Operations heute und morgen, Teil 4: Hochverfügbarkeit
In vielen Unternehmen gehören DevOps-Prinzipien und Cloud-Infrastruktur-Komponenten mittlerweile zum Standard. Auf dem Weg zur Hochverfügbarkeit eröffnet das neue Möglichkeiten. Doch jede Medaille hat zwei Seiten.


In vielen Unternehmen gehören DevOps-Prinzipien und Cloud-Infrastruktur-Komponenten mittlerweile zum Standard. Auf dem Weg zur Hochverfügbarkeit eröffnet das neue Möglichkeiten. Doch jede Medaille hat zwei Seiten. Komplexe und vernetzte System- und Anwendungslandschaften stellen den Betrieb weiterhin vor Probleme, und Hochverfügbarkeit bleibt eine Herausforderung.
Geschäftsprozesse sind die Basis jeder Wertschöpfung. Das erfordert zum einen eine klar strukturierte und reibungslos arbeitende IT-Organisation, zum anderen, dass die benötigten technischen Systeme auf Ausfallsicherheit und Korrektheit ausgerichtet sind. Anders ausgedrückt: Hochverfügbarkeit ist ein wichtiger Erfolgsfaktor. Viele Unternehmen haben dafür unter anderem ihre IT-Organisation nach DevOps-Prinzipien aufgestellt und Cloud-Infrastrukturen eingeführt.
Definition und Struktur von Verfügbarkeit
Operations heute und morgen
Das Business scheint aus IT-Sicht seine Anforderungen und Wünsche nach neuen und aktualisierten Features immer schneller zu ändern. Gleichzeitig gibt es innerhalb der IT fortwährend neue Trends, die umgesetzt werden wollen. Doch wo steht der IT-Betrieb bei der Umsetzung der Anforderungen und Wünsche? Haben die Entwickler mit dem agilen Trend die Mauern zum Business eingerissen, kam in den letzten Jahren zunehmend der Wunsch nach DevOps auf. Dev steht für Development/Entwicklung und Ops für Operations/Betrieb. Damit soll auch die Mauer zwischen Entwicklung und Betrieb überwunden werden. Doch was hat sich bisher wirklich durchgesetzt? Das betrachtet die Artikelserie "Operations heute und morgen":
Verfügbarkeit (engl. 'availibility') bedeutet im Allgemeinen die Bereitschaft oder das Vorhandensein. Im Zusammenhang mit Prozessen und technischen Systemen fällt häufig auch der Begriff Zuverlässigkeit. Aber Obacht – Verfügbarkeit und Zuverlässigkeit sind zwei verschiedene Dinge (vgl. [2]). Zuverlässigkeit, im Engl. 'reliability', ist die Wahrscheinlichkeit, dass ein System störungsfrei, ohne Fehler über einen möglichst langen Zeitraum funktioniert. Während Verfügbarkeit den relativen Anteil des Zeitraums angibt, in dem das System seine Aufgabe beziehungsweise Funktion erfüllt, selbst wenn Fehler auftreten.
Ein Beispiel: Ein System das jede Stunde 3,6 Sekunden nicht vorhanden ist, ist mit 99,9 Prozent hochverfügbar, jedoch sehr unzuverlässig. Steht ein System dagegen für den Zeitraum von einer Woche im Jahr nicht zur Verfügung, ist es sehr zuverlässig, aber mit circa 98 Prozent nicht wirklich hochverfügbar.
Steht ein System nicht zur Verfügung, liegt ein Systemausfall oder ein Systemversagen vor, im Englischen 'failure' (Systemverhalten passt nicht zur Systemspezifikation). Ursache sind Fehler ('error'), die ein Fehlerverhalten ('fault') erzeugen. Alle drei Typen werden als Fehler übersetzt und meist auch synonym verwendet. Geht es wie in diesem Artikel um Fehler im Kontext von Hochverfügbarkeit, sind "Failures" und damit
Systemausfälle und Systemversagen gemeint. Die einschlägige Literatur (siehe z. B. [2]) unterscheidet typischerweise fünf Fehlertypen im Kontext von Verfügbarkeit:
- Crash Failure (Absturzfehler): Ein System antwortet permanent nicht mehr, hat bis zum Zeitpunkt des Ausfalls aber korrekt gearbeitet.
