

Missing Link: Stephen Wolfram über die Rolle der KI in der Forschung (Teil 2)
Stephen Wolfram – Erfinder des Computeralgebrasystems "Mathematica" – gibt einen Einblick in die Grenzen und Potenziale von KI in der Wissenschaft.
Dieser Beitrag wurde uns mit freundlicher Genehmigung von Stephen Wolfram zur Verfügung gestellt: Stephen Wolfram (2024), "Can AI Solve Science?", Stephen Wolfram Writings.
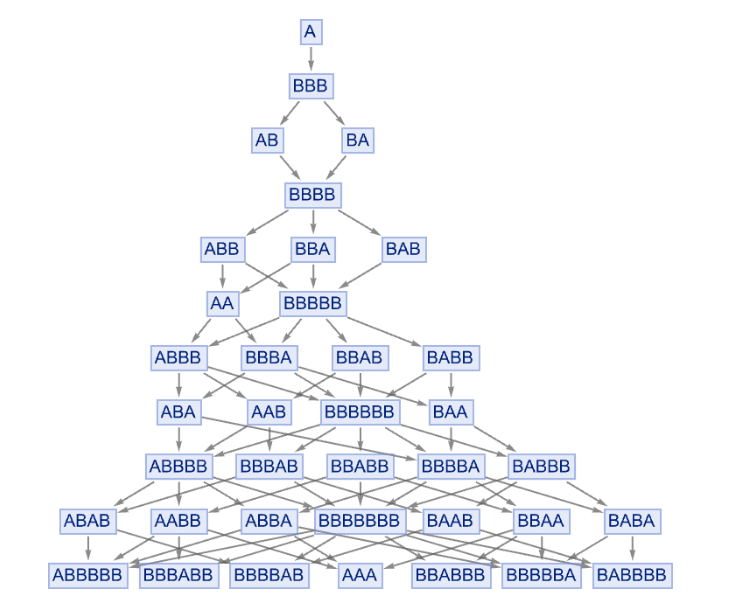
Im ersten Teil des Beitrags ging es hauptsächlich um die Frage, ob Künstliche Intelligenz helfen kann, bestimmte Berechnungsprozesse zu "überspringen" und abzukürzen. Es gibt jedoch auch viele Situationen, in denen es stattdessen darum geht, einen Prozess zu beschleunigen, den man als multikomputationalen Prozess (zur Erklärung siehe den unten stehenden Kasten) bezeichnen könnte, bei dem es in jedem Schritt viele mögliche Ergebnisse gibt und das Ziel beispielsweise darin besteht, einen Weg zu einem bestimmten Endergebnis zu finden. Als einfaches Beispiel für einen multikomputationalen Prozess kann ein Mehrwegsystem betrachtet werden, das auf Zeichenketten operiert, wobei in jedem Schritt die Regeln {A BBB, BB A} auf alle möglichen Arten angewendet werden:
(Bild: Stephen Wolfram)
Was ist nun der kürzeste Pfad von A nach BABA? In dem hier gezeigten Fall lässt sich die Antwort leicht berechnen, beispielsweise indem explizit ein Pfadsuchalgorithmus auf dem Graphen ausgeführt wird:
{A, BBB, AB, BBBB, ABB, AA, ABBB, ABA, BBBBA, BABA]
Es gibt viele Arten von Problemen, die diesem allgemeinen Muster folgen. Viele Herausforderungen folgen einem universellen Schema:
- eine siegreiche Zugfolge innerhalb eines Spielgraphen ermitteln
- ein Rätsel als Sequenz von Zügen anhand eines Möglichkeitsgraphen lösen
- einen Beweis für ein Theorem basierend auf definierten Axiomen entdecken
- einen chemischen Syntheseweg anhand grundlegender Reaktionen identifizieren
Im Kern geht es um das Durchdringen von NP-Problemen, bei denen sich eine Vielzahl "nichtdeterministischer" Berechnungspfaden offenbart.

Im sehr einfachen oben genannten Beispiel ist es uns ohne Weiteres möglich, einen gesamten Mehrweggraphen explizit zu erzeugen. In den meisten praktischen Beispielen wäre der Graph jedoch astronomisch groß.
Die Herausforderung besteht daher typischerweise darin herauszufinden, welche Züge gemacht werden sollen, ohne den gesamten Graphen der Möglichkeiten nachzuzeichnen. Ein gängiger Ansatz ist der Versuch, den verschiedenen möglichen Zuständen oder Ergebnissen eine Bewertung zuzuweisen und nur die Pfade mit etwa den höchsten Bewertungen zu verfolgen.
