

Teile mit Eile
Bislang noch weitgehend unbemerkt – abgesehen von einigen Insidern im Forum von semiaccurate.com – hat AMD vor ein paar Wochen im Software Optimization Guide for AMD Family 10h and 12h Processors ein paar interessante Hinweise zur Mikroarchitektur des kommenden AMD-Prozessors Llano gegeben.
- Andreas Stiller
Nun ist definitiv klar, dass es sich bei der prinzipiellen Architektur des eigentlichen Kerns („Husky“, Familie12h) um einen weitgehend unveränderten Phenom der Familie 10h (eingeführt mit Opteron Barcelona) handelt. Der Befehlssatz ist komplett unverändert (inklusive 3Dnow und SSE4a) geblieben, enthält also nicht, wie hier und da spekuliert, bereits SSE4.1/2 oder gar AVX. Bei der Hardware gibt es allerdings neben der Verkleinerung auf 32-nm-Strukturen zwei wichtige Änderungen: zu den Integer-Recheneinheiten gesellt sich nun ein Hardware-Divider und der L3-Cache wurde komplett gestrichen. Den Kontakt zu den anderen Kernen, zum Speicher und zur GPU übernimmt jetzt die integrierte North Bridge (CNB), an die jeder Kern über einen Synchronizer (CIF) ankoppelt. Die GPU verbindet sich mit der Northbridge gleich über zwei bidirektionale Interfaces, die auf die schönen Namen Onion (Zwiebel) und Garlic (Knoblauch) hören. Feinheiten zu den Lauchgewächsen und der Northbridge weiß man noch nicht, Onion ist vermutlich für I/O und CPU/GPU-Kommunikation zuständig und vermittelt zwischen der GPU und der zentralen Queue in der Northbridge (IFQ). Garlic hingegen sorgt für die schnellen Speicherzugriffe der GPU und koppelt am DRAM-Controller-Front-End an. Die Performance für diesen GPU-Zugriff auf den gemeinsamen Speicher hatte AMD schon vor einiger Zeit mit 27 GByte/s beziffert.
Die Northbridge sorgt unter anderem auch für die Datenkohärenz zwischen GPU und CPU, denn beide sollen, wie bei Sandy Bridge, auch in einem gemeinsamen kohärenten Adressraum laufen können, was die Performance im Vergleich zu externen Lösungen deutlich erhöht und zudem die Programmierung vereinfacht.
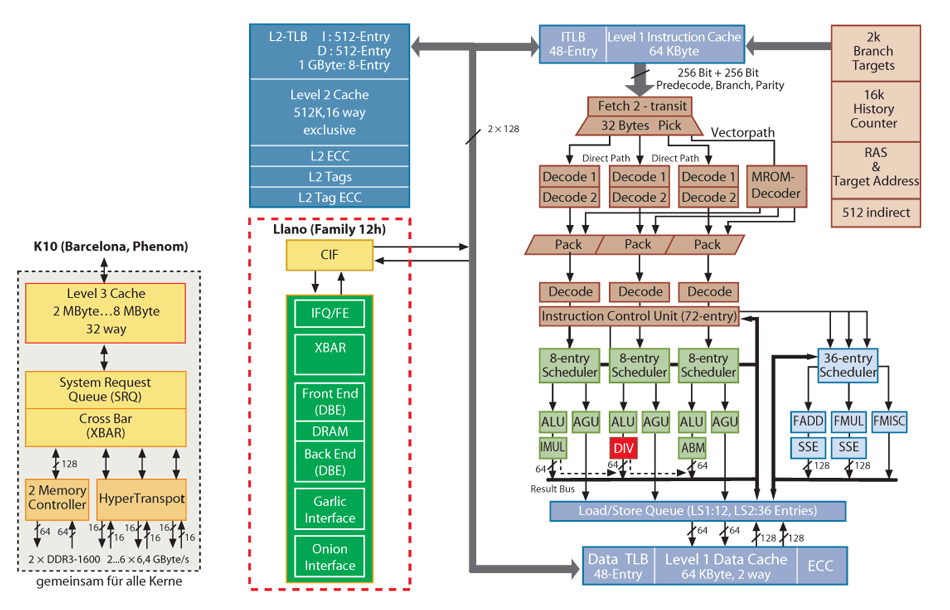
Der nur für einen Sockel vorgesehene Llano kennt auch kein Hyper-Transport mehr, braucht er auch nicht, bietet er doch PCI-Express 2.0 und ein Unified Media Interface an – ein offenbar leicht modifiziertes PCI-Express-x4-Interface, das den Fusion Controller Hub (FCH) namens Hudson ansteuert. Kürzlich drang inoffiziell durch, die Llano-Desktop-Plattform „Lynx“ könnte zudem Hybrid CrossFireX bieten, also das Zusammenspiel der integrierten Grafik mit einer externen ATI-Grafikkarte ermöglichen.