- Omission Failure (Auslassungsfehler): Ein System reagiert auf (einzelne) Anfragen nicht, weil es die Anfragen nicht erhält oder keine Antwort sendet.
- Timing Failure (Antwortzeitfehler): Die Antwortzeit eines Systems liegt außerhalb eines festgelegten Zeitintervalls.
- Response Failure (Antwortfehler): Die Antwort, die ein System gibt, ist falsch.
- Byzantine Failure (byzantinischer/zufälliger Fehler): Ein System gibt zu zufälligen Zeiten zufällige Antworten ("es läuft Amok").
Die meisten Personen denken bei Systemausfällen und Systemversagen vor allem an Absturzfehler. Es ist aber wichtig zu berücksichtigen, dass alle Fehlerklassen in die Verfügbarkeit einfließen. Es geht demnach nicht nur darum, die relativ einfach zu handhabenden Absturzfehler zu behandeln, sondern alle Fehlertypen, also zum Beispiel auch zu langsame oder falsche Antworten zu erkennen und damit umzugehen.
Verfügbarkeit wird üblicherweise als Größe zwischen 0 Prozent ("gar nicht verfügbar") und 100 Prozent ("voll verfügbar") ausgedrückt. Die Welt ist unvollkommen, und Fehler werden passieren, deshalb wird von Hochverfügbarkeit gesprochen, was bedeutet, den Prozentsatz möglichst nah an die Vollverfügbarkeit (100 %) zu bringen. Mit der "Anzahl der Neunen" wächst die Verfügbarkeit, zum Beispiel "3 Neunen" (0,999/9,9 %, < 7 h Downtime/Jahr), "4 Neunen" (0,9999/99,99 %, < 1 h Downtime/Jahr) oder "5 Neunen" (0,99999/99,999 %, < 6 Min. Downtime/Jahr). Verfügbarkeit wird nach Robert S. Hanmer [2] und dem BSI-Kompendium Hochverfügbarkeit [3] wie folgt berechnet:
Verfügbarkeit := MTTF / (MTTF + MTTR)
Dabei enstpricht MTTF ('mean time to failure') dem Zeitraum bis zum Ausfall beziehungsweise Fehler des Systems. MTTR ('mean time to repair') ist der Zeitraum von der Erkennung bis zur abschließenden Behebung beziehungsweise Reparatur des Fehlers. Das Ergebnis kann damit die Werte zwischen 0 für "gar nicht verfügbar" und 1 für "immer verfügbar" annehmen. Wird dieser Wert mit 100 multipliziert, erhält man die vertraute Darstellung in Prozent.
Nun gibt es zwei Möglichkeiten, die Verfügbarkeit, wie in der folgenden Abbildung anhand des Regelkreislaufs zu beeinflussen:
- Erhöhung der MTTF: die Lebensdauer erhöhen, damit der Wert für MTTR vernachlässigbar klein wird.
- Verkürzung der MTTR: den Zeitraum für die Reparatur so "klein" wie möglich machen, sodass der Wert im Verhältnis zur MTTF ebenfalls vernachlässigbar klein wird.
