

Mehr Qualität und Geschwindigkeit bei DevOps
Viele Unternehmen folgen penibel bestimmten Anleitungen, um Entwicklung, Test und Deployment von Software aktuellen Anforderungen anzupassen. Doch das führt nur bedingt zu höherer Qualität und Geschwindigkeit, da individuelle Optimierungen fehlen. Zeit für eine neue Ausbaustufe von DevOps.
- Andreas Grabner
Ob sie es nun DevOps oder anders nennen: Viele Unternehmen folgen penibel bestimmten Anleitungen, um Entwicklung, Test und Deployment von Software aktuellen Anforderungen anzupassen. Doch das führt nur bedingt zu höherer Qualität und Geschwindigkeit, da individuelle Optimierungen fehlen. Zeit für eine neue Ausbaustufe von DevOps.
Branchengrößen wie Facebook, Flickr, Twitter oder Amazon gelten als Wegweiser für DevOps. Doch deren Vorgehen dürfen andere Unternehmen nicht einfach nachahmen, denn sie besitzen eine andere Organisation, Firmenkultur oder Softwareausstattung. Stattdessen sollten sie bei der Planung von DevOps-Prozessen mit dem wichtigsten Ziel beginnen, der schnelleren Auslieferung von Software, ohne dabei die Qualität zu gefährden. Das müssen die Entwicklungs-, Test- und Betriebsteams gemeinsam verinnerlichen. Tools können sie dabei unterstützen, die Aufgaben entlang der Prozesskette effizienter zu automatisieren.
Initial war DevOps ein gutes Mittel, um die Beteiligten auf die Notwendigkeit für Veränderungen hinzuweisen, die aus der schlanken Produktionsweise seit den 1980er-Jahren resultierte. Doch nun erfordern neue Trends wie "Your App is Your Brand", Internet der Dinge und Industrie 4.0 die nächste Evolutionsstufe von DevOps, da sich durch DevOps 1.0 zwar im Durchschnitt die Lieferzeit von Software verkürzt hat – es aber nun vermehrt zu Qualitätsproblemen kommt, die Nutzer direkt spüren – etwa dass Dienste wie Facebook down sind – oder in den Nachrichten lesen – etwa United streicht Tausende Flüge nach Softwareupdate.
DevOps 2.0 verlangt von jedem Techniker, sein Wissen und Können auf verantwortliche Weise für das Endprodukt einzusetzen. Sogenannte War Rooms, in die sich das Team und verschiedene Experten einige Tage zurückziehen, um Lösungsszenarien auszuarbeiten, müssen dabei eine Ausnahme bleiben. Das lässt sich durch einen Fokus auf Qualität über den gesamten Softwarelebenszyklus erreichen: angefangen bei den Anforderungen, dann in der Entwicklung und beim Testen sowie schließlich in der Live-Stellung und im Betrieb – und das möglichst automatisiert.
Und tschüss, War Room!
Das Ausbessern von Fehlern in der Produktivphase ist eine teure Angelegenheit. In einem typischen War Room sitzen viele Führungskräfte und Experten tagelang in einem Zimmer und analysieren Log-Files. Diese Zeit geht für das Entwickeln neuer Funktionen verloren. Stattdessen investieren die Involvierten alleine in den USA etwa 60 Milliarden Dollar jährlich für das Beheben der Probleme von gestern (Quelle: NIST).
Entsprechend sollten Unternehmen ihre bislang womöglich monolithischen Architekturen durch Continuous-Delivery-Prozesse ersetzen. Eine Weiterentwicklung des Qualitätsansatzes durch DevOps-Metriken ist nötig, um Probleme so früh wie möglich in der Entwicklungsphase zu identifizieren. Das wird im Englischen häufig als "Shift Left" bezeichnet, also die Erweiterung des Qualitätsansatzes nach links in der Zeitleiste.
Eine Welt ganz ohne War Rooms wird es zwar nicht geben, aber sie lassen sich in vielen Fällen vermeiden. Basierend auf praktischen Erfahrungswerten aus der Problemursachenforschung von hunderten Kunden lässt sich sagen, dass 80 Prozent der Fehler im Produktionsbetrieb von lediglich 20 Prozent der Fehlermuster verursacht werden. Dazu zählen zum Beispiel ein falsch gewähltes Framework, ineffizienter Datenbankzugang, zu großzügige Speicherzuweisungen, CPU-Spitzen verursachende Algorithmen, ungeeignete Synchronisierung gemeinsam genutzter Ressourcen oder ewiges Loggen.
