

DarkBERT ist mit Daten aus dem Darknet trainiert – ChatGPTs dunkler Bruder?
Forscher haben ein KI-Modell entwickelt, das mit Daten aus dem Darknet trainiert ist – DarkBERTs Quelle sind Hacker, Cyberkriminelle, politisch Verfolgte.

(Bild: BeeBright/Shutterstock.com)
- Silke Hahn
Ein südkoreanisches Forscherteam hat das Tor-Netzwerk durchkämmt für einen Datensatz zum Training großer Sprachmodelle (Large Language Models, kurz LLM). Die auf unkonventionelle Weise beschafften Daten stammen ausschließlich aus dem Darknet, also potenziell von Hackern, Cyberkriminellen und Betrügern – sowie von politisch Verfolgten und anderen, die die Anonymität schätzen, sei es für undurchsichtige Geschäfte oder zum unbeobachteten Austausch von Informationen etwa unter einem repressiven Regime.
Das damit erstellte Modell DarkBERT soll anderen großen Sprachmodellen des gleichen Architekturtyps (BERT und RoBERTa) hinsichtlich seiner Fähigkeiten ebenbürtig oder leicht überlegen sein. Das sei aus ersten Testreihen hervorgegangen, wie das Team in einem vorläufigen Forschungsbericht bei arXiv.org mitteilt. Den Atomcode oder generell vertrauliche Informationen solle man ihm besser nicht anvertrauen – Gleiches gilt jedoch für generative KI-Systeme allgemein.
Dark Web spricht anders als das Clear Web
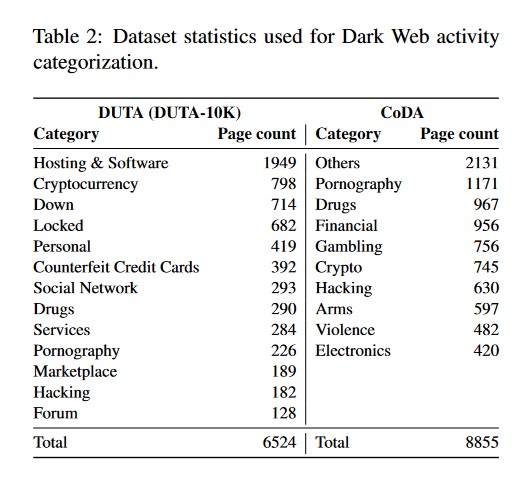
(Bild: DarkBERT: A Language Model for the Dark Side of the Internet)
Ein Blick auf die Fakten: Dunkelberts Schöpfer haben nach eigenen Angaben nicht im Sinn, die Weltherrschaft an sich zu reißen oder Inhalte des verborgenen Internets in den sichtbaren Bereich des Internets (Clear Web) zu gießen, wenngleich sie ihrem Werk durch die Bezeichnung eine düstere Note verpasst haben. Mit DarkBERT wollen sie die Vor- und Nachteile eines domänenspezifischen Modells für das Deep Web in verschiedenen Anwendungsfällen untersuchen.
DarkBERT soll Licht ins Darknet bringen
Ziel der Forschung sei es, die Sprache des Darknets weiter zu erschließen, geht aus dem Vorspann des Berichts hervor. Sprachmodelle, die gezielt für das Dark Web entwickelt sind, könnten "wertvolle Erkenntnisse liefern". Das südkoreanische Team hält eine angemessene Repräsentation des Darknets in einem großen Sprachmodell für wichtig, um die lexikalische und strukturelle Vielfalt zu bändigen, die diesen Raum offenbar vom sichtbaren Bereich des Clear Web unterscheidet. Das übergeordnete Ziel ist den Forschern zufolge Sicherheitsforschung und das Erschaffen eines KI-Modells mit Kontextverständnis für die Domäne Darknet.
Videos by heise
Die Ausgangsfrage des Projekts war, ob ein gezieltes Training auf Daten aus dem Darknet einem LLM besseres Kontextverständnis für die Sprache dieser Domäne verleiht als ein Training mit Daten aus dem frei zugänglichen "oberflächennahen" Internet. Zur Datengewinnung schloss das Team ein Sprachmodell mittels Tor an das Dark Web an und sammelte dabei Rohdaten per Crawl, womit es in einem zweiten Schritt ein Modell erstellte. Anschließend verglichen die Forscher das neue Modell mit bestehenden KI-Modellen des von Google entwickelten Typs BERT (Bidirectional Encoder Representations from Transformers) und dessen verbesserter Architektur RoBERTa (Robustly Optimized BERT Pre-training Approach).

