

Operations heute und morgen, Teil 3: Virtualisierung und Containerisierung
Der nächste logische Schritt nach "Software is eating the world" heißt Virtualisierung und Conntainerisierung. Doch sind Private Cloud und Docker die Allheilmittel für jedermann?
- Daniel Schneller
- Lukas Pustina

Der nächste logische Schritt nach "Software is eating the world" heißt Virtualisierung und Conntainerisierung. Doch sind Private Cloud und Docker die Allheilmittel für jedermann?
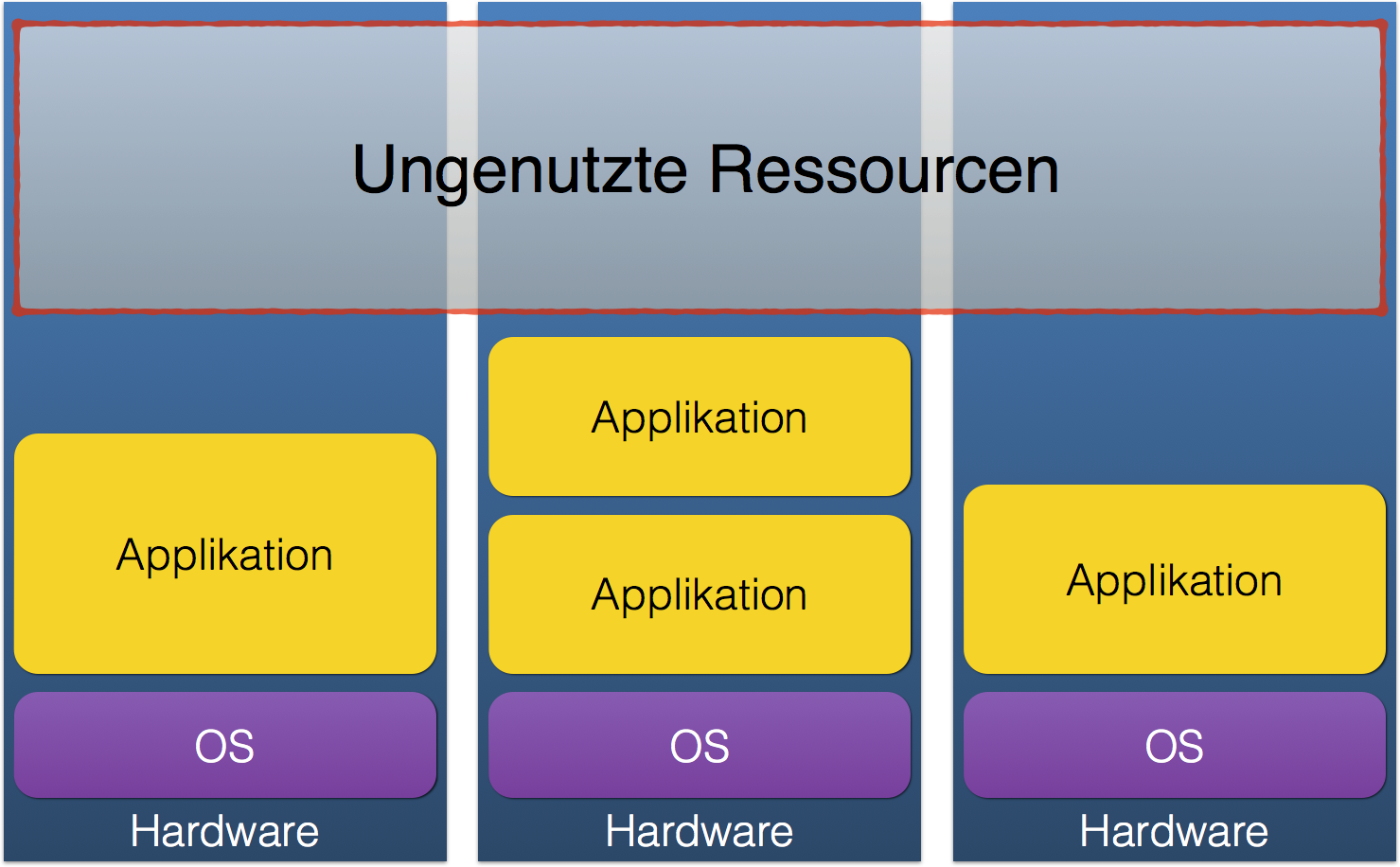
Noch nicht allzu lang ist es her, dass für beinahe jeden Dienst, den Unternehmen entweder nutzen oder selbst bereitstellen wollten, Serverhardware anzuschaffen und in Betrieb zu nehmen war, von andauernder Pflege mit regelmäßigen Betriebssystem- und Anwendungsupdates, Hardwarereparaturen und der Jagd nach Softwarebugs ganz zu schweigen. Durch notwendige fachliche Trennungen, Datenschutz, unterschiedliche Lastprofile, Risikominimierung oder schlicht Inkompatibilitäten stieg die Anzahl separater Maschinen schnell, und mit ihr der Aufwand und die Kosten für den laufenden Betrieb.
Gleichzeitig wurden die vorhandenen Ressourcen in Summe nicht effizient genutzt, da kaum eine Anwendung die ihr exklusiv bereitgestellten Rechen- und Speicherkapazitäten dauerhaft und vollständig ausnutzt und somit teuer eingekaufte Ressourcen brachliegen lässt. Aus den gleichen Gründen halten zum Beispiel Fluggesellschaften ihre Flotten so lückenlos wie möglich in Bewegung. Jedes Flugzeug, das länger als unbedingt – etwa zu Wartungszwecken – nötig am Boden steht, kostet Geld. Der Schlüssel zur effizienten Ressourcenauslastung ist die Minimierung von Leerlauf. Ein Server, der ungenutzte Kapazitäten hat, ist totes Kapital.
