Das Linux-Dateisystem Ext4
Ext3, das Standarddateisystem für Linux, ist in die Jahre gekommen. Moderne Massenspeicher kommen seinen Limits immer näher, und die blockbasierte Datenverwaltung wird aktuellen Dateigrößen nicht mehr gerecht.
Erschienen in c't 10/09, S. 180
Angesichts rapide steigender Datenmengen wird immer deutlicher, dass Ext3, das derzeitige Linux-Standarddateisystem, an seine Grenzen stößt. Eine maximale Dateisystem- und damit Volume-Größe von 16 TByte kann in großen RAID-Verbunden schon jetzt zwicken, aber mehr ist mit den 32-bittigen Blocknummern von Ext3 bei Datenblöcken von 4 KByte Größe eben nicht drin. Eine größere Renovierung steht also an.
Die Entwicklung von Ext4 begann 2006 mit zwei Änderungen für das Ext3-Dateisystem, die die Blocknummern auf 48 Bit erweiterten und die bisherige indirekte Blockadressierung, bei der die zu einer Datei gehörenden Datenblöcke in einer langen Liste einzelner Blocknummern gespeichert werden, durch Extents – Bereiche von Datenblöcken – ersetzte. Da sich dabei die auf der Platte gespeicherten Datenstrukturen änderten, entschieden sich die Programmierer, diese Patches nicht in das alte Ext3 einzupflegen, sondern mit Ext4 eine neue Version des Dateisystems auf Basis des Ext3-Codes zu entwickeln.
Herausgekommen ist nach drei Jahren mit Ext4 eine deutliche Weiterentwicklung von Ext3, die das Limit für Volumes auf 1024 PByte und damit auf Jahre in den sicheren Bereich verschiebt. Gleichzeitig machen die Extents – in anderen Dateisystemen wie XFS längst implementiert – die Verwaltung großer Dateien effizienter. Schließlich gibt es eine Reihe interner Änderungen, die die Performance von Ext4 gegenüber Ext3 verbessern sollen.
Die Kernel-Entwickler haben den Ext4-Code in den Kernel 2.6.19 aufgenommen, um ihn dort reifen zu lassen. Bis zur Version 2.6.27 war Ext4 als experimentell markiert, seit Linux 2.6.28 gilt das neue Dateisystem als stabil – was keineswegs ausschließt, dass der Code nicht noch Bugs oder Überraschungen enthalten kann. Das aktuelle Ubuntu 9.04 [1] lässt sich bereits auf Ext4 installieren, das kommende Fedora 11 wird Ext4 bereits als Standarddateisystem verwenden.
Große Volumes
Ext4 arbeitet mit 48-bittigen Blocknummern bei einer Standard-Blockgröße von nach wie vor 4 KByte. Das erlaubt eine Dateisystemgröße von bis zu 248 Blöcken à 4 KByte, also einem Exabyte (1024 PByte) an Stelle der 16 TByte von Ext3. Warum nicht gleich 64-bittige Blocknummern? Die Entwickler nennen in einem Artikel [2] einen ganz pragmatischen Grund: 1 EByte wird auf lange Zeit ausreichen – und schon bei einem Dateisystem dieser Größe würde ein kompletter e2fsck-Lauf (bei der heute verfügbaren Hardware) über 100 Jahre dauern. Bevor man auch nur in die Nähe dieser Grenze kommt, müsse man daher ganz andere Probleme angehen, die viel größere Änderungen im Dateisystem erfordern würden als 64-bittige Blocknummern. Zudem passen die 48-bittigen Blocknummern besser in die alten Ext3-Datenstrukturen.
Laut Ext4-Chefentwickler Ted Ts’o sollte die Erweiterung der Blocknummern auf 64 Bit keine allzu große Sache sein – möglicherweise wird sie bereits im Zuge der Weiterentwicklung von Ext4 angegangen. Einige Strukturen wie der Superblock, die Blockgruppen-Deskriptoren und der zusammen mit Ext4 entwickelte neue Journaling-Layer JBD2 sind bereits auf 64-bittige Blocknummern ausgelegt.
