

Datenverarbeitung: Apache Flink 1.11 setzt flexible Checkpoints
Das Stream-Processing-Framework führt Unaligned Checkpoints ein und bekommt eine neue API für Datenquellen.

Das Team hinter Apache Flink hat Version 1.11 des Frameworks zur Verarbeitung von Datenströmen freigegeben. Zu den wichtigsten Neuerungen gehören Unaligned Checkpoints, die Verzögerungen vermeiden sollen, und eine neue Data Source API, die Batch- und Stream-Verarbeitung vereinheitlicht.
Flexible Barrieren
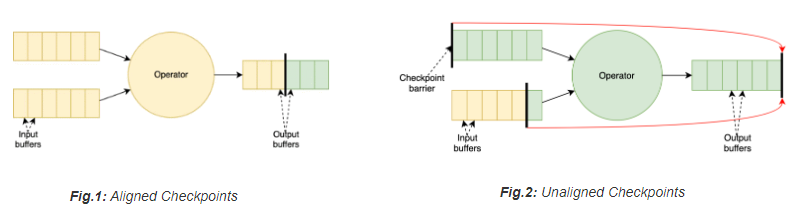
Checkpoints dienen in Flink zur zustandsbehafteten Verarbeitung über Funktionen oder Operatoren. Damit der Status fehlertolerant vorhanden ist, setzt das Framework Checkpoints, die den Status und Positionen im Stream speichern. Operatoren, die mehrere Datenströme verarbeiteten, mussten bisher darauf warten, dass alle Streams den zeitlich gleichen Status hatten. Das ist eigentlich selten ein Problem, da die zeitliche Verzögerung typischerweise im Millisekundenbereich liegt.
Videos by heise
Wenn es jedoch in einem Input-Stream zu einem Rückstau kommt (Backpressure), kann das Warten den aktuellen Prozess längere Zeit blockieren. An der Stelle kommen die neu eingeführten Unaligned Checkpoints zum Tragen: Sie ermöglichen das Setzen von Checkpoints, ohne die Datenströme vorher auf Linie bringen zu müssen. Der Preis für den zeitlichen Gewinn ist ein höherer Speicherbedarf.
(Bild: Apache Software Foundation)
Unaligned Checkpoints sind in Flink 1.11 als Beta gekennzeichnet. Zum Aktivieren dient die Funktion enableUnalignedCheckpoints() in der Klasse CheckpointConfig. Sie funktionieren nur bei der garantiert einmaligen Verarbeitung (Exactly Once) für Checkpoints, nicht in der mindestens einmaligen Option (At-Least-Once).
Schnittstelle zu den Quellen
Ebenfalls als Beta gekennzeichnet ist die neue Data Source API, die das Schreiben von Konnektoren für Datenquellen deutlich vereinfachen soll. Entwicklerinnen und Entwickler mussten sich bisher zum Erstellen von Connectors mit den Interna von Flink auskennen. Außerdem mussten sie für die Batch- und Stream-Verarbeitung jeweils eigenen Code schreiben.

Die neue API unterscheidet zwischen einem sogenannten SplitEnumerator, der als einzelne Instanz läuft und sogenannte Splits erzeugt. Die Datenportionen, die von der Datenquelle stammen, reicht er an mehrere, parallel arbeitende SourceReaderweiter, die die Splits verarbeiten und Streams erzeugen. Das Erstellen von Wasserzeichen (Watermarks) und Zeitstempeln (Event Time Handling) erfolgt transparent innerhalb des SourceReader, sodass Entwicklerinnen und Entwickler sich nicht um diese Flink-Interna kümmern müssen.

(Bild: Apache Software Foundation)
Die neu eingeführte Data Source API kombiniert die drei Komponenten Split, SplitEnumerator und SourceReader miteinander. Sie ermöglicht bei der Verarbeitung sowohl Stream-Verarbeitung (Unbounded) als auch das Zusammenspiel mit Batch-Quellen (Bounded). In letzterem Fall ist sowohl die Anzahl der vom Enumerator generierten Splits als auch deren Umfang endlich, während bei Streams eins von beiden unbegrenzt ist.
Wasserzeichen und SQL
Zu den weiteren Neuerungen in Flink 1.11 gehört die Verarbeitung von Change Data Capture (CDC) in der API/SQL und das vereinheitlichte Erstellen von Wasserzeichen, das ein Interface für AssignerWithPunctuatedWatermarks auf der einen und AssignerWithPeriodicWatermarks auf der anderen Seite bietet. Die Anbindung an Python über PyFlink bringt ebenfalls einige Ergänzungen mit.

(Bild: Apache Software Foundation)
Weitere Details lassen sich der Ankündigung von Flink 1.11 entnehmen. Das Projekt mit dem Eichhörnchen als Maskottchen hat seine Ursprünge in der deutschen Hauptstadt. Es entstand 2010 im Rahmen des Starosphere-Forschungsprojekt an der TU Berlin, der Humboldt-Universtät zu Berlin und dem Hasso-Plattner-Institut in Potsdam. Seit 2014 ist das Projekt unter dem Dach der Apache Software Foundation aufgestellt, wo es Anfang 2015 zum Top-Level-Projekt aufgestiegen ist. 2016 erschien Version 1.0 des Stream-Processing-Frameworks, das unter anderem bei Netflix und Uber zum Einsatz kommt.
Einige Flink-Projektbeteiligte haben 2014 das Start-up data Artisans gegründet, das seit 2019 eine Tochter von Alibaba ist. Kurz nach der Übernahme durch den chinesischen Cloud-Anbieter änderte data Artisans seinen Namen in Ververica. [Link auf Beitrag 1766804]
(rme)