(Bild: DarkBERT: A Language Model for the Dark Side of the Internet)
Zielgruppe: Cybersicherheitsbehörden und Strafverfolger
Erwartungsgemäß übertraf DarkBERT die beiden bei Tests zum Darknet durch sein Domänenwissen – zumindest leicht. BERT gilt heutzutage angesichts mächtiger Transformermodelle des GPT-Typs zwar als leicht veraltet, war aber von Google als Open Source verfügbar gemacht worden und die Forschung nutzt den Modelltyp weiterhin für Replikationsstudien. DarkBERT ist eine nachtrainierte RoBERTa, geht aus dem Preprint hervor, in die über zwei Wochen hinweg zwei Datensätze eingespeist wurden: einmal die gecrawlten Rohdaten und beim zweiten Mal eine aufbereitete (preprocessed) Form des Datensatzes.
Die Zielgruppe sind nicht Cyberkriminelle, sondern Strafverfolgungsbehörden, die das Darknet zum Bekämpfen von Internetkriminalität durchforsten. Am verbreitetsten im Darknet sind laut dem Preprint die Themen Betrug und Datendiebstahl, und angeblich wird das Darknet auch für anonyme Gespräche der organisierten Kriminalität genutzt. Interessant an dem Ansatz ist, dass das Dark bzw. Deep Web ein Bereich des Internets ist, den Suchmaschinen wie Google ausblenden und in dem sich die Mehrheit der Menschen nicht (oder nicht regelmäßig) tummelt, denn dafür ist spezielle Software nötig.

(Bild: BSI)
Anonymität auch für Journalisten und Oppositionelle wichtig
Grundsätzlich wäre das anonyme Surfen im Netz für alle Menschen interessant, denen ihre Privatsphäre am Herzen liegt und die ihre Daten nicht in den Pool großer Technikkonzerne spülen wollen, die das Datensammeln oder Targeting durch personalisierte Werbung zum Geschäftsmodell gemacht haben (wie Google). Auch Journalisten, Oppositionelle und politisch Verfolgte nutzen das Darknet, etwa, um auf regional gesperrte und zensierte Inhalte zuzugreifen. Der Tor-Browser ist zunächst nichts weiter als ein Overlay-Netzwerk zum Anonymisieren der Verbindungsdaten, sein Logo und das Akronym stehen für das Zwiebelprinzip (ausgeschrieben lautet das Akronym "The Onion Router"). Tor schützt seine Nutzer vor der Analyse des Datenverkehrs etwa beim Browsen, Chatten und Mailen.
Empfohlener redaktioneller Inhalt
Mit Ihrer Zustimmung wird hier ein externes YouTube-Video (Google Ireland Limited) geladen.
Ich bin damit einverstanden, dass mir externe Inhalte angezeigt werden. Damit können personenbezogene Daten an Drittplattformen (Google Ireland Limited) übermittelt werden. Mehr dazu in unserer Datenschutzerklärung.
Wem die verfügbaren Modelle durch das Reinforcement-Training mit menschlichem Feedback (RLHF) zu weichgespült und empathisch vorkommen, hätte mit DarkBERT vielleicht seine Freude – oder wäre am Ende enttäuscht, falls die "dunkle" Variante Mythen über die Beschaffenheit des Darknet zerstört und der Output trivialer ausfällt als erwartet. Das oberflächennahe Internet ist zudem nicht für Schöngeistigkeit berühmt. DarkBERT ist nicht frei zugänglich und es bestehen keine Pläne, das Modell der Öffentlichkeit zugänglich zu machen, geht aus dem arXiv-Preprint hervor.

(Bild: DarkBERT: A Language Model for the Dark Side of the Internet)
Keine Veröffentlichung geplant
Für Cybersicherheitbehörden könnten ähnliche Ansätze interessant sein, sofern sie mit einer Echtzeitsuche kombiniert werden, etwa um einschlägige Foren oder illegale Aktivitäten zu überwachen. Dabei bleibt zu hoffen, dass solchen Ansätzen nicht die letzten geschützten Räume des Internets zum Opfer fallen, in denen Überwachung und Zensur noch nicht greifen.
Ob Strafverfolgern Zugang gewährt wird, ist nicht bekannt, Anfragen für akademische Forschungszwecke hingegen werden angenommen. Wenn man bedenkt, dass auch LLaMA von Meta AI / FAIR (Facebook AI Research) in dieser Form zugänglich gemacht und rasch geleakt wurde, ist vorstellbar, dass DarkBERT in absehbarer Zeit inoffiziell in Umlauf geraten könnte – etwa im Darknet.
(sih)
