
NVIDIAs Ampere-GPUs
Aufgedreht
Großes Thema der letzten Wochen war NVIDIAs neue GPU-Generation Ampere für HPC und KI.
Als erste GPU mit neuer Ampere-Architektur ließ NVIDIA Mitte Mai die A100 für Supercomputer und aufwendige KI-Berechnungen vom Stapel. Gestiegen ist vor allem die Transistorendichte: Verteilten sich beim in 12 nm gefertigten Vorgänger Volta noch 21,1 Milliarden Transistoren auf 815 mm2, sind es beim Ampere dank 7-nm-Technik 54 Milliarden auf 826 mm2. Allerdings ist NVIDIA bei der tatsächlichen Bestückung erst einmal einen Schritt zurückgegangen.
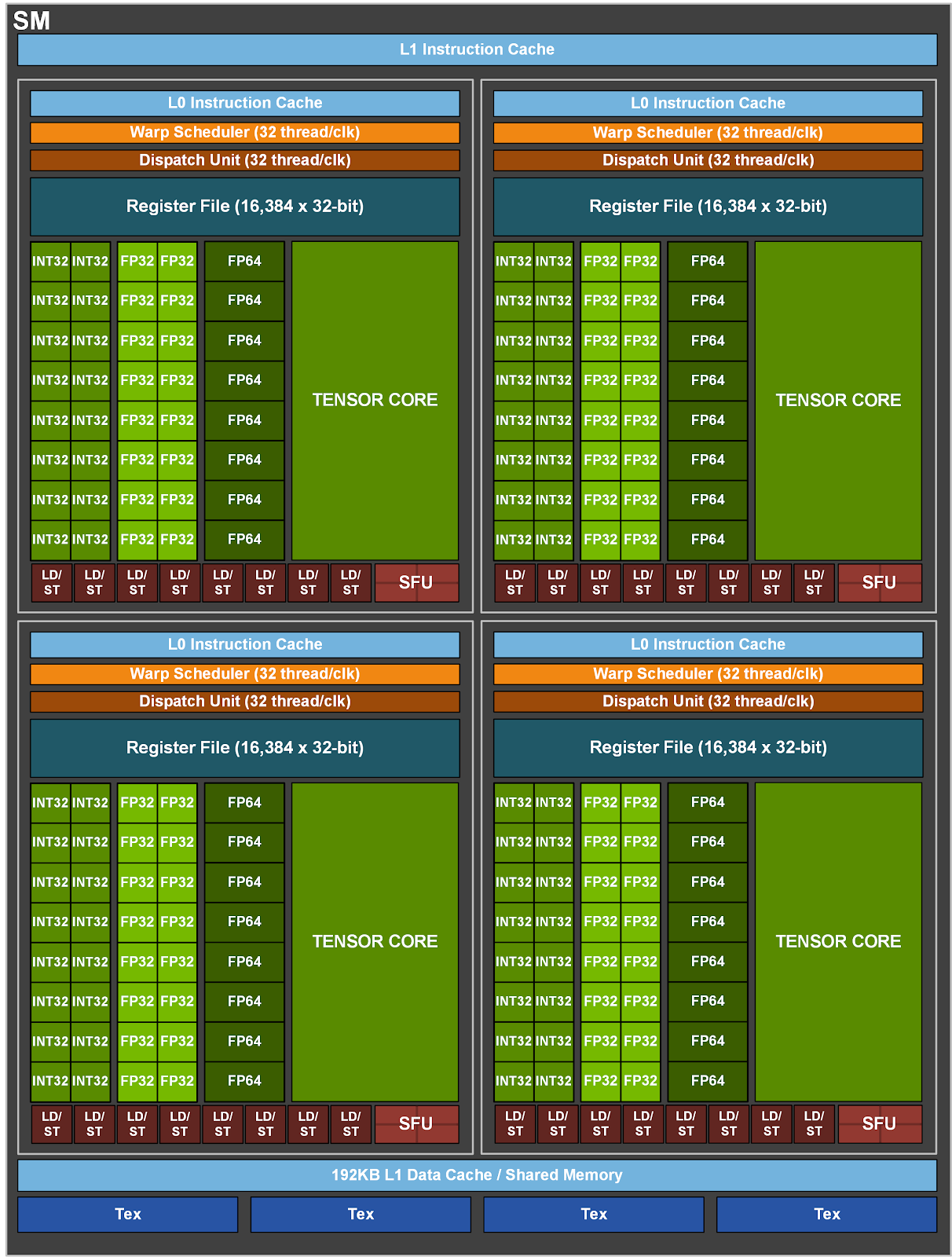
Grundlage der A100 ist die neu entwickelte GA100-Grafikeinheit. Sie fasst statt 80 nun 128 SMs (Streaming- oder Shader-Multiprozessoren). Jeder trägt wie gehabt 64 FP32-Kerne für Floating-Point-Berechnungen mit einfacher Genauigkeit, 32 FP64-Kerne für doppelte Genauigkeit, 64 INT32-Kerne für Integerberechnungen und vier Tensor Cores der nun dritten Generation. Das ergibt 8192 FP32- und INT32-Cores, 4096 FP64-Kerne sowie 512 Tensor Cores – in der Theorie.