Der in Ext3 32-bittige i_blocks-Wert im Inode, der die Anzahl der von einer Datei belegten Blöcke enthält, wurde gleich in zweierlei Hinsicht an die größeren Blocknummern angepasst: Zum einen zählt er nicht mehr, wie noch in Ext3, in Festplattensektoren von 512 Byte Größe, sondern in der Blockgröße des Dateisystems, also in der Regel 4 KByte. Ein Flag im Inode gibt an, wie der Wert zu interpretieren ist; das ist bei einem Upgrade von Ext3 nach Ext4 wichtig, da dort auch noch alte Ext3-Inodes vorkommen können, die Sektoren zählen.
Zum anderen nutzt man zwei bislang nicht verwendete Bytes im Inode, um die oberen 16 Bits der 48-bittigen Blocknummer zu speichern. Das Dateisystem-Feature huge_file zeigt an, dass das Dateisystem mit 48-bittigen Blocknummern arbeitet und die Inodes in Dateisystemblöcken zählen können. Einzelne Dateien können derzeit allerdings trotz der 48-bittigen Blocknummern nicht größer als 16 TByte werden, da sich mit der aktuellen Struktur der Extents keine größeren Files verwalten lassen – dazu gleich mehr.
Im Vergleich mit den anderen Dateisystemen im Kernel konkurriert Ext4 vor allem mit XFS – IBMs JFS hat bis heute nicht allzu viele Anhänger in der Linux-Welt gefunden, und Reiser 4 ist nach wie vor nicht in den Kernel integriert. Als Vorteile gegenüber XFS führen die Ext4-Entwickler die schlankere Code-Basis an (rund 30.000 Zeilen in 900 KByte versus 100.000 Zeilen in 3,2 MByte), die Möglichkeit, ein Ext3-Dateisystem nach Ext4 zu konvertieren, und der große Anteil Code, den man von dem ausgereiften und gründlich getesteten Ext3 übernommen hat.
| Linux-Dateisysteme | ||
| Dateisystem | maximale Dateigröße | maximale Dateisystemgröße |
| Ext4 | 16 TByte | 1024 PByte |
| Ext3 | 2 TByte | 16 TByte |
| JFS | 4 PByte | 32 PByte |
| ReiserFS 3 | 8 TByte | 16 TByte |
| XFS | 8192 PByte | 8192 PByte |
| ZFS (Solaris) | 16.384 PByte | 16.384 PByte |
Extents
Große Dateien
Die wichtigste interne Verbesserung in Ext4 ist die Verwendung von Extents anstelle der in Ext3 verwendeten indirekten Blockadressierung. Bei letzterer speichert ein Inode die Nummern von maximal zwölf 4-KByte-Blöcken. Ist eine Datei größer als 48 KByte, kommen zunächst indirekt adressierte Blöcke (bis 4 MByte), dann doppelt (bis 4 GByte) und schließlich dreifach indirekt adressierte Blöcke zum Einsatz, bei denen eine Blocknummer im Inode auf einen Block mit Blocknummern verweist, die auf Blöcke mit Blocknummern verweisen, die auf Blöcke mit den Blocknummern der Daten verweisen (Details zu Ext3 finden Sie hier [3]). Dieses klassische Adressierungsschema der Unix-Welt bewährt sich bei kleinen oder sehr stark fragmentierten Dateien sowie bei sparse files, bringt aber bei großen Dateien einen zunehmenden Verwaltungs-Overhead mit sich.
Extent-Datenstruktur
struct ext3_extent {
__u32 ee_block;
/* first logical block
extent covers */
__u16 ee_len;
/* number of blocks
covered by extent */
__u16 ee_start_hi;
/* high 16 bits of
physical block */
__u32 ee_start;
/* low 32 bits of
physical block */
};
Extents: Eine Datenstruktur von 12 Byte verwaltet bis zu 128 MByte Daten.
