The Art of State: Zustandsmanagement in React-Anwendungen, Teil 1

Wie lassen sich via typischer Szenarien einer React-Anwendung verschiedene Mittel zur Arbeit mit dem Zustand einräumen und was eignet sich für welche Fälle?
Eine zentrales Thema bei der Entwicklung von React-Anwendungen ist die Frage nach dem Verwalten ihres Zustands (State): Wo wird er optimalerweise gehalten, sodass er den Komponenten möglichst effizient zur Verfügung steht? Kann eine Bibliothek für externes State-Management eine Verbesserung sein oder sorgt sie eher für neue Probleme? Dieser Artikel beschreibt verschiedene Arten von Zuständen und stellt die React-eigenen Lösungen zum Arbeiten ihnen vor. In zwei weiteren Teilen werden externe Bibliotheken vorgestellt, die das Arbeiten mit einem globalem Zustand vereinfachen sollen.
Zustand in React-Anwendungen
Der React-Zustand hält die Daten einer Anwendung. Darin kann zum Beispiel hinterlegt sein, welche Daten in einem Eingabefeld eingegeben sind und welche von einem Server gelesen wurden, oder auch UI-Informationen darüber etwa, ob ein Menü geöffnet oder ausgeklappt ist.
Bei Diskussionen über den State wird häufig zwischen lokalem und globalem State unterschieden. Lokaler State ist ein Zustand, den die Komponente direkt vorhält, die ihn auch (ausschließlich) benutzt. Von globalem Zustand ist die Rede, wenn der Zustand für mehrere Teile oder sogar für die ganze Applikation von Bedeutung ist und folglich mehreren Komponenten zur Verfügung stehen muss.
Zur Beantwortung der Frage, welche Technologie zum Einsatz kommt, hilft es, wenn sich Entwickler darüber Gedanken machen, ob ein bestimmter Zustand lokaler oder globaler Natur ist. Sicherlich gibt es zwischen den beiden Extremen Abstufungen, sodass eine Unterscheidung nicht immer nach dem Schwarz-Weiß-Prinzip möglich ist. Zur Diskussion dieser Fragestellung und denkbarer Lösungsansätze soll eine kleine Blog-Anwendung dienen. Der Beispiel-Code, um die Funktionsweise auszuprobieren und nachzuvollziehen, befindet sich auf GitHub [4].
Die Anwendung stellt auf der ersten Seite eine Vorschau-Liste für die Blog-Posts dar, die ein Server lädt. Das Klicken auf die Vorschau eines Blog-Posts zeigt den kompletten Artikel. Über den Login-Button können sich registrierte Benutzer anmelden und danach eigene Blog-Posts schreiben. Für die beiden Anwendungsfälle gibt es jeweils eigene Formulare.
Am Anfang ist der lokale Zustand ...
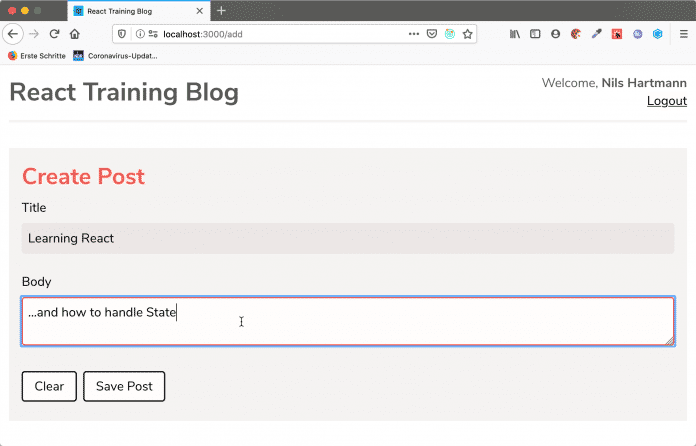
Die Abbildung 1 zeigt den Editor für einen neuen Blog-Post. Hier können Anwender einen Titel und den eigentlichen Inhalt des Blog-Posts eingeben und ihn speichern. Da der neue Blog-Beitrag, solange er in der Bearbeitung ist, für den Rest der Anwendung irrelevant ist, ist die Komponente mit dem lokalem State implementiert, siehe das folgende Beispiel:
export default function PostEditor() {
const [title, setTitle] = React.useState("");
const [body, setBody] = React.useState("");
// . . .
return (
<div>
<h1>Create Post</h1>
<label>
Title
<input value={title}
onChange={(e) => setTitle(e.currentTarget.value)} />
</label>
<label>
Body
<textarea value={body}
onChange={(e) => setBody(e.currentTarget.value)} />
</label>
// . . .
