

Verwundbarkeitsanalyse anhand von CPE-Dictionary und CVE-Feeds
Sicherheitslücken können Cyberangriffe ermöglichen. Deswegen müssen Sicherheitsverantwortliche ständig nach Verwundbarkeiten bei der installierten Software suchen. Was sind die Herausforderungen einer solchen Verwundbarkeitsanalyse?

- Luis Alberto Benthin Sanguino
- Martin März
Cyberkriminelle nutzen Schwachstellen in Software aus, um Rechner mit Malware wie Ransomware zu infizieren. Um das zu verhindern, wird eine entdeckte Verwundbarkeit schnell bekanntgegeben und das entsprechende Sicherheitsupdate veröffentlicht. Auf Grundlage dieser Information müssen die Benutzer das Update zeitnah installieren, um die Sicherheitslücke zu beheben.
In Unternehmen, in denen mehrere Softwareprodukte auf Hunderten von Rechnern installiert sind, ist der Einsatz eines Verwundbarkeitsmanagementsystems (VMS) erforderlich, um die installierten Softwareprodukte regelmäßig zu überwachen. Solche Systeme prüfen anhand verschiedener Quellen – zum Beispiel Hersteller-Bulletins oder öffentlicher Datenbanken wie die CVE-Feeds (Common Vulnerabilities and Exposures) –, ob eine Software verwundbar ist. Dieses Verfahren bezeichnet man als Verwundbarkeitsanalyse (VA).
Die CVE-Feeds sind eine der am häufigsten verwendeten Quellen für Schwachstelleninformationen. Diese Datenbank bietet den Vorteil, dass sie öffentlich zugänglich und kompatibel mit dem CPE-Standard (Common Platform Enumeration) ist.
Der Artikel skizziert eine VA-Methode, in der die CPE-Dictionary als Quelle für die Software-IDs im Zusammenhang mit den CVE-Feeds eingesetzt wird. Darüber hinaus präsentieren die Autoren Ergebnisse einer Evaluierung, die einige negative Aspekte wie den Mangel an Synchronisation von CPE-Dictionary und CVE-Feeds zeigt. Zudem geben sie Empfehlungen, die diese Nachteile berücksichtigen, damit eine Verwundbarkeitsanalyse zuverlässige und korrekte Resultate liefert.
Beschreibung und Einsatz des CPE-Standards
Der CPE-Standard definiert ein Schema für die Benennung von IT-Produkten. Auf diese Weise lassen sich Software- und Hardwareprodukte eindeutig identifizieren. Das ermöglicht den Austausch von Produktinformationen (z. B. die Version einer Software) zwischen unterschiedlichen Systemen oder Schnittstellen, die den CPE-Standard erfüllen. Beispielsweise stellt ein Softwareinventarisierungssystem innerhalb eines Unternehmens die CPEs installierter Software zur Verfügung, sodass ein Verwundbarkeitsanalysesystem, das auch den CPE-Standard unterstützt, nach verwundbaren Versionen dieser Software suchen kann.
Um die Zuordnung einer CPE zu einem Softwareprodukt zu vereinfachen, bietet die National Vulnerability Database (NVD) eine XML-Datenbank (CPE-Dictionary), die die CPEs der meisten Softwareprodukte schon erfasst. Die CPE-Dictionary gilt als die offizielle Quelle von CPEs und ist öffentlich zugänglich. Im folgenden Beispiel sieht man den Eintrag der CPE-Dictionary (Version 2.3) für Mozilla Firefox 52.0:

Beschreibung und Einsatz des CVE-Standards
Damit IT-Sicherheitsexperten, Wissenschaftler, CERTs (Computer Emergency Response Team) oder die Antivirusindustrie Verwundbarkeiten in Software- oder Hardwareprodukten eindeutig identifizieren können, ist eine standardisierte Methode notwendig. Der CVE-Standard entstand für diesen Zweck. Jeder bekannten Softwareschwachstelle wird eine eindeutige CVE-ID zugewiesen.
