

Reactive Extensions: Renaissance eines Programmiermodells
Das Konzept des Reactive Programming ist seit geraumer Zeit in aller Munde. Microsofts Rx-Bibliothek, die für viele Plattformen und Programmiersprachen verfügbar ist, setzt das Prinzip konsequent um.

- Marko Beelmann
Reactive Programming ist eher eine Renaissance als eine Revolution, denn das Konzept ist nicht unbedingt neu. Die Entwicklung von Libraries wie Reactive Extensions https://github.com/Reactive-Extensions (Rx) oder auch die Verbreitung des Aktorenmodels haben das Konzept aufgegriffen und so den Bekanntheitsgrad deutlich erhöht. Aber vor allem die Verwendung von RxJS als Teil von Angular 2 hat für eine Steigerung der Popularität gesorgt.
Der Artikel geht auf die Grundkonzepte von Rx und deren praktische Anwendung ein. Sehr theoretische und mathematische Aspekte wie Monaden beleuchtet er dagen nicht näher, da das Verständnis für die regelmäßige Nutzung im Vordergrund steht.
Historie und Hintergrund
Rx kommen aus dem Hause Microsoft: Das Cloud Programmability Team hat die Erweiterungen entwickelt. Unter der Federführung von Eric Meijer, der auch maßgeblich an der Entwicklung von LINQ beteiligt war, tauchten um 2006 die ersten Versionen der Libraries im Internet auf. Die ursprünglich für .NET/C# entwickelte Bibliothek ist heute eine von vielen, denn mittlerweile gibt es Rx für zahlreiche Sprachen und Plattformen. Vor allem hat sich das einheitliche asynchrone Programmiermodell – auch über Sprachen hinweg – bei vielen Entwicklern durchgesetzt.
Zum ersten produktiven Einsatz kam die Bibliothek mit der Veröffentlichung von Windows Phone. Alle hauseigenen Rx-Varianten hat Microsoft als Open Source veröffentlicht. Der Quellcode sowie die Dokumentation sind auf den entsprechenden Seiten bei GitHub zu finden.
Artikel zum Thema Reactive Programming auf heise Developer:
In der Entwicklung von UI-Applikationen ist das reaktive Konzept bereits seit langem verbreitet: Bewegt der Benutzer die Maus in der Applikation, gibt das System die Information über die Bewegungen an die Software weiter. Aus Sicht des Entwicklers kommen die Events asynchron an, und die Anwendung kann entsprechend reagieren. Jede einzelne Mausbewegung wird durch eine entsprechende Koordinate über die Events verteilt. Mit ein bisschen Abstraktion wirken die Events wie ein Array, das aus Mauskoordinaten besteht und dessen Elemente über die Zeit zur Verfügung stehen. Daher werden die Observables, alternativ auch Event Streams genannt, gerne als ein Array über Zeit bezeichnet.
Unter der Haube
Observables unter der Haube
Ein anderer Name für Rx ist "LINQ für Events", da die Extensions LINQ-Abfragen auf Ereignisse ermöglichen. Das bezieht sich nicht ausschließlich auf die typischen .NET-Events. Microsoft hatte LINQ, das für Language Integrated Query steht, mit dem .NET-Framework 3.5 eingeführt. Es ermöglicht, die Anwendung SQL-ähnlicher Abfragen auf XML, Collections oder Arrays. Als Beispiel dient eine Liste mit den Werten von 1 bis 10, aus denen ein Programm mit dem Where-Operator eine Liste der enthaltenen geraden Werte erzeugt:
var range = Enumerable.Range(1,10);
var evenRange = range.Where(value => value % 2 == 0);
foreach (var value in evenRange)
Console.WriteLine(value);
Im .NET-Framework lassen sich die Operatoren nur auf das Interface IEnumerable<T> anwenden. T steht dabei für einen generischen Datentypen.
