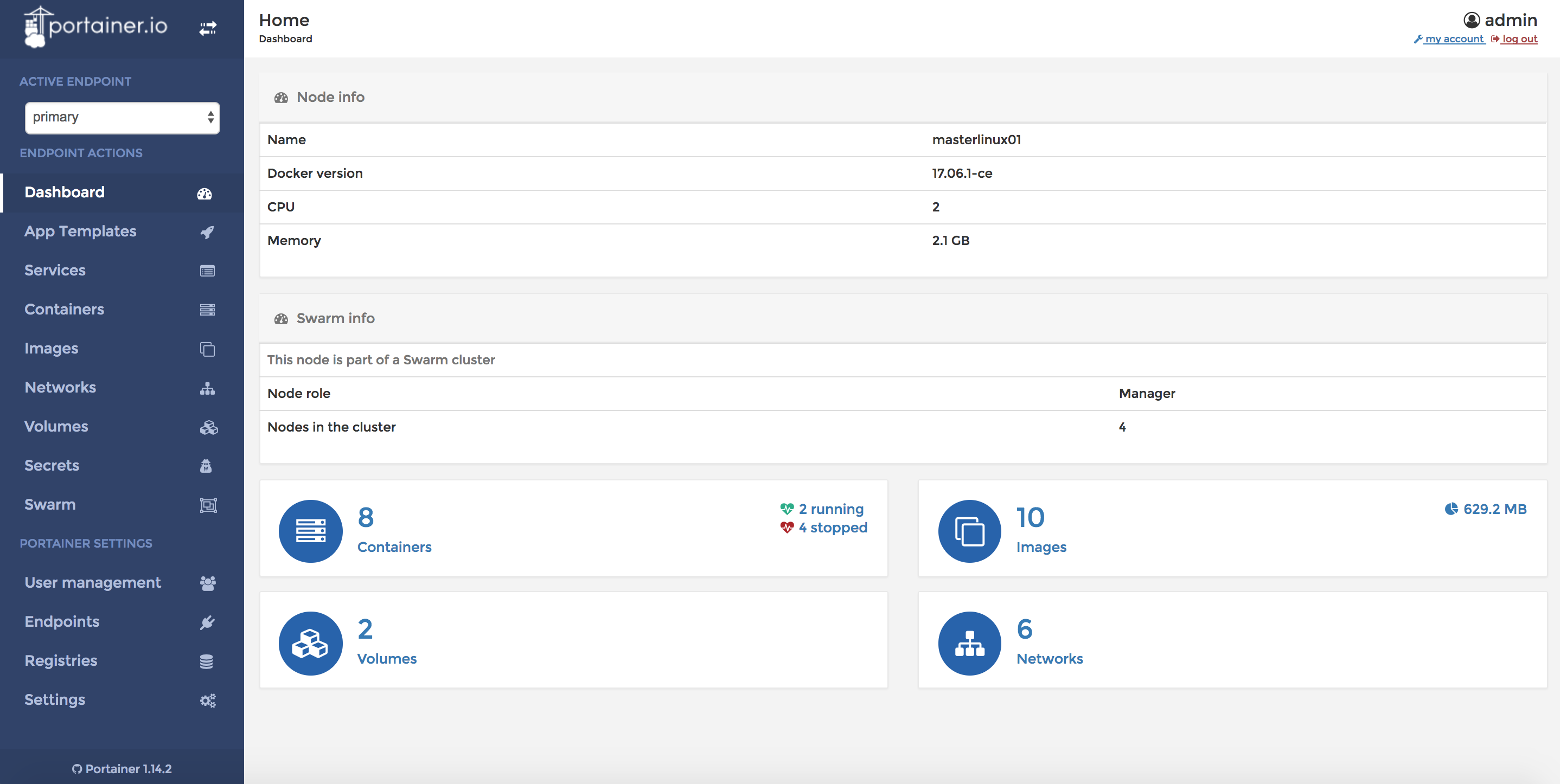
Docker stellt zwar selbst mit dem Projekt Swarm Visualizer eine Visualisierungsoberfläche zur Verfügung, allerdings steht mit dem Tool Portainer eine weitaus umfangreichere und ausgereiftere Alternative zur Verfügung, die ebenfalls vollständig als Open-Source-Software vorliegt. Im Internet finden sich dazu viele Gegenüberstellungen. Und da Portainer zusätzlich hybride Cluster aus Windows- und Linux-Nodes vollständig unterstützt, steht der Nutzung im vorliegenden Szenario nichts im Wege.
