

Mit allen Sinnen
Multimodale KIs kombinieren Bild und Text
Kaum hat sich der Mensch an Text- und Bildgeneratoren gewöhnt, veröffentlichen OpenAI, Google, Microsoft und Meta ihre multimodalen Modelle, die beide Welten vereinen. Das ermöglicht praktischen KI-Anwendungen und sogar Robotern ein umfassenderes Verständnis der Welt.
Sprach-KIs wie ChatGPT sind nicht nur wahre Formulierungskünstler. Immer wieder überraschen sie mit ihrem Wissen und fast intellektuell wirkenden Fähigkeiten. Doch ihr Weltwissen gewannen sie lange Zeit nur aus Texten, also dem geschriebenen Wort. Fragen und Anweisungen nahmen sie lediglich in Schriftform entgegen und Antworten gaben sie ebenfalls nur als Text. Ganz anders der Mensch: Er sieht, hört, fühlt, schmeckt, spricht und interagiert mit seiner Umwelt auf vielfältige Weise. Sein Wissen über Natur, Kunst und Technik hat er sich nicht nur angelesen, sondern vieles auch mit seinen Sinnen erfahren.
Die heiße Herdplatte, auf die man versehentlich mit der Hand gefasst hat, oder das sprichwörtliche Begreifen von Bällen beim Jonglieren bleiben einem nicht nur lange im Gedächtnis. Sie sind auch der beste anschauliche Unterricht in Physik, den man sich vorstellen kann. Der Mensch verarbeitet also Signale aus diversen Quellen und kann das Ergebnis auf unterschiedliche Arten ausgeben. Die Wissenschaft bezeichnet das als Multimodalität – und genau diese Fähigkeit gilt als wichtige Weiterentwicklung der Chatbots von OpenAI, Google, Meta und Co. auf dem Weg zu einer generellen künstlichen Intelligenz.
GPT-4V und das darauf aufsetzende ChatGPT können mittlerweile schon Bilder interpretieren. Google wiederum kontert mit seinem von Grund auf multimodal trainierten Gemini. Es stammt aus der im Jahr 2014 übernommenen britischen KI-Schmiede DeepMind. Deren bahnbrechende Entwicklungen wie AlphaGo, AlphaZero und AlphaFold, kombiniert mit den Sprach- und Bild-KI-Meilensteinen aus Googles eigenen Laboren (BERT, FLAN, PaLM, MoE et cetera), sicherten dem Konzern lange Zeit die technologische Spitzenposition in der KI-Forschung. Das änderte sich, als OpenAI seinen ChatGPT-Coup landete und die etablierten Player wie Google und Meta unter Zugzwang setzte: so stark, dass Google sich genötigt sah, die Gemini-Ergebnisse werbewirksam mit einem Video in Szene zu setzen.
Dass dieses die wahren Fähigkeiten des multimodalen Modells wohl mehr als beschönigt darstellte, bescherte dem Konzern einen veritablen Shitstorm. Auch im zugehörigen technischen Whitepaper hat Google den Pfad der Tugend verlassen. Anders als in früheren Aufsätzen nannte der Konzern weder die nötigen technischen Details, um die Arbeit wissenschaftlich nachvollziehen zu können, noch verglich er die Ergebnisse fair mit existierenden Modellen. Trotzdem zeigt das Gemini-Video sehr gut, wohin die Reise geht. Aber eins nach dem anderen.
Gemeinsames Training
Im Laufe der Entwicklung von Deep-Learning-Verfahren, der Technik hinter dem KI-Hype, war es zunächst nötig, dass Menschen komplexe Aufgaben in kleinere Teile zerlegten, um erfolgreich ein stabiles Netz zu trainieren. Als sie die Basics im Griff hatten, machten sich Forscher daran, komplexere Aufgaben mit einem einzigen Netz zu erledigen. Am Beispiel eines Sprachassistenten lässt sich das gut veranschaulichen, siehe Grafik unten.

Ein Sprachassistent besteht aus den drei großen Blöcken Spracherkennung (ASR, Automatic Speech Recognition), Textverständnis (NLU, Natural Language Understanding) und Sprachsynthese (TTS, Text-to-Speech). Um diese zu beherrschen, wurde jede Aufgabe zunächst weiter unterteilt: die Spracherkennung etwa in eine Übersetzung von Audio zu Zeichen und eine zweite Stufe, die aus den Zeichen orthografisch korrekte Wörter und Sätze bildet. Ähnlich läuft es bei der Sprachsynthese, die zuerst aus dem Text sogenannte Mel-Spektrogramme erzeugt, bevor die eigentliche Audiodatei generiert wird. Mel-Spektrogramme sind kompakte Repräsentationen von Frequenzen und Sprachenergie über die Zeit.