Um diese Probleme frühzeitig zu identifizieren, sind passende Architekturmetriken zu ermitteln. Das beginnt beim Starten der Entwicklermaschine, noch bevor der Code eingegeben wird, und seiner Automatisierung in Continuous Integration durch Unit- und Integration-Tests. Eine Architekturmetrik für die Webentwicklung bildet zum Beispiel die Anzahl der Ressourcen auf einer Seite, wie Bilder, JavaScript oder CSS. Ein Entwickler sollte in den Browser integrierte Diagnose-Tools nutzen, um zu gewährleisten, dass die Seite nicht durch zu viele Elemente überladen wird. Die gleiche Metrik lässt sich mit einem Selenium-Test bei der Continuous Integration verifizieren.
Beispiele
Beispiel: Anzahl der SQL Statements
Das Prinzip soll anhand eines Beispiels erläutert werden. Anwendungen sind häufig ineffizient beim Zugriff auf eine Datenbank. Das liegt meist an einer hohen Anzahl an SQL-Aufrufen, die zu viele Daten auf ineffiziente Weise anfordern. In einem Fall wurden folgende Werte in einer produktiven Umgebung gemessen:
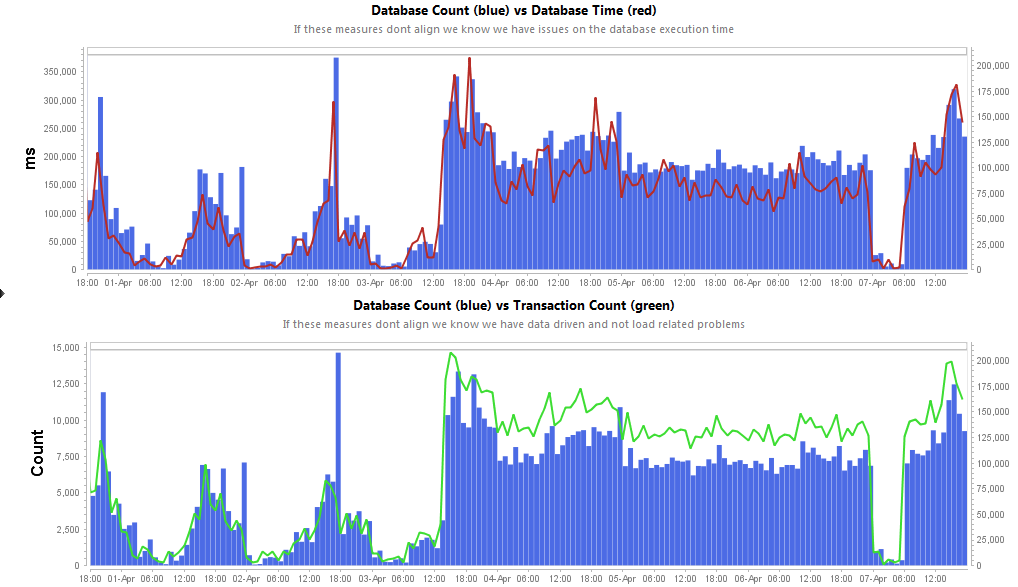
Das Verhalten änderte sich nach dem Aufspielen einer neuen Softwareversion. Diese verursachte einen Performanceabfall und überladene Datenbankserver. Es stellte sich heraus, dass das Entwickler-Team die Nutzung ihres O/R-Mapping-Frameworks Hibernate verändert hatte. Eine schlechte Konfiguration führte dazu, dass Hibernate viel mehr SQL-Abfragen ausführte als zuvor, um das gleiche Ergebnis zu erhalten.