Extents adressieren keine einzelnen Blöcke, sondern mappen stattdessen einen (möglichst großen) Bereich einer Datei auf einen Bereich zusammenhängender Blöcke auf der Platte. Dazu braucht man statt vieler einzelner Blocknummern nur noch drei Werte: Der Start und die Größe des Bereichs in der Datei (jeweils in Dateisystemblöcken) sowie die Nummer des ersten Datenblocks auf der Platte. Die Datenstruktur eines Extents in Ext4 sieht so aus wie in dem Kasten rechts.
Dabei zählt Ext4 die Blöcke innerhalb einer Datei 32-bittig, was die maximale Größe einer Datei im Ext4-Dateisystem auf 232 4-KByte-Blöcke, also 16 TByte begrenzt. Dieses Limit könnte fallen, wenn das Extent-Format überarbeitet wird: Es gibt bereits Überlegungen, für sparse files und sehr stark fragmentierte Dateien, die sich mit Extents nicht effizient verwalten lassen, ein anderes Format zu verwenden, das wieder mit einzelnen Blocknummern arbeitet. Außerdem denken die Entwickler darüber nach, beschädigte Extents durch zusätzliche Informationen und eine Checksumme erkennen zu können.
Das ist zwar alles noch Zukunftsmusik, aber eine Grundlage dafür ist zumindest schon gelegt: Vor den Extents steht eine Header-Struktur auf der Platte, die auch eine magic number zur Identifizierung und falls nötig Unterscheidung von Extents je nach Typ erlaubt.
Für die Größe eines Extents stehen 15 Bit zur Verfügung, sodass ein Extent nicht größer als 215 4-KByte-Blöcke, also 128 MByte werden kann. Für dieses Limit gibt es einen einfachen Grund: Wie Ext3 unterteilt auch Ext4 die Platte in Blockgruppen von 128 MByte Größe. Da jeder Blockgruppe ein Blockgruppen-Deskriptor und ein Ausschnitt aus der Inode-Bitmap, der Block-Bitmap und der Inode-Tabelle vorangehen, lassen sich nicht mehr als 128 MByte am Stück speichern.
Das übrig gebliebene sechzehnte Bit bei der Extent-Größe speichert, ob der Extent bereits mit Daten beschrieben ist – wenn nein, gibt das Dateisystem beim Lesen der Daten Nullen zurück („unitialized extent flag“). Das ermöglicht es Anwendungen, Plattenplatz vorzubelegen („persistent preallocation“, dazu gleich mehr), eine von mehreren Maßnahmen zur Performance-Steigerung in Ext4, ohne dass dadurch ein Zugriff auf früher in diesem Bereich gespeicherte Daten möglich wird.
Extents bringen vor allem bei großen Dateien und dort speziell bei solchen Operationen Vorteile, die in erster Linie Metadaten-Operationen erfordern, also beim Löschen und Verkürzen von großen Dateien. Das sieht man bereits, wenn man mit dd ein paar große Dateien anlegt und sie dann wieder löscht (siehe Tabelle) – vor allem das Löschen benötigt bei Ext4 nur einen Bruchteil der Zeit.