Mittlerweile dominieren jedoch Ende-zu-Ende-trainierte Modelle, die Spracherkennung und Sprachsynthese jeweils in einem Schritt erledigen. Unter dem Stichwort „Spoken Language Understanding“ werden sogar die ersten vier der in unserer Grafik dargestellten Schritte zusammen in einem Modell gelöst. Bei der Audio-to-Audio-Translation (A2AT) wiederum geht es darum, mit nur einem Modell das gesprochene Wort von der einen in die andere Sprache zu übersetzen.
Dazu werden vortrainierte Bausteine zu einem großen Ganzen zusammengefügt und mithilfe passender Datensätze weiter optimiert (Finetuning). Bei der Audio-to-Audio-Tranlation funktionierte diese Methode bisher aber noch nicht zufriedenstellend. Doch nun hat Meta mit SeamlessM4T ein Modell veröffentlicht, das gut genug für Alltagsanwendungen zu sein scheint – ein weiterer Schritt in Richtung des ersehnten Babelfisches, der Anhalter dereinst durch die Galaxis begleiten wird.
Nach dem gleichen Prinzip lassen sich auch multimodale Modelle bauen. Eine Modalität bezieht sich auf die Eingabe- beziehungsweise Ausgabedaten. Text, Audio und Bild sind die bekanntesten Modalitäten. Für Anwendungen wie etwa das autonome Fahren sind aber auch LiDAR- und Radardaten wichtige Modalitäten. Sie werden zum Beispiel in Form von 3D-Punktwolken verarbeitet. Dazu kommen gegebenenfalls Tiefeninformationen und Daten von IMUs (Inertial Measurement Unit für Beschleunigungswerte im Raum). Diese benötigt man unter anderem bei der Verarbeitung egozentrischer Videos für VR und Robotik.
Die derzeit populärste und anschaulichste Aufgabenstellung für multimodale Modelle ist das Visual Question Answering (VQA). Dabei wird ein Bild zusammen mit einer Frage ins neuronale Netz gefüttert, die sich auf den Inhalt des Bildes bezieht. Die Antwort muss das Netz als Text formulieren, siehe nachfolgendes Bild.

Nach dem gleichen Muster funktionieren Fragen zu Audiodateien. Sie beziehen sich meistens auf Laute, zum Beispiel: „Welches Tier macht diese Geräusche?“ oder „Welches Instrument spielt die Musik?“ Darauf trainierte Modelle verwendet zum Beispiel YouTube, wenn in der automatischen Untertitelung „Applaus“, „sanfte Musik“ oder „Gelächter“ erscheint, wenn gerade nicht gesprochen wird. Doch solche simplen Audio- oder Bildbeschreibungen gelten in der Regel nicht als multimodal. Nur wenn man beliebige inhaltliche Fragen stellen kann, die über Objekterkennung hinausgehen, ist eindeutig multimodale KI gefragt. Ein Stück weit bedeutet multimodal also auch: universeller einsetzbar. Wie knifflig es ist, den Begriff eindeutig zu definieren, lesen Sie im folgenden Kasten.
Auch für Bildgeneratoren gibt es differenzierte Kriterien, ab wann sie als multimodal gelten. Bilderzeugung etwa mit Stable Diffusion, Midjourney, Dall-E und anderen fällt gemäß der Definition dann unter Multimodalität, wenn sich die Eingabe nicht auf ein Textprompt beschränkt. Zusätzlich muss zumindest auch ein Bild als Vorlage ins Spiel kommen (Img2Img), oder die Pose eines Menschen dient als Vorlage für den nächsten Bildaufbau (ControlNet). Im Folgenden berücksichtigen wir nur fortgeschrittene Varianten von Bilderzeugern, die Bilder ähnlich wie ein klassischer Editor detailliert bearbeiten, montieren oder verfremden (zum Beispiel Emu Edit von Meta, siehe Tabelle „Multimodale Bildgeneratoren und -editoren“).
Multitalente für Büro, Logistik und Alltag
Wenn KIs Fragen zu Audio-, Bild- und Videoinhalten beantworten können, kommt das vor allem Büroangestellten zugute. Unternehmen und Universitäten forschen aber auch intensiv daran, wie sie mit multimodalen Modellen das autonome Fahren sowie die Robotik voranbringen können. Denn Roboter, die eng mit Menschen zusammenarbeiten, müssen nicht nur ihre Umgebung visuell wahrnehmen und interpretieren, sondern auch schriftliche oder mündliche Anweisungen von Menschen ausführen.