Ferner führen ein Displayport V1.1 und ein DV/High-Definition-Multimedia-Interface vom Prozessor nach draußen. Eine kleine Änderung gegenüber dem Phenom gibts beim auf bis zu 1866 MT/s beschleunigten DDR3-Speicher-Interface: bei Llano kann man nicht mehr per BIOS wählen, ob der Speicherzugriff über zwei getrennte 64-Bit-Kanäle (unganged) oder als ein 128-Bit-Kanal (ganged) agieren soll, es kennt nur unganged. Mit DDR3-1866 (PC3-14900), wie man es dem schon geraume Zeit im Internet kursierenden Electrical Data Sheet entnehmen kann, dürfte man dann wohl auch nur zwei DIMMs anschließen können, ähnlich wie derzeit bei den DDR3-1600-DIMMs (PC3-12800).
Dividende
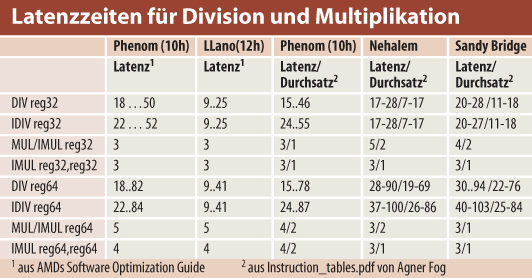
Den Integer-Hardware-Divider hatte Chipguru Hans de Vries schon vor Zeiten auf einem unscharfen Die-Plot aufgespürt und Dresdenboy Matthias Waldhauer verwies in seinem Blog Citavia.blog.de auf das US-Patent (US7584237) von AMD aus dem Jahre 2009, das diesen Hardware-Divider für Patentschriften ungewöhnlich ausführlich beschreibt. Entscheidend ist, dass er den Quotienten in 8 + (Bitanzahl des Quotienten/2, aufgerundet) Takten ausrechnen kann, im besten Fall also bereits nach 9 Takten die Lösung liefert, egal wie groß Divisor und Dividend sind. Im Worst Case sind für die Berechnung bei 32-Bit-Divisionen 25 Takte und bei 64 Bit 41 Takte für Division nötig. Da die Dividiereinheit nicht pipelined ist, entspricht die Durchsatzzeit dieser Latenzzeit.
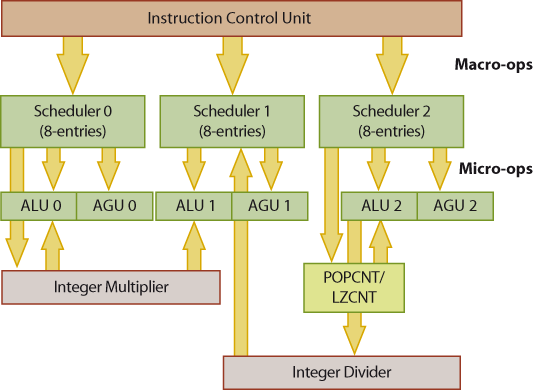
Der Divisionsrest – wie man ihn etwa für Modulo-Rechnungen braucht – ist zwei Takte später verfügbar. Er wird im R/E/DX-Register angeliefert und benötigt dafür eine zweite Pipeline, um auf den Result-Bus zu gelangen. Das Gleiche ist schon seit K7-Zeiten beim MUL-Befehl und IMUL in der Einoperandenform der Fall, die in einer an Pipe 0 angeschlossenen Hardwareeinheit ausgeführt werden. Hier nimmt dann (ab 16-Bit-Operationen) das R/E/DX-Register den überlaufenden Teil des Ergebnisses auf und benötigt für die Ausgabe zusätzlich eine zweite Pipeline (Pipe 1). Dafür muss der Prozessor in der mitbenutzten Pipeline aber passende „Bubbles“ einbauen, sie also kurz anhalten. Braucht man den Überlauf nicht, ist es daher sinnvoll, die Zweioperandenform von IMUL zu wählen, die ohnehin bei 64-Bit-Divisionen etwas zügiger ist und die zudem die andere Pipeline nicht stört.