public interface IEnumerable<out T> : IEnumerable
{
IEnumerator<T> GetEnumerator();
}
Das Interface besteht lediglich aus einer Methode, die einen Iterator des Typs IEnumerator<T> zurückgibt. Damit ist es möglich, Element für Element aus der zugrunde liegenden Liste oder Collection abzufragen.
public interface IEnumerator<out T>
{
T Current { get; }
bool MoveNext();
void Reset();
}
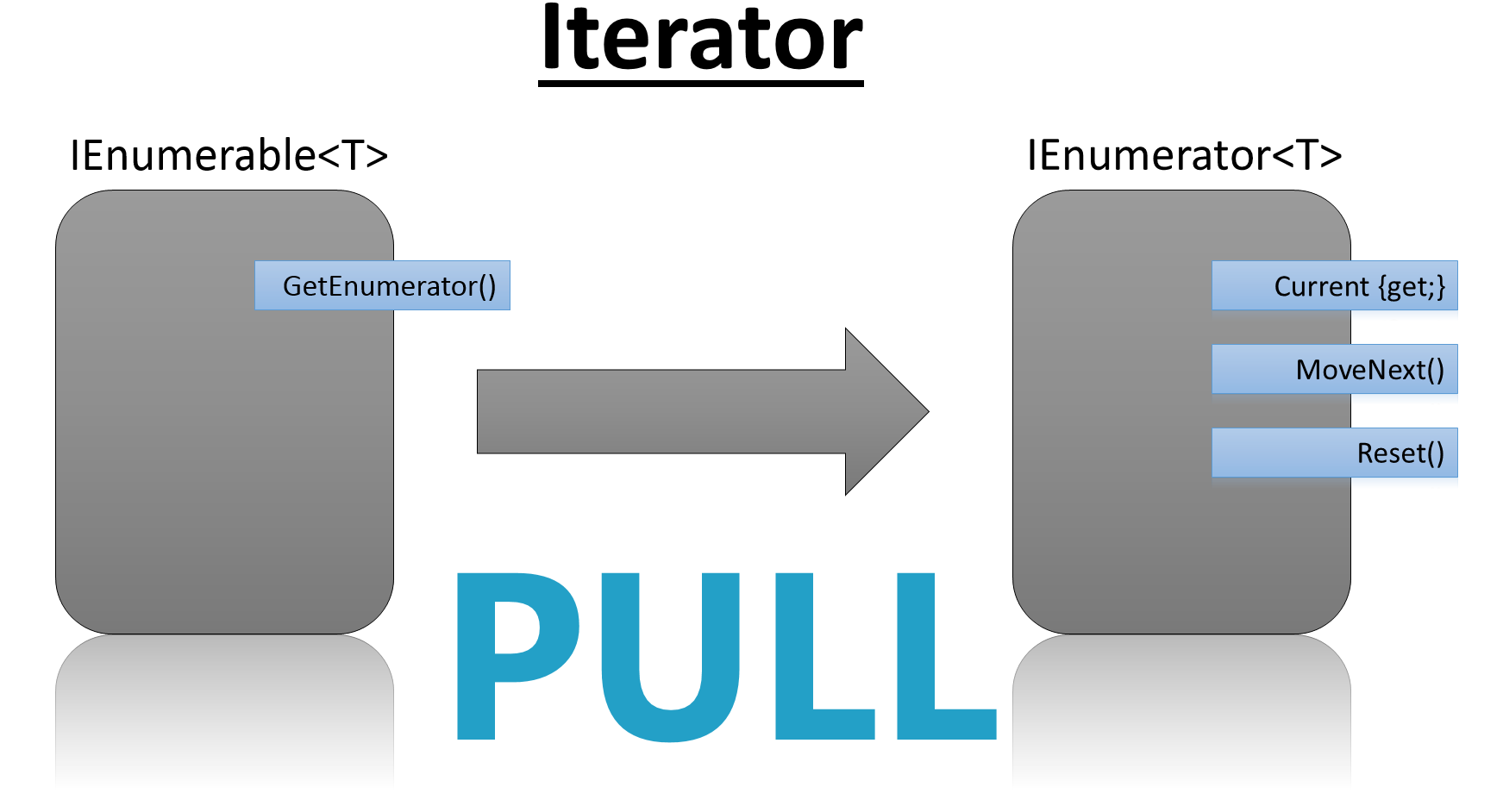
Das Interface besteht aus einer Property und zwei Methoden, wobei Reset() hier unter den Tisch fallen darf. Die Property Current enthält immer das Element, auf das der Iterator gerade zeigt. Die Methode MoveNext() fordert das nächste Element an. Sollte keines mehr vorhanden sein, liefert die Methode den Wert false zurück. Abbildung 1 stellt das Iterator-Modell schematisch dar.
