Machine Learning mit Apache Spark 2

Apache Spark bietet ausgereifte Werkzeuge für das Umsetzen von Software im Bereich maschinelles Lernen. Ein Beispielprojekt zeigt Bilderkennung für handgeschriebene Ziffern.
Die Vernetzung der Welt und mit ihr die Komplexität nehmen stetig zu. Der Bedarf, gute Entscheidungen schneller zu treffen, führt zu mehr Automatisierung. Intelligente Software erobert den Alltag mit Methoden des maschinellen Lernens. Sie reicht von einfachen statistischen Verfahren bis hin zu komplexen neuronalen Netzen, die aufwendig trainiert werden.
Ungeahnte Leistung
Menschliches Denken bringt erstaunliche Leistungen hervor, die den "Nutzern" nicht bewusst sind. Das stellt Daniel Kahneman in seinem Buch "Schnelles Denken, langsames Denken" auf lesenswerte Weise vor [1]. Die Softwareentwicklung hat sich viele Jahre schwer getan, ansatzweise intelligente Systeme zu erstellen, und sich dabei auf die Automatisierung von Routineaufgaben beschränkt. Komplexe Tätigkeiten wie das Bewerten von Informationen und das Treffen von Entscheidungen blieben bisher die Domäne der Menschen. Das scheint sich aktuell zu ändern.
Die Kosten für Rechenleistung und Speicherplatz sinken, und spezielle Hardware wie GPUs beschleunigen das verteilte Rechnen. Big Data liefert die technischen Grundlagen für das Verarbeiten riesiger Datenmengen, und Frameworks wie Apache Spark bieten einen standardisierten, einfachen Einstieg in die Umsetzung lernender Algorithmen.
Maschinelles Lernen hat das Ziel, Methoden zu liefern, die durch Training aus Daten Modelle ableiten, die danach für neue Eingaben Vorhersagen treffen ("predictive computing"). Die wirklichen Zusammenhänge, die im Modell stecken, bleiben meist im Detail unbekannt oder schwer nachvollziehbar. Am Ende zählt nur, dass es funktioniert.
Folgende Liste zeigt eine kleine Auswahl möglicher Einsatzbereiche:
- Das Aufkommen elektronischer Zahlungen wächst rasant. Es wird wichtig, Nutzungsmuster automatisch zu analysieren, um Betrugsversuche zu verhindern (Fraud Detection).
- Mit Assistenten wie Google Now, Siri und Alexa hält die Spracherkennung (Speech Recognition) Einzug ins tägliche Leben.
- Bilder oder Teile automatisch zu erkennen (Image Recognition), ist eine Basisfunktion vieler Bereiche. Autonomes Fahren ist ohne diese Grundlage kaum möglich.
- Unternehmen sind an der Meinung ihrer Kunden interessiert: Algorithmen sichten massenweise Bewertungen oder Kurznachrichten und erkennen frühzeitig Trends (Sentiment Analysis) und leiten Aktionen ein.
- Unter dem Schlagwort "Industrie 4.0" erobert die Informatik erneut die Produktion in allen Branchen. Zusätzlich zur Automatisierung der Abläufe analysiert Software massenhaft Sensoren, um früh auf Defekte oder Abnutzung zu reagieren.
Maschinelles Lernen im Unternehmensumfeld
Nach der ersten Idee zu einem Projekt teilt sich die Umsetzung meist in zwei Phasen: Aus der großen Menge an Verfahren ist die passende Variante zu wählen. Manche erfordern für das Training klassifizierte (gelabelte) Daten: Jeder Datensatz muss das gewünschte Resultat enthalten. Somit steckt oft viel Aufwand im Beschaffen und Aufbereiten qualitativ hochwertiger Trainings- und Testdaten.
Die meisten Verfahren erfordern umfangreiche Konfigurationen. Gute Ergebnisse erreichen Forscher oft nur durch Experimente mit unterschiedlichen Einstellungen. Nach dem Training ist das Ergebnis ein Modell, in dem Wissen über die Zusammenhänge der vorgelegten Daten steckt. Die Qualität sollte ein Lauf mit separaten Testdaten prüfen, die nicht Teil des Trainings sind. Liefert das Modell auch dafür gute Ergebnisse, kann es in die zweite Phase übergehen.