Erste Einsatzgebiete sehen Experten momentan in der Logistik oder im Privathaushalt. Dazu trainieren Roboter fleißig mit Kisten voller Gegenstände, um treffsicher einzelne herauszugreifen oder nach Ähnlichkeit zu sortieren. Auch wenn sie eine Dose Cola aus dem Kühlschrank holen sollen, profitieren Roboter vom umfangreichen Weltwissen der aktuellen Sprachmodelle (Large Language Model, LLM): Dieses befähigt sie, die Zielvorgabe des Menschen zu verstehen und in ausführbare Pläne zu übersetzen. Die relativ knappe Anweisung das Kaltgetränk zu holen, muss die Maschine also übersetzen in
- in die Küche gehen (oder fahren)
- Kühlschrank lokalisieren
- zum Kühlschrank gehen
- Kühlschranktür öffnen
- gewünschtes Getränk im Kühlschrank finden
- Getränk nehmen
- Kühlschranktür schließen
- zum Auftraggeber gehen
- Getränk übergeben
Stößt der Roboter dabei auf ein Hindernis, muss das integrierte LLM den Plan abändern und zum Beispiel „(1a) Küchentür öffnen“ als neue Aufgabe einfügen.
Der Google Assistant, der mit Google Lens zusammenwächst, bringt multimodale Modelle bereits aufs Smartphone. Dort dient er als Dolmetscher und liefert Informationen zu Fotos, Videos, Musik oder zur Umgebung. Darüber hinaus gibt es unzählige weitere Beispiele dafür, wie ein solcher Assistent als Vorstufe zu genereller KI in Zukunft sinnvoll eingesetzt werden könnte. Stellen Sie sich vor, ein Schüler oder Student macht ein Foto seiner Mitschrift aus dem Unterricht oder einer Übungsaufgabe, die eine Skizze enthält, und möchte eine Erklärung dazu haben. Personalisierte KI-Lerntutoren könnten Schritt für Schritt beim Lösen der Aufgabe helfen sowie den Stoff individuell und ans jeweilige Wissen angepasst erläutern. Oder was wäre, wenn der Chatbot die Handbücher technischer Geräte studieren und Fragen zur Inbetriebnahme oder Wartung direkt mit Text und hilfreicher Illustration beantworten würde? Dieses Szenario wird gerade an der Hochschule Hof im Teilvorhaben „Speaking Manual“ des Technologietransferprojekts „Multimodale Mensch-Maschine-Schnittstelle mit KI“ erarbeitet.
Zentralgestirn LLM
Da LLMs schon erstaunlich viel des dafür benötigten Wissens verinnerlicht haben, werden die meisten multimodalen Modelle um diese Textgeneratoren herum aufgebaut. Auch OpenAI hat sein Basis-LLM GPT-4 kürzlich um Bildverständnis erweitert. Einige Forscher bezeichnen solche Konstrukte deshalb als MLLMs und sehen diese als weiteren wichtigen Schritt auf dem Weg zu genereller künstlicher Intelligenz (Artificial General Intelligence, AGI).
Um ihre multimodalen Experimente handhabbar zu gestalten, arbeiten viele Entwickler bisher noch mit eher kleineren Sprachmodellen, etwa mit der 7- oder maximal mit der 13-Milliarden-Parameter-Variante des LLaMA-Ablegers Vicuna. Das wird vermutlich auch erst mal so bleiben, da vor allem im Forschungs- und Open-Source-Bereich der Trend zu mittelgroßen Sprachmodellen mit höchstens 35 Milliarden Parametern geht. Das Englisch-Chinesische Modell Yi mit 34 Milliarden Parametern setzte sich erst kürzlich an die Spitze der Benchmark-Plattform Huggingface LLM-Leaderboards, auf der sich Sprachmodelle in einer Reihe von standardisierten Testszenarien messen. Im Februar 2024 erschien nun mit LLaVA 1.6 34B ein multimodales Modell auf Basis von Yi. Allerdings kann man bislang noch keine verlässliche Aussage über dessen Performance treffen.
Für die Interpretation von Bildern wiederum benötigt man ein eigenes, darauf spezialisiertes Foundation-Modell. Häufig dient dazu eine ViT-Variante, also ein Vision Transformer. Die Transformer-Architektur hat das Textverstehen revolutioniert, eroberte aber nach und nach quasi alle Modalitäten und wird in unterschiedlichen Varianten sowohl bei Bildern als auch bei Audiodaten sehr erfolgreich eingesetzt: zum Beispiel der Conformer, ein um Convolution-Schichten ergänzter Transformer für Spracherkennung. Der Vision Transformer kommt üblicherweise mit 1 bis 2 Milliarden Parametern aus, in seltenen Fällen hat er auch deutlich mehr.
