OpenMP 4.5: Eine kompakte Übersicht zu den Neuerungen
OpenMP 4.5 ist der nächste Schritt in der Entwicklung von OpenMP, dem Standard für die Shared-Memory-Programmierung. Die neue Version stärkt vor allem die Programmierung von Beschleunigern mit dem Ziel, zu OpenACC aufzuschließen, bringt aber auch einige allgemeine neue Funktionen.


OpenMP 4.5 ist der nächste Schritt in der Entwicklung von OpenMP, dem Standard für die Shared-Memory-Programmierung. Die neue Version stärkt vor allem die Programmierung von Beschleunigern mit dem Ziel, zu OpenACC aufzuschließen, bringt aber auch einige allgemeine neue Funktionen.
OpenMP 4.0 erschien im Juli 2013 [1] und brachte als größte Neuerung Konstrukte für die Programmierung von Beschleunigern und Coprozessoren. Deren rasante Verbreitung vor allem im Hochleistungsrechnen hat dem OpenMP Language Committee keine Pause gegönnt, verlocken diese Geräte doch mit mehr Rechenleistung bei geringerem Energieverbrauch im Vergleich zu herkömmlichen Prozessoren. Dafür fordern sie aber auch eine spezielle Programmierung ihrer Mikroarchitektur und Berücksichtigung eines getrennten Speichers.
Sowohl auf diesen Geräten als auch auf herkömmlichen Multicore-Prozessoren muss somit immer mehr darum gekämpft werden, Parallelität auszudrücken, um deren Leistung auszunutzen. Um all das zu unterstützen, bringt OpenMP 4.5 eine Reihe neuer Funktionen und Verbesserungen für parallele Programmierung.
Schleifen verteilen leicht gemacht
Parallele Schleifen sind ein, wenn nicht das wichtigste Konstrukt in OpenMP. Mit den Worksharing-Konstrukten for für C/C++ und do für Fortran bietet OpenMP einen denkbar einfachen Weg, eine Schleife in Stücke zu hacken und die einzelnen Teile von den OpenMP-Threads bearbeiten zu lassen. Dennoch gibt es ein paar nervige Einschränkungen, die das Programmieren paralleler Schleifen verkomplizieren. Die vielleicht gravierendste ist, dass Worksharing-Konstrukte nicht in anderen derselben Art enthalten sein dürfen. Man kann also keine parallele Schleife innerhalb einer anderen einbauen, ohne zusätzliche parallele Regionen samt neuen Teams von Threads zu erzeugen.
Das neue Konstrukt taskloop schafft hier Abhilfe, indem es OpenMP-Tasks zur Ausführung nutzt und damit einige dieser Einschränkungen aufhebt.
Als kleiner Einschub sei an dieser Stelle erwähnt, dass OpenMP einen Task als Einheit von Code nebst Datenumgebung versteht. Wird ein task-Konstrukt erreicht, lässt sich der Task entweder direkt ausführen oder aber in eine Warteschlange einreihen und später abarbeiten. Dazu gesellen sich dann noch passende Synchronisationskonstrukte zur Steuerung der Reihenfolge in der Abarbeitung.
Der folgende Code zeigt ein Beispiel, wie sich normale Tasks und eine parallele Schleife mittels des taskloop-Kontruktes verschränkt lassen:
#pragma omp taskgroup
{
#pragma omp task
long_running_task() // kann nebenher ablaufen
#pragma omp taskloop collapse(2) grainsize(500) nogroup
for (int i = 0; i < N; i++)
for (int j = 0; j < M; j++)
loop_body();
}
Der Funktionsaufruf long_running_task() ist ein asynchron gestarteter Task, der sich somit nebenläufig zu der darauf folgenden Schleife ausführen lässt. Die Schachtelbarkeit von Tasks erlaubt es weiterhin, dass in der Funktion loop_body() erneut Tasks erzeugt werden, insbesondere auch mit dem taskloop-Konstrukt. Die collapse-Klausel, die ebenfalls beim for/do-Konstrukt verfügbar ist, instruiert den Compiler, die beiden nachfolgenden Schleifen zu einer zusammenzufassen. Die OpenMP-Implementierung ist für das Verteilen von Tasks auf die Threads zuständig und kann so für Lastverteilung sorgen, falls die Bearbeitung unterschiedlicher Aufgaben unterschiedlich lange dauern. Im Beispiel kann also der Thread, der für die Task-Ausführung des Funktionsaufrufs long_running_task() zuständig war, nach dem Abschluss an der Abarbeitung der Tasks der Schleife teilhaben.