Bei automatisierten Beweisen von Theoremen ist es auch üblich, "von den Anfangspropositionen abwärts" und "von den endgültigen Theoremen aufwärts" zu arbeiten, um zu versuchen, den Treffpunkt der Pfade in der Mitte zu finden. Zudem gibt es eine weitere wichtige Idee: Hat man erst einmal das Lemma etabliert, dass es einen Weg von X nach Y gibt, kann man X Y als eine neue Regel in die Sammlung der Regeln aufnehmen.

Wie könnte KI helfen? Als ersten Ansatz könnte man in Betracht ziehen, etwas Ähnliches wie das oben beschriebene Mehrwegsystem für Zeichenketten zu nehmen und eine KI, die einem Sprachmodell entspricht, darauf zu trainieren, Sequenzen von Token zu generieren, die Pfade (oder was in einem mathematischen Kontext Beweise wären) darstellen. Die Idee besteht darin, die KI mit einer Sammlung gültiger Sequenzen zu füttern, ihr dann den Anfang und das Ende einer neuen Sequenz zu präsentieren und sie zu bitten, die Mitte auszufüllen.
Hierfür habe ich ein ziemlich einfaches Transformer-Netzwerk verwendet:

(Bild: Stephen Wolfram)
Dann trainiert man es, indem man viele Sequenzen von Token übergibt, die gültigen Pfaden entsprechen (wobei E das „End-Token“ darstellt).
A,BABA:BBB,AB,BBBB,ABB,AA,ABBB,ABA,BBBBAE
zusammen mit "negativen Beispielen", die das Fehlen von Pfaden anzeigen:
BABA,A:N
Das trainierte Netzwerk erhält einen Prompt mit einem Präfix, ähnlich jenen aus den Trainingsdaten. Anschließend erfolgt die iterative Ausführung „im Stil eines Sprachmodells“ (effektiv bei einer Temperatur von Null, das heißt, stets wird der „wahrscheinlichste“ nächste Token ausgewählt):
A,BABA:
A,BABA,B
A,BABA,BB
A,BABA,BBB
A,BABA,BBB,
A,BABA,BBB,A
A,BABA,BBB,AB
A,BABA,BBB,AB,
A,BABA,BBB,AB,B
⁝
A,BABA:BBB,AB,BBBB,ABB,AA,ABBB,AAB,ABBBBE
Eine Zeit lang funktioniert es perfekt – doch gegen Ende treten Fehler auf, wie durch die in Rot dargestellten Token angezeigt. Die Leistung variiert je nach Ziel – in einigen Fällen weicht es gleich zu Beginn vom Kurs ab:
A,AAA:ABBB,BBB,ABB,ABB,AA,ABBB,AAB,ABBBB,AAA,
A,BAAB:BBB,AB,BBBB,ABB,AA,ABBB,AAB,ABBBBE
A,ABBA:BBB,AB,BBBB,ABB,AA,ABBBB,AAB,ABBBBE
A,BBBBBBBBB;A,ABB,BBBB,ABB,AA,ABBB,AAB,ABBBB,AABB,ABBBBB,ABBBBBBEBBBE
A,BB:ABBB,ABEBE,ABB,ABBBE,AA,ABBB,A
Wie lässt sich nun eine Verbesserung erzielen? Eine Möglichkeit besteht darin, bei jedem Schritt nicht nur das Token, das als am wahrscheinlichsten angesehen wird, zu behalten, sondern einen Stapel von Token – wodurch effektiv ein Mehrwegsystem generiert wird, das der LLM-Controller potenziell navigieren könnte. (Dies kann man sich etwas scherzhaft als einen "Quanten-LLM" vorstellen, der stets mehrere Pfade der Geschichte erkundet.)
(Übrigens könnte man sich auch vorstellen, mit vielen verschiedenen Regeln zu trainieren, um dann das zu tun, was im Wesentlichen einem Zero-Shot-Lernen entspricht, und einen Pre-Prompt zu geben, der angibt, welche Regel in einem bestimmten Fall verwendet werden soll.) Eines der Probleme bei diesem LLM-Ansatz ist, dass die generierten Sequenzen oft sogar "lokal falsch" sind: Das nächste Element kann laut den gegebenen Regeln nicht auf das vorherige folgen.
Dies legt jedoch einen anderen Ansatz nahe. Statt zu versuchen, die KI "sofort die gesamte Sequenz ausfüllen zu lassen", soll sie stattdessen nur auswählen, "wohin sie als Nächstes gehen soll", wobei sie stets einer der angegebenen Regeln folgt.
Ein einfaches Trainingsziel besteht dann im Wesentlichen darin, die KI die Distanzfunktion für den Graphen lernen zu lassen, oder mit anderen Worten, die KI in die Lage zu versetzen, zu schätzen, wie lang der kürzeste Pfad (falls vorhanden) von einem Knoten zum anderen ist. Mit einer solchen Funktion besteht eine typische Strategie darin, dem zu folgen, was im Wesentlichen einem Pfad des "steilsten Abstiegs" entspricht – bei jedem Schritt den Zug zu wählen, von dem die KI schätzt, dass er am besten dazu beiträgt, die Entfernung zum Ziel zu verringern.