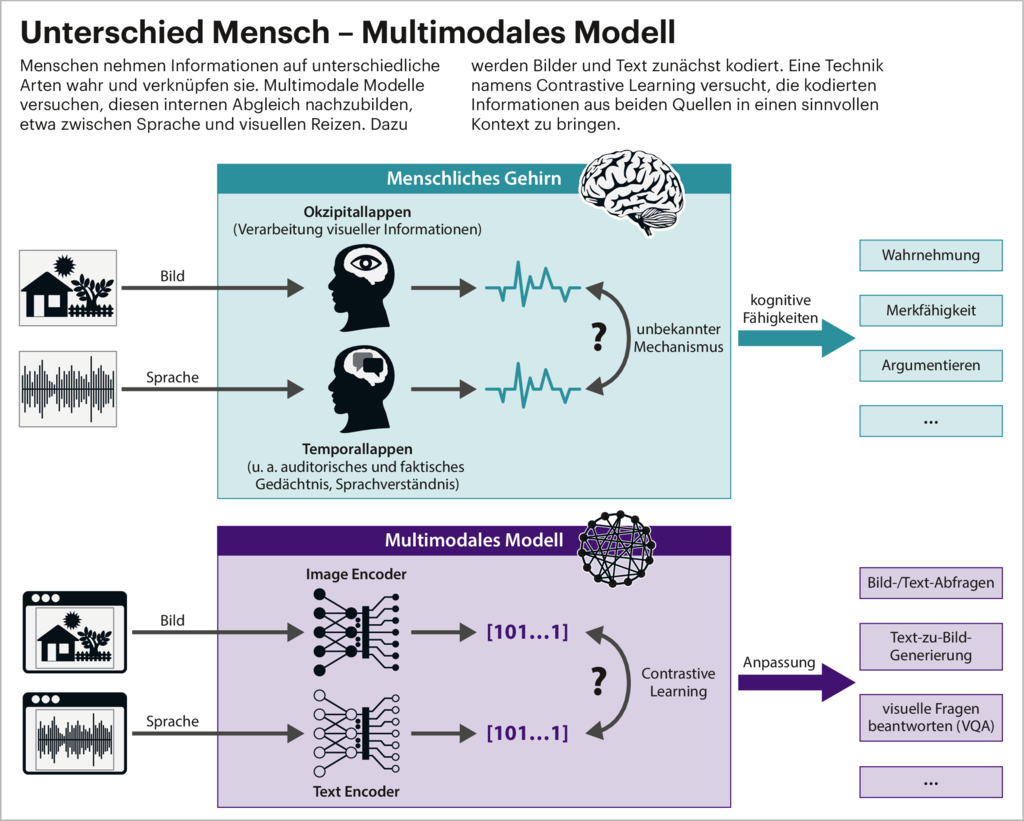
Das LLM und der Vision Transformer werden häufig eingefroren, sodass sich ihre Parameter durch weiteres Training nicht mehr verändern. Trainierbar sind nur die neuen Neuronenschichten, die zur Verbindung der beiden vortrainierten Foundation-Modelle dienen. Dieses kombinierte Training ist meist nochmals zweigeteilt. Zunächst geht es um das sogenannte Image-Text-Aligning, also das Zuordnen von Bildteilen zu Wörtern. Danach lernen die Modelle, damit möglichst vielfältige Aufgaben zu lösen, die ihnen ein Mensch stellen könnte (Instruction Tuning).
Foundation-Modelle besitzen durch ihr Training eine innere Repräsentation der Eingabedaten im sogenannten Latent Space. Das ist ein riesiger Vektorraum, in dem die kodierten Informationen vor allem gemäß ihrer Bedeutung sortiert sind. Bei den großen Sprachmodellen liegen semantisch zusammengehörende Begriffe nah beieinander, etwa „Hund“ und „bellen“. Bei einem Bildgenerator wiederum wären die entsprechenden (kodierten) Fotos oder Ausschnitte benachbart. Das Image-Text-Aligning gleicht die verschiedenen Latent-Spaces von Bild- und Sprachmodell aneinander an. Prominenter Pionier dieses Verfahrens war der Text-Bild-Transfomer CLIP von OpenAI, der immer noch Bestandteil einiger multimodaler Modelle ist.
Auch wenn Vergleiche von KI mit dem Menschen immer gefährlich sind, gibt es hier rudimentäre Gemeinsamkeiten mit unserem internen Weltmodell. Wurden Sie schon mal nach der Übersetzung eines Wortes in einer Fremdsprache gefragt und Sie hatten das Gefühl, die Wortbedeutung relativ gut erklären zu können, aber Ihnen ist trotzdem die exakte Übersetzung nicht eingefallen? Dabei haben Sie ihren eigenen Latent Space erkundet.

Auf das Aligning folgt das Instruction Tuning, das die Modelle zu Generalisten ausbildet, sprich: Es bewirkt, dass die multimodalen Modelle in möglichst vielen Disziplinen punkten. Anhand typischer Beispiele lernen sie etwa, die Farbe eines Kleidungsstücks zu benennen oder die abgebildete Aktivität auszugeben. Ziel dieses Instruction Tunings ist, dass das MLLM fortan auch zu Problemstellungen, die es nicht aus den Trainingsdaten kennt, eine korrekte, zufriedenstellende Lösung präsentieren kann.