| Performance bei großen Dateien | |||
| Ext31 | Ext41 | Verbesserung | |
| Anlegen von acht Dateien à 1 GByte | |||
| Zeit | 155,9 s | 145,1 s | 6,9 % |
| Durchsatz beim Schreiben | 55,4 MByte/s | 59,3 MByte/s | 7,0 % |
| Löschen von acht Dateien à 1 GByte | |||
| Zeit | 11,87 s | 0,33 s | 97,2 % |
| 10.000 zufällige Lese- und Schreiboperationen in 8 GByte | |||
| Operationen/s | 80,0 | 88,7 | 10,9 % |
| 1 Mount-Option: noatime; Single User Mode; Dateisystem jeweils frisch gemountet | |||
Extent-Bäume
Ext4 benutzt die 60 Byte im Inode, die Ext3 zum Speichern von 15 32-bittigen Blocknummern verwendet, um dort vier Extents und einen Header-Extent von jeweils 12 Byte Länge abzulegen. Damit lassen sich Dateien bis zu 512 MByte direkt aus dem Inode heraus verwalten. Dabei zeigt sich ein weiterer, ganz praktischer Vorteil der 48-bittigen Blocknummern: Würden sowohl für die Position des Extents in der Datei als auch für den Start-Block auf der Platte 64-Bit-Werte verwendet werden, stiege die Größe eines Extents auf 18 Byte. Da der Extent-Header bereits 12 Byte belegt, könnte man nur noch zwei statt vier Extents im Inode speichern.

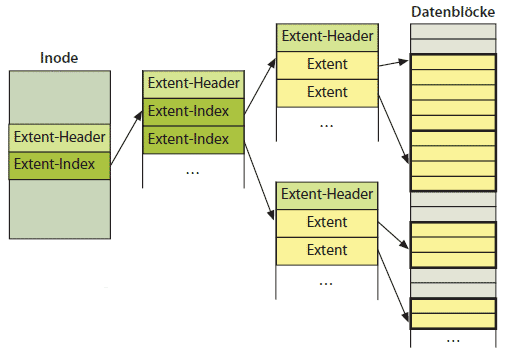
Ist eine Datei größer als 512 MByte, baut Ext4 einen Baum aus Extents auf. Dabei kommt eine weitere Datenstruktur zum Einsatz, der Extent-Index, der lediglich die Startposition des Extents in der Datei und eine Blocknummer auf der Festplatte enthält. In diesem Datenblock können dann entweder Extents stehen, die auf die Daten verweisen, oder erneut Extent-Indexe, wobei jeder Block mit einem Extent-Header beginnt. Der Extent-Baum startet mit einem Extent-Index im Inode.
Extents packen zwei Probleme von Ext3 an: Sie verringern den Verwaltungs-Overhead bei großen Dateien – eine 500-MByte-Datei lässt sich mit vier Extents à 12 Byte im Inode effizienter verwalten als mit einem halben Megabyte über die Platte verstreuter 32-bittiger Blocknummern – und können die Fragmentierung des Dateisystems verhindern. Dazu haben die Entwickler einige neue Mechanismen implementiert.
Einer davon ist die bereits angesprochene „persistent preallocation“. Mit dem Systemaufruf fallocate() kann eine Anwendung für eine Datei eine bestimmte Menge Speicher reservieren und das Dateisystem so darüber informieren, wie groß die Datei werden wird. Hilfreich ist das vor allem, wenn eine Datei langsam wächst oder wenn sie nicht sequenziell geschrieben wird, wie es beispielsweise Tauschbörsen-Clients machen.
Dank der „persistent preallocation“ kann Ext4 gleich ausreichend Platz in möglichst zusammenhängenden Bereichen auf der Platte reservieren. Erfreulicher Nebeneffekt für die Anwendung: Das tatsächliche Schreiben der Daten kann nicht mehr wegen Speicherplatzmangel fehlschlagen. Die Glibc stellt fallocate() derzeit noch nicht zur Verfügung; Anwendungen müssen die Funktion entweder per syscall() aufrufen oder posix_fallocate() verwenden. Das bereits erwähnte sechzehnte Bit in der Größenangabe eines Extents speichert, ob ein Extent voralloziert, aber noch nicht mit Daten beschrieben ist.
Weitere Optimierungen
Kaputt optimiert?