</div>
);
}Dasselbe gilt für das Login-Formular. Auch hier spielt für den Rest der Anwendung keine Rolle, was Benutzer als Username beziehungsweise Passwort eingegeben haben. Die Sache sieht anders aus, sobald sie das Login-Formular abgeschlossen haben und der Server ein positives Ergebnis gesendet hat. Die Frage, ob und welcher Benutzer (Name, Rollen etc.) gerade angemeldet ist, spielt für die ganze Anwendung eine Rolle, da davon abhängig die UI bestimmte Elemente anzeigt oder nicht. Es handelt sich um einen "Klassiker" für globalen Zustand.

Schwieriger einzuordnen ist die Frage, ob es sich bei der ausgewählten Sortierreihenfolge der Blog-Liste auf der Übersichtsseite um globalen oder lokalen Zustand handelt. Hier können Benutzer aus verschiedenen Kriterien wählen, in welcher Reihenfolge die Posts erscheinen sollen. Auch wenn der Server die eigentliche Sortierung ausführt, sollen Benutzer ihre gewählten Kriterien über einen Seitenwechsel hinweg erhalten. Klicken sie zum Beispiel einen einzelnen Post oder das Login-Formular an und kehren wieder auf die Übersichtsseite zurück, sollen ihre Sortiereinstellungen beibehalten werden. In dem Fall handelt es sich einerseits ("fachlich") um lokalen Zustand, weil die Sortierinformationen nur für die Blog-Listen-Komponente relevant sind. Andererseits können die Informationen nicht direkt an dieser Komponente abgelegt werden, da sie sonst mit dem Verschwinden der Komponente (Wechsel der Seite) ebenfalls verloren gehen. Deswegen sind sie an einem anderen Ort wie einer höheren Komponente abzulegen. Dann lässt sich von globalem Zustand sprechen, der allerdings eher technisch motiviert ist.
Ähnlich ist die Seite zum Darstellen eines einzelnen Blog-Posts zu betrachten. Zwar wird der geladene Post nur für die einzelne Seite benötigt, es wäre allerdings denkbar, dass die einmal geladenen Posts auf dem Client gecacht werden sollen, um eine schnellere Navigation zu ermöglichen. Auch in dem Fall müsste ein eigentlich lokaler State aus seiner "natürlichen" Komponente herauswandern.
Die Einzelansicht eines Blog-Posts zeigt noch eine andere Art von State, der ebenfalls nicht in der Komponente vorgehalten wird: die URL. In ihr ist hinterlegt, welcher Blog-Post gerade dargestellt werden soll (oder welche andere Ansicht). Solche Informationen liegen bei "kleineren" UI-Elementen unter Umständen in einem React State (z. B. ob ein Menü auf- oder zugeklappt ist). Bei "größeren Einheiten", zum Beispiel welche Seite offen ist, lagert man diese Information oft in die URL aus, um die Seiten verlink- und anspringbar zu machen.
Hier gibt es ebenfalls verschiedene Herangehensweisen, welche Informationen die URL und welche React hält. Oftmals ist das eine fachliche Fragestellung: Soll sich eine Seite per URL referenzieren lassen? Sollen Teile der Darstellung ebenfalls per URL gesetzt werden können? Die Sortierkriterien könnten ein Fall für die URL sein, sodass jemand, der einen Link verschickt beziehungsweise empfängt und öffnet, die genau gleiche Darstellung sieht. Neben der URL kann Zustand zum Beispiel in den Speichermöglichkeiten im Browser vorkommen, etwa in Form eines Session Token und als einfache Zwischenspeichermöglichkeit bei der Eingabe neuer Daten in ein Formular.
Zustand in React-Anwendungen lässt sich demnach in global und lokal unterteilen, aber auch nach Funktionen: Geht es etwa um reinen UI State (Menü auf- oder zugeklappt, Sortierkriterien) oder zum Beispiel um das Cachen von Daten? Außerdem unterscheidet sich Zustand in der Art, wie mit ihm interagiert und wie er verändert wird. Daten in einem Eingabefeld verändern sich in der Regel eher schnell, nämlich in der Geschwindigkeit, in der ein Eingabefeld ausgefüllt wird. Ein ausgewähltes Theme oder die Information, ob ein Benutzer eingeloggt ist oder nicht, ändern sich hingegen in der Regel selten. Diese Fragestellungen können Konsequenzen auf die Wahl der "richtigen" Technologie für den jeweiligen Zustand haben, damit man einerseits eine möglichst einfache Herangehensweise wählt, andererseits aber auch eine, die das Problem zum Beispiel hinsichtlich Performance adäquat adressiert.