Denn A100 bekommt nur 108 SMs, die im GPU Boost Clock mit 1410 MHz laufen. Summa summarum ergibt das 6912 FP32- und INT32-Kerne, 3456 FP64- und 432 Tensor Cores. Zudem steigt die Kapazität des HBM2-Speichers auf 40 GByte bei einem Durchsatz von 1,6 TByte/s. Damit wächst auch der Hunger: 400 statt 300 W verlangt der Accelerator nun.
{kind=link}
{kind=link}
Die Tensor Cores beherrschen erstmals Berechnungen mit doppelter Genauigkeit, wie sie bei Simulationen im HPC häufig vorkommen. Dabei soll der Tensor Core eine Rechenleistung von bis zu 19,5 TFlops Peak erreichen. Für KI-Trainings mit geringeren Anforderungen an die Genauigkeit hat NVIDIA das TensorFloat32-Format TF32 entwickelt, ein auf die Tensor Cores angepasstes 32-Bit-Floating-Point-Format, mit dem 156 TFlops Peak erreicht werden. Der Trick bei diesem Performanceschub: Das Datenformat besteht nur aus 19 Bit – eines für das Vorzeichen, 8 Bit für den Exponenten wie bei FP32 und 10 Bit für die Mantisse wie bei FP16. Damit verfügt es über den Wertebereich von FP32 und die Genauigkeit von FP16.
Weitere erlaubte Datenformate sind BF16 (Binary Floating Point 16 Bit), FP16, INT8 und INT4. Mit der neuen Tensor-Core-Funktion Sparsity will NVIDIA dessen Rechenleistung effektiv verdoppeln. Für die FP64- und FP32-Kerne außerhalb des Tensor Core halbiert NVIDIA die Performancewerte: 9,7 TFlops für FP64, 19,5 TFlops für FP32, 19,5 Tops für INT32, 78 TFlops für FP16 und 39 TFlops für BF16.
Als Multi-Instance-GPU lässt sich jedes A100-Modul in bis zu sieben Instanzen partitionieren. Jede wird isoliert ausgeführt und verfügt über eigene Speicher-, Cache- und Recheneinheiten. NVLink 3.0 arbeitet nun mit 12 Links und 600 GByte/s. Der NVSwitch käme bei 16 GPUs auf einen aggregierten Durchsatz von 9,6 TByte/s.
In den Handel kommen die GPUs aber derzeit nicht einzeln. Vier A100-Module bündelt NVIDIA auf dem Systemboard HGX Redstone für Server mit mindestens 2 U. Dort verbinden sechs NVLinks jede GPU mit jeder anderen. 4 U benötigt die 8-GPU-Version HGX Delta, auf der sechs NVSwitch-Chips die GPUs koppeln.
Als erstes Ampere-Delta-System stellte NVIDIA den 6 U hohen DGX A100 vor mit acht A100-GPUs, zwei 64-Kern-Rome-CPUs von AMD, 1 TByte RAM, 15 TByte auf NVMe-4.0-SSDs und neun Mellanox-NICs ConnectX-6 VPI für HDR-InfiniBand und 200-Gigabit-Ethernet. Als Listenpreis gibt NVIDIA knapp 200000 US-Dollar an.
Da Intels CPUs derzeit noch kein PCIe 4.0 bieten, müssen Supercomputerbauer für eine Xeon-Ampere-Kombination auf Ice Lake SP warten. Derzeit plant das Jülich Supercomputer Centre seinen JUWELS, das Lawrence Berkeley National Laboratory den Perlmutter und die Indiana University den Big Red 200 mit A100.
Das KIT (Karlsruher Institut für Technologie) will mit dieser CPU-GPU-Kombination für über 15 Millionen Euro den FP64-17-PFlops-Rechner HoreKa bauen, die Max-Planck-Gesellschaft in Garching für über 20 Millionen Euro das System Raven mit über 20 PFlops. Beide Supercomputer soll Lenovo Mitte 2021 fertigstellen.
Beide Systeme bekommen eine Wasserkühlung für CPUs, RAM und GPUs sowie Metallrücktüren mit Wasserdurchfluss für die Restwärme. Während die Kaltwasserkühlung in Garching die Effizienz der Hardware erhöht, arbeitet das KIT mit Flüssigkeitstemperaturen von 50 bis 60 °C und damit nachhaltiger. Die Kühlung kostet weniger Energie und heizt im Winter die anliegenden Büros. (sun@ix.de)