Experimentelle Architekturen
Zwar mischen die üblichen Verdächtigen aus der Deep-Learning-Szene wie Google, Microsoft, OpenAI und Meta auch bei multimodaler KI mit, aber als Vorreiter in Sachen Visual Question Answering tut sich derzeit ein nicht einschlägig für KI bekanntes Unternehmen hervor: Salesforce mit seinen BLIP-Modellen (Bootstrapping Language-Image Pre-training). Die Reihe umfasst BLIP, BLIP2 und InstructBLIP.
Das Besondere an BLIP war, wie die Entwickler die trainierbare Verbindung zwischen dem eingefrorenen Vision Transformer und dem LLM konstruierten. Sie schufen ein Gebilde namens Q-Former (Querying Transformer) beziehungsweise einen neuartigen Mechanismus namens Querying Attention. Dieser Mechanismus befähigte das Modell, die vom Vision Transformer kodierten Bilddaten effektiv zu verarbeiten. Dazu generiert der Q-Former für jedes Bild-Text-Paar spezifische, maßgeschneiderte Abfragen. Sie dienen dazu, die für die Beantwortung einer Frage relevanten visuellen Merkmale aus dem vom ViT kodierten Bild zu extrahieren. Speist man zum Beispiel ein Bild von einer Katze mit Sonnenbrille ein und möchte wissen, was die Katze auf der Nase hat, so wird der Q-Former Queries generieren, die vor allem Objekte erkennen und lokalisieren. Fragt man hingegen nach der abgebildeten Katzenrasse, so müssen die Queries eher auf Felltextur und -farbe sowie die typischen Formen von Nase oder Ohren zielen, Details dazu siehe Grafik unten.

Einen Meilenstein im sogenannten Few-Shot-Learning hatte zuvor bereits DeepMind mit Flamingo gesetzt. Beim Few-Shot-Learning gibt der Nutzer ein paar Beispielfragen mit richtigen Antworten vor: zum Beispiel Bilder mit handgeschriebenen Rechenaufgaben, flankiert von der Lösung in Textform. Anschließend muss die KI eine weitere Aufgabe nach diesem Schema lösen. Das kann sie nur, wenn sie aus den Beispielen ableitet, dass sie die Informationen auf dem Bild per OCR (Optical Character Recognition, Zeichenerkennung) und Handschrifterkennung in maschinenlesbaren Text umwandeln soll und dass es sich um einen mathematischen Term handelt, den sie berechnen muss. Auf noch bessere Fähigkeiten zum Generalisieren (Zero-Shot-Learning) zielten Microsoft-Forscher mit ihrem im April 2023 veröffentlichten LLaVA. Beherrscht ein Modell das Zero-Shot-Lernen, dann muss sich der Nutzer keine Beispiele mehr ausdenken, sondern kann der KI einfach beliebige Aufgaben stellen, die sie zuvor nicht explizit trainiert hat.

Alle genannten Modelle haben einen Vision Encoder und ein LLM als Bestandteile, führen diese aber auf unterschiedliche Arten zusammen, siehe Grafik oben. DeepMinds Flamingo zum Beispiel friert zwar das LLM ein, erweitert aber die bestehenden LLM-Schichten mit sogenannten Attention-Blöcken um zusätzliche Cross-Attention-Schichten. Das sind Aufmerksamkeitsmechanismen, die den Fokus auf relevante Bildbereiche und Wörter lenken. Hier lernen sie, welche Bildbereiche für eine Frage relevant sind. BLIP hingegen lässt das LLM komplett unangetastet. LLaVA wiederum hält das LLM nur während des Pretrainings eingefroren und erlaubt während des Finetunings Updates aller LLM-Gewichte.
Was das Übersetzen der kodierten Bild- in Text-Repräsentationen angeht, verwenden die Modelle ebenfalls unterschiedliche Arten von Projektionen. Während LLaVA mit einem einfachen Feed-Forward-Netzwerk arbeitet (Details siehe Grafik oben) greifen BLIP und Flamingo auf ausgefeiltere Netzwerkarchitekturen für diese Übersetzungsschicht zurück. BLIVA versucht, das Beste aus beiden Ansätzen zu vereinen und nutzt zwei verschiedene Wege als Eingabe für das LLM. Wie genau sich die verschiedenen Herangehensweisen und Architekturen auf die Fähigkeiten der Modelle auswirken, lässt sich nur schwer beurteilen. Die Entwicklung steht erst am Anfang und vergleichende Studien fehlen bislang. Die grundlegende Funktionsweise künstlicher neuronaler Netze erklären wir ab Seite 22.