Für Listen und Collections, deren Elemente bereits beim Beginn der Iteration vorhanden sind, ist das Interface gut geeignet. Wenn der Aufruf von MoveNext() dagegen beispielsweise einen Request zu einem Webserver führt, um das nächste Element bereitzustellen, kann die Methode und damit der zugehörige Thread potenziell blockieren. Auch in Zeiten von Multicore sollen Entwickler blockierende Threads unter allen Umständen vermeiden, denn der Preis für das Bereitstellen neuer Threads und den daraus folgenden Thread-Kontext-Wechsel ist nicht zu unterschätzen.
An dieser Stellen kommen die Observables ins Spiel. Sie können aufgrund ihres Interfaces deutlich besser mit solchen asynchronen Quellen umgehen. Mit Rx stehen dem Interface alle gängigen LINQ-Operatoren zu Verfügung. Das Observable besitzt nur eine einzige Interface-Methode:
public interface IObservable<out T>
{
IDisposable Subscribe(IObserver<T> observer);
}
Im Gegensatz zum IEnumerable<T> benötigt die Interface-Methode Subscribe() ein Objekt vom Typ IObserver<T> als Übergabeparameter. Das Interface des IObserver<T> ist ebenfalls übersichtlich gehalten und besteht aus drei Methoden:
public interface IObserver<in T>
{
void OnCompleted();
void OnError(Exception error);
void OnNext(T value);
}
Die Methoden sind aus Sicht des Observer Callbacks, die das Observable aufruft. Letzteres ist ein Objekt, das ein Observer überwachen kann. Dieser kann Informationen über drei Ereignisse erhalten: Über OnNext() bekommt der Observer neue Werte oder Events des