Warum nicht mal virtuell
Operations heute und morgen
Das Business scheint aus IT-Sicht seine Anforderungen und Wünsche nach neuen und aktualisierten Features immer schneller zu ändern. Gleichzeitig gibt es innerhalb der IT fortwährend neue Trends, die umgesetzt werden wollen. Doch wo steht der IT-Betrieb bei der Umsetzung der Anforderungen und Wünsche? Haben die Entwickler mit dem agilen Trend die Mauern zum Business eingerissen, kam in den letzten Jahren zunehmend der Wunsch nach DevOps auf. Dev steht für Development/Entwicklung und Ops für Operations/Betrieb. Damit soll auch die Mauer zwischen Entwicklung und Betrieb überwunden werden. Doch was hat sich bisher wirklich durchgesetzt? Das betrachtet die Artikelserie "Operations heute und morgen":
- Das moderne IT-Unternehmen
- DevOps im Jahre 2015
- Virtualisierung & Containerisierung
- Hochverfügbarkeit
- Big Data aus Betriebssicht
- Monitoring
Virtualisierung brachte diesbezüglich eine Verbesserung der Situation mit sich. Statt auf einem Bare-Metal-Server ein einziges Betriebssystem mit einer oder nur wenigen Anwendungen zu betreiben, erlaubte sie die bis dato durch verschiedene Server erreichte physikalische Trennung durch eine logische zu ersetzen. Mit Erweiterungen der CPU-Befehlssätze wie Intels VT-X lassen sich mehrere
Betriebssysteminstanzen mit den darin laufenden Anwendungen auf der gleichen Maschine parallel betreiben. Dadurch steigt die mittlere Auslastung der Hardware, die Anzahl physikalischer Server sinkt – und mit ihr die Kosten.