Wie bei OpenMP üblich unterstützt das taskloop-Konstrukt die gewohnten Mittel, die Sichtbarkeit von Daten zu definieren. Das wird in OpenMP Scoping genannt, also das explizite Aufführen von Variablen in den Klauseln shared, private, firstprivate oder lastprivate. Weiterhin versteht das Konstrukt die Klausel nogroup, welche die implizit vorhandene taskgroup um das Konstrukt abschaltet und somit die automatische Synchronisation mit den erzeugten Tasks vermeidet. Die Größe dieser Tasks (Anzahl Iterationen) lässt sich mittels grainsize einstellen. Wer lieber die Anzahl der zu startenden Tasks kontrollieren möchte, kann die num_tasks-Klausel verwenden.
Soll mehr Einfluss auf das Abarbeiten der Tasks genommen werden, wird die mit OpenMP 4.5 neue priority-Klausel interessant: Je höher der angegebene Wert ist, desto höher die Priorität eines Tasks. Dieser Hinweis dient als Empfehlung an die OpenMP-Laufzeitumgebung, Tasks auszuwählen und deren Bearbeitung vorzuziehen, falls zu einem Zeitpunkt mehrere Tasks zur Ausführung bereitstehen. Eine Garantie, aus der Angabe von Prioritäten eine exakte Ausführungsreihenfolge abzuleiten, gibt es aber nicht. Ohne Angabe der Klausel haben alle Tasks die Priorität 0, sie sind also gleichwertig.
Locking
Ausgesperrt
Gegenseitiger Ausschluss, gemeinhin als Locking bezeichnet, ist in der parallelen Programmierung ein notwendiges Übel. Sperrobjekte ("Locks") sind häufig einzusetzen, um Konflikte beim nebenläufigen Zugriff auf gemeinsam genutzte Datenstrukturen oder Ressourcen zu vermeiden. Diesen Schutz erkauft man sich durch weniger Parallelität aufgrund der Tatsache, dass ein Thread warten muss, bis ein anderer die Sperre aufgehoben und den kritischen Abschnitt verlassen hat. Das ist insbesondere dann ärgerlich, wenn die Sperre nur zur Sicherheit gesetzt werden muss, die Wahrscheinlichkeit eines Zugriffskonflikts aber gering ist.
Das folgende Beispiel zeigt eine einfache (und ineffiziente) Implementierung der Methoden zum Einfügen und Suchen von Paaren in einer hash_map.
template<class K, class V>
struct hash_map {
hash_map() {
omp_init_lock(&lock);
}
~hash_map() {
omp_destroy_lock(&lock);
}
V& find(const K& key) const {
V* ret = 0;
omp_set_lock(lock);
ret = internal_find(key);
omp_unset_lock(lock);
return *ret;
}
void insert(const K& key, const V& value) {
omp_set_lock(lock);
internal_insert(key, value);
omp_unset_lock(lock);
}
//...
private:
mutable omp_lock_t lock;
hash_buckets *buckets;
// ...
};
Das verkürzte Beispiel (keine Fehlerbehandlung usw.) zeigt sofort eine Schwäche der Implementierung auf. Die Sperre wird gleich beim Eintritt in den Methoden angefordert, was dazu führt, dass jeweils nur ein Thread auf die Datenstruktur zugreifen kann. Da Hash-Datenstrukturen jedoch explizit dafür gedacht sind, Zugriffskonflikte aufzulösen, entsteht hier ein unnötiger Engpass: Es könnten sehr wohl mehrere Threads auf die Datenstruktur zugreifen, solange sie nicht auf denselben Hash-Bucket oder sogar auf denselben Eintrag zugreifen oder ihn verändern. Typischerweise geht jetzt die Optimierungsarbeit los, und die Sperren werden vom offensichtlichen Ort in die Tiefen der Implementierung verschoben. Manche versuchen sich gar an einer Lock-freien Implementierung.
OpenMP 4.5 kann hier etwas Erleichterung schaffen, indem Programmierer die neue API für Sperren nutzen. Diese wurde um zwei Funktionen (omp_init_lock_with_hint und omp_init_nest_lock_with_hint) erweitert, die ein zusätzliches Argument vom Typ omp_lock_hint_t erwarten (siehe auch folgende Tabelle).
