

Künstlich intelligente Diagnose als zweite Meinung
Google hat ein Tool zum Vergleich von Tumoraufnahmen entwickelt. Ärzte fragen sich, ob man einem solchen System künftig sein Leben anvertrauen kann.
(Bild: Rudolf A. Blaha)
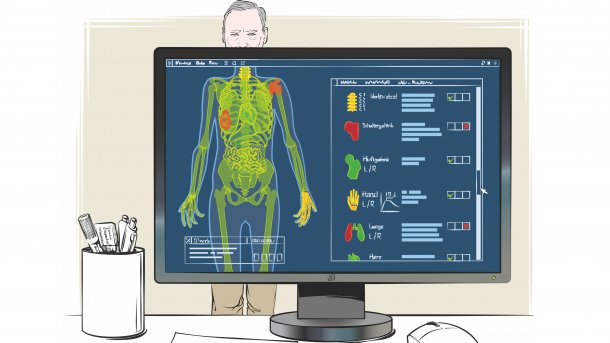
Für die Radiologie und insbesondere die Krebserkennung haben Forscher am Universitätsklinikum Essen (UKE) bereits eine ganze Reihe künstlich intelligenter Systeme entwickelt. Die KI klassifiziert umfangreiche Aufnahmen aus dem Computertomografen (CT) oder dem Magnetresonanztomografen (MRT) gleichbleibend schnell und sticht dabei jeden menschlichen Arzt aus.
Die Systeme können mittlerweile Tumore in der Lunge oder in der Prostata erkennen. Bei Gebärmutterhalskrebs schätzt eine KI ein, ob der Tumor bereits gestreut hat. Bei Leberkrebs prognostiziert ein System, welche Erfolgschance eine Bestrahlung bietet. Allerdings werde dieses höchstens als zweite Meinung eingesetzt, die Entscheidung fälle auf absehbare Zeit in jedem Fall der Arzt, betont Professor Dr. Michael Forsting, medizinischer Direktor des Instituts für diagnostische Radiologie am UKE.
„Es gibt einige Bereiche, in denen KI dem verantwortlichen Arzt sehr gute Hinweise liefern kann, beispielsweise beim Hautkrebs-Screening“, sagt Professor Dr. Andreas Stang, Präsident der Deutschen Gesellschaft für Medizinische Informatik, Biometrie und Epidemiologie (GMDS). Das Problem bestehe derzeit in der Evaluation der Systeme, die zum Teil bereits sehr leistungsfähig arbeiteten. „Derzeit werden wir geradezu von KI überrollt“, berichtet auch der Onkologe Professor Dr. Michael Hallek am Universitätsklinikum Köln. Nach seiner Ansicht steht die KI-gestützte Erkennung von Tumoren kurz vor dem praktischen Einsatz. Die automatisierte Altersbestimmung von Jugendlichen anhand von Knochenaufnahmen wird als unterstützendes Standard-Tool bereits im Westdeutschen Teleradiologieverbund angeboten.
Black Box erhellen
Ein Problem ist die Qualitätssicherung bei den klassifizierenden Systemen. Die künstliche Intelligenz lässt sich bei ihren Entscheidungen nicht so leicht in die Karten schauen. Das ihr zugrunde liegende neuronale Netz ist mithilfe von hunderten oder sogar zigtausenden Beispielfällen per Deep Learning entstanden, verfeinert und getestet worden, aber seine Antworten und Empfehlungen sind im Einzelfall nicht nachvollziehbar.