Dazu enthält das Beispielprojekt eine komplette Portainer-Konfiguration. Das im Haupt-Playbook inkludierte run-portainer.yml enthält alle dafür notwendigen Anweisungen:
- name: Create directory for later volume mount into Portainer service on Linux Manager node if it doesn´t exist
file:
path: /mnt/portainer
state: directory
mode: 0755
when: inventory_hostname in groups['linux']
sudo: yes
- name: Run Portainer Docker and Docker Swarm Visualizer on Linux Manager node as Swarm service
shell: "docker service create --name portainer --publish 9000:9000 --constraint 'node.role == manager' --constraint
ignore_errors: yes
when: inventory_hostname == "masterlinux01"
Nach der Erstellung eines Mount-Punkts für die später zu persistierenden Portainer-Meta-Daten, deployt man Portainer als Docker Swarm Service. Die beiden Constraints --constraint 'node.role == manager' sowie -- constraint 'node.labels.os==linux' sorgen dafür, dass Docker Swarm Portainer nur auf Linux-Manager-Nodes laufen lässt. Im aktuellen Beispiel damit also genau auf einer Maschine. Die Anweisung [i]--mount type=bind,src=/var/run/docker.sock,dst=/var/run/docker.sock gibt Portainer direkten Zugriff auf die laufende Docker-Instanz des Linux-Manager-Nodes. Dadurch ist Portainer in der Lage, alle möglichen Management-Aufgaben innerhalb eines Docker Swarm auszuführen. Weitere Konfigurationsmöglichkeiten verrät die Portainer-Dokumentation.
Ein Aufruf der Portainer-Weboberfläche von einem der Windows-Nodes kann schnell frustrieren. Denn der installierte Internet-Explorer ist nicht in der Lage, die auf einer neueren Angular-Version basierende Oberfläche von Portainer vernünftig darzustellen. Per Ansible ist ein aktueller Browser aber schnell installiert. Dann lässt sich Portainer einfach per http://172.16.2.10:9000 aufrufen.
Doch im vorliegenden Beispielprojekt ist das gar nicht nötig. Denn die Konfigurationsanweisung masterlinux.vm.network "forwarded_port", guest: 9000, host: 49000, host_ip: "127.0.0.1", id: "portainer" im Vagrantfile des Vagrant-Multi-Machine-Clusters bindet den Port 49000 des Host-Systems an den Port 9000 des Linux-Manager-Nodes. Und auf dem Port ist der Portainer-Docker Swarm Service deployt. Es genügt ein Aufruf der Adresse http://localhost:49000/ im Browser des Vagrant-Hosts, um Portainer zu öffnen.
