

Verteilte Daten ohne Mühe: Conflict-Free Replicated Data Types
Seite 4: Sets
Ein normaler Set bildet leider keinen CRDT, denn die Set-Operationen add und remove sind nicht kommutativ. Die Folge add(E) – remove(E) hat ein anderes Ergebnis als die Folge remove(E) – add(E). Es gibt jedoch mehrere Ansätze für eine Datenstruktur, die einem Set möglichst nahekommt, bei der es sich aber dennoch um einen CRDT handelt. Im Folgenden werden drei dieser Ansätze vorgestellt.
G-Set
Die einfachste Strategie, um einen Set-ähnlichen CRDT zu erhalten, ist, auf removes komplett zu verzichten. Sie kommt beim bereits vorgestellten G-Set (Grow-Only-Set) zum Einsatz.
2P-Set
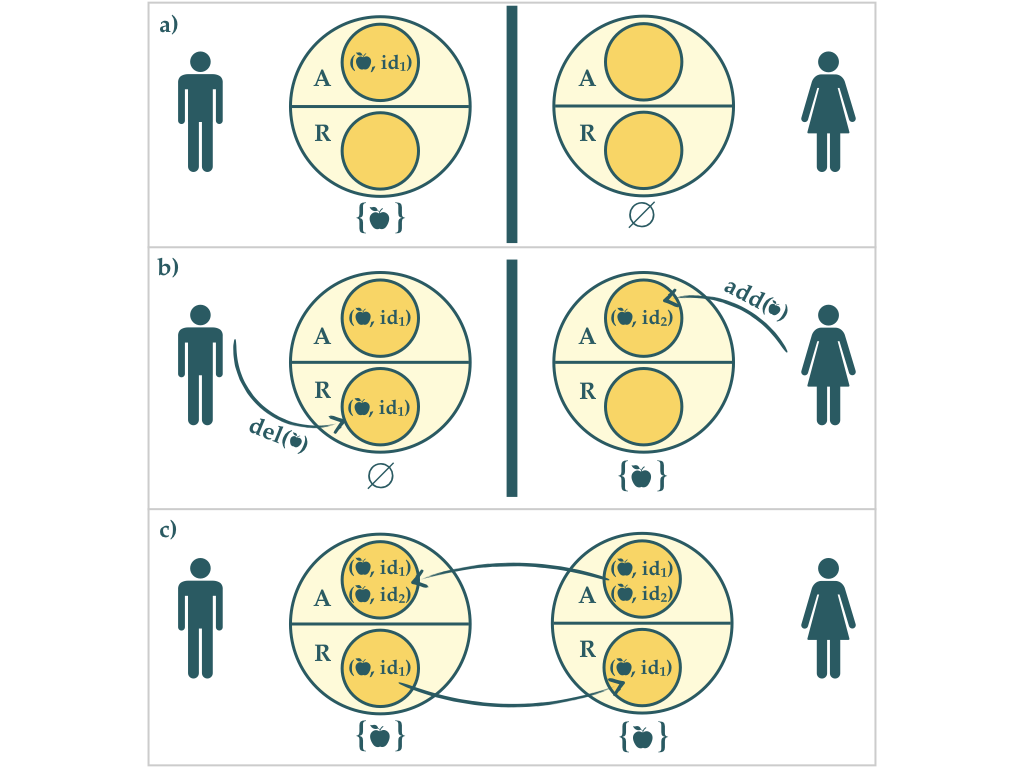
Während es durchaus Anwendungsfälle gibt, in denen ein G-Set völlig ausreichend ist, möchte man jedoch meistens Elemente auch wieder entfernen können. Die Idee eines 2P-Sets ähnelt dem PN-Counter. Intern besteht ein 2P-Set aus zwei G-Sets A und R: der erste G-Set A speichert die hinzugefügten Elemente, und der zweite G-Set R speichert die entfernten Elemente.
Ein 2P-Set enthält ein Element genau dann, wenn es im G-Set A enthalten ist, aber nicht in R. Ein 2P-Set erlaubt es also, Elemente auch zu entfernen, und ist ein CRDT. Es hat aber die vielleicht überraschende Eigenschaft, dass ein einmal entferntes Element nie wieder zum 2P-Set hinzugefügt werden kann.