Das stimme im Prinzip zwar, bestätigt Forsting, er sehe für dieses Problem aber zwei Lösungen. Die eine ist der einfache Parallelcheck: „Denken wir an Lungenscreenings. In Zukunft fehlen wahrscheinlich die Ärzte, um alle Screenings zu erledigen. Also sichtet eine KI die Aufnahmen und man lässt Bilder mitlaufen, von denen der korrekte Befund bekannt ist.“
Die zweite Möglichkeit besteht in KI-spezifischen Mechanismen zur Plausibilitätskontrolle, die die Wissenschaftler in Essen derzeit entwickeln. Dazu noch einmal ein Blick auf die Bestimmung des Knochenalters: Dabei begutachtet der Mediziner auf einer Röntgenaufnahme der Hand die Wachstumsfugen an den Gelenken. Sind alle Fugen geschlossen, so ist das Wachstum im Wesentlichen abgeschlossen. An Vergleichsgrößen lässt sich so das Alter eines Jugendlichen abschätzen.
Unter Ärzten gilt die Bestimmung der Skelettreife als eine ziemlich langweilige Aufgabe und tatsächlich gibt es inzwischen sogar mehrere KI-Systeme, die diese Analyse automatisiert bewerkstelligen, etwa für die Bewertung der Handknochen oder für die der Knie. Das System aus Essen gibt allerdings nicht nur eine Zahl für das Knochenalter aus. Zusätzlich stellt es grafisch dar, welche Bildbereiche ausschlaggebend für die Einschätzung gewesen sind. Wenn sich dabei offenbart, dass die KI die entscheidenden Wachstumsfugen gar nicht berücksichtigt hat, etwa weil die betrachtete Hand verdreht war, wird der Fehler in dieser grafischen Plausibilitätsprüfung deutlich.

(Bild: Uniklinik Essen)
Schicht für Schicht
„In diesem Bereich wird aktuell viel geforscht“, bestätigt Professor Dr. Christoph Palm von der Ostbayrischen Technischen Hochschule Regensburg. Palm entwickelt mit seinem Team eine KI, die anhand der Videoaufnahmen einer Endoskopie Speiseröhrenkrebs erkennt. Auch dieses System soll, wenn es ausgereift ist, grafisch markieren, welche Bildelemente zur Entscheidungsfindung maßgeblich relevant gewesen sind. Um zu verstehen, wie sich die Vorgänge in der Black Box erhellen lassen, muss man sich vor Augen halten, wie eine KI in Form eines neuronalen Netzes trainiert wird.
Das Training besteht darin, dass ein Algorithmus Schicht für Schicht die Gewichte an den Knotenpunkten des Netzes verändert und dann die Entscheidungen des neuen Netzes bewertet. Nur die Anpassungen, die die größten Verbesserungen bringen, behält der Algorithmus bei – und wiederholt diesen Prozess, bis das neuronale Netz mit seinen Entscheidungen ein Optimum erreicht.
Die Entwicklung einer Explainable AI, also einer selbsterklärenden KI in der Bildanalyse, geht im bestehenden neuronalen Netz den umgekehrten Weg: Schicht für Schicht dreht der Algorithmus an den Eingangsparametern und bewertet, ob sich dadurch die diagnostische Entscheidung am Ausgang verändert. Wenn dieses Verfahren bei der Anfangsschicht angekommen ist, nimmt es automatisch eine Analyse des Eingangsbildes vor. Die entscheidenden Pixel sind identifiziert. Damit zeigt die KI dem Arzt, welchen Bildbereichen es seine entscheidenden Informationen entnommen hat.
Eine Lücke entscheidet
Aber Palm warnt, die Anzeige der für eine Entscheidung relevanten Bildbereiche sei allein nicht ausreichend für eine Qualitätskontrolle. Als Beispiel nennt er eine einfache KI, die gelernt hat, ein „C“ von einem „O“ zu unterscheiden. Der relevante Bildbereich für die Erkennung eines „C“ liegt dort, wo der Buchstabe offen ist. Die KI würde für eine Plausibilitätskontrolle also pflichtschuldig die Lücke markieren – ein Bildbereich, in dem vom Buchstaben gar nichts zu sehen ist. Was ist also, wenn eine onkologische KI einen Tumor meldet, aber gleichzeitig einen Bildbereich markiert, der keinen Tumor direkt zeigt? Vielleicht ist die Entscheidung falsch, aber möglicherweise hat die KI auch Zusammenhänge gefunden, die man bisher noch nicht beachtet hatte.