Eine lokale Docker Swarm Registry
Wie im Abschnitt "HTTP-basierte Docker-Registries erlauben" erwähnt, gelingt das Bereitstellen der Docker-Images für das Applikations-Deployment auf jeden Cluster-Node am einfachsten mit einer lokalen Docker Registry. Obwohl eine Docker Registry nicht direkt zum Initialisieren eines Docker Swarm notwendig ist, ist sie für einen vollständig nutzbaren Schwarm doch unverzichtbar. Die Initialisierung einer Registry ist in der Docker-Dokumentation beschrieben. Allerdings hat sie noch einige Pull-Requests (docker.github.io/pull/4465, docker.github.io/pull/4641 und docker.github.io/pull/4644) nötig. Das Beispielprojekt setzt die Docker Registry wieder mit Ansible auf. Dazu kommt das inkludierte Playbook run-swarm-registry.yml zum Einsatz:
- name: Specify to run Docker Registry on Linux Manager node
shell: "docker node update --label-add registry=true masterlinux01"
ignore_errors: yes
when: inventory_hostname == "masterlinux01"
- name: Create directory for later volume mount into the Docker Registry service on Linux Manager node if it doesn´t
file:
path: /mnt/registry
state: directory
mode: 0755
when: inventory_hostname in groups['linux']
sudo: yes
- name: Run Docker Registry on Linux Manager node as Swarm service
shell: "docker service create --name swarm-registry --constraint 'node.labels.registry==true' --mount type=bind,src
ignore_errors: yes
when: inventory_hostname == "masterlinux01"