Der Klassiker: lokaler State mit useState-Hook
Der "klassische" lokale State wird wie oben gesehen mit dem Hook useState erzeugt. Sobald React die Komponente, die diesen Zustand erzeugt hat, aus dem DOM entfernt (etwa durch das Wechseln auf eine andere Seite), verschwindet auch der Zustand. Er ist also an den Lebenszyklus der Komponente gekoppelt. Von der Komponente ausgehend lässt sich der Zustand aber per Property an eine unterliegende Komponente reichen. Ebenso kann man einer unterliegenden Komponente eine Callback-Funktion zum Ändern des Zustands übergeben. Schon an der Stelle kann man sich darüber streiten, ab wann es sich um lokalen oder bereits um globalen Zustand handelt.
Custom Hooks
Die React Hook API bietet die Möglichkeit, eigene, sogenannte Custom Hooks zu schreiben. Wenn in einer Anwendung häufig wiederkehrende Muster vorkommen, kann es hilfreich sein, dafür eigene Hooks zur Verfügung zu stellen. In Custom Hooks lassen sich weitere Hooks verwenden, also auch der Hook useState. Besonders daran ist: Wenn sich der Zustand innerhalb des Custom Hook ändert, wird die Komponente ebenfalls neu gerendet, die den Hook verwendet. Custom Hooks sind technisch gesehen normale JavaScript-Funktionen, bei denen sich Rückgabewert und Funktionssignatur (im Gegensatz zu Komponentenfunktionen) frei wählen lassen. Auf diese Weise können Entwickler eine passende, fachliche API wählen. Das folgende Listing zeigt einen einfachen "Hello World"- Custom Hook, der einen einfachen Zähler zur Verfügung stellt. Ähnlich wie die useState-API liefert er den aktuellen Wert des Zählers sowie eine Funktion zum Ändern des Zählers zurück, allerdings in Form eines Objekts und nicht als Array wie bei useState.
// Custom Hook
function useCounter(initial) {
const [ value, setValue ] = React.useState(initial);
return {
count: value,
increaseCounter() { setValue(value + 1) }
}
}
// Exemplarische Verwendung des Hook in einer Komponente
function LikeButton() {
const { count, increaseCounter } = useCounter(10);
return (
<button onClick={increaseCounter}>{count} Likes</button>
);
}Ein realistischeres Szenario als das "Hello World" ist ein Custom Hook zum Zugriff auf eine Remote API, beispielsweise mit der Browser-API fetch. Das folgende – vereinfachte – Beispiel zeigt einen Custom Hook, der via fetch Daten von einer API lädt. Die URL der API wird dem Custom Hook per Argument übergeben. Der Hook liefert einen Indikator (isLoading) zurück, der anzeigt, ob der Request gerade läuft. Nach dem Laden der Daten werden die Daten ebenfalls zurückgeliefert.
function useApi(url) {
const [ loading, setLoading ] = React.useState(false);
const [ data, setData ] = React.useState(null);
React.useEffect( () => {
setLoading(true);
fetch(url)
.then(res => res.json())
.then(data => {
// Server Request beendet
setLoading(false);
setData(data);
})
}, [url]);
return { loading, data };
}Mit den Informationen können Verwender des Hooks abhängig von dessen Zustand eine Information an die Benutzer ausgeben, dass die Daten gerade geladen werden, oder die übertragenen Daten anzeigen. In der Blog-Beispielanwendung lässt sich dieser Hook etwa verwenden, um die Übersichtsseite zu laden beziehungsweise einen Blog-Post für die Einzeldarstellung:
// Blog-�bersicht:
function BlogListPage() {
const { loading, data } = useApi("http://api/posts");
if (loading) {
return <LoadingIndicator />
}
return <BlogList posts={data} />
}
// Einzeldarstellung:
function BlogPage(props) {
const { loading, data } =
useApi("http://api/posts/" + props.postId);
if (loading) {
return <LoadingIndicator />
}
return <Blog post={data} />
}Komplexer Zustand
Beim Vergleichen des Custom Hook mit der PostEditor-Komponente fällt auf, dass beide Komponenten mehr als einen Zustand erzeugen, in dem sie mehrfach useState aufrufen. Allerdings gibt es – unabhängig vom fachlichen Inhalt – einen gravierenden Unterschied zwischen den Zuständen der beiden Komponenten: Im Fall des PostEditor handelt es um zwei völlig unabhängige Zustände. Je nachdem, in welches Feld Benutzer tippen, ändert das den einen oder anderen Zustand, ohne dass es einen fachlichen Bezug zum jeweils anderen Zustand gäbe.