Wie lässt sich dies tatsächlich mit neuronalen Netzen umsetzen? Ein Ansatz besteht darin, zwei Encoder zu verwenden (sagen wir, aufgebaut aus Transformern) – die effektiv zwei Einbettungen generieren, eine für Quellknoten und eine für Zielknoten. Das Netzwerk kombiniert dann diese Einbettungen und lernt eine "Metrik", die die Distanz zwischen den Knoten charakterisiert:

(Bild: Stephen Wolfram)
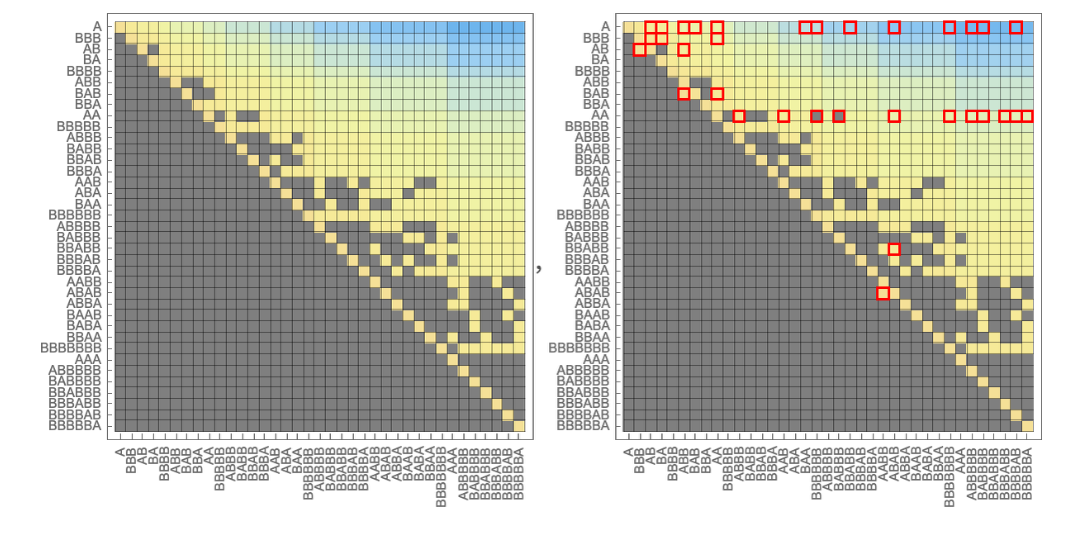
Durch das Training eines solchen Netzwerks mit dem Mehrwegsystem, das diskutiert wurde – indem ihm einige Millionen Beispiele für Quell-Ziel-Distanzen gegeben werden (zuzüglich eines Indikators, ob diese Distanz unendlich ist) –, lässt sich das Netzwerk verwenden, um einen Teil der Distanzmatrix für das Mehrwegsystem vorherzusagen. Und was sich zeigt, ist, dass diese vorhergesagte Matrix der tatsächlichen Matrix ähnlich, aber definitiv nicht identisch ist:
(Bild: Stephen Wolfram)
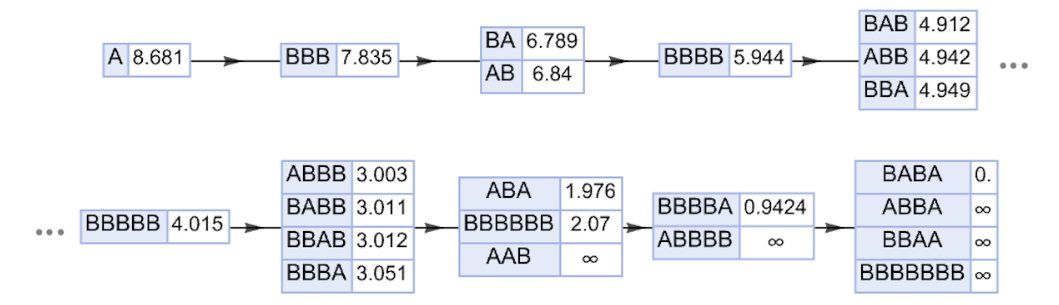
Dennoch kann man sich vorstellen, einen Pfad zu konstruieren, bei dem in jedem Schritt die vom neuronalen Netz vorhergesagten geschätzten Distanzen zum Ziel für jedes mögliche Ziel berechnet werden, um dann dasjenige auszuwählen, das "am weitesten führt“:
(Bild: Stephen Wolfram)
Jeder einzelne Zug hier ist garantiert gültig, und tatsächlich wird schließlich das Ziel BABA erreicht – allerdings in etwas mehr Schritten als der tatsächlich kürzeste Pfad. Auch wenn der optimale Pfad nicht ganz gefunden wird, hat es das neuronale Netz ermöglicht, den "Suchraum“ zumindest etwas zu beschneiden, indem Knoten priorisiert und nur die roten Kanten durchquert werden:

(Bild: Stephen Wolfram)
(Ein technischer Punkt ist, dass das spezielle neuronale Netz, das hier verwendet wurde, die Eigenschaft hat, dass alle Pfade zwischen einem gegebenen Paar von Knoten immer die gleiche Länge haben – wenn also ein Pfad gefunden wird, kann er als der "kürzeste" betrachtet werden. Eine Regel wie {A AAB, BBA B} hat diese Eigenschaft nicht, und ein neuronales Netz, das auf diese Regel trainiert wurde, kann Pfade finden, die das richtige Ziel erreichen, aber nicht so kurz sind, wie sie sein könnten).