Observable zur Verfügung gestellt. Mit der Methode OnCompleted() teilt das Observable mit, dass es keine Werte beziehungsweise Events mehr liefern wird. Sollte innerhalb des Observables ein Fehler auftreten, erfolgt ein Aufruf der OnError()-Callback-Methode des Observer. Die Aufrufe für OnCompleted() und OnError() sind immer final: Nach einem dieser Callbacks sollte und wird das Observable keinen anderen mehr aufrufen.
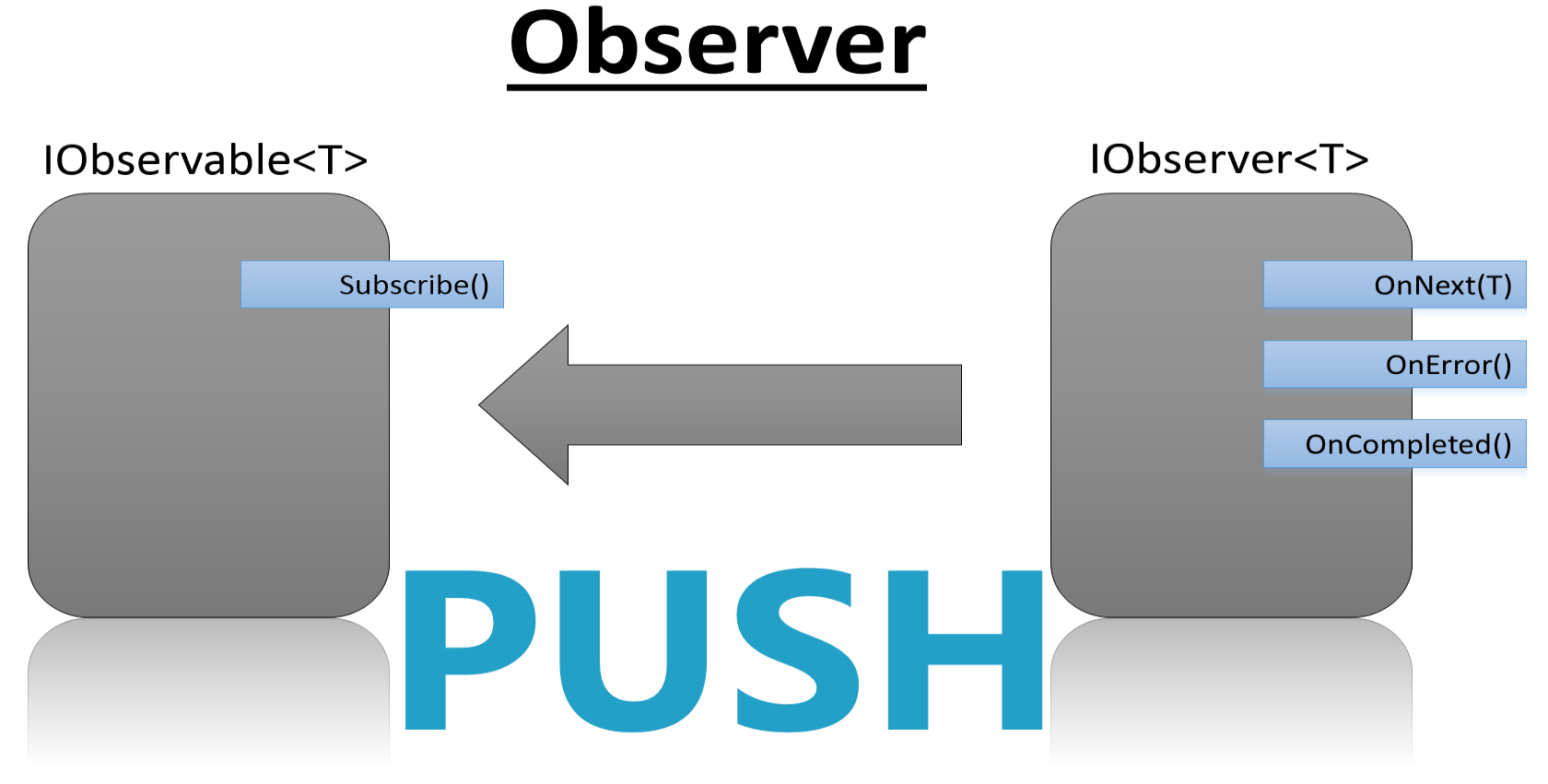
Die Verwendung von Callbacks verhindert das Blockieren des aktuellen Threads, weil das Observable sie nur aufruft, wenn ein entsprechendes Ereignis eintritt. Das ist einer der Gründe, warum Entwickler das Observable gerne für asynchrone Aufgaben heranziehen. Das folgende kleine Beispiel filtert analog zum IEnumerable<T> einen Bereich von Zahlen:
var range = Observable.Range(1,10);
var evenRange = range.Where(value => value % 2 == 0);
var subscription = evenRange.Subscribe(Console.WriteLine);
Anstatt mit einer foreach-Schleife zu iterieren und den Wert auf der Konsole auszugeben, übergibt der Code den Callback für einen neuen Wert der Subscribe()-Methode. Das ist eine vereinfachte Form, die auf die Übergabe eines Observer-Interfaces verzichtet. Die Erweiterungsmethoden von Rx sorgen für die Kompatibilität zum Interface. Dass Entwickler nicht zwangsmäßig alle drei Callbacks angeben müssen, um ein Observable zu nutzen, vereinfacht den Einsatz. Der obige Code übergibt als Callback Console.WriteLine, das für die Ausgabe des Werts auf der Konsole sorgt.