Der nächste Schritt, virtuelle statt echter Server zu kaufen, liegt damit nicht mehr fern. Unzählige Startups, ebenso wie namhafte Unternehmen, betreiben ihre komplette Infrastruktur virtualisiert. Netflix, Dropbox und iCloud – um nur einige bekannte Beispiele zu nennen – bedienen sich verschiedener Dienstleister, die ihnen virtuelle Infrastruktur als Dienstleistung anbieten (IaaS – Infrastructure as a
Service). Sie kaufen bedarfsgerecht von beispielsweise Amazon (Elastic Compute Cloud; EC2) oder Microsoft (Azure) binnen Minuten gezielt Rechen- und/oder Speicherkapazitäten ein und schalten sie ebenso schnell wieder ab. Zur Abdeckung von Lastspitzen, wie sie beispielsweise saisonbedingt oder zu bestimmten Ereignissen auftreten können, sind so nicht dauerhaft Kapazitätsreserven ungenutzt vorzuhalten.
Cloud
Geschäftsmodell: Software as a Service
Als logische Konsequenz aus der schnellen und einfachen Verfügbarkeit virtueller Hardware vollzog sich schnell der nächste Evolutionsschritt: SaaS – Software as a Service. Jede Firma hat Bedarf an mehreren der typischen Basisdiensten wie E-Mail, Wiki oder Issue Tracker, die aber nicht den Kern des Geschäfts ausmachen. Statt also eigene E-Mail-Server auf virtueller Hardware zu betreiben und damit weiterhin für große Teile des Betriebs selbst verantwortlich zu sein, bietet es sich viel eher an, einen Cloud-Dienst wie Google Apps, Confluence oder Trello als Dienstleistung einzukaufen.
Der Vorteil liegt auf der Hand: Skalierung, Wartung, Betrieb und Weiterentwicklung der Dienste obliegen dem jeweiligen Anbieter, binden keine internen Ressourcen und sind finanziell gut planbar. Das gilt selbst für die Anbieter. Sie können von Skaleneffekten profitieren – IaaS spielt auch hier eine wichtige Rolle – und ihre Dienste dadurch vergleichsweise günstig anbieten und schnell weiterentwickeln.
Die Wolke im Keller
Doch nicht in jeder Situation ist ein extern gehostetes Angebot möglich oder wünschenswert. Sei es aus rechtlichen oder politischen Gründen, Sicherheits- oder Verfügbarkeitserwägungen – auf absehbare Zeit werden über das Internet angebotene Dienste eigene Rechenzentren nicht komplett ablösen. Doch warum sollte man in solchen Fällen nicht auch "in-house" von Erfahrungen und Techniken profitieren, die Cloud-Anbieter für den Betrieb ihrer öffentlichen Plattformen einsetzen.
Ursprünglich von Rackspace für den eigenen Bedarf entwickelt und später als Open Source freigegeben, hat sich das inzwischen industrieweit unterstützte OpenStack zur De-facto-Plattform für private Clouds entwickelt.
Es besteht aus einer Reihe von Einzelprojekten, die im Halbjahrestakt unter einem wohlklingenden Release-Namen gemeinsam veröffentlicht werden und Hand in Hand zusammenspielen, um alle Facetten einer komplett virtualisierten Infrastruktur zu verwalten. Dazu gehören als wichtigste Komponenten "Nova", das sich um den Lebenszyklus virtueller Maschinen kümmert, und "Neutron", das als SDN (Software Defined Network) virtuelle Switches, Router, Gateways, DHCP Server et cetera verwaltet.
Darüber hinaus stehen mit Cinder, Glance, Ceilometer, Keystone und Horizon weitere Bausteine bereit, die Volumes und Disk-Images bereitstellen, statistische Nutzungsdaten erfassen, User und Mandanten verwalten sowie eine Self-Service-Weboberfläche liefern. Eine vollständige Liste würde den Rahmen sprengen – sie umfasst eine Menge weiterer Dienste, von der SQL-Datenbank bis hin zu Firewalls und Lastverteilern. Unterstützt wird eine Vielzahl von Hypervisor-Plattformen, darunter neben KVM und Xen auch vSphere und Hyper-V, sowie unterschiedliche Storage und Netzwerktechniken.