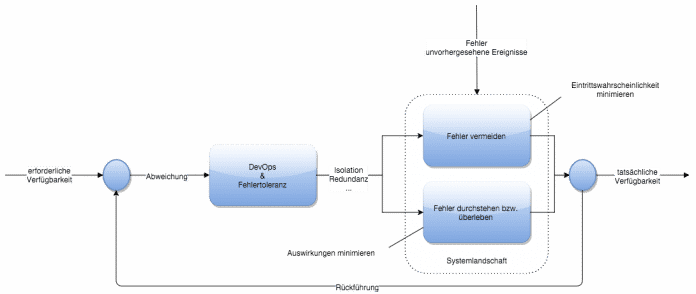
Infrastruktur, Fehlertoleranz
Fehler antizipieren und vermeiden
Folgt man dem ersten Ansatz und möchte die MTTF erhöhen, kommen dafür typischerweise redundante Infrastrukturbausteine zum Einsatz, etwa Cluster und mehrfach ausgelegte Netzwerkverbindungen. Diese Form der Redundanz adressiert in der Regel Fehlerquellen unterhalb der Anwendungsebene, primär bezogen auf das Ausfallen der Hardware- und Infrastrukturkomponenten. Es handelt sich um eine prophylaktische Maßnahme, die Eintrittswahrscheinlichkeit eines Gesamtausfalls des Systems zu minimieren, und sie beruht auf der Annahme, dass Mängel und Fehlerursachen in mehreren Infrastrukturbausteinen gleichzeitig auftreten, sehr unwahrscheinlich ist.
Der Vorteil für Entwickler ist, dass sie annehmen können, dass die Infrastruktur für ihre Anwendung nahezu 100 Prozent verfügbar ist. Mängel in der Anwendung beziehungsweise auf Anwendungsebene kompromittieren die Verfügbarkeit jedoch weiterhin. Um die dafür nötige Stabilität der Software herzustellen, sind Fehlerursachen zu antizipieren. Ist der Fehler (Störung, Irrtum etc.) einmal bekannt, lässt er sich in der Anwendung abfangen und korrigieren. Zusätzlich wird die Fehlerkonstellation, wenn möglich, mit einem Testfall geprüft, um das "falsche" Verhalten zukünftig zu vermeiden. Neben der eigentlichen Funktionserweiterung kommt es zur kontinuierlichen Verfeinerung und Verbesserung der Stabilität.
Folglich obliegt das Sicherstellen von Hochverfügbarkeit nicht mehr allein nur dem Betrieb, sondern sollte bereits in die Software eingebaut werden. Hier hilft ein iteratives und inkrementelles (agiles) Vorgehen. Ergänzt um DevOps-Prinzipien, ermöglicht die Feedbackschleife aus dem Betrieb zurück in die Entwicklung, gemeinsam zu lernen und geeignete Maßnahmen zu implementieren, um die Verfügbarkeit auszubauen. Es ist illusorisch anzunehmen, dass sich Entwickler, die – wie heute leider häufig noch üblich – vom Betrieb abgeschirmt sind und nur für die möglichst schnelle Umsetzung von Fachanforderungen belohnt werden, viele Gedanken über Verfügbarkeit machen. Vielfach ist das heute immer das alleinige Problem der Betriebsseite.
Heutige Anwendungslandschaften sind ein Netz aus Softwarebausteinen, die auf Cloud-Infrastrukturen-Komponenten ohne besondere Verfügbarkeitszusicherungen betrieben werden. Galt früher, ein "System muss verfügbar sein", heißt es nun, dass eine komplexe und hochgradig vernetzte Anwendungslandschaft verfügbar sein muss.
Wer sich mit verteilten Systemen – und nichts anderes ist eine vernetze Anwendungslandschaft aus vielen, relativ kleinen Bausteinen, die per Netzwerk miteinander kommunizieren – beschäftigt hat, weiß, dass Verfügbarkeit in verteilten Systemen eine besondere Herausforderung ist. Zum einen reduziert jeder beteiligte Baustein die Gesamtverfügbarkeit des Systems. Folglich ist die Kette so stark wie ihr schwächstes Glied, genauer aber ist die Kette schwächer als ihr schwächstes Glied (vgl. [3]). Damit die gesamte Einheit noch eine akzeptable Verfügbarkeit erreicht, sind die einzelnen Bausteine extrem verfügbar auszulegen. Zum anderen ist auch das Netzwerk selbst eine zusätzliche Quelle möglicher Ausfälle [6]. Erschwerend kommt hinzu, dass die Infrastruktur häufig über keine Hochverfügbarkeitsmechanismen verfügt.
