

GTC 2012: Blick ins Herz von Nvidias HPC-Superchip
Einen tiefen Einblick ins Innenleben des GK110-Chips gaben zwei Nvidia-Mitarbeiter auf der GPU Technology Conference. Die GPU ist speziell fürs Supercomputing optimiert.

(Bild: Martin Fischer)
Einen detaillierten Blick in das Innere des kürzlich angekündigten Kepler-Superchips GK110 gaben Nvidias Architekturspezialist Lars Nyland und CUDA-Entwickler Stephen Jones auf der GPU Technology Conference im kalifornischen San Jose. Bei der Entwicklung von Kepler sei es vor allem um die Verbesserung dreier zentraler Punkte gegangen: Performance, Effizienz und Programmierbarkeit.
GK110 ist laut Nvidia nicht nur der leistungsfähigste, sondern mit seinen 7,1 Milliarden Transistoren auch komplexeste Mikroprozessor der Welt. Im Unterschied zum GK104 ist GK110 speziell fürs Supercomputing entwickelt worden, daher wird er sein Debut im vierten Quartal des Jahres auf einer Tesla- (K20) und nicht GeForce-Karte feiern. Spielerkarten sollen erst im Jahr 2013 mit GK110-GPUs bestückt werden.
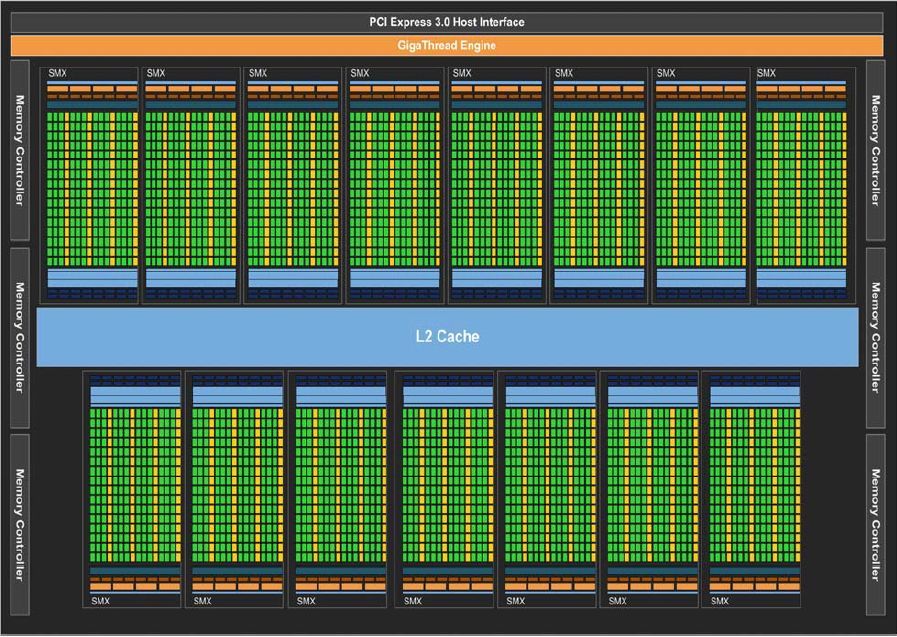
(Bild: Nvidia)
Funktionseinheiten in Hülle und Fülle
Seine Ausführungseinheiten verteilt der GK110 auf bis zu 15 SMX-Blöcke. Jeder davon besteht aus 192 Shader-Rechenkernen (Single-Precision-Cores), 16 Textur- und 64 Double-Precision-Einheiten. Dazu kommen je ein 64 KByte großer L1-Cache sowie 48 KByte Read-Only-Cache. Von den Load-Store- und Special-Function-Units (für transzendente Funktionen) existieren pro SMX jeweils 32 Stück. Gefüttert wird der Shader-Cluster durch 4 Warp Scheduler und 8 Dispatch-Einheiten. Damit lassen sich bis zu 4 Warps – also vier Bündel aus je 32 Threads – gleichzeitig ausführen.

(Bild: Nvidia)
Pro SMX stehen wie bei GK104 weiterhin 65.536 Register bereit. Mit GK110 darf ein Thread aber nun bis zu 255 nutzen, bei GK104 war bereits bei 63 Schluss. Das soll laut Lars Nyland besonders die Performance bei Double-Precision-Berechnungen erhöhen. Als Beispiel nannte er eine Anwendung im Bereich der Quantenchromodynamik, die auf GK110 um den Faktor 5,3 schneller ablief als auf dem GF110-Vorgängerchip.
Der GK110 beherbergt im Vollausbau also insgesamt 2880 Shader-Rechenkerne und die gigantische Anzahl von 240 Textureinheiten – das ist fast die doppelte Menge, die heutige High-End-GPUs bieten. Bei der Texturverarbeitung soll GK110 überdies noch effizienter sein.

(Bild: Nvidia)
Nvidia wird auf den GK110-Boards schnellen GDDR5-Speicher einsetzen. Er kommuniziert über sechs 64-Bit-Speichercontroller mit der GPU – also über 384 Datenleitungen. Das sorgt für eine deutlich höhere Datentransferrate als noch bei GK104-Karten, die nur 256-Bit-Interfaces besitzen. Neben dem Speicher sind auch Register und die L1-/L2-Caches ECC-geschützt. Die Leistungseinbußen im ECC-Modus will Nvidia außerdem laut eigenen Angaben um 66 Prozent reduziert haben.
Dynamic Parallelism, Hyper-Q und verbessertes GPUDirect

(Bild: Nvidia)
Zwei wesentliche Neuerungen sind Dynamic Parallelism und Hyper-Q, durch die Programme effizienter ablaufen und einfacher zu programmieren sind. Dafür ist Version 5.0 des CUDA-Toolkits nötig, das Nvidia bereits als Preview-Version registrierten Entwicklern bereitstellt. Die finale Version will Nvidia im dritten Quartal des Jahres veröffentlichen. Außerdem erlauben Kepler-Grafikkarten nun auch den direkten, serverübergreifenden Zugriff auf den Speicher anderer Kepler-Grafikkarten (GPUDirect). Ausführliche Details zu den einzelnen Funktionen finden Sie hier.
Daten-Sharing dank Shuffle-Instruktion

(Bild: Nvidia)
Threads innerhalb eines Warp-Bündels können durch die Shuffle-Instruktion (Shfl) nun einfacher auf Daten gemeinsam zugreifen. Mit Fermi-GPUs war man dafür auf zusätzliche Load-Store-Operationen und Shared-Memory-Zugriffe angewiesen. Dadurch sollen beispielsweise FFT-Berechnungen schneller ablaufen. Auch bei den sogenannten atomaren Operationen (Atomics) hat Nvidia deutlich nachgelegt. GK110 unterstützt nun zusätzliche 64-Bit-Atomics, nämlich atomicMin, atomicMax, atomicAnd, atomicOr und atomicXor. (mfi)