Weitere Optimierungen im Dateisystem sorgen dafür, dass Ext4 Dateien auch unabhängig von der „persistent preallocation“ möglichst am Stück speichert. Schreibzugriffe werden zunächst gepuffert, sodass der Block Allocator, der in Ext3 und Ext4 Datenblöcke für Schreiboperationen reserviert, nicht mehr für jeden 4-KByte-Block Daten sofort aufgerufen werden muss („delayed allocation“), sondern mehrere Blöcke auf einmal allozieren kann. Dadurch lassen sich bei größeren Schreibzugriffen viele Blöcke auf einmal und idealerweise als ein Extent am Stück belegen („multiblock allocation“).
Diese Änderungen verringern den Overhead im Dateisystem und damit sowohl die Systemlast als auch I/O-Engpässe, wenn eine Anwendung größere Mengen Daten schreibt, und verhindern die Fragmentierung von Dateien. Nur für kurze Zeit angelegte temporäre Dateien können komplett im Cache bleiben und werden gar nicht erst auf die Platte geschrieben. Beim Mounten von Ext4 erzeugt der Ext4-Code eine Liste freier Extents für jede Blockgruppe, die im Speicher bleibt und mit deren Hilfe der Block Allocator die Verteilung der Dateien auf der Platte optimiert.
Die „delayed allocation“ ist allerdings eine sehr aggressive Caching-Strategie, die das Risiko von Datenverlusten [4] bei einem Systemabsturz oder Stromausfall erhöht. Nicht nur, dass die Daten länger im Cache bleiben – „delayed allocation“ entkoppelt auch das Schreiben von Daten und Metadaten: Eine neu angelegte Datei kann im Dateisystem bereits auftauchen, bevor die Daten auf die Platte geschrieben sind. Sie hat dann eine Größe von 0 Byte und keine zugeordneten Datenblocks, bis die Daten tatsächlich auf der Platte gelandet sind.
Das hat einen hässlichen Nebeneffekt bei Anwendungen, die beim Überschreiben einer existierenden Datei mit neuen Daten besonders vorsichtig sind: Viele Programmierer schreiben in diesem Fall die neuen Daten zunächst in eine temporäre Datei, die sie dann mit rename() auf den alten Namen umbenennen. Die Logik dahinter: Solange die neuen Daten noch nicht geschrieben sind, bleibt zumindest die alte Version der Datei erhalten.
Mit der „delayed allocation“ kann es allerdings passieren, dass die überschriebene Datei nach einem Systemabsturz gar keine Daten mehr enthält, da der Eintrag im Dateisystem auf die neue, bereits angelegte, aber noch nicht mit Daten befüllte Datei zeigt – rename() ist eine reine Metadaten-Operation. Das Gleiche kann passieren, wenn die Anwendung vor dem Schreiben der neuen Daten ftruncate() aufruft: Das Abschneiden der alten Datei passiert viel schneller als das Schreiben der neuen Daten.
Dieses Verhalten von Ext4 ist durchaus konform mit dem POSIX-Standard und tritt auch bei anderen Dateisystemen, etwa XFS, auf. Ext3 allerdings verhält sich hier in seinem Standard-Betriebsmodus „data=ordered“ gutmütiger und nimmt Änderungen an den Metadaten erst vor, wenn die Daten auf die Platte geschrieben sind – was aber keine bewusste Design-Entscheidung, sondern eher Zufall ist. Dennoch verlassen sich mittlerweile zahlreiche Linux-Anwendungen darauf.
Das „0-Byte-Problem“ hat zu hitzigen Diskussionen [5] unter den Kernel-Entwicklern geführt, wobei zwei sehr unterschiedliche Sichtweisen aufeinandergeprallt sind: Die der Dateisystementwickler, denen es um maximale Performance und die Sicherstellung eines in sich konsistenten Dateisystems geht, und der eher pragmatische Blick beispielsweise von Linus Torvalds, nach dessen Ansicht das Dateisystem den Erwartungen der Anwender gerecht werden sollte – und die wollen vor allem keinen Datenverlust. Mit dem kommenden Kernel 2.6.30 versucht Ext4, problematische Situationen zu erkennen und sich dort wie Ext3 zu verhalten, also die Daten zu schreiben, bevor die Metadaten geändert werden. Der Kernel 2.6.28 von Ubuntu 9.04 enthält bereits diese Patches – hier tritt das Problem also gar nicht auf.