Das Problem hätte sich bereits an der Workstation des Entwicklers identifizieren lassen, falls er die Anzahl der ausgeführten SQL Statements nach der Konfigurationsänderung untersucht hätte. Hibernate bietet wie viele andere Frameworks integrierte Logging- und Diagnose-Tools, um genau solche Fehler zu entdecken. Das ist in der folgenden Abbildung zu erkennen:

Beispiel: Architekturmetriken in Tests
Die meisten Tester entwickeln hervorragende funktionale Tests, unabhängig vom verwendeten Automatisierungs-Tool. Doch eine "Shift Left"-Mentalität bedeutet, dass Tester auch die technischen Architekturmetriken prüfen sollten. Die agilen Teams können sie dabei unterstützen, automatisch die Anzahl der SQL Statements für jeden durchgeführten Test zu sammeln. Damit müssen sie das nicht mehr manuell vor dem Einpflegen des Codes erledigen. Anschließend erhalten sie sofort die Ergebnisse, wie die folgende Abbildung vereinfacht anhand der Anzahl der SQL Statements zeigt.
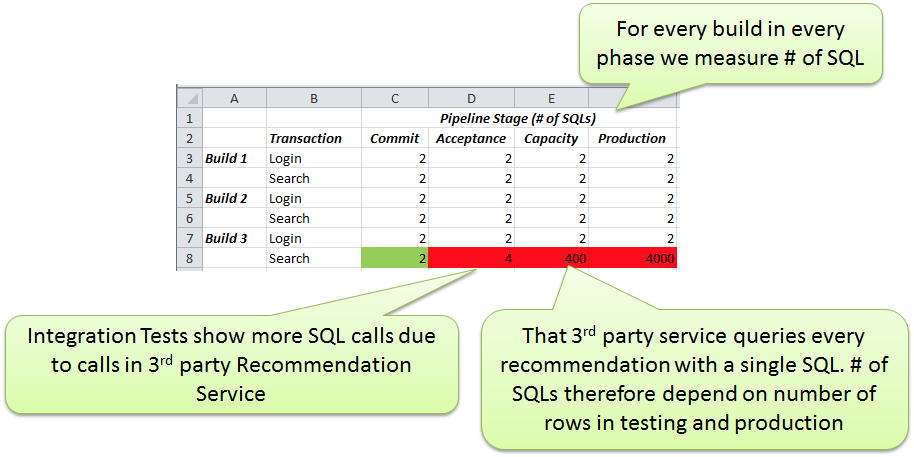
Falls eine Abweichung wie in der letzten Zeile geschieht, ist der Build sofort zu stoppen. Diese Untersuchungen sind besonders hilfreich, wenn sie in einer Testumgebung durchgeführt werden, die mehr Testdaten in der Datenbank enthält, als die Entwickler in ihrem lokalen System besitzen. Schließlich gibt es viele andere Metriken, die entlang der Entwicklungskette zu berücksichtigen sind. Für Webentwickler sind das Web-Performance-Metriken wie die Anzahl an Bildern und CSS- oder JavaScript-Dateien. Für Architekten serviceorientierter Anwendungen ist es wichtig, wie die Dienste miteinander kommunizieren, wie viele Daten pro Service-Call übertragen werden und wie viele Ressourcen das bindet. Diese Werte sind so früh wie möglich und weiterhin während des gesamten Entwicklungsprozesses bis hin zum Live-System zu sammeln.
5 Schritte
Schritt 1: Die richtigen Fragen stellen
War-Room-Szenarien lassen sich durch das Einführen solcher DevOps-Prinzipien deutlich reduzieren – mit den richtigen Tools, die Problemursachen detailliert anzeigen. Denn herkömmliche Infrastrukturüberwachungsdaten, Log-Files oder Nutzerbeschwerden weisen zwar auf die Symptome, jedoch nicht die Ursachen eines Fehlers hin. Was ist aber für den Nachweis der Ursache wichtig? Um das zu ermitteln, können folgende Fragen helfen:
- Beschwert sich ein einzelner Nutzer oder sind alle Anwender von dem Problem betroffen?
- Gibt es einen Fehler in der Lieferkette einer Anwendung, zum Beispiel bei CDNs, Drittanbietern, ISPs, Cloud-Providern, Hosted Services oder mobilen Netzwerken?
- Ist eine geschäftskritische Transaktion betroffen?
- Liegt das Problem in der Applikation, an schlechtem Code, an der virtuellen Maschine, an der Infrastruktur oder am App-Server?
Mit den Antworten auf diese Fragen lassen sich die wirklichen Problemursachen schnell identifizieren, deren Behebung priorisieren und eine Antwort darauf finden. Statt eines War Room mit 20 Personen sind dann oft nur drei Mitarbeiter nötig – ein Entwickler, ein Tester und ein Betriebsexperte –, um die detaillierten Performanceinformationen auszuwerten und bei Bedarf externe Experten einzubinden.