Anders beim useApi-Hook: Hier sind die Teilzustände abhängig voneinander. Nach dem Laden der Daten ist zwingend der isLoading-Zustand neu zu setzen, um nicht in Inkonsistenzen zu geraten (Daten sind bereits geladen, isLoading verbleibt aber auf "true"). Noch deutlicher tritt die Abhängigkeit zutage, wenn nicht nur die Daten und isLoading gehalten werden sollen, sondern auch, ob beim Request ein Fehler auftrat, so wie in der folgenden Variante des Hooks:
function useApi(url) {
const [ loading, setLoading ] = React.useState(false);
const [ error, setError ] = React.useState(null);
const [ data, setData ] = React.useState(null);
React.useEffect( () => {
setLoading(true);
setError(null);
fetch(url)
.then(res => res.json())
.then(data => {
setLoading(false);
setData(data);
setError(null)
}).catch(e => {
setError(e);
setLoading(null);
setData(null)}
}, [url]);
return { loading, data, error };
}Sind die Daten geladen, ist nicht nur isLoading zurückzusetzen, sondern auch der error-Zustand. Ebenfalls gilt: Bei einem Fehler muss man die Daten und isLoading zurücksetzen. Hier kann das Verwenden einzelner Zustände zu Problemen führen: So mag bei der Entwicklung "vergessen" werden, einen der Zustände entsprechend zurückzusetzen. Beim Start des Requests werden etwa die Daten nicht zurückgesetzt. Das kann zwar fachlich korrekt sein, vielleicht ist es aber auch ein Versehen.
Ein anderes Problem ist, dass React unter Umständen die Komponente, die den Hook verwendet, nach den einzelnen setter-Aufrufen erneut rendert: nach dem Erhalt der Daten zum Beispiel nach setLoading, nach setData und dann noch einmal nach setError. Das wiederum kann ein Performanceproblem darstellen, in jedem Fall aber würde die verwendete Komponente inkonsistente Daten erhalten: Nach dem ersten Aufruf wäre isLoading auf "false" gesetzt, allerdings wären die (neuen) Daten noch nicht im State enthalten. Somit würden entweder veraltete Daten angezeigt oder die Anwendung würde sogar fehlerhaft werden, da die Komponente nicht damit rechnet, nicht mehr zu laden, aber auch keine Daten zu haben (und keinen Fehler).
Für solche Fälle, in denen eher ein "Gesamtzustand" als mehrere "Teilzustände" vorliegt, sollte man nur einen Zustand mit useState erzeugen, der dann ein Objekt aufnimmt. Der Zustand lässt sich in der Folge "atomar" aktualisieren, sodass es zu keinen "fehlerhaften" Renderings kommt. Außerdem ist das zumindest in einigen Situationen weniger fehlerhaft. Im Gegensatz zur setState-Methode aus der React-Klassen-API setzt die von useState zurückgegebene setter-Funktion übrigens den ganzen State neu. Das heißt, was immer dieser Funktion übergeben wird, ist der neue Gesamtzustand. Zum Vergleich: setState hat alten und neuen Zustand zusammengeführt und nicht ersetzt.
Im Folgenden der useApi-Hook mit einem Gesamtzustand für den Lebenszyklus eines Server Request:
function useApi(url) {
const [ apiState, setApiState ] =
React.useState(
{ loading: false, data: null, error: null }
);
React.useEffect( () => {
setApiState({loading: true});
fetch(url) // vereinfacht
.then(res => res.json())
.then(data => setApiState({data: data}))
.catch(err => setApiState({error: err}));
}, [url]);
return apiState;
}Auslagern von Logik: der useReducer-Hook
Für den Fall, dass die Logik und damit der Zustand komplexer werden, gibt es eine Möglichkeit, mit dem useReducer-Hook die Verwaltung des Zustands aus der Komponente oder dem Custom Hook herauszuziehen. Dabei wird eine sogenannte Reducer-Funktion implementiert, in der die Logik zum Verarbeiten des Zustands untergebracht ist. React übergibt ihr den jeweils aktuellen Zustand sowie eine Aktion (Action). Auf Basis der beiden Informationen, von altem Zustand und Action erzeugt die Funktion neuen Zustand, den sie zurückliefert. Der neue Zustand wiederum wird dann an die verwendende Komponente zurückgegeben, sodass diese sich neu rendert, genau wie bei useState.