| Typ | Bedeutung |
| omp_lock_hint_none | Kein Typ gewünscht, OpenMP-Implementierung kann Typ der Sperre frei wählen. |
| omp_lock_hint_uncontended | Die Sperre erzeugt wenige Konflikte. |
| omp_lock_hint_contended | Die Sperre erzeugt viele Konflikte durch konkurrierende Threads. |
| omp_lock_hint_nonspeculative | Sperre soll nicht spekulativ ausgeführt werden; zu viel Konfliktpotenzial durch Überlappung des Working-Sets der Threads. |
| omp_lock_hint_speculative | Optimistisches Sperren; Konfliktpotenzial im Working-Set ist gering. |
Mit dieser API ist es möglich, dass sich für jede einzelne Sperre spezifizieren lässt, auf welche Art die Sperre implementiert werden soll. Im folgenden Beispiel nutzen die Autoren das, um der OpenMP-Implementierung mitzuteilen, dass die Sperre für die hash_map spekulativ ausgeführt werden soll (omp_lock_hint_speculative).
template<class K, class V>
struct hash_map {
hash_map() {
omp_init_lock_with_hint(&lock,
omp_lock_hint_speculative);
}
~hash_map() {
omp_destroy_lock(&lock);
}
V& find(const K& key) const {
V* ret = 0;
omp_set_lock(lock);
ret = internal_find(key);
omp_unset_lock(lock);
return *ret;
}
void insert(const K& key, const V& value) {
omp_set_lock(lock);
internal_insert(key, value);
omp_unset_lock(lock);
}
//...
private:
mutable omp_lock_t lock;
hash_buckets *buckets;
// ...
};
Auf einem Prozessor mit Intel Transactional Synchronization Extensions führt das dazu, dass die Hardware die Sperre zunächst ignoriert und nur bei einem Konflikt zwischen zwei Threads die betroffenen Rechenkerne zurücksetzt. Darauf wiederholen die Kerne die Ausführung mit vollständigem gegenseitigem Ausschluss.
Beschleuniger
Mehr Komfort mit Beschleunigern
In OpenMP 4.0 wurde das Gerätemodell vom Host mit den traditionellen OpenMP-Threads um das Vorhandensein eines oder mehrerer Beschleuniger erweitert, die derzeit alle vom selben Typ sein müssen. Das target-Konstrukt überträgt die Ausführung vom Host zum entsprechenden Gerät (siehe Abb.), im Folgenden häufig Beschleuniger genannt. Der Code, der auf dem Beschleuniger ausgeführt wird, wird auch als Kernel bezeichnet und umfasst in der Regel einen rechenintensiven Bereich der Anwendung. Dabei ist es möglich, über die map-Klausel Variablen mitsamt ihren Werten mitzunehmen beziehungsweise auf dem Gerät Speicher für den Kernel zu reservieren.
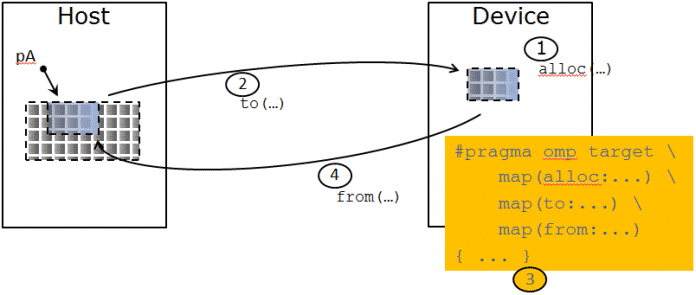
OpenMP 4.0 brachte sogenannte Datenregionen, wie sie OpenACC besitzt, in denen Daten auf dem Beschleuniger auch über mehrere Kernel-Aufrufe hinweg erhalten bleiben, und zwar für die gesamte Lebensdauer der Region. Ein Beispiel ist im folgenden Codebeispiel gezeigt, in dem sich die Datenregion von Zeile 3 bis zum Ende erstreckt.
double var1[N];
#pragma omp target data map(tofrom:var1[:N])
{
class C *c = new C();
#pragma omp target
c.kernel1(); // verwendet var1 und Member von C
#pragma omp target
c.kernel2(); // verwendet var1 und Member von C
delete c;
}
Eine wesentliche Beschränkung dieses Ansatzes ist allerdings, dass sich die Dauer einer Datenregion durch den strukturierten Block ergibt, der dem Pragma nachfolgt. Das erlaubt zwar das Umfassen mehrerer Kernelaufrufe wie hier in einfach strukturiertem Code, ermöglicht es aber nicht, in einer Datenregion weitere Variablen auf den Beschleuniger zu mappen oder aber an weiteren Stellen im Code Vorkehrungen zum Mappen von Daten zu treffen. Ein Beispiel hierfür wäre das Mappen von Daten im Konstruktor der Klasse C.