Darüber hinaus bekommt ein CVE für eine Verwundbarkeit nicht nur eine ID, sondern es werden Angriffsmöglichkeiten wie ein DoS-Angriff (Denial of Service) kurz beschrieben, die Kritikalität dieser Schwachstelle definiert und, am wichtigsten, die betroffenen Software- und Hardwareprodukte in das CPE-Format übergeben. Dadurch lässt sich ein bestimmtes IT-Produkt mit einer Verwundbarkeit einfach verlinken.
Ähnlich wie beim CPE-Standard bietet die NVD eine öffentlich zugängliche XML- oder JSON-Datenbank (CVE-Feeds), in der die meisten bekannten Schwachstellen im CVE-Format eingetragen werden. Abbildung 2 zeigt ein Beispiel eines Eintrags des XML-CVE-Feeds von 2018. In diesem Fall handelt es sich um einen Buffer Overflow in verschiedenen Versionen des Acrobat Reader. Die Informationen des CVE-Beispiels werden verkürzt dargestellt.

Zielsetzung und Anwendungsumfang einer Verwundbarkeitsanalyse
Ein Verwundbarkeitsmanagementsystem hat das Ziel, verwundbare Software innerhalb einer IT-Infrastruktur rechtzeitig zu erkennen, zu melden und zu beseitigen, um einen möglichen Angriff zu vermeiden. Den Prozess, in dem ein Softwareprodukt als verwundbar erkannt wird, bezeichnet man als Verwundbarkeitsanalyse.
Die vorherigen Abschnitte haben ein Verfahren zur eindeutigen Identifizierung von Software (CPE) und eine Methode zur eindeutigen Identifizierung bekannter Schwachstellen in Software (CVE) vorgestellt. Außerdem kam zur Sprache, dass öffentlich zugängliche Datenbanken für die CPE- und CVE-Einträge zur Verfügung stehen.
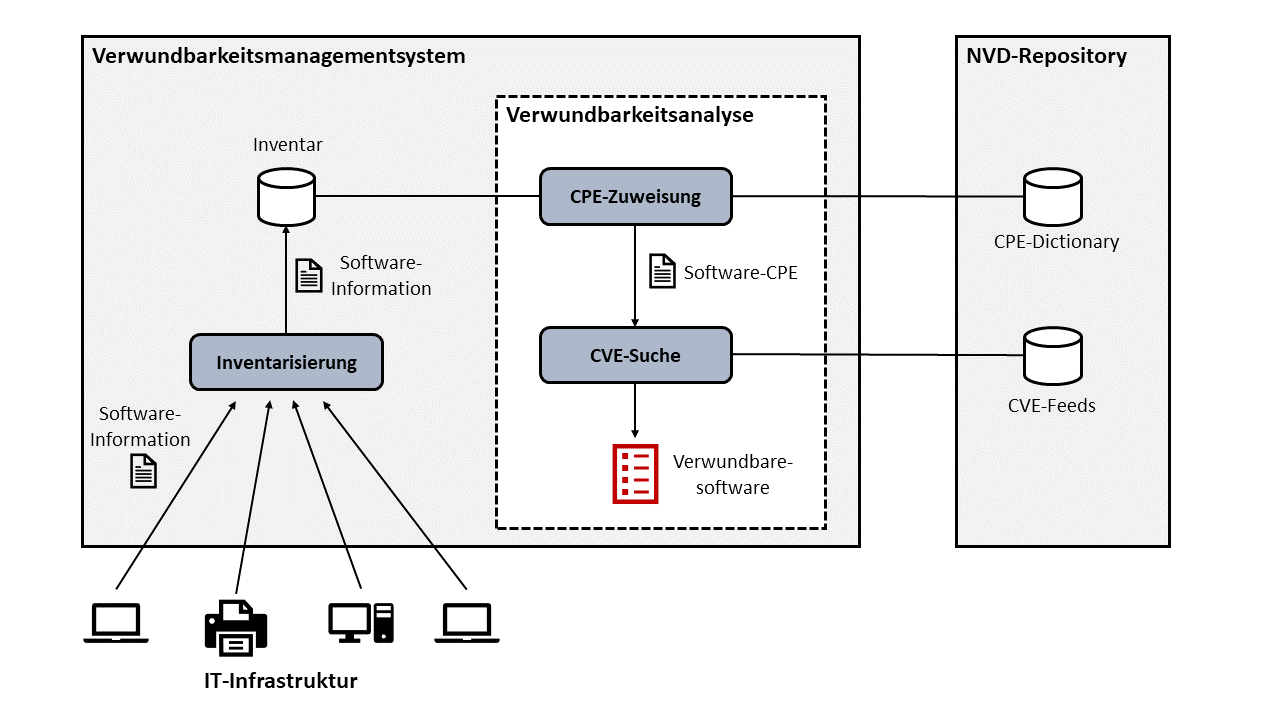
Die Kompatibilität der CVE-Feeds mit dem CPE-Standard ermöglicht die Implementierung kostengünstiger und effektiver Verwundbarkeitsanalyseangebote. Abbildung 3 zeigt die Realisierung einer VA anhand der CPE- und CVE-Datenbanken. Die VA-Komponente befindet sich in einem Verwundbarkeitsmanagementsystem und bekommt als Eingabe die Softwareprodukte, die in einer IT-Infrastruktur installiert sind, aus einer Inventardatenbank. Während der Analyse werden grundsätzlich drei Schritte durchgeführt:
- Jedes Softwareprodukt bekommt eine CPE.