Eine Reducer-Funktion für den Lebenszyklus des Server Request aus dem Custom Hook useApi könnte wie folgt aussehen:
function apiReducer(oldState, action) {
switch (action.type) {
case "FETCH_START":
return { ...oldState, loading: true, error: null };
case "LOAD_FAILED":
return { loading: false, error: action.error };
case "LOAD_FINISHED":
return { data: action.data };
default:
throw new Error("Invalid action!");
}
}Die Funktion verarbeitet drei Aktionen (FETCH_START, LOAD_FAILED, LOAD_FINISHED) und gibt jeweils neuen Zustand dafür zurück.
Es lässt sich darüber streiten, ob in dieser einfachen Form eine Reducer-Funktion den Code besser oder schlechter verständlich macht. In jedem Fall ist damit aber die Logik gänzlich aus dem React-Code (Hook bzw. Komponente) verschwunden. Denn bei einer Reducer-Funktion handelt es sich um eine reguläre, seiteneffektfreie JavaScript-Funktion, die sich auch in anderen Anwendungen oder mit anderen Bibliotheken einsetzen ließe. Selbst das Testen der Funktion ist einfacher, als eine ganze Komponente oder einen Custom Hook zu testen, da sie keinerlei Abhängigkeiten zu React hat.
Die Aktionen, die eine Reducer-Funktion verarbeiten kann, lassen sich frei definieren. Dabei handelt es sich um einfache JavaScript-Objekte, die eine type-Property enthalten (damit der reducer sie identifizieren kann) sowie – optional – einen fachlichen Payload, im Beispiel oben etwa die Fehlermeldung (bei Aktion LOAD_FAILED) beziehungsweise die neuen Daten (bei LOAD_FINISHED). Auch die Action[/code)-Objekte haben keine Abhängigkeit auf React oder Ähnliches und können zum Beispiel im Test einfach erzeugt werden. Der Verwender der Reducer-Funktion benutzt nun nicht mehr [code]useState, sondern den useReducer-Hook. Dieser erwartet dann die Reducer-Funktion und liefert jeweils den aktuellen Zustand sowie eine Funktion zum Verschicken von Aktionen an die Reducer-Funktionen (dispatch) zurück. Damit ist die API ähnlich wie bei useState: Sie gibt Zustand sowie eine Funktion zum Ändern des Zustands zurück, nur dass der Zustand nicht mehr direkt verändert, sondern eine Aktion ausgelöst wird. Der Custom Hook useApi kann den Reducer somit wie folgt verwenden:
function apiReducer(. . .) { wie oben gezeigt }
function useApi(url) {
const [apiState, dispatch] = React.useReducer(apiReducer);
React.useEffect( () => {
dispatch({ type: "FETCH_START" });
fetch(...)
.then(
data => dispatch({type: "LOAD_FINISHED", data: data })
)
}, [url]);
return apiState;
}In welchen Fällen Reducer-Funktionen wirklich Sinn ergeben, ist von Fall zu Fall zu entscheiden. Die Vorteile (Logik an einer Stelle konzentriert, keine React-Abhängigkeit, einfache Testbarkeit) überwiegen die Nachteile (relativ unschöner Code zum Dispatch der Actions, Arbeiten mit immutable-Objekten im Reducer) am ehesten, wenn der Reducer komplexe Logik zu verarbeiten hat. Die Reducer-Funktionen sind übrigens API-kompatibel mit denen aus Redux, sodass sich eine Reducer-Funktion auch mit Redux verwenden ließe. Der nächste Teil dieses Artikels wird sich näher mit Redux beschäftigen.
immer für immutable Datenstrukturen
Sowohl in Redux als auch in React müssen Reducer-Funktionen zwingend fortwährend neuen Zustand zurückgeben. Der alte Zustand, den sie reingereicht bekommen, darf nicht verändert werden. Deshalb wird der Zustand im Beispiel oben jedes Mal neu erzeugt und nicht verändert. Das Arbeiten mit solchen unveränderlichen (immutable) Datenstrukturen kann Code-lastig und fehleranfällig sein, selbst wenn Typ-Checker wie TypeScript hier einige Fehler frühzeitig erkennen.