| Multimodale Bild-Text-Modelle (MLLMs) | |||
| Hersteller und Modell | Veröffentlichungsdatum | Image Encoder und LLM | Beschreibung |
| DeepMind Flamingo | 04/2022 |
Normalizer-free ResNet F6 Chinchilla 70B(1.4B, 7B) | Flamingo kann als der GPT-3-Moment der multimodalen Modelle angesehen werden, weil es gute Ergebnisse bei Zero-Shot-Aufgaben gezeigt hat. Es kann also von seinen Trainingsdaten zu Aufgaben generalisieren, auf die es vorher nie trainiert wurde. |
|
Salesforce BLIP BLIP2 InstructBLIP |
02/2022 01/2023 06/2023 |
ViT-G (EVA-CLIP) Flan T5 XXL | InstructBLIP überträgt das Instruction-Tuning-Prinzip von FLAN-T5 auf multimodale Modelle und macht damit einen deutlichen Sprung bei der Generalisierung von Trainings- zu Testdaten. |
|
Microsoft LLaVA LLaVA v1.5 LLaVA v1.6 |
04/2023 12/2023 02/2024 |
CLIP ViT-L LLaMA 7B / 13B Mistral 7B / Yi 34B | Trainingsdaten (instruction-following) wurden von GPT-4 (ohne V) erstellt. Basierend auf existierenden Bildbeschreibungen generiert GPT-4 Fragen mit passenden Antworten. Erreicht 85 % der Genauigkeit von GPT-4V. |
|
Microsoft Kosmos-1 Kosmos-2 Kosmos-2.5 |
02/2023 06/2023 09/2023 | keine vortrainierten Encoder / Decoder | Mit nur 1,6 Milliarden Parametern schlägt Kosmos-1 Flamingo 9B in vielen Aufgaben. Im Vergleich zu einem gleich großen LLM, das mit denselben Daten (nur Text) trainiert wurde, schneidet Kosmos-1 fast identisch ab. Kosmos-1 beherrscht auch OCR und Handschrifterkennung. Kosmos-2 erweitert das Ganze um die Fähigkeit, sich auf einzelne Objekte im Bild zu beziehen und deren Verhältnis zueinander zu verstehen. |
|
Adobe LLaVAR |
06/2023 |
ViT-L/14 (CLIP) Vicuna 13B | Text-rich Image Understanding mit Schwerpunkt OCR. Ähnliche Ausrichtung wie MS Kosmos-2.5, das auf räumliches Textverständnis spezialisiert ist, um Dokumente mit komplexem Layout korrekt zu verstehen. |
|
Tsinghua-Universität CogVLM CogAgent |
11/2023 12/2023 |
EVA2-CLIP-E Vicuna 1.5 7B | Ein hervorragendes Open-Source-VLM ist CogVLM. CogAgent verbessert die Ergebnisse weiter und kann mit großen Bildern umgehen. Erste Tests des Autors bestätigen die hohe Qualität. |
|
Nanyang-Universität Otter OtterHD |
05/2023 11/2023 |
ViT-L/14 (CLIP) LLaMA 1 7B | OtterHD ist das jüngste Modell der Forschungsgruppe. Es verarbeitet Bilder mit höherer Auflösung und ist dabei dank einiger Optimierungen schneller in der Generierung und vor allem beim Training als andere Modelle mit kleinerer Bildauflösung. Es stützt sich auf das multimodale Modell Fuyu des Start-ups Adept AI, das keinen eigenen Image-Encoder verwendet. |
|
Apple Ferret |
10/2023 |
Vicuna 7B / 13B | Selbst Apple öffnet sich langsam und veröffentlichte kurz hintereinander zwei MLLMs. Ferret ist auf das Verarbeiten von Punkten, Rechtecken und Polygonen für das Markieren von Bildteilen spezialisiert. Das zweite Modell ist der Bildgenerator MGIE, siehe nächste Tabelle |
Jenseits von Text und Sprache
Mittlerweile richten Forscher und Entwickler ihren Fokus auf Systeme, die mehr als nur Text ausgeben oder Bilder anhand von Beschreibungen gestalten. Beispielsweise ist es wünschenswert, dass Image-to-Image-Bildgeneratoren künftig professionelle Montage- und Retuschetechniken beherrschen sowie Hand in Hand mit dem Menschen arbeiten. Gesteuert wird der kreative Prozess durch multimodale Prompts, wie es Microsofts Kosmos-G demonstriert, siehe nachfolgendes Bild.

Auch Meta hat kürzlich ein interessantes Modell namens Emu Edit veröffentlicht, mit dem man gezielt einzelne Teile eines Bildes manipulieren kann, ohne das Gesamtbild zu beeinflussen. Dazu ist ebenfalls ein erweitertes Text-Bild-Verständnis nötig, wie es nur in multimodalen Modellen zu finden ist. Der Vergleich oben zeigt, dass frühere Generatoren wie InstructPix2Pix dazu neigen, Anweisungen nicht auf einzelne Bildbereiche zu beschränken, sondern auf das gesamte Motiv überspringen zu lassen. Meta verwendet daher die Erkenntnisse aus seinem Basismodell Segment Anything (SAM) und trainiert Emu Edit darauf, bestimmte Bildbereiche auszuwählen. So kann der Bildgenerator zum Beispiel die Ohren eines Hasen gezielt anhand einer Textanweisung verformen oder das Tier eine regenbogenfarbige Trompete spielen lassen. Andere Modelle scheitern sichtlich an der räumlichen Zuordnung.