- Anhand der zugewiesenen CPE wird nach CVEs für das Softwareprodukt gesucht.
- Falls CVEs für die Softwareprodukte gefunden wurden, wird eine Liste zu den verwundbaren Produkten erzeugt. Danach werden bei Bedarf andere Komponenten wie ein Meldungssystem des VMS in diese Liste mit aufgenommen. Den letzten Teil zeigt die Abbildung 3 nicht, da der Fokus auf der Verwundbarkeitsanalyse (mit der CPE und CVE) liegt.
Evaluierung von CPE-Dictionary und CVE-Feeds
Bevor eine Verwundbarkeitsanalyse – mithilfe der offiziellen CPE- und CVE-Datenbanken – implementiert wird, ist es zu empfehlen, eine Evaluierung der Datenbanken durchzuführen, um einige Aspekte wie die Synchronisierung zwischen CPE-Dictionary und CVE-Feeds zu berücksichtigen. Über die Evaluierung lässt sich vermeiden, dass die Verwundbarkeitsanalyse inkorrekte Ergebnisse liefert. Es könnte zum Beispiel ein Softwareprodukt als nicht verwundbar klassifiziert werden, was tatsächlich gar nicht stimmt. Das führt somit zu einer Falsch-negativ-Rate (eng. false negative rate). Diese falsche Klassifizierung könnte einen Hackerangriff verursachen, der die Sicherheitslücke in der Software ausnutzt.
Bei einer Evaluierung von CPE-Dictionary und CVE-Feeds (durchgeführt am 13. Juni 2018) haben die Autoren ein Tool in Python geschrieben, das in Gitlab zur Verfügung steht. Es ermöglicht Entwicklern, die Evaluierung ebenfalls jederzeit durchführen zu können.
CVE-Einträge ohne CPE
Die CVE-Feeds enthalten 2864 CVEs ohne CPE-ID. Beispielsweise hat der CVE-Eintrag CVE-2018-0149 (eine XSS-Schwachstelle in der Web-Management-Schnittstelle eines Cisco-Produkts) bis zum Zeitpunkt der Evaluierung keine CPE-ID bekommen. In Abbildung 3 wurde eine Verwundbarkeitsanalyse skizziert, in der die Suche von CVEs für eine Software auf der zugewiesenen CPE-ID des Produkts basiert. Ohne Berücksichtigung der Tatsache, dass CVEs ohne CPE existieren, könnte so eine Analyse fehlerhafte Resultate liefern, da in vielen Fällen keine Beziehung zwischen einer CVE- und der CPE-ID einer Software möglich ist.
Veraltete Einträge in der CPE-Dictionary
CPE-Einträge können aus drei Gründen veraltet sein:
- Die CPE-ID hat einen Tippfehler oder stimmt nicht.
- Die CPE wird nicht länger benutzt und muss entfernt werden.
- Neue Informationen zu einem IT-Produkt sind hinzuzufügen.