Bei DIV/IDIV hat man da keine Wahlmöglichkeit, hier gibt es keine Zweioperandenform. Der Divider an Pipe 1 verwendet daher immer die Pipe 2 für die Ausgabe des Divisionsrestes mit. An Pipe 2 ist außerdem noch die Advanced-Bit-Manipulation-Einheit (ABM, zuständig für Population Count, POPCNT und Leading Zero Count, LZCNT) angeschlossen, die jedoch nur einen Ausgabepfad belegt.
Simulation
Der Integer Divider kommt jetzt, 14 Jahre nach dem einst vom Ex-CEO Dirk Meyer konzipierten Athlon K7, der immer noch die prinzipielle Architektur der aktuellen AMD-Desktop-Prozessoren vorgibt, vielleicht ein bisschen spät. Neuere Compiler benutzen alle möglichen Tricks, um lang andauernde Divisionen tunlichst zu vermeiden. Häufig kann man auch auf Gleitkomma umsteigen, wo man dank SSE dann gleich mehrere Divisionen parallel auszuführen vermag. So stellt sich die Frage, welchen Stellenwert diese Erweiterung heutzutage noch hat. Wir haben mal die 31 Programme der SPEC CPU 2006 (genauer gesagt die Assembler-Dateien, die die Intel-Compiler des Composer 2011 beim Kompilieren auf Wunsch erzeugen) durchsucht und dann mit dem Intel-Profiler deren Häufigkeit vermessen. DIV-und IDIV-Befehle spielen danach nur bei zweien der untersuchten Programme überhaupt eine nennenswerte Rolle (bwave, h264ref). Beim H.264-En/Decoder könnte sich der Llano dank Divider ein paar Prozent höherer Performance erfreuen. Dennoch, vielleicht wäre AMD besser beraten gewesen, stattdessen eine zweite Multiplikationseinheit einzubauen. Den Performance-Verlust durch den fehlenden L3-Cache kann der Divider jedenfalls nicht ausgleichen – da muss dann schon ein höherer Takt her, um mit den aktuellen Phenoms mitzuhalten.

Über den Takt gibt es bislang nur Spekulationen. AMD peilt mit Llano Taktfrequenzen von über 3 GHz an, die Versorgungsspannung soll zwischen 0,8 und 1,3 Volt betragen. Mit Hilfe von Power-Gating-Transistoren lässt sich jeder der vier Kerne separat von der Energieversorgung trennen, um Leckströme zu unterbinden. Ein Power-Gate-Ring umgibt Core und dazugehörigen L2-Cache. Dabei nutzen die AMD-Entwickler spezifische Vorteile der SOI-Technik: Sie können die Prozessorkerne masseseitig mit kompakteren N-FETs abschalten und verweisen darauf, dass „andere Firmen“, die herkömmliche (aber billigere) „Bulk-Silicon“-Wafer einsetzen, P-FETs verwenden müssen – gemeint ist selbstverständlich Intel. Das üblicherweise energiehungrige Taktverteilnetz (Clock-Grid) wurde gegenüber dem Phenom neu konstruiert und layoutet, sodass es dank mehrstufigem Clock-Gating und mit der halben Anzahl von Taktpuffer erheblich sparsamer arbeitet und nur noch mit etwa 8 Prozent zum Gesamtverbrauch beiträgt.
Der komplette Llano-Chip mit vier Kernen umfasst über eine Milliarde Transistoren und hat etwa 218 mm2 Größe. Die eigentlichen CPU-Kerne belegen nur einen Bruchteil der Siliziumfläche, denn ihre jeweils 35 Millionen Transistoren passen auf 9,69 Quadratmillimeter – für vier Kerne ergibt das 140 Millionen Transistoren auf knapp 39 Quadratmillimetern. Da kommen dann noch die L2-Cacheblöcke hinzu. AMD lässt den Prozessor in 32-Nanometer-Technik auf Silicon-on-Insulator-(SOI-)Wafern bei Globalfoundries in Dresden fertigen, wobei wie bei IBM und Intel auch ein High-K-Metal-Gate-Verfahren (HKMG) zum Einsatz kommt. Er soll mit zwei Kernen (Winterpark) und 65 Watt ACP sowie vier Kernen (Beavercreek) mit 100 Watt ACP herauskommen, und zwar irgendwann Ende des zweiten oder Anfang des dritten Quartals. Es gibt allerdings auch ein paar Hinweise auf vorgezogene Termine, in Indien soll AMD schon von Mai gesprochen haben. Bis dahin wird sich Konkurrent Sandy Bridge wohl von seinem Chipsatz-Schock wieder erholt haben.
(as)