So ausgerüstet skaliert OpenStack von einer Handvoll Servern bis hin zu Farmen mit tausenden Maschinen. Beim Aufbau einer Private Cloud mit OpenStack lohnt es sich, von Anfang an auf Automatisierung aller Installationsschritte zu setzen. Die Menge von Komponenten mit ihren jeweiligen Konfigurationen, multipliziert mit einer schnell wachsenden Anzahl von Maschinen, führt beim Versuch manueller Installation sonst unweigerlich zu Problemen, die sich schwer debuggen lassen.
Die Anbieter der großen Linux-Distributionen bieten daher mehr oder weniger automatisierte Installationsprogramme und Supportpakete an, um die initiale Installation im eigenen Rechenzentrum zu vereinfachen und beim laufenden Betrieb zu unterstützen. Red Hat bietet – analog zu Fedora/CentOS und RHEL – eine Community-Distribution unter dem Namen "RDO" (das offiziell keine Abkürzung für irgendetwas ist) an, die die jeweils aktuellen OpenStack-Releases auf Basis der hauseigenen Linux-Distribution bündelt. Die kommerzielle Variante trägt den Namen "Red Hat Enterprise Platform for OpenStack" und wird, eine entsprechende Subskription vorausgesetzt, langfristig mit Support und Updates versorgt, enthält dafür aber nicht immer die aktuellsten Features.
Ähnliche Angebote sind die SuSE OpenStack Cloud und Ubuntu OpenStack – The Canonical Distribution, basierend auf der jeweiligen Distribution und mit verschiedenen Schwerpunkten bezüglich eingesetzter Automatisierungswerkzeuge, grafischer Tools und architektureller Vorgaben.
Doch letztlich müssen – insbesondere bei mehr als einer Handvoll Servern und in komplexeren Netzwerken – die Zusammenhänge und detaillierten Konfigurationsmöglichkeiten von den zuständigen Administratoren verstanden werden, soll eine zuverlässige Private Cloud entstehen und auf Dauer funktionieren. Inwieweit distributionsspezifische Werkzeuge und damit einhergehende Unterschiede zu "Vanilla OpenStack" helfen oder stören, sollte vor einer Entscheidung in die eine oder andere Richtung in jedem Fall gründlich evaluiert werden.
Container
Container – Wachablösung für VMs?
Das 2013 gegründete und seit letztem Jahr kaum mehr zu übersehende Docker-Projekt machte den Begriff der "Containerisierung" populär. Zwar ist Docker seit einiger Zeit nicht mehr alleiniger Spieler in diesem Feld, aber sicherlich der bekannteste. Container werden vielfach als Nachfolger oder Ablösung der Virtualisierung gefeiert. Entsprechend finden sich zahlreiche Vergleiche und Gegenüberstellungen, die suggerieren, es handle sich dabei um konkurrierende Ansätze. Doch das ist mitnichten der Fall, stehen doch der VM-basierte Plattform- und der Container-Ansatz weitgehend orthogonal zueinander.