Leslie Lamport, einer der führenden Köpfe auf dem Gebiet verteilter Systeme hat salopp, aber treffend formuliert:
"A distributed system is one in which the failure of a computer you didn't even know existed can render your own computer unusable."
Anders ausgedrückt: In einem verteilten System gibt es viele Fehlerquellen, die sein korrektes Funktionieren kompromittieren, und es ist unmöglich, alle vorherzusagen oder gar zu vermeiden. Frei nach Murphy "Alles, was schiefgehen kann, wird auch schiefgehen".
Mit dieser Tatsache vor Augen sollte man sich bewusst werden, ob Verfügbarkeit, Zuverlässigkeit oder beide gefordert sind. Zuverlässige Systeme müssen möglichst lange fehlerfrei funktionieren und erfordern Maßnahmen, die MTTF zu maximieren.
Ein gutes Beispiel sind medizinische Geräte. Ein Fehler kann tödlich enden und ist zu vermeiden. Hochverfügbarkeit ist weniger wichtig, da die Wartung auch ein paar Tage am Stück dauern darf, solange ein Ersatzgerät vorhanden ist. Für viele Anwendungen ist Hochverfügbarkeit jedoch eine essenzielle Anforderung, insbesondere wenn sie von den Endkunden oder anderen, für das Erreichen der wirtschaftlichen Unternehmensziele essenziellen Nutzergruppen verwendet wird. Ist das der Fall, hilft Maximierung der MTTF nicht weiter, da Fehler weder vorhersehbar noch vermeidbar sind. Aber wie stellt man Hochverfügbarkeit in solchen verteilten Anwendungslandschaften sicher?
Fehler tolerieren und überleben
Mit Blick auf den zweiten Ansatz bleibt noch, MTTR, also den Zeitraum von der Erkennung (Detection) bis zur abschließenden Behebung (Recovery) oder zumindest Eindämmung beziehungsweise Linderung (Mitigation) zu minimieren. Abschließend ist die Ursache des Fehlers zu beheben und über ein Update in der letzten Phase (Treatment) des Fehlerlebenszyklus zu entfernen. Somit werden Schaden und Auswirkungen verringert und minimiert.
Positiv ausgedrückt, hält das System oder der Baustein ein vorab spezifiziertes Leistungsniveau auch bei auftretenden Fehlern aufrecht. Aus der Perspektive des Nutzers merkt dieser im besten Fall überhaupt nicht, dass ein Fehler aufgetreten ist. Im schlechtesten Fall erhält der Nutzer mindestens eine reduzierte/"herabgesetzte" und definierte Serviceleistung ('graceful degradation of service'). Gar keine Reaktion sowie technische Meldungen wie "NullPointerException" oder "Service unavailable" sind für den Anwender wenig hilfreich, sondern wirken abschreckend. Das Mindeste ist eine aussagekräftige Meldung, wie es für den Anwender weitergeht, zum Beispiel: "Der Service ist aufgrund von ... aktuell nicht verfügbar, bitte versuchen Sie es in 5 Minuten noch einmal". Der Rest gehört ins Log.
Fehler sind zur Laufzeit in der Produktion zu verdecken, einzudämmen (keine weitere Auswirkungen und Ausbreitung auf die anderen Systeme) und zu beheben. Im Idealfall erfolgt diese Behandlung automatisch. Sind Anwendungen und Bausteine widerstandsfähig gegenüber Fehlern von innen und Störungen von außen, wird typischerweise von Fehlertoleranz ('fault tolerance') gesprochen.
Im Kontext der Fehlertoleranz muss man sich bewusst sein, ob es um die Stabilisierung der Datenqualität oder die Aufrechterhaltung der Prozessqualität geht. Viele technische Diskussionen erörtern vor allem, ob und wie die Konsistenz, die Verfügbarkeit oder die Partitionstoleranz der Daten sichergestellt [7] werden soll. Dem Nutzer dagegen geht es meistens darum, sein Anliegen und damit den erforderlichen Prozess erfolgreich abzuschließen, die Datenqualität spielt dabei für ihn eine untergeordnete Rolle.