Diese Grundfragen wissenschaftlich zu klären ist eine Aufgabe der KI-Forschung. Aber die leidet unter der enormen Dynamik dieses Forschungsfeldes. Die Zahl der wissenschaftlichen Publikationen zu KI weltweit steigt rasant, Experten sprechen von einer jährlichen Verdopplung. So publizieren KI-Forscher zunehmend ohne Peer Review, also ohne wissenschaftlichen Diskurs vor der Veröffentlichung.
Professor Dr. Gerd Antes vom Universitätsklinikum Freiburg hat beobachtet, dass dafür einfach die Zeit zu fehlen scheint. Wer warte, bis ein seriöses Journal mit Peer Review ein Paper gedruckt hat, der investiere mehrere Monate. In dieser Zeit könnte ihn ein anderes Forschungsteam rechts überholen, indem es seine Ergebnisse ohne Prüfung „in einem Räuberjournal veröffentlicht“. Antes sieht vor allem in der KI-Forschung die Gefahr einer um sich greifenden „Fake Science“. Die könnte den Peer-Review-Prozess gerade auf diesem Feld komplett aushebeln.

(Bild: OTH Regensburg)
Große Trainingsdatenmenge vonnöten
Eine zweite grundlegende Kritik von Antes wendet sich gegen das Mantra, dass Big Data und damit eine möglichst hohe Anzahl von Datensätzen die Treffsicherheit der damit trainierten KI erhöht. Immer mehr ist immer besser? „Am Ende kann es auch sein, dass nur die Zahl der Heuhaufen steigt, in der nach der sprichwörtlichen Nadel gesucht werden muss“, warnt Antes.
Tatsächlich weiß niemand genau, wie groß die optimale Datenbasis für das Training einer konkreten KI ist. Die Forscher sind sich darin einig, dass bei einer zu kleinen Datenbasis ein sogenanntes Overfitting droht. Das System funktioniert für die Trainingsdaten ganz gut, aber es generalisiert eben nicht. Die KI muss jedoch auch bei Eingaben, die es so noch nie gesehen hat, gut funktionieren. Man braucht also für neuronale Netze eine ausreichend große Trainingsdatenmenge und zusätzlich einen davon unabhängigen Testdatensatz. Ob es auch nach oben eine Grenze gibt, ist unklar.
Und so machen immer wieder auch unsinnige Entdeckungen von medizinischen KI-Systemen die Runde. Beispielsweise ermittelte eine KI in einem Microsoft-Labor, Asthma stelle einen wirksamen Schutz gegen eine tödlich verlaufende Lungenentzündung dar. Asthma hat einen positiven gesundheitlichen Aspekt? Nur durch eine kritische Kontrolle offenbarte sich der tatsächliche Zusammenhang: Asthma-Kranke sind häufiger beim Pneumologen, eine Lungenentzündung fällt da viel schneller auf – ein gutes Beispiel für den Unterschied zwischen Kausalität und Korrelation und für die Irrungen, die eine überhastet veröffentlichte KI-Anwendung verbreiten kann. Was von KI-Systemen zu halten ist, die beispielsweise Langzeitvoraussagen zum Sterbezeitpunkt eines Menschen wagen, muss letztlich jeder für sich entscheiden.
Bildersuche klärt Tumorverdacht
Längst hat auch Google das Themenfeld der KI-Diagnosesysteme für sich entdeckt. Im Juli veröffentlichte die britische Google-Tochter DeepMind eine Studie zu einem KI-System, das bei gefährdeten Krankenhauspatienten bis zu 48 Stunden vorher ein akutes Nierenversagen voraussagen kann. Es ist trainiert mit den Gesundheitsdaten von 700.000 US-Veteranen. In der Praxis erkannte das System allerdings nur 56 Prozent der tatsächlich eingetretenen Fälle und auf jeden zutreffenden Alarm kamen zwei Fehlalarme – das ist wohl noch keine sehr gute Werbung für KI-Diagnosen.