Passend für Linux ist das Docker-Image für eine Docker Registry standardmäßig über den hub.docker.com bereitgestellt. Um die Registry auf dem Linux-Manager-Node auszuführen, versieht man ihn zuerst mit dem shell-Modul und dem Kommando docker node update mit dem Label registry=true. Danach erfolgt - wie schon bei der Portainer- Konfiguration - die Erstellung eines Mount-Punkts, der später von der Registry als persistente Ablagemöglichkeit für Docker-Images Verwendung findet.
Im letzten Schritt im Playbook weist Docker Swarm an, die Registry als Service auf dem Linux-Manager-Node zu starten und sie auf dem Port 5000 bereitzustellen. Nach der Ausführung des Ansible-Playbooks sollte der Docker Swarm einen Service mit dem Namen swarm-registry ausführen. Am einfachsten ist die Überprüfung über die Portainer-Oberfläche möglich.
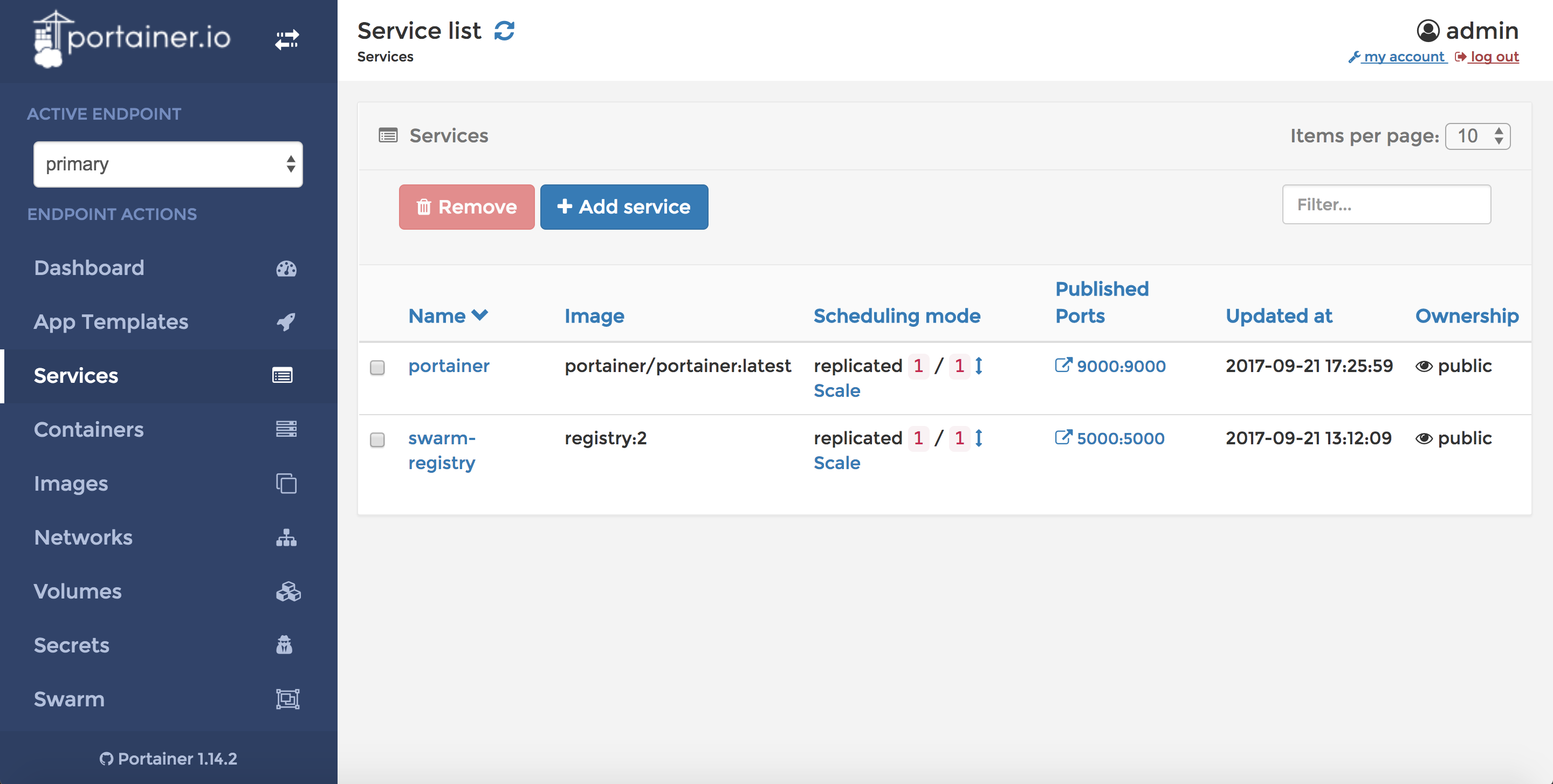
Im Haupt-Playbook initialize-docker-swarm.yml folgt nur noch ein letzter Schritt. Der letzte task inkludiert das Playbook display-swarm-status.yml, das nicht viel mehr zu tun hat, als den aktuellen Status des Schwarms am Ende der Ausführung des Ansible-Skripts auf der Kommandozeile auszugeben.
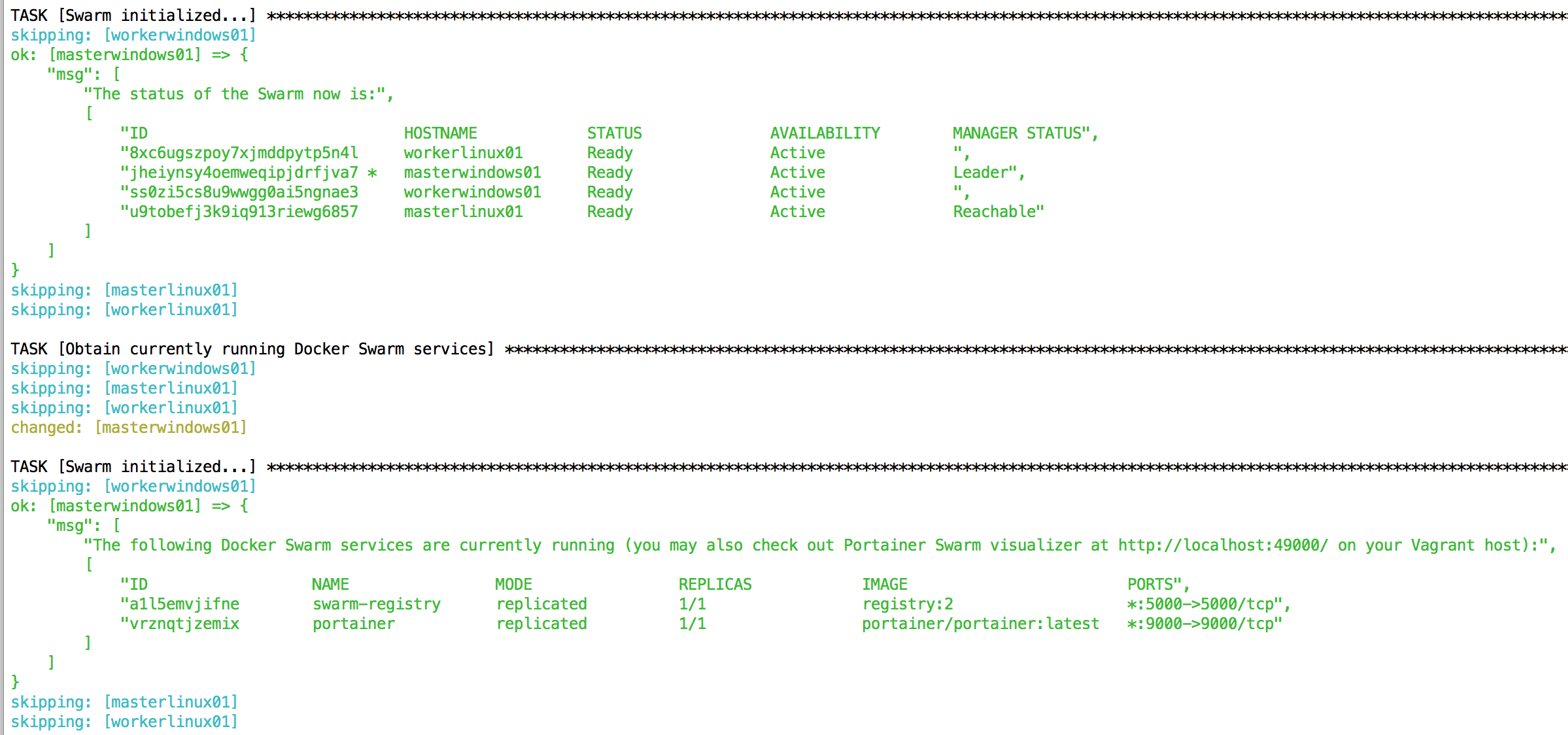
Fazit
Mit dem letzten Schritt steht ein vollständig initialisierter Docker Swarm zur Verfügung. Mit Infrastructure-as-Code- und DevOps-Tools wie Vagrant, Packer und Ansible ist es also möglich, ein vollständig nachvollziehbares und automatisiertes Setup eines hybriden Docker Swarm durchführen. Dieser integriert Windows- sowie Linux- Maschinen in allen innerhalb eines solchen Schwarms möglichen Rollen – seien es Manager- oder Worker-Nodes. Dieses Vorgehen erreicht mehrere wichtige Ziele.