Die veralteten CPEs werden mit dem XML-Element cpe-23:deprecation gekennzeichnet. Es enthält ein Kind-Element (cpe-23:deprecated-by), das gegebenenfalls zeigt, durch welche CPE die veraltete CPE ersetzt wurde. Außerdem wird der Grund der "Deprecation" anhand des Attributs "name" angegeben.
Zum Zeitpunkt der Evaluierung gab es 2939 veraltete CPEs. Alle waren wegen der Namenskorrektur veraltet. Das nachfolgende Bild zeigt einen veralteten CPE-Eintrag aus der CPE-Dictionary. Diese CPE ist veraltet, da der Name des Produkts falsch geschrieben wurde: "morbtay" statt "mortbay".

Die Tatsache, dass eine beträchtliche Menge von CPEs wegen Namenskorrektur "veraltet" sind, deutet darauf hin, dass sich während einer Verwundbarkeitsanalyse eine inkorrekte CPE-ID zu einer Software zuweisen ließe. Wie Abbildung 5 zeigt, gibt es einen Zeitraum, in dem die Zuordnung einer falschen CPE zu einer Software stattfinden kann. Wenn das nicht berücksichtigt wird, könnte die CVE-Suche einer VA falsche Ergebnisse liefern, da sie auf der zugewiesenen CPE-ID basiert.

Synchronisation zwischen der CPE-Dictionary und den CVE-Feeds
Zum Zeitpunkt der Evaluierung gab es in den CVE-Feeds 130.036 CPE-IDs, die nicht in der CPE-Dictionary waren. Die Autoren haben folgende Gründe dafür festgestellt:
- Die Versionen einiger IT-Produkte wurden noch nicht in der CPE-Dictionary eingetragen. Ein Beispiel hierfür ist die Version 3.5 des Produkts Red Hat Enterprise Virtualization. Es gibt keinen CPE-Eintrag in der CPE-Dictionary, obwohl dieses Release verwundbar ist und eine CPE dafür in den CVE-Feeds existiert (s. CVE-2008-3522).
- Eine CPE-ID wird aus einer Menge von Attributen wie Name, Version oder Update erzeugt (s. CPE-Benennungsspezifikation). In den CVE-Feeds gibt es CPE-IDs, die nicht in der CPE-Dictionary sind, weil unterschiedliche Werte für diese Attribute verwendet wurden. Im nachfolgend aufgeführten Beispiel wurde in der CPE-ID innerhalb der CPE-Dictionary der Wert "beta2" auf das Attribut "Update" gesetzt. Andererseits hatte man in den CVE-Feeds den String "beta2" mit der Version des Produkts ("1.2.0_beta2") konkateniert. Daraus ergeben sich zwei unterschiedliche CPE-IDs für das gleiche Produkt:
CPE-ID in der CPE-Dictionary: cpe:/a:digium:asterisk:1.2.0:beta2
CPE-ID in der CVE-Feeds: cpe:/a:digium:asterisk:1.2.0_beta2
- Es gibt IT-Produkte ohne CPE-Eintrag in der CPE-Dictionary. Zum Beispiel hat der Microsoft Search Server noch keinen Eintrag. Es gibt jedoch eine Sicherheitslücke (CVE-2008-4032), die die Version 2008 (x32- und x64-Architektur) der Software betrifft.
Die beschriebenen Punkte zeigen, dass keine Synchronisierung zwischen der CPE-Dictionary und den CVE-Feeds besteht, obwohl dieselbe Organisation beide Datenbanken betreibt. Für die Implementierung einer Verwundbarkeitsanalyse (wie in Abb. 3 skizziert) ist dieser Aspekt in Betracht zu ziehen, da die Ergebnisse stark vom Zusammenhang zwischen beiden Datenbanken abhängen.
Vorgehen und Empfehlungen beim Durchführen einer VA
Grundsätzlich sind für die Implementierung einer Verwundbarkeitsanalyse die Ergebnisse der oben vorgestellten Evaluierung zu berücksichtigen. Außerdem ist es empfehlenswert, für die Phasen (CPE-Zuweisung und CVE-Suche) einer VA die folgenden Punkte zu beachten:
CPE-Zuweisung
Die Zuweisung einer CPE-ID zu einem Softwareprodukt sollte nicht vollautomatisch erfolgen. Anhand von Daten wie Vendor, Produkt oder Version, die die Inventardatenbank zur Verfügung stellt (s. Abb. 3), sollten passende CPE-ID-Kandidaten für eine Software in der CPE-Dictionary gesucht werden. Im nächsten Schritt wählt man mit der vorhandenen Selektion die CPE-ID für das jeweilige Produkt aus.