Jetzt trifft das trainierte Modell Vorhersagen auf neuen, echten Produktionsdaten. Die Ergebnisse sind anschließend Grundlage für weitere Geschäftsprozesse. Die folgende Abbildung zeigt die zwei Prozesse mit beiden Phasen:

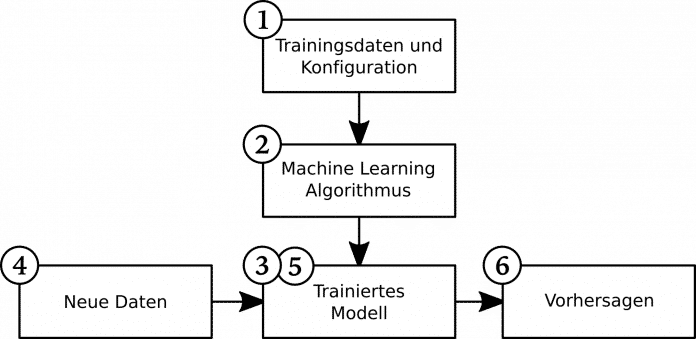
Allein das Training kann bei komplexen Modellen und großen Datenmengen lange dauern – Stunden oder Tage sind keine Ausnahme. Dagegen ist das Anwenden meist weniger zeitaufwendig.
Maschinelles Lernen mit Apache Spark 2
Spark hat in den letzten Monaten deutlich an Popularität gewonnen, und das Entwickler-Team veröffentlicht regelmäßig neue Funktionen. Derzeit ist die zweite Hauptversion verfügbar, über die heise Developer ausführlich berichtet hat (BEITRAG 1869067). Spark 2.1 enthält ein Beispiel zur "linearen Regression", das aus Datenpunkten einen Trend ableitet. Man kann dieses Beispiel als "Hello World" des Machine Learning ansehen.
Das umfangreiche Machine-Learning-Paket spark.ml bietet einen einfachen Einstieg in das Thema mit vielen vordefinierten Algorithmen und mächtige Transformatoren für das Aufbereiten der Daten. Über das Pipeline-Konzept lassen sich einzelne Schritte als Abläufe konfigurieren, optimieren und speichern. Trainierte Modelle lassen sich zwischen Entwicklung und Produktion und sogar zwischen den von Spark unterstützten Sprachen (Scala, Java, Python und R) austauschen.
Da Spark auf Scala basiert, nutzen die meisten Beispiele diese JVM-Sprache. Mit Java 8 und Lambdas ist die Spark API mittlerweile elegant einsetzbar. Der Overhead anonymer Klassen entfällt inzwischen.
Das für den Artikel verwendete Beispiel soll handgeschriebene Ziffern erkennen. Letztlich handelt es sich um eine Klassifizierung. Um es einfach zu halten, ist es ein eigenständiges Programm – die Konfiguration der Spark-Bibliotheken erfolgt mit Maven. Der Quellcode ist ebenso auf GitHub [1] zu finden wie die Trainingsdaten und die Log-Ausgaben zu allen Beispielen.