Es ist jedoch nicht sicher, wie gut dies funktionieren wird. Das neuronale Netz könnte einen beliebig weit "vom Kurs abbringen" und sogar zu einem Knoten führen, von dem aus es keinen Weg zum Ziel gibt.
Aber zumindest in einfachen Fällen kann der Ansatz potenziell gut funktionieren – und die KI kann erfolgreich einen Pfad finden, der das Spiel gewinnt, den Beweis führt usw. Man kann jedoch nicht erwarten, dass es immer funktioniert. Der Grund dafür ist, dass man auf multikomputationale Irreduzibilität stoßen wird. So wie in einem einzelnen "Berechnungsstrang" die Irreduzibilität der Berechnung bedeuten kann, dass es keine Abkürzung gibt, einfach "die Schritte der Berechnung durchzugehen", so kann in einem Mehrwegsystem die multikomputationelle Irreduzibilität bedeuten, dass es keine Abkürzung gibt, einfach "allen Berechnungssträngen zu folgen", um dann zu sehen, welche sich z.B. vereinigen.
Aber selbst wenn dies prinzipiell möglich wäre, passiert es in der Praxis in den Fällen, die für uns Menschen interessant sind? Bei Spielen oder Rätseln neigen wir dazu, es schwierig – aber nicht zu schwierig – zu machen, um zu "gewinnen". Und wenn es um Mathematik und das Beweisen von Theoremen geht, möchten wir auch, dass die Fälle, die wir für Übungen oder Wettbewerbe verwenden, schwer, aber nicht zu schwer sind. Aber wenn es um mathematische Forschung und die Grenzen der Mathematik geht, erwartet man eine solche Einschränkung nicht sofort. Und das Ergebnis ist dann, dass man erwarten kann, direkt mit multikomputationaler Irreduzibilität konfrontiert zu werden – was es schwierig macht, dass KI zu viel hilft.
Es gibt jedoch eine Fußnote zu dieser Geschichte, die damit zu tun hat, wie wir neue Richtungen in der Mathematik wählen. Man kann von einem metamathematischen Raum ausgehen, der durch die Konstruktion von Theoremen aus anderen Theoremen auf alle möglichen Arten in einem riesigen Mehrweggraphen gebildet wird. Aber wie wir weiter unten sehen werden, sind die meisten Details davon weit entfernt von dem, was menschliche Mathematiker als "Mathematik betreiben" ansehen würden. Stattdessen scheinen Mathematiker implizit Mathematik auf einer "höheren Ebene" zu betreiben, auf der sie diese "mikroskopische Metamathematik" vergröbert haben – so wie wir eine physikalische Flüssigkeit im Hinblick auf ihre relativ einfach zu beschreibende kontinuierliche Dynamik untersuchen könnten, obwohl "darunter" viele komplizierte molekulare Bewegungen liegen.
Kann die KI bei dieser "fluiddynamischen" Mathematik helfen? Potenziell ja, aber hauptsächlich in Form von Code-Unterstützung. Es gibt etwas, das ausgedrückt werden will, sagen wir in Wolfram Language. Aber es wird Hilfe benötigt – im Stil eines LLM – um von unserem informellen Konzept zu einer expliziten Berechnungssprache zu gelangen. Und in dem Maße, in dem das, was getan wird, den strukturellen Mustern dessen folgt, was zuvor getan wurde, kann man erwarten, dass so etwas wie ein LLM helfen wird. Aber in dem Maße, in dem das, was ausgedrückt wird, "wirklich neu" ist und unsere Sprache nicht viel "Boilerplate" enthält, ist es schwer vorstellbar, dass eine KI, die auf dem basiert, was bereits getan wurde, viel helfen wird. Stattdessen muss eine irreduzible Multicomputerberechnung durchgeführt werden, die es ermöglicht, einen neuen Teil des Rechenuniversums und des Ruliad zu erforschen.