Ein weiteres Schlaglicht auf DeepMind warf 2016 eine Kooperation mit dem britischen Krankenhausbetreiber Royal Free NHS Foundation Trust. Über diese Zusammenarbeit verschaffte sich DeepMind Zugriff auf landesweite Patientendaten und machte dafür nur geringe Zugeständnisse zum Datenschutz. Man versprach etwa, die Patientendaten nach der Zusammenarbeit zu löschen.
Mit seiner Kompetenz in umgekehrter Bildersuche hat Google im August ein KI-System veröffentlicht, das Vergleichsbilder zu Gewebeaufnahmen mit potenziellen Tumoren im Cancer Genome Atlas sucht. In diesem Projekt der US-Regierung sind Krebs-Erscheinungsformen katalogisiert. Die besondere Herausforderung der neuen Google-Suche SMILY (Similar Medical Images Like Yours) besteht darin, dass Pathologen die Metadaten zu abgelegten Aufnahmen ganz unterschiedlich pflegen und dabei höchst selten auf relevante Bildbereiche im einzelnen eingehen. Zudem handelt es sich bei den Bilddateien in der Regel um große Aufnahmen mit über 100.000 × 100.000 Pixeln. Ratsuchende Mediziner können bei der SMILY-Anfrage interessante Bildbereiche markieren und damit ihre Suchanfrage konkretisieren.

(Bild: Google)
Hilfreiches Tool für die Zukunft
Die ärztliche Intuition bleibt eine grundlegende Voraussetzung für den Einsatz von SMILY, wie selbst das Google-Forscherteam um Martin Stumpe in Mountain View (Kalifornien) betont. So zeigten Suchergebnisse zu Testaufnahmen mit Prostatagewebe unter den ersten fünf Treffern lediglich zu 63,9 Prozent Aufnahmen mit ähnlichem Gewebe. Blindes Vertrauen ist da keinesfalls angebracht. Gleichwohl verknüpfen viele Mediziner mit dieser Technik Hoffnungen auf ein hilfreiches Tool in der Zukunft.
Unterdessen geht die KI-Entwicklung in Essen bereits weiter. Dort hat sich bei MRT-Aufnahmen gezeigt, dass die KI auch Bilder mit geringem Kontrast sicher auswerten kann. Damit könnte die Zahl der Aufnahmen verringert werden. Die Untersuchung eines Knies nimmt dann statt 15 Minuten nur noch etwa 5 in Anspruch, wie Forsting schildert. Zudem haben die Wissenschaftler erkannt, dass sie durch die Auswertung mit KI auf den Einsatz von Kontrastmittel bei Gehirnaufnahmen im MRT verzichten können. Bei CT-Untersuchungen könnte der Kontrastmitteleinsatz drastisch auf ein Zehntel gesenkt werden.
Doch nicht nur in der Radiologie und bei der Tumorerkennung verspricht KI schnelle Fortschritte. Weitere Ansätze in Essen fassen die Sturzprophylaxe im Klinikalltag ins Auge. Wenn im Krankenhaus ein Patient stürzt, ist das oft folgenreich. Eine KI könnte die Faktoren für Stürze ermitteln und die Gefahr für den einzelnen Patienten abschätzen. Generell sieht Forsting noch reiches Potenzial für neue KI-Anwendungen von der Pathologie bis zur sprechenden Medizin, etwa der Psychiatrie. Wahrscheinlich könnte eine psychiatrische KI einiges aus den Fotos ableiten, die ein Patient auf Instagram hochlädt, oder aus den Aktivitäten, die er auf Facebook offenbart.
Digitalisierung ist der Anfang
Eine Voraussetzung für KI-Diagnosen bildet die konsequente Digitalisierung der Patientendaten und die Vereinheitlichung der Datenformate innerhalb der Klinik. Letztlich führt dieser Schritt nicht nur zu mehr Einsatz von KI. Forsting betont, dass dadurch auch die individualisierte Medizin begünstigt werde, indem KI-Systeme zugleich sehr viele Faktoren auch genetischer und molekularbiologischer Art analysierten. Er meint sogar, dass der Arzt in Zukunft auf die Vorsortierung und Unterstützung durch die KI schlicht angewiesen sei.