Der MNIST [2]-Datensatz des National Institute of Standards and Technology umfasst 60.000 Trainings- und 10.000 Testbilder. Jedes der 28 mal 28 Punkte großen Bilder zeigt eine Ziffer (0 bis 9) in Graustufen (Werte 0 bis 255). Die Daten liegen im CSV-Format im Verzeichnis "Resources". Über die MNIST-Projektseite finden sich zusätzliche Dateiformate. Das Feld label in der ersten Spalte dokumentiert die korrekte Ziffer. In den folgenden 784 Spalten liegen die Daten für die Bildpunkte:
label,p0,p1,...p783
7,0,0,...,0,84,185,159,151,60,36,0,0,..,0
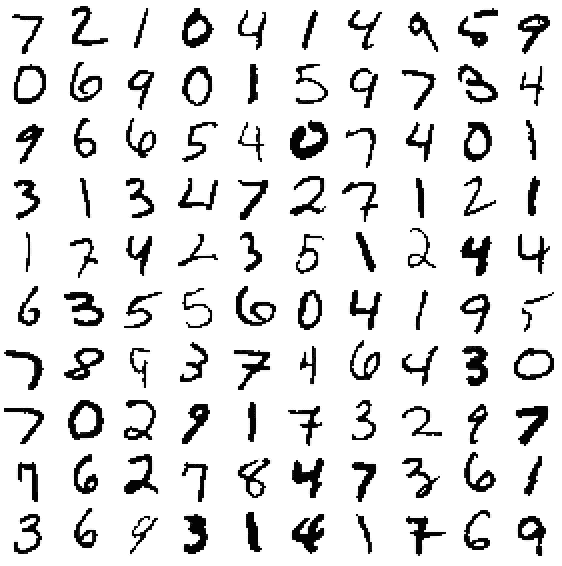
Grundsätzlich implementiert das Beispiel folgende Schritte:
- Einlesen der Daten
- Vorbereiten der Daten: Zerlegen in Label und Feature-Vektor
- Konfigurieren des ML-Algorithmus
- Trainieren des Modells
- Prüfen des Modells mit Testdaten
- Auswertung
Entscheidungsbäume
Klassifizieren mit Entscheidungsbäumen
Entscheidungsbäume (Decision Trees) sind geordnete, gerichtete Bäume [3]. Jeder Knoten steht für eine logische Regel und jedes Blatt für eine Entscheidung. Das erste Beispiel soll die Aufgabe mit einem DecisionTreeClassifier von Spark lösen.
Die ersten Zeilen des Programms erzeugen eine Spark-Instanz, die auf dem lokalen Rechner mit drei Threads laufen soll ("local[3]"). Mit der Methode master() ließe sich alternativ die URL zu einem Spark-Cluster übergeben, das die Ausführung übernimmt:
SparkSession spark = SparkSession
.builder()
.appName("JavaMNISTDT")
.master("local[3]")
.getOrCreate();
Die folgenden Befehle konfigurieren einen Reader, der die CSV-Daten mit den Test- und Traingsdaten liest:
DataFrameReader reader = spark.read()
.option("header", "true")
.option("delimiter", ",")
.option("inferSchema", true)
.format("com.databricks.spark.csv");
Dataset<Row> test = reader
.load(Const.BASE_DIR_DATASETS+"mnist_test2.csv")
.filter(e -> Math.random() > 0.00 );
Dataset<Row> train = reader
.load(Const.BASE_DIR_DATASETS+"mnist_train2.csv")
.filter(e -> Math.random() > 0.00 );
Der filter-Befehl selektiert aus dem gesamten Datenbestand eine zufällige Stichprobe, damit Experimente schneller ablaufen können. Der Wert 0.0 wählt alle Zeilen aus. Während der Entwicklung sind folgende Befehle zum Prüfen der Struktur und der eingelesen Daten hilfreich:
train.showSchema(); // Logs the schema.
train.show(2); // Logs first 2 data rows.
Leider versteht der DecisionTreeClassifier die vorliegenden Daten nicht direkt. Er erwartet eine Spalte mit dem Label und eine Spalte mit einem FeatureVector. Das benötigte Zusammenführen der Bildpunkte lässt sich von Hand erledigen, aber genau für solche Aufgaben bietet Spark eine Reihe von Transformatoren und andere Hilfsklassen an. Der VectorAssembler führt die Werte mehrerer Spalten in einem Vektor zusammen. Zuerst kopiert das Programm die Namen der relevanten Spalten (p0 bis p783) aus dem Schema in ein Feld. Der Assembler übernimmt das Feld und den Namen der aggregierten Zielspalte (features):
StructType schema = train.schema();
String[] inputFeatures = Arrays.copyOfRange(schema.fieldNames(), 1,
schema.fieldNames().length);
VectorAssembler assembler = new VectorAssembler()
.setInputCols( inputFeatures )
.setOutputCol("features");
Meist liegen die Klassennamen (Labels) nicht als numerische Werte vor, sondern könnten fachliche Bezeichnungen sein. Um die Informationen für den Algorithmus zu nutzen, hilft der StringIndexer, der aus allen Werten einen numerischen Index aufbaut. Die Eingabe besteht aus der zu indizierenden Spalte label und der Zielspalte IndexedLabel:
StringIndexerModel stringIndexer = new StringIndexer()
.setInputCol("label")
.setHandleInvalid("skip")
.setOutputCol("indexedLabel")
.fit(train);
Der StringIndexer untersucht alle Werte der Spalte vor dem Trainingslauf durch Aufruf der Methode fit().