Für beide Zielsetzungen gibt es Muster, die die Zeiträume der genannten Phasen der MTTR verkürzen. Als zwei grundlegende Muster für Fehlertoleranz werden im Folgenden Isolation und Redundanz als gute Ausgangspunkte für fehlertolerante Systeme vorgestellt.
Isolierung, Redundanz
Isolation oder Units of Mitigation
Eine Anwendung in kleinere Module zu zerlegen, gehört heute zum guten Ton in der Softwareentwicklung. Aus der Perspektive der Fehlertoleranz ist die Aufteilung ebenfalls eine gute Idee. Im Fehlerfall ist nur ein Teil der Anwendung kompromittiert und nicht die ganze Anwendung – vorausgesetzt, die Bausteine sind als möglichst unabhängige Einheiten entwickelt worden und gegeneinander isoliert. Diese unabhängigen Einheiten werden, je nach Quelle, Bulkheads (als Metapher aus dem Schiffsbau übernommen), Failure Units oder Units of Mitigation genannt. Die Einheiten isolieren sich up- und downstream gegen Fehler anderer Einheiten, um kaskadierende, das heißt sich über mehrere Einheiten fortpflanzende Fehler zu vermeiden.
Das Finden geeigneter Failure Units ist ein reines Design-Thema. Es gibt keine fertigen Bibliotheken, Frameworks oder Best Practices, die sich einfach anwenden ließen. Hier sind Augenmaß, Erfahrung und kontinuierliches Lernen gefragt. Hat man eine Struktur gefunden, stehen für die Implementierung eine Menge Muster und Prinzipien zur Verfügung, etwa lose Kopplung, Latenzüberwachung, Request-Limitierung oder auch die vollständige Validierung aller Aufrufparameter und Rückgabewerte (vgl. [1], [2]).
Auch sehr wichtig: Redundanz
Redundanz ist ein weiteres zentrales Muster im Kontext der Fehlertoleranz. Typischerweise werden Failure Units redundant ausgelegt. Redundanz ist geeignet, mit allen Arten von Fehlern umzugehen, nicht nur mit Absturzfehlern. Zunächst muss man sich Gedanken über das Szenario machen, dass mit Redundanz adressiert werden soll:
- Soll ein Failover implementiert werden, das heißt beim Ausfall einer Einheit (idealerweise komplett transparent) auf eine andere umgeschaltet werden?
- Oder soll die Latenz gering gehalten werden? Das bedeutet, es werden mehrere Einheiten redundant genutzt, um die Wahrscheinlichkeit einer zu langsamen Antwort zu reduzieren.
- Oder sollen Antwortfehler erkannt (in Zeiten von NoSQL keine Seltenheit), das heißt die Antworten mehrerer redundanter Einheiten ausgewertet werden, um die Wahrscheinlichkeit fehlerhafter Antworten zu reduzieren?
- Oder soll Skalierung/Lastverteilung implementiert, also eine Einheit zu zahlreichen Anfragen auf mehrere Einheiten verteilt werden?
- ...
Abhängig vom gewählten Szenario sind dann weitere Aspekte zu berücksichtigen:
- Welche Routing-Strategie passt zum gewählten Szenario, wenn Load Balancer eingesetzt werden? Reicht einfaches Round Robin oder wird eine komplexere Strategie benötigt? Und unterstützt diese der Load Balancer?
- Stellt das System einen automatischen Master-Wechsel sicher, wenn ein Master-Slave-Ansatz für Failover zum Einsatz kommt und der Master ausfällt?