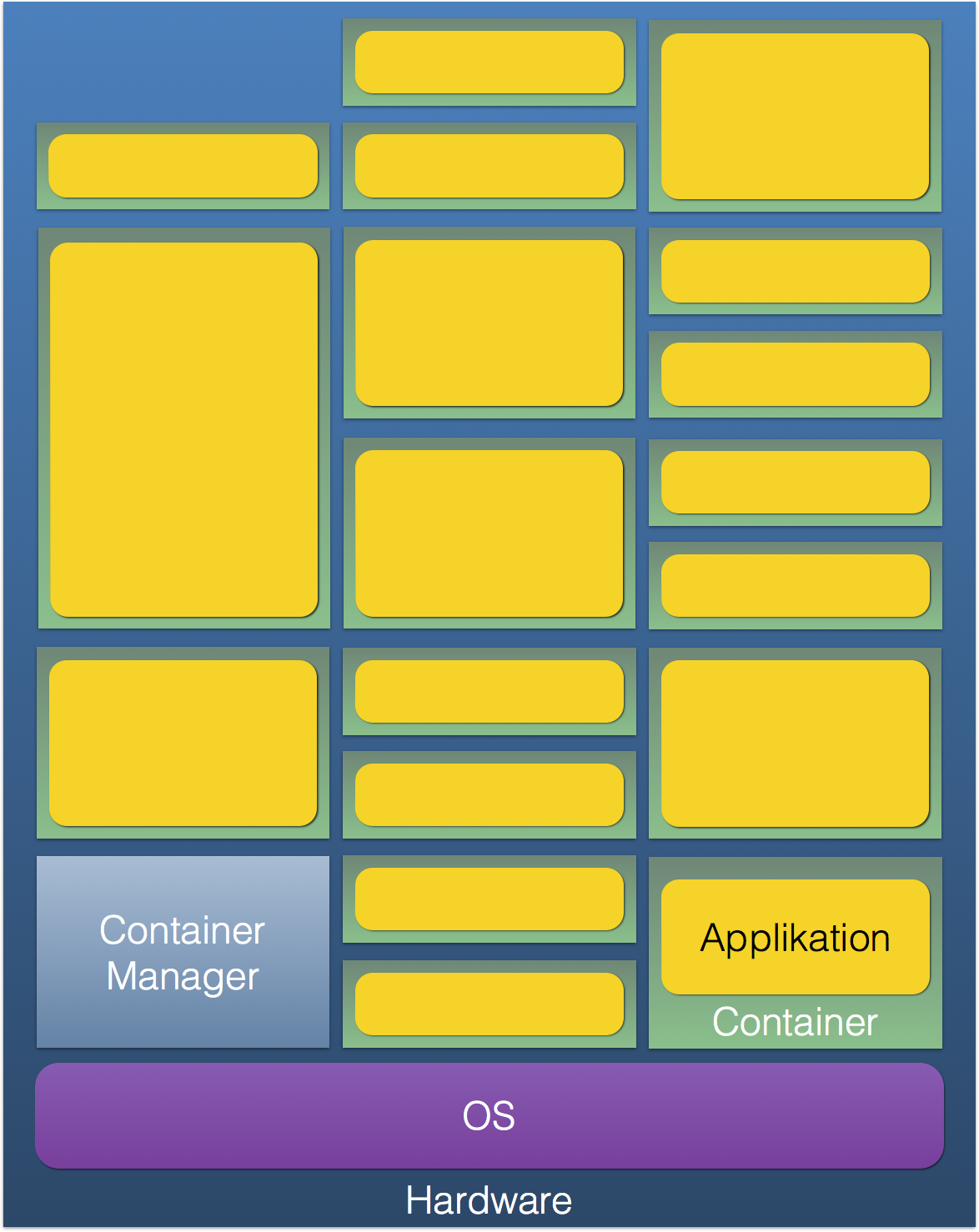
Unter einem Container versteht man eine komplette Anwendung, inklusive ihrer Abhängigkeiten und Konfiguration, verpackt in einem definierten, wiederverwendbaren Format. Im Unterschied zu einer kompletten Virtual Machine enthält ein Docker-Container jedoch kein eigenes Betriebssystem mit eigenem Kernel, Treibern et cetera. Er fällt dadurch deutlich schlanker aus. Vereinfacht gesagt ist ein Container keine virtuelle Maschine, sondern eine Art "virtualisiertes Binary". Man spricht daher auch von Anwendungsvirtualisierung.