Es ist wahrscheinlich, dass keine 100-prozentigen Übereinstimmungen mit den Informationen zu einem Softwareprodukt vorhanden sind. In dem Fall sollte die VA-Implementierung die Möglichkeit bieten, eine CPE-ID anzupassen. Darüber hinaus muss man sich während der Implementierung, bei der Anpassung oder Erzeugung einer CPE-ID, an die CPE-Spezifikation halten.
CVE-Suche
Da dieselbe Institution (NVD) CPE-Dictionary und CVE-Feeds verwaltet, könnte man meinen, dass die CPEs, die in der CVE-Feeds sind, eine Teilmenge der CVE-Dictionary sind. Wie die Evaluierung zeigt, ist diese Annahme nicht korrekt. Deshalb sollten nicht nur exakte Übereinstimmungen der CPE-ID einer Software in den CVE-Feeds gesucht werden, sondern auch ähnliche CPEs.
Die Ähnlichkeit zwischen zwei CPEs lässt sich anhand von Attributen wie Vendor einer CPE-ID bewerten. Das bedeutet, dass die Attribute der CPE-ID einer Software mit den Attributen der CPEs eines CVE-Eintrags abgeglichen werden. Welche Attribute eine CPE enthält, ist in der CPE-Spezifikation definiert.
Die CPE-ID muss nicht das einzige Element sein, um CVEs für ein Softwareprodukt in den CVE-Feeds zu suchen. Wie im Abschnitt zur Evaluierung erwähnt, gibt es CVE-Einträge ohne CPE. In diesen Fällen lässt sich die CVE-Suche mit dem Element "summary" (s. Abb. 2) durchführen. Hier werden Informationen wie Vendor, Produkt oder Version einer Software gegen den Text des "summary"-Elements abgeglichen.
Fazit
Sicherheitslücken in Softwareprodukten können Cyber-Angriffe gegen Unternehmen ermöglichen. Deswegen müssen Unternehmen ständig nach Verwundbarkeiten in den installierten Softwareprodukten suchen. Dieser Prozess wird als Verwundbarkeitsanalyse (VA) bezeichnet. Der Artikel hat zusammengefasst, wie sich eine VA anhand der CPE-Dictionary und der CVE-Feeds realisieren lässt (s. Abb. 3). Die beiden Datenbanken sind öffentlich verfügbar und miteinander kompatibel, was einen großen Vorteil für die Implementierung einer Verwundbarkeitsanalyse darstellt.
Um falsche Ergebnisse einer VA zu vermeiden, sind jedoch einige Aspekte dieser Datenbanken zu berücksichtigen. Beispielsweise besteht keine Synchronisierung zwischen beiden Datenbanken. Wenn diese Nachteile sorgfältig analysiert werden, lassen sich Verwundbarkeitsanalysen einfach, effektiv und kostengünstig implementieren. Die Autoren geben auch Empfehlungen, wie man mit diesen Problemen umgehen kann. Es gibt ein Tool auf Gitlab, das diese Empfehlungen implementiert und die Nachteile der CPE-Dictionary und CVE-Feeds berücksichtigt.
Luis Alberto Benthin Sanguino
ist bei der adesso AG in der Line of Business Automotive DEV am Standort München tätig. Er befasst sich mit Themen im Bereich IT-Sicherheit – insbesondere Verwundbarkeitsanalyse, Penetrationstests und Analyse bösartiger Webseiten.
Martin März
beschäftigt sich schwerpunktmäßig mit der Beratung zur IT- und Informationssicherheit und ist bei der adesso AG in den Bereichen Public und Finance tätig. Die Leistung seiner Beratung erstreckt sich von der Planung, Umsetzung und Aufrechterhaltung von Informationssicherheitsmanagementsystemen
(ISMS) nach ISO 27001 bis hin zum Erstellen von Sicherheitskonzepten nach dem BSI-Grundschutz.
(ane)