Besonders spannend sind MLLMs, die in unterschiedlichen Disziplinen glänzen: Sie formulieren nicht nur gute Antworten auf Fragen zu einem Bild, sondern editieren die Motive auch feingranular. Auf Wunsch beantworten sie rein sprachliche Anfragen mit Text und Bild. Das von einer chinesischen Forschergruppe entwickelte DreamLLM ist ein Vertreter dieser Kategorie und darf als ein guter Schritt in Richtung allgemeine KI verstanden werden. Zukünftig werden sich solche Modelle auch an Benchmarks für die Spezialisten im Bereich Text- und Bildverständnis messen lassen müssen, also anhand von rein textbasierten Fragen wie bei TruthfulQA oder reinen Bildaufgaben ohne Text wie Objekterkennung und semantische Segmentierung. Schließlich ist die Hoffnung, dass sich durch das Lernen aus mehreren Modalitäten das allgemeine Weltverständnis der Modelle verbessert. Momentan sind sie davon noch ein gutes Stück entfernt, aber sie entwickeln sich in enormer Geschwindigkeit, wie man anhand der Daten in den Tabellen erahnen kann.
| Multimodale Bildgeneratoren und -editoren | ||
| Hersteller, Modell | Datum | Beschreibung |
|
Uni Siegen LDEdit |
10/2022 | Eines der ältesten Modelle in dieser Kategorie stammt aus Siegen. Latent Diffusion ist eine Variante des typischen Image Diffusion, die vorteilhaft für das Überarbeiten von Bildern ist. |
|
Alibaba Composer |
02/2023 | Composer ist stark multimodal ausgerichtet, da es außer Fotos und Text auch Tiefeninformationen, Skizzen und Farbhistogramme als Input verarbeitet, um Stil und Bildkomposition festzulegen. |
|
Google Imagen Re-Imagen Imagen Editor |
05/2022 09/2022 04/2023 | Mit Imagen Editor erweitert Google sein Bild-Diffusion-Modell Imagen um feingranulare Editierfähigkeiten. Dazu muss der Nutzer jedoch die gewünschte Region im Bild maskieren, während er sie bei Emu Edit per Textanweisung auswählt. |
|
Meta CM3leon |
09/2023 | CM3Leon gibt es in drei Größen: 350M, 760M und 7B. Das größte Modell übertrifft dabei die Bildgenerierungsqualität von Googles Parti 20B und Re-Imagen 3.6B. Letzteres hat zwar nur halb so viele Parameter, aber rund ein Drittel mehr Trainingsdaten verwendet. Im Vergleich zu Flamingo 9B schlägt sich CM3leon gut in manchen VQA-Tasks, aber nicht in allen. |
|
Tsinghua-Universität DreamLLM 7B |
09/2023 | Das Modell ist insofern bemerkenswert, als es sowohl in VQA als auch bei Bildgenerierungsaufgaben spezialisierte Modelle übertrifft. Zudem kann es Text und Bild vermischt als Ausgabe erzeugen. |
|
Microsoft Kosmos-G |
10/2023 | Kosmos-G kann zwei Bilder in der durch flankierenden Text beschriebenen Weise kombinieren. Microsoft interpretiert dabei Bilder wie eine Fremdsprache, die dem Sprachmodell beigebracht werden muss. Mit 1,9 Milliarden Parametern erreicht Kosmos-G eine Bildqualität vergleichbar mit OpenAIs DALL-E 2 und besser als Metas Emu 14B. An Googles Imagen 3.4B kommt Kosmos-G qualitativ nicht heran, ist dafür aber flexibler. |
|
Meta Emu Edit |
11/2023 | Emu Edit ist auf Bildgenerierung spezialisiert, verfolgt aber einen ähnlichen Ansatz wie Kosmos-2. Statt mit Objekterkennungsdaten wurde es mit Daten für semantische Segmentierung trainiert. Daher markiert es ausgewählte Objekte nicht nur grob mit Rechtecken, sondern zeichnet die Umrisse detailliert nach. |
|
Apple MGIE |
02/2024 | MGIE benutzt ein LLM, um die Texteingabe umzuformulieren und mit detaillierteren Informationen anzureichern, sodass das generierte Bild besser zu den vermuteten Vorstellungen des Nutzers passt: zum Beispiel Lichtschwert passend zu Star Wars. |
Aufwand und Ertrag
Da die in den multimodalen Modellen eingesetzten Image-Encoder meist schon mit Millionen Bildern vortrainiert wurden, genügen für das multimodale Training relativ kleine Datenmengen (siehe Grafik auf S. 60). LLaVA zeigt, dass man auch mit weniger als einer Million Trainingsbildern gute Ergebnisse erzielen kann. mPlug-OWL dagegen setzt eher auf Masse und verwendet über eine Milliarde Bild-Text-Paare.