Schritt 2: Die Fähigkeiten erweitern
Wenn die DevOps-Praktiken nicht miteinander abgestimmt sind, besitzen Entwicklung, Test und Betrieb verschiedene Sichten, und ihre Performance wird anhand unterschiedlicher Metriken gemessen: Entwickler erstellen neue Funktionen und vervollständigen so viele Punkte wie möglich. Tester entdecken Fehler und schicken die Software an die Entwickler zurück. Der Betrieb konzentriert sich auf die Stabilität und möchte daher am liebsten laufende Systeme nicht ändern.
Um eine reibungslose Zusammenarbeit zu ermöglichen, sind die Grenzen zwischen den Abteilungen zu überwinden. Sie sollten stattdessen ein Team mit einem gemeinsamen Ziel bilden. Dabei muss das Rad nicht neu erfunden werden. Ein konstanter Zyklus aus Programmieren, Testen und Verbessern ist weiterhin beizubehalten. Doch statt dass Tester zehn Fehler am Tag finden und einfach zurückschicken, sollten sie die Entwickler über häufige Fehler informieren, damit sie diese von Anfang an vermeiden. Anschließend können sich die Tester auf wichtigere Aufgaben wie Akzeptanztests und hochskalierte Performance-Tests konzentrieren – und die Entwickler auf die Gestaltung innovativer Funktionen und Oberflächen.
Daher sollten die Fähigkeiten der drei Expertenteams verbessert werden. Sie müssen die jeweiligen Herausforderungen der anderen Bereiche verstehen. DevOps eignet sich ideal für eine optimierte Zusammenarbeit, die Einigung auf gemeinsame Tool-Sets und einheitliche Metriken.
Application-Performance-Monitoring-Tools (APM) – die Weiterentwicklung reiner System-Monitoring-Werkzeuge durch die Integration umfassender Überwachung der Qualität in der gesamten Anwendungslieferkette – ermöglichen es, dass jeder die gleiche Sprache spricht. Sie können eine einheitliche, automatisierte Performanceansicht bieten, die individuell für die Rolle und die Anforderungen jedes Team-Mitglieds eingestellt ist. Wenn etwas schief läuft, kann das funktionsübergreifende Team das gemeinsam korrigieren, ohne einen War Room einzuberufen.
Schritt 3: Die Prioritäten festlegen
Manches Mal tauchen Hunderte von Problemmeldungen auf. Die IT-Abteilung hat aber nicht die Zeit, sie alle einzeln zu durchforsten. User-Experience- und APM-Tools können bei der Priorisierung der Probleme helfen, indem sie die Datenmengen aller Nutzer über die gesamte Anwendungslieferkette aggregieren. Sie bieten eine Analyse der Auswirkungen mit der Option, tiefer in die technischen Problemursachen hineinzugehen. Sie sorgen außerdem für einen Überblick durch die Identifizierung von Problemmustern im gesamten produktiven System.
APM-Tools sollen des Weiteren bei der Priorisierung von Verbesserungen für eine höhere Kundenzufriedenheit unterstützen, unter anderem durch die Beantwortung folgender Fragen:
- Folgen die Nutzer dem Pfad, der für die Anwendung vorgesehen ist?
- Nutzen sie alle Funktionen?
Diese Tools machen das Nutzerverhalten transparent, heben Möglichkeiten für die Verbesserung des Nutzungsflusses hervor und entfernen überflüssigen Code, damit nicht auch noch Arbeit in ohnehin nicht genutzte Funktionen gesteckt wird.
Durch die Kombination der Daten mit Erkenntnissen aus dem Business, welche Transaktionen, Anwendungen und Nutzergruppen geschäftskritisch sind, kann sich das IT-Team auf die wichtigen Punkte konzentrieren. Das sind die Probleme, die Unternehmen am meisten kosten – in Sachen Vertrieb, Markenwert und Nutzerzufriedenheit.
Schritt 4: Den Anwendungsbereich erweitern
Continuous Delivery bringt zahlreiche Vorteile, doch manchmal bleiben die Unternehmen bei der Einführung auf halbem Wege stehen. Die Kosten für das Beheben von Fehlern in der Produktivphase können bis zu 150-mal höher sein als im frühen Entwicklungszyklus. Das hat eine Studie des bekannten US-amerikanischen Softwarespezialisten Barry Boehm ergeben. Um eine echte und umfassende Continuous Delivery zu erreichen, ist daher der Anwendungsbereich über den gesamten Entwicklungslebenszyklus zu erweitern.