Classifier benötigt die Spalten mit den numerischen Labels und den FeatureVector. Optional lässt sich die Tiefe des erzeugten Baums begrenzen – maximal sind 30 Ebenen erlaubt. In der Praxis bieten sich Werte zwischen 10 und 15 an. Die Ergebnisse der Klassifikation landen in der Spalte prediction:
DecisionTreeClassifier dt = new DecisionTreeClassifier()
.setMaxDepth(28).setSeed(12345L)
.setLabelCol(stringIndexer.getOutputCol())
.setFeaturesCol(assembler.getOutputCol());
Die Ergebnisse in prediction entsprechen der numerischen Darstellung. Ein IndexToString-Transformer wandelt auf die fachlichen Bezeichnungen und legt diese in der Spalte predictionLabel ab. Die Zuordnung steuert der StringIndexer bei.
IndexToString indexToString = new IndexToString()
.setInputCol("prediction")
.setOutputCol("predictedLabel")
.setLabels(stringIndexer.labels());
Eine Pipeline fasst die einzelnen Schritte als Ablauf zusammen:
Pipeline pipeline = new Pipeline()
.setStages(new PipelineStage[] {
assembler
, stringIndexer
, dt
, indexToString
});
Die Methode fit() startet das Training und erstellt ein Modell für die komplette Pipeline. Das Modell liefert mit der Methode transform(test) auf den unbekannten Testbestand ein neues Dataset inklusive der Vorhersage:
PipelineModel model = pipeline.fit(train);
// Use the model to evaluate the test set.
Dataset<Row> result = model.transform(test);
Eine Zeile genügt, um die Erkennungsrate zu ermitteln. Der Befehl filter wählt die Zeilen, bei denen Label und Vorhersage übereinstimmen:
String correct = "Correct:"+
(100.0 * result.filter("label = predictedLabel")
.count() / result.count());
Die Rate ist mit 88 Prozent akzeptabel. Das gesamte Training und der Test dauern keine zwei Minuten auf dem Rechner des Autors, einem MacBook Pro 2013 mit Intel i5.
Spark bietet eine Debug-Ansicht, um Entscheidungsbäume zu visualisieren. Entwickler müssen das Modell lediglich aus der Pipeline entnehmen:
String showTree = ((DecisionTreeModel)model.stages()[2])
.toDebugString();
Für das gewählte Beispiel ist der erstellte Baum mit 27 Ebenen leider zu unübersichtlich.
Ein Wald voller Bäume
Eine Erweiterung der Entscheidungsbäume sind Random Forests [4], die nicht nur einen Baum generieren, sondern einen ganzen Wald. Jeder Baum trägt mit einem Faktor zur endgültigen Entscheidung bei. Die einheitliche API erleichtert das Austauschen. Der RandomForestClassifier erhält die Anzahl der zu erzeugenden Bäume und ersetzt den alten Algorithmus in der Pipeline:
RandomForestClassifier rf = new RandomForestClassifier()
.setNumTrees(30)
.setLabelCol("indexedLabel")
.setFeaturesCol(assembler.getOutputCol());
Pipeline pipeline = new Pipeline()
.setStages(new PipelineStage[] {
assembler
, stringIndexer
, rf
, indexToString
});
Einen ganzen Wald zu erstellen, zahlt sich aus. Zwar verdoppelt sich die Trainingszeit auf vier Minuten, dafür steigt die Erkennungsrate auf gute 96,3 Prozent.
Eine Kreuztabelle stellt die erkannten Ziffern (Zeilen) den erwünschten Antworten (Spalten) gegenüber. Die erste Zeile und die erste Spalte zeigen das jeweilige Label. Die Diagonale hoher Zahlen zeigt viele korrekt erkannte Ziffern.