Zusätzlich zu der optimierten Allozierungsstrategie, die eine Dateifragmentierung weitgehend verhindern kann, soll sich Ext4 auch im Betrieb defragmentieren lassen. Ein Defragmentier-Tool soll wahlweise einzelne Dateien oder ganze Dateisysteme defragmentieren, wobei das Programm nichts grundlegend Anderes macht, als die Daten umzukopieren. Wichtig ist das Werkzeug vor allem, wenn man ein bestehendes Ext3-Dateisystem nach Ext4 migrieren möchte, da es Ext3-mäßig gespeicherte Dateien in das Ext4-Format wandeln können soll. Derzeit sind allerdings weder die für die Online-Defragmentierung erforderlichen Patches in den Linux-Kernel integriert noch ist das Defragmentier-Tool fertiggestellt.
Sicherer
Einige Neuerungen sollen die Zuverlässigkeit des Dateisystems erhöhen. So versieht das Journal jede Transaktion mit einer Checksumme. Damit lassen sich nicht nur fehlerhaft ins Journal geschriebene Daten erkennen; zudem vereinfacht sich der Commit von abgeschlossenen Transaktionen im Journal. Auch in den Blockgruppendeskriptoren kommen Checksummen zum Einsatz.
Ext4 nutzt standardmäßig den Barriere-Mechanismus, den neuere Festplatten bieten. Eine solche Barriere beeinflusst das Caching und Umsortieren von Schreibzugriffen moderner Festplatten: Der Platten-Controller führt alle Schreibzugriffe vor einer Barriere aus, bevor er die Schreibzugriffe hinter der Barriere in Angriff nimmt. Damit lässt sich beispielsweise sicherstellen, dass alle zu einer Transaktion gehörenden Schreibvorgänge im Dateisystem ausgeführt sind, bevor der Commit ins Journal geschrieben wird. Mit der Mount-Option barriers=0 lässt sich dieser Mechanismus abschalten.
Die Extents erlauben in Ext4 umfangreichere Konsistenzchecks als die Blocklisten in Ext3. So lässt sich beispielsweise überprüfen, ob sich die Extents einer Datei überschneiden. Zudem speichern die Extent-Header in einem Extent-Baum die Baumtiefe, die über den gesamten Baum konsistent sein muss, und die einem Extent-Index zugeordneten Extents müssen denselben Bereich einer Datei abdecken wie der Index. Bei der indirekten Blockadressierung von Ext3 hingegen ist ein Block mit Blocknummern nicht von zufälligen Daten unterscheidbar, ein Konsistenzcheck daher nur sehr rudimentär möglich.
Sollte einmal ein kompletter fsck-Lauf notwendig sein, geht das bei Ext4 deutlich schneller als bei Ext3. Mit der Option uninit_bg (in Ubuntu 9.04 standardmäßig gesetzt) initialisiert mkfs.ext4 nicht alle Blockgruppen. Das beschleunigt nicht nur das Anlegen des Dateisystems, sondern sorgt vor allem dafür, dass e2fsck lediglich die initialisierten Inodes überprüfen muss. Die Dauer eines fsck-Laufs hängt damit nur noch von der Zahl der Dateien, nicht von der Zahl der insgesamt vorhandenen Inodes (und damit der Größe des Dateisystems) ab.