Dieses oftmals benötigte Feature bringt OpenMP 4.5 in Form der beiden neuen target data-Konstrukte, wie im Folgenden gezeigt. Beide stehen im Code für sich selbst. Das target enter data-Konstrukt führt dabei ein Mapping vom Host zum Gerät durch, target exit data entfernt dieses Mapping entsprechend wieder mit der Option, die Daten zum Host zu kopieren.
/* Variablen in var-list werden zum Beschleuniger gemappt */
#pragma omp target enter data map(map-type: var-list) [clauses]
/* Variablen in var-list werden vom Beschleuniger gemappt */
#pragma omp target exit data map(map-type: var-list) [clauses]
Um nun die Motivation für die neue Funktion noch einmal aufzugreifen, zeigt das nächste Beispiel, wie sich im Konstruktor der Klasse C Daten auf ein Gerät im Rahmen einer bestehenden Datenregion mappen lassen.
class C {
public:
C() {
#pragma omp target enter data map(alloc:values[M])
}
~C() {
#pragma omp target exit data map(delete:values[M])
}
private:
double *values;
};
Hierbei wird das Array values auf dem Beschleuniger angelegt. Das target enter data-Konstrukt erzeugt dabei eine sogenannte unstrukturierte Datenregion. Im Destruktor der Klasse C lässt sich entsprechend mit einem target exit data-Konstrukt und dem map-Typ delete das Feld abräumen.
Eine weitere Neuerung im Kontext der Datenverwaltung zwischen Host und Geräten ist die Unterstützung vom Transfer strukturierter Daten. Bisher war es lediglich möglich, einfache skalare Variablen und Felder oder eine Instanz eines strukturierten Datentyps als Ganzes via bitweisem Kopieren zu mappen. OpenMP 4.5 unterstützt nun auch das Mappen einzelner Datentypteile, wobei sich diese Funktion wiederum mit den Mitteln zum Ausdruck von Teilen von Arrays kombinieren lässt. Der folgende Code zeigt ein paar Beispiele der nun vorhandenen Möglichkeiten, womit zu hoffen ist, dass diese den Transfer komplizierter Datenstrukturen bei der Programmierung von Beschleunigern deutlich vereinfachen.
struct A {
int field;
double array [N];
} a;
#pragma omp target map(a.field)
#pragma omp target map(a.array[23:42])
Um das Thema Mapping von Daten abzuschließen, sei noch erwähnt, dass nun skalare Variablen in Bezug auf Datenregionen wie "firstprivate" behandelt werden: Sind sie vor einer Datenregion im lokalen Scope deklariert, werden sie genau dann auf das Gerät gemappt, wenn sie in der entsprechende Region referenziert werden. Werden sie nicht referenziert, werden sie auch nicht gemappt – in OpenMP 4.0 bestand der unnötige Zwang für eine Implementierung, alle Variablen zu mappen. Wer das neue Verhalten aber nicht mag, der kann die neue Klausel defaultmap(tofrom:scalar) verwenden, sodass die skalaren Variablen wieder alle wie gehabt gemappt werden.
Eine weitere wesentliche Neuerung im Bereich der Beschleunigerprogrammierung ist das asynchrone Offloading. Bisher war es so, dass ein target-Konstrukt den Offload initiierte, also den Wechsel des Kontrollflusses vom Host hin zum Gerät. Damit war aber der ausführende Thread auf dem Host so lange blockiert, bis der Kernel auf dem Gerät abgeschlossen war.
Im Sinne der Integration in den Rest von OpenMP wurde kein neues Konstrukt eingeführt, um Asynchronität zu ermöglichen, sondern das target-Konstrukt hat ein Upgrade erhalten und ist nun per definitionem ein Task-Konstrukt.
Damit das Verhalten bestehender Programme nicht verändert wird, ist ein target-Konstrukt standardmäßig allerdings ein Task, dessen Ausführung nicht aufgeschoben werden darf, sondern direkt erfolgen muss. Um die Asynchronität einzuschalten, ist die Klausel nowait hinzuzufügen. Das hat zur Folge, dass der Kernel – also der Inhalt des target-Konstrukts – auf dem Beschleuniger ausgeführt wird, während auf dem Host die Ausführung direkt nach dem Ende des target-Konstrukt fortgesetzt wird. Das gilt ebenso für die oben erwähnten enter/exit target data-Konstrukte, was ein asynchrones Mappen zwischen Host und Gerät ermöglicht.