|
Label |
0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 0 | 968 | 1 | 3 | 4 | 1 | 3 | ||||
| 1 | 1122 | 4 | 3 | 1 | 4 | 1 | ||||
| 2 | 8 | 998 | 5 | 4 | 1 | 3 | 7 | 4 | 2 | |
| 3 | 8 | 974 | 7 | 1 | 9 | 5 | 6 | |||
| 4 | 1 | 1 | 3 | 1 | 940 | 6 | 1 | 8 | 21 | |
| 5 | 3 | 3 | 17 | 3 | 840 | 5 | 5 | 12 | 4 | |
| 6 | 9 | 3 | 3 | 1 | 5 | 7 | 926 | 4 | ||
| 7 | 1 | 5 | 20 | 2 | 1 | 984 | 1 | 14 | ||
| 8 | 2 | 7 | 12 | 5 | 4 | 4 | 4 | 926 | 10 | |
| 9 | 7 | 5 | 4 | 11 | 14 | 4 | 1 | 4 | 6 | 953 |
Neuronale Netze & Fazit
Klassifizieren mit Neuronen
Neuronale Netze sind die Stars des maschinellen Lernens und erleben nach einem Hype in den 1990er-Jahren ihren zweiten Frühling. Biologische Nervenzellen lieferten bereits in den 1960ern die Grundidee für das mathematische Modell. Eine detaillierte Einführung findet sich auf den Seiten zu Deep Learning [5] bei der Stanford University.
Zeitgemäße Hardware erlaubt das Training immer größerer Netze. Zusätzlich haben Forscher in den letzten Jahren neue Netzstrukturen für Spezialaufgaben erforscht. Einen schönen Überblick liefert der "Neuronal Netzwerk Zoo" des Asimov-Instituts [6].
Spark bietet einen Multilayer Perceptron Classifier (MLPC), der ein Feedforward Artificial Neural Network (FANN) erzeugt, bei dem sich jedes Neuron mit allen Neuronen der davor liegenden Schicht verbindet. Das Verfahren nutzt Back Propagation als Lernmethode, die die Abweichungen zwischen Ergebnis der Ausgabeneuronen und der Erwartungswerte ermittelt. Die Differenzen definieren die Stärke der Veränderungen an den Gewichten zwischen den Neuronen. Die Details finden sich in der Spark-Dokumentation [7].
Der Klassifizierer erwartet als Parameter die Struktur des Netzes. Das Beispiel nutzt vier Ebenen: In der ersten entsprechen die 784 Neuronen dem Eingabevektor. Es folgen zwei versteckte Schichten mit 800 und 100 Neuronen. Die Ausgabeschicht enthält 10 Neuronen für die gesuchten Klassen:
int[] layers = { 784, 800, 100, 10 };
MultilayerPerceptronClassifier mlpc = new MultilayerPerceptronClassifier()
.setLabelCol(stringIndexer.getOutputCol())
.setFeaturesCol(assembler.getOutputCol())
.setLayers(layers);
Nach dem Start fällt die deutlich längere Laufzeit von 33 Minuten auf. Das Ergebnisse verbessert sich leicht auf 96,7 Prozent.
Ansätze zur Optimierung
Um den Prozess zu verbessern, können Entwickler den Kontrast erhöhen. Aus dem Spark-Fundus bietet sich hierfür der Binarizer an, der die Pixel an dem Grenzwert 127,5 scharf in schwarze oder weiße Punkte trennt. Für die Pipeline ergibt sich ein neuer Schritt zwischen VectorAssembler und Classifier. Die Eingabespalte des Classifier ist damit die Ausgabe des Binarizer:
Binarizer binarizer = new Binarizer()
.setInputCol("features")
.setOutputCol("bin_features")
.setThreshold(127.5);
MultilayerPerceptronClassifier mlpc =
new MultilayerPerceptronClassifier()
.setLabelCol(stringIndexer.getOutputCol())
.setFeaturesCol(binarizer.getOutputCol())
.setLayers(layers);
Pipeline pipeline = new Pipeline()
.setStages(new PipelineStage[] {assembler
, stringIndexer
, binarizer
, mlpc
, indexToString
});
Der Einsatz des Binarizer verbessert die Erkennung leider nicht (96,5 %). Er reduziert dafür die Trainingsdauer erheblich um 20 Prozent (6 Minuten). Erst eine eine geschicktere Wahl der Werte für die Anzahl der Iteration und der Toleranz erhöht die Erkennungsleistung: Eine geringe Toleranz führt zu exakten Ergebnissen zum Preis von mehr Iterationen im Training. Die maximale Anzahl der Iterationen begrenzt die Laufzeit des Trainings:
MultilayerPerceptronClassifier mlpc =
new MultilayerPerceptronClassifier()
.setLabelCol(stringIndexer.getOutputCol())
.setFeaturesCol(binarizer.getOutputCol())
.setLayers(layers)
.setMaxIter(1000) //default 100
.setTol(1e-7); //default 1e-6
Die neuen Einstellungen verbessern die Erkennung auf 97,8 Prozent mit dem Preis, dass die Rechenzeit auf über eine Stunde steigt:
| Label | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 0 | 970 | 1 | 3 | 2 | 2 | 1 | 1 | |||
| 1 | 1128 | 1 | 1 | 1 | 3 | 1 | ||||
| 2 | 5 | 1 | 1003 | 6 | 2 | 1 | 3 | 6 | 5 | |
| 3 | 4 | 987 | 7 | 1 | 4 | 3 | 4 | |||
| 4 | 1 | 2 | 958 | 5 | 4 | 12 | ||||
| 5 | 3 | 1 | 6 | 3 | 869 | 2 | 1 | 4 | 3 | |
| 6 | 4 | 3 | 3 | 7 | 4 | 936 | 1 | |||
| 7 | 3 | 6 | 3 | 1 | 1009 | 6 | ||||
| 8 | 2 | 1 | 3 | 6 | 4 | 4 | 1 | 4 | 945 | 4 |
| 9 | 3 | 4 | 10 | 3 | 3 | 6 | 5 | 975 |
Eine höhere Anzahl von Schichten und von Neuronen je Schicht könnten die Leistung weiter steigern. Manche Veröffentlichungen zu der Aufgabenstellung schlagen vor, die Trainingsdaten um leicht gedrehte Bilder zu erweitern. Das lässt sich mit Spark als Affine-Transformationen realisieren.
Ausblick und Fazit
Maschinelles Lernen hat das Potenzial zu einem bestimmenden Trend der nächsten Jahre zu werden. Der Bedarf ist vorhanden, und die Techniken sind bereit für den professionellen Einsatz.
Die größten Herausforderungen eines Projekts im Bereich maschinelles Lernen liegen im Beschaffen und Aufbereiten von Trainingsdaten sowie der Wahl eines Algorithmus für eine konkrete Aufgabenstellung. Leider ist die Wirkung von Parametern im Detail oft nur dürftig dokumentiert. Manchmal hilft ein Blick in den Quellcode, oft bleibt nur eigenes Experimentieren.
Etwas Hilfestellung gibt ein sogenanntes Cheatsheet [8] von Microsoft, das einige Algorithmen und ihre typischen Einsatzmöglichkeiten aufzeigt.
Werkzeuge wie Apache Spark erleichtern den Einstieg – die Vielfalt der vorhanden Algorithmen und Hilfsklassen ist beeindruckend. Das Pipeline-Konzept überzeugt bei der Umsetzung wiederverwendbaren Abläufe und Modelle im produktiven Einsatz. Das Verteilen von Berechnungen auf einem Cluster erlaubt das Erstellen komplexer Modelle.
Heiko Spindler
ist freiberuflicher Softwarearchitekt, Entwickler und Scrum Master. Er ist Dozent, schreibt Artikel und spricht regelmäßig auf Fachkonferenzen. 2014 erschien sein Buch "Single-Page-Web-Apps" im Franzis Verlag.
Literatur:
[1] Kahneman, Daniel; Schnelles Denken, langsames Denken; Penguin Verlag 2016 (rme [9])
URL dieses Artikels:
https://www.heise.de/-3657735
Links in diesem Artikel:
[1] https://github.com/brainbrix/spark-tests
[2] https://en.wikipedia.org/wiki/MNIST_database
[3] https://de.wikipedia.org/wiki/Entscheidungsbaum
[4] https://de.wikipedia.org/wiki/Random_Forest
[5] http://ufldl.stanford.edu/tutorial/supervised/MultiLayerNeuralNetworks/
[6] http://www.asimovinstitute.org/neural-network-zoo/
[7] https://spark.apache.org/docs/2.1.0/ml-classification-regression.html#multilayer-perceptron-classifier
[8] https://docs.microsoft.com/en-us/azure/machine-learning/machine-learning-algorithm-cheat-sheet
[9] mailto:rme@ix.de
Copyright © 2017 Heise Medien