Technisch basieren Container auf bereits länger verfügbaren Funktionen, die der Linux-Kernel zur Isolierung von Anwendungen bietet, wie Kernel Namespaces, cgroups und SELinux. Anwendungen verschiedener Container laufen dadurch als weitgehend voneinander abgeschottete reguläre Userland-Prozesse in einer einzigen gemeinsamen Linux-Umgebung. Jeder Prozess bekommt vom Kernel nur seine "eigene kleine Welt" präsentiert: Prozesshierarchie, Rechenkapazität, Netzwerk-Interfaces, Dateisystem – das steht aus Sicht der Anwendung im Container exklusiv zur Verfügung. Das vereinfacht die Konfiguration erheblich. Die Anwendung kann zum Beispiel immer darauf bauen, einen bestimmten Netzwerkport binden zu können – in ihrem Container besteht keine Gefahr, dass ein anderer Prozess diesen bereits belegt hat. Damit entfällt etwa die Notwendigkeit für entsprechende Fehlerbehandlung in der Anwendung oder für viele ansonsten notwendige Konfigurationseinstellungen.
Sollen Anwendungen zusammenarbeiten – beispielsweise Anwendungs- und Datenbankserver – können sie in ihren jeweils eigenen Containern laufen. Die Anwendung erwartet ihre Datenbank zum Beispiel immer auf localhost:3306. Im einfachsten Fall, wenn beide Container auf der gleichen Maschine laufen, sorgt der Container-Daemon durch Einrichtung entsprechender NAT-Regeln dafür, dass die Daten transparent ihren Weg zum Datenbankcontainer und zurückfinden. In komplexeren Setups können die Container auch auf unterschiedliche Hosts verteilt sein, gegebenenfalls mit zwischengeschalteten Load-Balancern und so weiter. Charmanterweise ändert sich jedoch dadurch nichts an der Konfiguration der Anwendungen innerhalb der Container.
Die Vorteile der Container liegen auf der Hand: Der verhältnismäßig große Overhead einer kompletten Virtual Machine, die ein vollständiges Betriebssystem mit eigener Speicherverwaltung, Treibern, Massenspeichern et cetera mit sich bringt, entfällt. Dadurch ist es möglich, einen Container in einem Bruchteil der Zeit zu starten und auch nur einen Bruchteil der Ressourcen zu verbrauchen, die eine VM benötigen würde.
Darüber hinaus kann ein einmal erstellter Anwendungscontainer Bit-identisch sowohl etwa auf dem lokalen Entwickler-PC laufen als auch auf dem Produktivsystem. Im ersten Fall können alle Container, die die Anwendungskomponenten enthalten, auf der gleichen Maschine nebeneinander laufen, in letzterem Fall verteilt im Cluster. Die Fehlerkategorie "bei mir lokal lief es aber" verliert damit deutlich an Schrecken. Mit Orchestrierungssystemen wie Googles Kubernetes oder Apache Mesos werden Container anhand vorgegebener Regeln (z. B. wie viele Instanzen eines bestimmten Dienstes zu jeder Zeit laufen sollen) über die verfügbare Hardware verteilt und überwacht. Damit lassen sich auch große Setups verwalten.
Nicht alles ist Gold ...
Jedoch sind Container (mal wieder) kein Allheilmittel und bringen bei allen Vorzügen auch eine Reihe wichtiger Einschränkungen mit sich. Naturgemäß bleibt die Isolierung der Container untereinander und gegenüber dem Hostsystem (noch) deutlich hinter klassischer Virtualisierung zurück. Alle Container beziehungsweise die darin enthaltenen Prozesse teilen sich den gleichen Kernel und die gleichen Systembibliotheken – was gegebenenfalls Kompatibilitätsprobleme nach sich zieht und zum Beispiel Windows zumindest derzeit noch ausklammert. Zwar gibt es bereits Docker-Client-Software für Windows, doch erst mit Windows Server 2016 steht die Unterstützung von containerisierten Windows-Anwendungen auf dem Programm.