Zuallererst lässt sich das berühmte "Works-on-my-Maschine"-Pattern umgehen, auf das leider auch die meisten Blogbeiträge setzen. Jeder Schritt ist zu 100 Prozent nachvollziehbar. Und das sogar für jeden im Entwicklungsteam – mit vertretbarem Einarbeitungsaufwand. Sollten die vielen genutzten Verfahren doch einmal zu unvorhergesehenen Fehlersituationen führen, können Entwickler jederzeit alles von vorn neu aufsetzen. Alles was dazu nötig ist, ist ein Klick und eventuell der Besuch der Kaffeemaschine. Und sollte es einen Fehler geben, kann ein Pull-Request diesen beheben. Besonders in der schnellen Entwicklung in der Welt der Docker-Windows-Container ist das Vorgehen empfehlenswert. Auch die vielen Microservice-Architekturen können von solch einem vollautomatisierten Ansatz nur profitieren, ist doch das Management der Infrastruktur durch die große Anzahl an nötigen Umgebungen nicht mehr sinnvoll manuell machbar.
Zusätzlich zeigt das Setup alle Schritte auf, die nötig sind, um einen hybriden Mixed-OS Docker-Swarm-Cluster aufzusetzen. Dieser ist sofort für ein potenzielles Applikations-Deployment nutzbar – egal, ob die Anwendungen nativ auf Windows oder Linux setzen. Mit dem Einsatz des Vagrant-Multi-Machine-Setup ist alles sogar lokal auf den Entwickler-PCs vollständig nachvollziehbar und nutzbar. So sind die Skripte, die später auf die Stages inklusive Produktion Anwendung finden, auch lokal nutzbar. Der Bruch zwischen lokaler Entwicklung und Staging/Produktion verschwindet damit nahezu vollständig.
Jonas Hecht
führte die Überzeugung, dass Softwarearchitektur und Hands-on-Entwicklung zusammengehören, zu codecentric. Tiefgreifende Erfahrungen in allen Bereichen der Softwareentwicklung großer Unternehmen treffen bei ihm auf eine Leidenschaft für neue Technologien.
(bbo)