Limits und Performance
Mit Ext4 fallen einige Grenzen. So erlaubt das Dateisystem eine unbegrenzte Zahl von Unterverzeichnissen in einem Directory, bei Ext3 waren lediglich 32.000 erlaubt. Die Inodes haben jetzt standardmäßig eine Größe von 256 Byte, bei Ext3 reichten noch 128 Byte. Den zusätzlichen Platz nutzt Ext4 unter anderem dazu, die Zugriffszeiten statt in Sekunden in Nanosekunden zu protokollieren und extended attributes direkt im Inode zu speichern.
Ein Patch von Google-Entwicklern für den aktuellen Kernel 2.6.29 erlaubt es, Ext4 ohne Journal zu betreiben, was den Durchsatz nach Messungen von Google um bis zu zwei Prozent erhöhen kann. Angesichts der Vorteile, die das Journal im Fall eines Systemabsturzes oder Stromausfalls bringt, dürfte das allerdings nur dann ernsthaft in Frage kommen, wenn es wirklich auf jedes Quentchen I/O ankommt. Die Userland-Tools bieten derzeit noch keine Möglichkeit, den Betrieb ohne Journal einzurichten.
Doppelte Buchführung
Auch wenn die Ext4-Entwickler gerne die Kompatibilität mit Ext3 herausstreichen, sind diese Aussagen doch mit Vorsicht zu genießen. Zwar lässt sich ein Ext3-Dateisystem als Ext4 mounten, Auswirkungen auf das Dateisystem hat das jedoch keine: Ext4 kennt noch das alte Ext3-Schema zur Blockadressierung und spricht das Dateisystem genauso wie Ext3 an. Man kann auf dem als Ext4 gemounteten Dateisystem lesen und schreiben und es anschließend wieder als Ext3 weiterverwenden.
Erst wenn man mit
tune2fs -O extents
bei Ext3 das Dateisystem-Feature extents setzt und damit die Extents aktiviert, behandelt der Ext4-Code das Dateisystem tatsächlich als Ext4. Die bereits existierenden Dateien bleiben allerdings unverändert im Ext3-Format gespeichert – ein Flag im Inode gibt ja an, ob der Inode Blocknummern oder Extents enthält. Lediglich Dateien, die nach der Umwandlung und dem Mounten als Ext4 neu angelegt werden, profitieren von den neuen Datenstrukturen.
Bei einer solchen Konvertierung entsteht also kein „echtes“ Ext4-Dateisystem, sondern ein Hybrid aus Ext3- und Ext4-Strukturen. Wer ein Dateisystem vollständig von Ext3 nach Ext4 migrieren möchte, kommt um das Sichern der Daten und Neuanlegen des Dateisystems nicht herum. Abhilfe könnte das bereits erwähnte Defragmentier-Tool bringen, das – auf unter Ext3 gespeicherte Dateien losgelassen – die defragmentierte Datei im Ext4-Format mit Extents anlegt.
Nach dem Setzen des extents-Features führt kein bequemer Weg mehr zu Ext3 zurück: Ebenso wie ein mit
mkfs -t ext4
gleich als Ext4 angelegtes Dateisystem lässt sich Ext4 nicht mehr als Ext3 mounten. Das kann beim Einsatz eines etwas älteren Rettungssystems ohne Ext4-Unterstützung für böse Überraschungen sorgen. (odi [6]) (odi [7])
URL dieses Artikels:
https://www.heise.de/-221262
Links in diesem Artikel:
[1] https://www.heise.de/tests/Ubuntu-9-04-im-Test-221809.html
[2] http://ols.108.redhat.com/2007/Reprints/mathur-Reprint.pdf
[3] https://www.heise.de/tests/Das-Dateisystem-Ext3-tunen-221480.html
[4] https://www.heise.de/news/Moeglicher-Datenverlust-bei-Ext4-205664.html
[5] https://www.heise.de/news/Kernel-Entwickler-streiten-ueber-Ext3-und-Ext4-209350.html
[6] mailto:odi@heiseopen.de
[7] mailto:odi@ix.de
Copyright © 2009 Heise Medien