In einem weiteren Schritt bietet die Diagnoseunterstützung per KI eine Chance für die Telemedizin. Viele kleine Krankenhäuser im Umland haben keine eigene radiologische Abteilung mehr, keine Pathologie, keine Virologie und auch kein eigenes Labor. „Telemedizin 2.0 ist integrierte Diagnostik, unterstützt durch KI“, sagt Forsting. Die einfache Knochenalterbestimmung im Teleradiologieverbund zeigt, wie das aussehen kann. Zudem könnten gleich mehrere KI-Systeme parallel genutzt werden und sich in ihren Diagnosen ergänzen.
Solche Systeme haben allerdings nicht nur technische Aspekte, sondern setzen auch gesellschaftliche Entwicklungen voraus. Neben der KI-Forschung muss auch das Vertrauen in diese Technik wachsen. Dasselbe gilt für die Bereitschaft der Ärzte, sich auf diese Technik einzulassen. Im Beispiel der Knochenalterbestimmung führte die Abstimmung mit den Füßen allerdings binnen weniger Monate zu einer hohen Akzeptanz.
Künftig ins Google-Krankenhaus?

Google hat jüngst eine Ähnlichkeitssuche für Tumoraufnahmen veröffentlicht und die Apple Watch warnt bei Herzrhythmusstörungen. Professor Dr. med. Michael Forsting vom Uniklinikum Essen erwartet steigendes Engagement der US-Konzerne im Gesundheitswesen.
c’t: Herr Professor Forsting, kann eine deutsche Klinik schon in Hinblick auf den Datenschutz in Bezug auf diagnostische KI mit großen amerikanischen Konzernen zusammenarbeiten?
Michael Forsting: Das wäre nur in eine Richtung möglich. Wenn wir beispielsweise per Machine Learning eine künstliche Intelligenz trainieren und damit ein Produkt entwickeln, dann gehen mit dem ja nicht die einzelnen Patientendaten raus. Eine derartige Zusammenarbeit ist aber nicht das Ziel von Google, Amazon oder Apple. Die wollen selbst Daten sammeln und damit diagnostische KIs entwickeln. Und das macht eine Kooperation schwierig, denn wir können keine Patientendaten ausliefern. Eher werden Konzerne wie Google oder Amazon also in Zukunft selbst Krankenhäuser betreiben.
c’t: Krankenhäuser in den USA oder weltweit?
Forsting: Die werden in den USA anfangen, weil sie das dortige Gesundheitssystem einfach besser kennen. Aber warum sollten sie auf den deutschen Markt verzichten? Die deutsche Medizin ist sehr gut und hier werden auch sehr gute Daten produziert.
c’t: Bereitet Ihnen das Sorgen?
Forsting: Wenn durch das Engagement dieser Konzerne die Medizin tatsächlich besser wird, dann wird mit den Füßen abgestimmt. Wenn ein Arzt dafür bekannt ist, dass er schneller die bessere Diagnose stellt – wo würden Sie hingehen?
Da entstehen dann einfach neue Player im Gesundheitsmarkt. Die sammeln ja schon heute reichlich Daten. Die Tatsache beispielsweise, dass die halbe Menschheit fotografiert, was sie isst, erfreut natürlich die medizinische Daten sammelnden Konzerne. Wahrscheinlich kennen sie auch bereits das Gewicht ihrer User. Und die Apple Watch zeichnet ja nicht umsonst das EKG auf. Aber mit diesen Daten können sie bisher nur Prävention anbieten. Wenn sie Akutmedizin machen wollen, dann müssen sie Krankenhäuser betreiben. Ich sehe keine andere Möglichkeit, an valide Daten zu kommen
Dieser Artikel stammt aus c't 22/2019.
(agr)