Zur Illustration des Problems noch ein weiterer Reducer, der die Darstellung der Blog-Liste verwalten soll. Der darin verwaltete Zustand besteht aus einem Filter, der nur Posts mit einer gewissen "Like"-Anzahl anzeigt sowie die Informationen zur Sortierung (nach was wird sortiert und in welcher Richtung):
function blogListOptionsReducer(state, action) {
switch (action.type) {
// setzt den Filter neu; die Sortierreihenfolge
// soll aber bestehen bleiben
case "SET_BLOGLIST_FILTER_BY_LIKES": {
return { ...state, likes: action.likes };
}
case "SET_BLOGLIST_SORT": {
// setzt Sortierkriterium und -Reihenfolge neu,
// der Likes-Filter soll aber bestehen bleiben
return {
...state,
sortBy: action.sortBy,
order: action.direction,
};
}
default:
throw new Error("Invalid action!");
}
}Schon in diesem einfachen Beispiel ist darauf zu achten, den alten Zustand zu kopieren sowie die Kopie anzupassen und zurückzuliefern. Das Problem wird komplexer, je aufwendiger das Zustandsobjekt ist – ob es etwa aus Arrays und verschachtelten Strukturen besteht.
Eine Möglichkeit, den Code zu vereinfachen, ist die Bibliothek immer [5] zu verwenden. Sie erlaubt es, mit Objekten zu arbeiten, als seien sie veränderlich. Tatsächlich arbeitet sie aber nicht auf dem Originalobjekt, sondern auf einem Objekt, das nur so aussieht wie das Originalobjekt. Auf ihm zeichnet immer alle ausgeführten Veränderungen transparent auf und erzeugt daraus ein komplett neues Objekt.
Die API ist dabei einfach: Die Anwendung übergibt der produce-Funktion ein Objekt sowie eine Callback-Funktion zum Verarbeiten des Objekts. immer ruft dann die übergebene Callback-Funktion mit einem "Draft-Objekt" auf. Auf ihm werden mit den regulären JavaScript-APIs Änderungen vorgenommen. Das Ausführen der Callback-Funktion erzeugt immer die Kopie des Originalobjekts, wendet darauf die aufgezeichneten Änderungen an und gibt die Kopie an den Aufrufer von produce zurück.
Die oben gezeigte Reducer-Funktion kann mit immer wie folgt aussehen:
import produce from "immer";
function blogListOptionsReducer(oldState, action) {
return produce(oldState, state => {
switch (action.type) {
case "SET_BLOGLIST_FILTER_BY_LIKES": {
// Sortierkriterium bleibt bestehen!
state.likes = action.likes;
break;
}
case "SET_BLOGLIST_SORT": {
// Likes-filter bleibt bestehen!
state.sortBy = action.sortBy;
state.order = action.direction;
break;
}
default: . . .
}
}
}Fazit
Der Zustand in React-Anwendung lässt sich in unterschiedliche Kategorien, zum Beispiel lokal und global oder einfach und komplex, einteilen. Das kann eine Hilfe bei der Wahl der geeigneten Technologie sein, mit der der jeweilige Zustand verwaltet und verarbeitet wird.
Dieser Artikel hat verschiedene Ansätze zur Arbeit mit einfachem und komplexem Zustand vorgestellt, die mit den React-eigenen Mitteln realisierbar sind. In weiteren Artikeln werden Verfahren und Bibliotheken zur Arbeit mit globalem Zustand vorgestellt.
Nils Hartmann [6]ist freiberuflicher Softwareentwickler, Trainer und Coach aus Hamburg. Er programmiert in Java und JavaScript und berät und schult Teams beim Ein- und Umstieg in die Entwicklung von Single-Page-Anwendungen mit den Schwerpunkten React, TypeScript und GraphQL. Nils ist Autor des Buches "React – Grundlagen, fortgeschrittene Techniken, Praxistipps" (dpunkt.verlag 2019).
(ane [7])
URL dieses Artikels:
https://www.heise.de/-4934595
Links in diesem Artikel:
[1] https://www.heise.de/ratgeber/The-Art-of-State-Zustandsmanagement-in-React-Anwendungen-4934595.html
[2] https://www.heise.de/ratgeber/The-Art-of-State-Zustandsmanagement-in-React-Anwendung-Teil-2-4990188.html
[3] https://www.heise.de/ratgeber/The-Art-of-State-Zustandsmanagement-in-React-Anwendung-Teil-3-5054351.html
[4] https://github.com/nilshartmann/react-statemanagement-examples
[5] https://github.com/immerjs/immer
[6] https://nilshartmann.net
[7] mailto:ane@heise.de
Copyright © 2020 Heise Medien