- Um die Latenz gering zu halten, kann man einen "Fan out & quickest one wins"-Ansatz verwenden. Das heißt, eine Anfrage wird parallel an mehrere redundante Einheiten gesendet und die schnellste Antwort kommt zum Einsatz. Wie stellt man bei so einem Ansatz sicher, dass die Einheiten nicht von alten, nicht mehr benötigten Anfragen so belastet werden, dass sie die neuen Anfragen nicht mehr zeitnah bearbeiten können
Fazit
Heutige Systemlandschaften sind in der Regel komplex, verteilt und hochgradig vernetzt. Außerdem werden sie immer häufiger auf Cloud-artigen Infrastrukturen betrieben. Es ist nicht mehr hinreichend zu versuchen, gemäß dem traditionellen Stabilitätsansatz die Eintrittswahrscheinlichkeit von Fehlern zu minimieren. Stattdessen müssen Fehler als unvermeidbar und unvorhersehbar akzeptiert und toleriert werden. Der Kern von Fehlertoleranz ist die Isolation der einzelnen Bausteine mit dem Ziel, kaskadierende Fehler zu vermeiden. Redundanz ist ein mächtiges Muster, das einem hilft, mit allen möglichen Arten erkannter Fehler umzugehen. Wie erwähnt, gibt es jedoch weitere Muster im Kontext der Fehlertoleranz, Hochverfügbarkeit auszubauen.
Am wichtigsten sind vielleicht folgende Botschaften:
- Hochverfügbarkeit ist nicht mehr nur Aufgabe des Betriebs, sondern bereits bei der Entwicklung mit in die Anwendungen einzubauen – ein Grund mehr für DevOps, da dafür die Feedbackschleifen benötigt werden.
- Hochverfügbarkeit und Zuverlässigkeit sind verschiedene Dinge mit unterschiedlichen Zielsetzungen, und es erfordert andere Maßnahmen, entweder die MTTF zu maximieren oder die MTTR zu minimieren. Die Wahl hängt sowohl vom Einsatzgebiet der Software als auch der wirtschaftlichen Bewertung ab.
Abschließend sei noch erwähnt, das in der letzten Zeit häufig der Begriff Resilience synonym zur Fehlertoleranz genannt wird. Fehlertoleranz ist Resilience, aber Letzteres ist mehr als Fehlertoleranz. Es umfasst viele weitere Prinzipien wie Transparenz und Autonomie im Rahmen des Software-Designs, die helfen, Anwendungen robust und hochverfügbar zu gestalten.
Ansgar Fitz
ist als Senior IT Consultant bei der codecentric AG tätig. Mit den Schwerpunkten agile Softwarentwicklung und Resilience Software Design ist er immer auf der Suche nach neuen Konzepten für den IT-Betrieb.
Literatur
- Andrew Tanenbaum, Marten van Steen; Distributed Systems – Principles and Paradigms; Prentice Hall, 2nd Edition, 2006
- Robert S. Hanmer; Patterns for Fault Tolerant Software; Wiley 2007
- BSI-Kompendium Hochverfügbarkeit [8]
(ane [9])
URL dieses Artikels:
https://www.heise.de/-2840537
Links in diesem Artikel:
[1] https://www.heise.de/ratgeber/Operations-heute-und-morgen-Teil-1-Das-moderne-IT-Unternehmen-2624295.html
[2] https://www.heise.de/ratgeber/Operations-heute-und-morgen-Teil-2-DevOps-im-Jahre-2015-2700954.html
[3] https://www.heise.de/ratgeber/Operations-heute-und-morgen-Teil-3-Virtualisierung-und-Containerisierung-2762412.html
[4] https://www.heise.de/ratgeber/Operations-heute-und-morgen-Teil-4-Big-Data-aus-Betriebssicht-3074778.html
[5] https://www.heise.de/ratgeber/Operations-heute-und-morgen-Teil-5-Monitoring-3118453.html
[6] https://de.m.wikipedia.org/wiki/Fallacies_of_Distributed_Computing
[7] https://blog.codecentric.de/2011/08/grundlagen-cloud-computing-cap-theorem/
[8] https://www.bsi.bund.de/DE/Themen/weitereThemen/Hochverfuegbarkeit/HVKompendium/hvkompendium_node.html
[9] mailto:ane@heise.de
Copyright © 2015 Heise Medien