Unternehmen können neuen Code schneller installieren, ohne schneller Fehler zu erzeugen, indem sie eine einheitliche Version der Performancedaten aus Entwicklung, Test und Produktion verwenden. Damit reduzieren sie ungeplante Tätigkeiten und technische Lücken. Entsprechend können sich die IT-Mitarbeiter wieder vermehrt auf die Entwicklung neuer Funktionen und Oberflächen konzentrieren. Dadurch lässt sich eine enorme Geschwindigkeit in der Bereitstellung neuer Funktionen erreichen. Zum Beispiel führt Amazon nach eigenen Angaben etwa alle 10 Sekunden ein neues Deployment durch. Dabei erzeugt nur 0,001 Prozent der Neuinstallationen ein Problem. Im Vergleich zu 2006 verzeichnete das Unternehmen 2012 um 75 Prozent weniger Ausfälle und um 90 Prozent weniger Ausfallminuten.
Schritt 5: So viel wie möglich automatisieren
Inzwischen stehen so viele Daten zur Verfügung, dass Unternehmen sie möglicherweise nicht mehr alle verarbeiten können. Das Gute am Application Performance Management ist aber, dass nicht jeder Nutzer das Wissen und die Zeit benötigt, um alle Vorgänge genau zu verstehen. Sind einmal die Prioritäten gemeinsam mit den Fachabteilungen festgelegt, die wichtigsten technischen Metriken identifiziert und die Key Performance Indicators (KPIs) gesetzt, lässt sich die Überwachung der Performance weitgehend automatisieren.
Selbst in der Prozesskette lassen sich viele Schritte automatisieren. Zum Beispiel können nach einem Lasttest ohne weiteres Zutun Change Requests direkt an die Entwickler gesandt werden. Während eines Integrationstests ist ebenfalls der automatische Versand von Fehlermeldungen an die Entwickler möglich. Zudem warnen Alarmmeldungen bei Überschreiten der Toleranzgrenzen für KPIs oder SLAs.
Unternehmen können damit eine kontinuierliche Qualität in ihre Continuous-Delivery-Prozesse einbauen. Dazu werden auf Metriken basierende Qualitäts-Gateways in jede Stufe der Prozesskette integriert, insbesondere zwischen Unit-, Acceptance- und Performance-Testing. Der Ansatz verstärkt das Sicherheitsnetz und unterstützt das Team beim Umgang mit sich verändernden Anforderungen. Denn die Mitarbeiter können sofort erkennen, ob sie eine neue Funktion mit der nötigen Qualität ausliefern. Zudem entdecken sie Fehler früher.
Fazit
Mithilfe dieser Best Practices können Unternehmen ihren DevOps-Ansatz weiterentwickeln und auf eine nächste Ausbaustufe von DevOps bringen. Zuerst sollten sie die richtigen Fragen stellen, um die Problemursachen festzustellen. Anschließend sind die Fähigkeiten der IT-Experten zu erweitern, damit sie die jeweiligen Herausforderungen der anderen Bereiche verstehen und bei der Problemlösung an einem Strang ziehen. Eine klare Festlegung der Prioritäten dient zur Trennung von wichtigen und unwichtigen Problemen und führt zu effizienteren Anwendungen. Die Einführung von Continuous Delivery darf dabei nicht auf halbem Wege stehen bleiben.
Performance Monitoring hat über den gesamten Entwicklungslebenszyklus, von den Workstations der Entwickler an, eine kontinuierliche Qualität zu gewährleisten. Zu guter Letzt sorgt eine weitgehende Automatisierung dafür, dass Fehler schnell entdeckt werden und eine hohe Qualität gewährleistet ist. Mit diesen Schritten gehören War Rooms weitgehend der Vergangenheit an, und das Unternehmen gewährleistet neben einer Continuous Delivery auch eine Continuous Quality.
Andreas Grabner
hat mehr als 15 Jahre Berufserfahrung als Architekt und Entwickler im Java- und .NET-Umfeld. In seiner derzeitigen Funktion als Technology Strategist bei Dynatrace leitet er das APM-Center of Excellence-Team.
(ane)