Um das Ganze sinnvoll anwenden zu können, fehlt noch die Möglichkeit, auf den Abschluss einer asynchronen Operation zu warten. Hierzu wurde auf die mit OpenMP 4.0 eingeführten Task-Abhängigkeiten zurückgegriffen. Ein einfaches Beispiel für sowohl asynchrone Datentransfers und Kernelausführung als auch den Ausdruck von Abhängigkeiten ist im Folgenden dargestellt.
double data[N];
#pragma omp target enter data map(to:data[N]) \
depend(inout:data[0]) nowait
do_something_on_the_host();
#pragma omp target depend(inout:data[0]) nowait
perform_kernel_on_device();
do_something_on_the_host();
#pragma omp target exit data map(from:data[N]) \
depend(inout:data[0])
Das target enter data-Konstrukt in Zeile 3 initiiert das Mapping von data auf das Gerät, wegen der Angabe der Klausel nowait kann das aber asynchron geschehen, sodass die Ausführung auf dem Host direkt in Zeile 5 mit der Funktion do_something_on_the_host() fortgesetzt wird. Der eigentliche Kernelaufruf erfolgt in den Zeilen 7 und 8: Auch hier wird wieder Asynchronität ermöglicht, aber die Angabe der Abhängigkeit sorgt dafür, dass der Kernel erst gestartet wird, wenn der Datentransfer abgeschlossen ist. Das Mapping des Ergebnisses enthält ebenfalls wieder eine Abhängigkeit, sodass es sich erst ausführen lässt, wenn der Kernel beendet wurde.
Um dieses Feature zu ergänzen, bringt OpenMP 4.5 eine Reihe von API-Funktionen mit, welche die Speicherverwaltung auf dem Gerät vom Host aus erlauben. Beispielsweise alloziert omp_target_alloc() einen Speicherbereich auf dem Gerät. Es gibt zusätzlich einen Zeiger dazu zurück, der sich dann als Argument entsprechende Funktionen mitgeben lässt, die schließlich einen Kernel aufrufen. Mit der omp_target_memcpy()-Funktion können beliebige Datentransfers ausgedrückt werden. Diese API-Funktionen sind insbesondere im Zusammenspiel mit Bibliotheken notwendig geworden.
Die folgende abschließende persönliche Anmerkung sei erlaubt: Die Beschleunigerprogrammierung ist bestimmt nicht leicht, nicht unbedingt für jedermann gedacht, und auch nicht in jeder Anwendung ist Asynchronität oder der Ausdruck von Abhängigkeit notwendig. OpenMP 4.5 bringt diese Werkzeuge aber mit und versucht dadurch besonders attraktiv zu sein, dass – anstelle der Einführung neuer Konstrukte – soweit wie möglich auf vorhandene zurückgegriffen wurde.
Fazit
Fazit, und auf zur nächsten Etappe: OpenMP 5.0
Die nun erschienene Version von OpenMP war einst als Nummer 4.1 geplant und angekündigt, aber mit Blick auf die vielen Neuerungen hat das OpenMP Language Committee, also das Gremium, das den Sprachstandard kontinuierlich weiterentwickelt, beschlossen, die vielen Neuerungen entsprechend mit dem Versionssprung 4.5 zu würdigen. In Bezug auf die Beschleunigerprogrammierung hat man mit OpenACC 2.0 aufgeschlossen, im Unterschied dazu aber die vollständige Integration mit der Thread- und Task-parallelen Programmierung geschafft. Diese wurde mit den weiteren vorgestellten neuen Funktionen ausgebaut.
Wichtige Ziele von OpenMP 5.0 – erwartet in zwei bis drei Jahren – sind die Integration von Schnittstellen zum Andocken von Tools, die Unterstützung von Daten- und Task-Lokalität sowie Möglichkeiten zur Arbeitsverteilung zwischen Host und Beschleuniger.
Michael Klemm
ist Teil der Intel Software and Services Group und arbeitet in der Developer Relations Division mit Fokus auf Höchstleistungsrechnen. Er wirkt im OpenMP Language Committee an unterschiedlichsten Fragestellungen mit und leitet die Projektgruppe zur Entwicklung von Fehlerbehandlungsmechanismen für OpenMP.
Christian Terboven
ist stellv. Leiter der Gruppe Hochleistungsrechnen am IT Center und Lehrstuhl HPC der RWTH Aachen. Seit 2006 arbeitet er mit im OpenMP Language Committee und ist dort Leiter der Gruppe Affinity, welche sich dem Thema Nähe von Threads, Tasks und Daten zu Rechenkernen widmet.
(ane [2])
URL dieses Artikels:
https://www.heise.de/-3020235
Links in diesem Artikel:
[1] https://www.heise.de/hintergrund/Die-wichtigsten-Neuerungen-von-OpenMP-4-0-1915844.html
[2] mailto:ane@heise.de
Copyright © 2015 Heise Medien