Da es sich letztlich bei Software in Containern um reguläre Prozesse handelt, beschränkt sich der Virtualisierungs-Overhead auf ein Minimum. Das bringt so eine nahezu ungebremste Ausführungsgeschwindigkeit und die Möglichkeit, mehr Anwendungen auf der gleichen Hardware zu betreiben, als mit VMs möglich. Doch kann ein Softwarefehler oder eine Sicherheitslücke das gesamte System in Mitleidenschaft ziehen. Das ist bei Virtualisierung, die mit ihrer Hardwareunterstützung von "echter" Isolierung profitiert, nicht möglich. Eine Kernel-Panic in einer VM hat keine Auswirkung auf weitere, auch wenn sie auf der gleichen physischen Maschine gehostet sind. Passiert das Gleiche auf einem Container-Host, stürzen alle Container gleichzeitig über die Klippe.

Last, but not least gilt zu bedenken, dass die wenigsten existierenden Anwendungen sich ohne weiteres in Container stecken lassen. Auch wenn Google intern dem Vernehmen nach all seine Software in Containern verpackt und Entwickler allerorten oft allein aus Spaß am Neuen entsprechende Grundlagen schaffen, dürfte auf absehbare Zeit der Großteil existierender Software – insbesondere bereits seit Jahren laufende Individual- und Branchenanwendungen – schon aus wirtschaftlichen Gründen die nötigen Umbauarbeiten wohl kaum erfahren.
Fazit
Die Mischung macht's
Wie so oft kommt es also bei der Auswahl der richtigen Technik auf die konkreten Anforderungen an. Genau wie es weiterhin sinnvolle Szenarien für den Betrieb von Anwendungen auf "echter" Hardware gibt, können virtuelle Maschinen, Container oder eine Hybridlösung aus beiden je nach Anforderung die beste Wahl sein.
Container können ihre Stärken nur optimal ausspielen, wenn die darin laufende Software mitspielt und sich darauf versteht, dynamisch verteilt in einem Cluster betrieben zu werden. Grundlegende Themen wie persistente Daten, Logging und Monitoring von Containern müssen überdacht und teils neu entwickelt werden. Sind diese Voraussetzungen gegeben, glänzen Container durch niedrigen Overhead und leichte Portierbarkeit.
Virtuelle Maschinen bieten stärkere Isolierung, eine breitere Plattformbasis (sie sind nicht auf Linux-Anwendungen beschränkt) und stellen keine besonderen Anforderungen an die in ihnen laufende Software. Hinzu kommt, dass die Werkzeuge zum Management und zur Provisionierung allein aufgrund des zeitlichen Vorsprungs deutlich weiter entwickelt sind als solche für Container.
Container und virtuelle Maschinen werden parallel existieren. Die Verteilung der Anteile wird sich im Laufe der Zeit wahrscheinlich zugunsten der Container verschieben, doch sie als Konkurrenten zu betrachten, ergibt nur wenig Sinn und wird beiden Techniken nicht gerecht. Container und sie umgebende Techniken stellen eher eine willkommene Erweiterung der Toolchain dar, mit dem Softwareentwickler und Infrastrukturspezialisten gemeinsam – Stichwort DevOps – die Systeme von heute fit für morgen machen.
Daniel Schneller
beschäftigt sich seit über 15 Jahren mit dem Entwurf und der Umsetzung komplexer Software- und Datenbanksysteme und ist unter anderem Autor des "MySQL Admin Cookbook". Er leitet derzeit bei der CenterDevice GmbH den Bereich Mobile Development.
Dr. Lukas Pustina
hat langjährige Erfahrung in der Entwicklung und dem Betrieb von verteilten Systemen. Er hat dabei stets ein Auge auf neue Techniken in diesem Umfeld. Zurzeit arbeitet er als Leiter des Bereichs Infrastruktur bei der CenterDevice GmbH an der Realisierung einer hochskalierbaren Cloud-Software.
(ane)