Wie in der KI-Forschung seit Jahrzehnten üblich, wird auch die Entwicklung multimodaler Modelle überwiegend von Benchmarks getrieben: also gewissermaßen Prüfungsaufgaben mit zugehörigen Erfolgskriterien (Metriken). Ähnlich wie die großen Sprachmodelle (siehe c’t 26/2023) müssen mittlerweile auch die multimodalen KIs sehr unterschiedliche Aufgaben absolvieren. Dabei durchlaufen sie pro Aufgabenbereich mehrere Benchmarks, um ein umfassendes Bild des Könnens der Modelle zu bekommen.
Da wird zum Beispiel zwischen Bildbeschreibung mit kurzen Antworten oder ausführlichen Antworten unterschieden. In manchen Benchmarks muss das Modell im Bild vorhandenen Text berücksichtigen, etwa auf einem Straßenschild, wozu es OCR beherrschen muss. Wieder andere Benchmarks prüfen, wie gut die Modelle schlussfolgern können. Die Fragen sind dann so konzipiert, dass sie nicht mit den vorhandenen Informationen allein beantwortet werden können, sondern Hintergrundwissen erfordern, zum Beispiel physikalisches Allgemeinwissen.
So lautet eine typische Frage: Was passiert als Nächstes in der Szene, die auf dem Bild zu sehen ist? Dann muss das Modell beispielsweise schlussfolgern, dass ein Ball auf den Boden fallen wird, oder ein Luftballon nach oben steigt, weil er mit Helium gefüllt ist.
In dem sehr umfassenden und anspruchsvollen Benchmark MMMU (Massive Multi-discipline Multimodal Understanding and Reasoning) lösen die besten Modelle knapp 60 Prozent der Aufgaben korrekt: Gemini Ultra schnitt zum Redaktionsschluss (Ende März 2024)mit 59,4 Prozent am besten ab, dicht gefolgt von GPT-4V mit 56,8 Prozent. Das auf dem neuen LLM Yi 34B basierende LLaVA 1.6 ist mit 51,1 % ebenfalls gut im Rennen und zu diesem Zeitpunkt das beste Open-Source-Modell. Es übertrifft sogar Gemini Pro (47,9 %). Menschliche Experten liegen zwischen 76 und 88,6 Prozent.
Atemberaubende Geschwindigkeit
Deep-Learning-Verfahren entwickeln sich in atemberaubendem Tempo. Im Bereich multimodaler Modelle werden die Erfahrungen aus früheren unimodalen Bereichen und insbesondere mit LLMs aufgegriffen und sehr schnell umgesetzt. Das Zusammenspiel aus Parameteranzahl, Datenmenge beziehungsweise -qualität und Trainingsaufwand ist auch hier wieder entscheidend. Aber auch architektonische Verbesserungen und neue Finetuning-Verfahren spielen eine Rolle. Die verschiedenen Kombinationsmöglichkeiten werden in einer solchen Geschwindigkeit ausprobiert, dass selbst Experten Mühe haben, den Überblick zu behalten und all die Variationen einzuschätzen und miteinander zu vergleichen.
Während es vor allem aus Kosten- und Effizienzgründen einen Trend hin zu kleineren Modellen gibt, die mit deutlich weniger Parametern ähnlich gute Ergebnisse wie die großen Vorbilder erzielen, entstehen andererseits auch sehr große Architekturen. Das geschieht vor allem bei den großen Konzernen, die genügend Geld und Ressourcen haben. So hat Google jüngst gezeigt, dass es in der Lage ist, einen Image-Encoder mit 22 Milliarden Parametern zu trainieren, während die größten vorherigen nur 4 Milliarden hatten und die gängige Größe bei 0,4 Milliarden liegt. Ob sich sehr große Vision-Transformer durchsetzen werden oder, wie das einst ehrfürchtig bestaunte multimodale Modell Wu Dao 2.0 mit 1,7 Billionen Parametern, sang- und klanglos in der Bedeutungslosigkeit verschwinden, ist noch nicht absehbar.
Insgesamt arbeiten die derzeit verbreiteten Architekturen aus Bild- und Sprachmodell in vielen Anwendungsgebieten bereits zufriedenstellend. Das interne Wissen der KIs über Zusammenhänge und Gesetzmäßigkeiten scheint sich durch das gemeinsame Bild-Text-Training tatsächlich zu verbessern. Insbesondere aber können Menschen mit solchen Systemen deutlich leichter kommunizieren und interagieren als mit reinen LLMs oder per Textprompt gesteuerten Bildgeneratoren. (atr@ct.de)
Studien und weitere Quellen: ct.de/ymd4