Asynchron & Fazit
Asynchroner Ablauf
Die bisherigen Beispiele liefen komplett synchron ab. Beim Observable werden direkt beim Aufruf von Subscribe() die Werte 1 bis 10 an den Callback für den nächsten Wert zugestellt. Die Rx Library ermöglicht auf einfache Art das Erstellen eines asynchronen Observable. Die statische Methode Interval() erwartet als Parameter ein zeitliches Intervall, in dem neue Events generiert werden – im folgenden Beispiel im Sekundentakt. Anschließend kombiniert der Code das neue Observable mit dem vorhanden. Der Operator zip führt schließlich die beiden Streams zusammen. Er überwacht die beiden Quell-Observables und generiert auf dem zusammengeführten erst ein neues Event, wenn jede Quelle jeweils ein Ereignis meldet. Das Ereignis besteht aus den Tupple der beiden neuen Werte der Quell-Observables.
var range = Observable.Range(1, 10);
var evenRange = range.Where(value => value % 2 == 0);
var interval = Observable.Interval(TimeSpan.FromSeconds(1));
var zipStream = interval.Zip(evenRange, (i, r) => r);
var subscription = zipStream.Subscribe(Console.WriteLine);
Das kombinierte Observable ist asynchron, da die Events nun einen zeitlichen Bezug besitzen. Somit gibt das Beispielprogramm jede Sekunde einen Wert aus dem bereits gefilterten Observable aus und zeigt anschaulich, was mit "Array über Zeit" gemeint ist.
Die Registrierung auf ein Observable mit der Methode Subscribe() gibt ein Objekt mit dem IDisposable-Interface zurück. Dieses Objekt wird als Subscription bezeichnet und ist ein Grund, warum Observables für die asynchrone Programmierung sehr attraktiv sind. Nach dem Aufruf der Methode Dispose() auf eine Subscription endet die Zustellung der Events. Für asynchrone Operation öffnet das Vorgehen eine elegante Möglichkeit, die Operation abzubrechen. Mithilfe des Dispose() drückt der Aufrufer aus, dass ihn das Ergebnis der noch laufenden Operation nicht mehr interessiert. Die Abarbeitung der eigentlichen asynchronen Operation erfolgt bis zu ihrem Abschluss, aber sie stellt das Ergebnis nicht mehr über das Observable zu. Die Ereignisse OnError() und OnClompeted() fallen nach dem Dispose() ebenfalls unter den Tisch.
Sollte das Observable auf einem .NET-Event basieren, erfolgt beim Aufruf von Dispose() die korrekte Deregistrierung des zugehörigen Ereignisses.
Generell bringt das System Observables auch nach dem Eintreten von OnError() und OnCompleted() automatisch in einen aufgeräumten Zustand. Wenn eines der beiden Events eintritt, ist es das letzte Ereignis, das das zugehörige Observable seinem Beobachter meldet.
Fazit
Die Observables stellen Entwicklern ein Interface zu Verfügung, das sich vor allem für zeitlich abhängige (asynchrone) Daten eignet. Im Vergleich zu den Tasks der Task Parallel Library (TPL) können Observables nicht nur exakt einen Wert zurückgeben: Ein Observable kann kein, eines oder mehrere Ergebnisse liefern und ist damit deutlich flexibler. Der im Interface enthaltene Callback für auftrende Fehler erleichtert deren Behandlung. Eine weiterer Pluspunkt ist die elegante integrierte Option, Observables abzubrechen. Zudem müssen Entwickler nicht auf das async/await-Pattern verzichten.
Ein Blick auf das GitHub-Repository oder die Projektseite lohnt sich auf jeden Fall. Interessierte finden unter Introduction to Rx ein Tutorial.
Marko Beelmann
arbeitet seit 16 Jahren in der professionellen Softwareentwicklung und derzeit bei Philips Medizin Systeme. Schwerpunkte seiner Arbeit liegt im Design und der Entwicklung von Software im .NET Umfeld. Zudem ist er als Sprecher auf Konferenzen zu diversen Themen rund um Softwareentwicklung tätig.
(rme)