OR-Set
Während bei einem 2P-Set im Konfliktfall die remove-Operation den Vorzug erhält, favorisiert ein OR-Set (Observed-Remove-Set) die add-Operation. Die grundlegende Idee ist, dass jedes zu einem OR-Set hinzugefügte Element, eine neue interne eindeutige ID bekommt. Die Tupel aus Element und ID werden gespeichert. Sofern das gleiche Element ein zweites Mal zu einem OR-Set hinzugefügt wird, erhält es eine neue ID. Der OR-Set enthält dann zwei Tupel mit diesem Element.
Intern besteht ein OR-Set ebenfalls aus zwei G-Sets A und R, die auch die gespeicherten Tupel aufnehmen. Ein Element ist in einem OR-Set enthalten, wenn es mindestens ein Tupel mit diesem Element gibt, dass im G-Set A enthalten ist, aber nicht im G-Set R. Um ein Element zu löschen, müssen alle Tupel mit diesem Element vom G-Set A in den G-Set R geschoben werden.
Interessant ist der Fall, wenn ein Element gelöscht wird und parallel bei einem anderen Knoten hinzugefügt wird. Beim Hinzufügen wird eine neue ID und somit ein neues Tupel erzeugt, dass auch nach einem Merge in dem G-Set A enthalten bleibt. Das Element ist also nach einem Merge in dem OR-Set (wieder) enthalten.
Das folgende Codebeispiel zeigt einen OR-Set im Einsatz.
// create two CrdtStores and connect them
final CrdtStore crdtStore1 = new CrdtStore();
final CrdtStore crdtStore2 = new CrdtStore();
crdtStore1.connect(crdtStore2);
// create a G-Set and find the according replica in the second store
final ORSet<String> replica1 = crdtStore1.createORSet("ID_1");
final ORSet<String> replica2 = crdtStore2.<String>findORSet("ID_1").get();
// add one entry to each replica
replica1.add("apple");
replica2.add("banana");
// the stores are connected, thus the G-Set is automatically synchronized
assertThat(replica1, containsInAnyOrder("apple", "banana"));
assertThat(replica2, containsInAnyOrder("apple", "banana"));
// disconnect the stores simulating a network issue, offline mode etc.
crdtStore1.disconnect(crdtStore2);
// remove one of the entries
replica1.remove("banana");
replica2.add("strawberry");
// the stores are not connected, thus the changes have only local effects
assertThat(replica1, containsInAnyOrder("apple"));
assertThat(replica2, containsInAnyOrder("apple", "banana", "strawberry"));
// reconnect the stores
crdtStore1.connect(crdtStore2);
// "banana" was added before both stores got disconnected, therefore it is now removed during synchronization
assertThat(replica1, containsInAnyOrder("apple", "strawberry"));
assertThat(replica2, containsInAnyOrder("apple", "strawberry"));
// disconnect the stores again
crdtStore1.disconnect(crdtStore2);
// add one entry to each replica
replica1.add("pear");
replica2.add("pear");
replica2.remove("pear");
// "pear" was added in both stores concurrently, but immediately removed from replica2
assertThat(replica1, containsInAnyOrder("apple", "strawberry", "pear"));
assertThat(replica2, containsInAnyOrder("apple", "strawberry"));
// reconnect the stores
crdtStore1.connect(crdtStore2);
// "pear" was added in both replicas concurrently
// this means that the add-operation of "pear" to replica1 was not visible to replica2
// therefore removing "pear" from replica2 does not include removing "pear" from replica1
// as a result "pear" reappears in the merged Sets
assertThat(replica1, containsInAnyOrder("apple", "strawberry", "pear"));
assertThat(replica2, containsInAnyOrder("apple", "strawberry", "pear"));
Ein OR-Set kommt einem normalen Set vermutlich am nächsten, da Elemente beliebig oft hinzugefügt und wieder entfernt werden können.
RGA
Bei dem letzten vorgestellten CRDT, dem Replicated Growable Array (RGA), handelt es sich um eine der Liste ähnliche Datenstruktur. Sie bietet zwei Operationen: addRight() und remove(). Die Methode addRight() zum Hinzufügen von Elementen ist insofern interessant, als dass neue Elemente nicht an einer konkreten Position eingefügt werden, sondern relativ zu einem bereits vorhandenen Element. Landen zwei Elemente parallel an der gleichen Stelle, steht das neuere vor dem älteren Element.
Wie schon beim LWW-Register tritt allerdings auch bei einem RGA das Problem auf, dass sich nicht mit letzter Sicherheit sagen lässt, welches Element das ältere ist. Gelöschte Elemente bleiben in der Datenstruktur und werden nur als gelöscht markiert, da sie ja noch als Bezugspunkt in addRight()-Operationen auftauchen könnten.
