

Streams und Collections in Java 8
Seite 5: Parallelisierung
Parallelisierung von Datenfluss und Kontrollfluss
Eine wesentliche Motivation für das Design der Java-8-Streams war die potenzielle Parallelisierung von Operationen im Stream. In Zeiten von Multicore-Systemen soll die Hardware-Architektur durch Anwendungen gut ausgenutzt werden – idealerweise durch eine gut skalierende Parallelisierung. Eine solche lässt sich im Wesentlichen durch zwei Varianten erreichen.
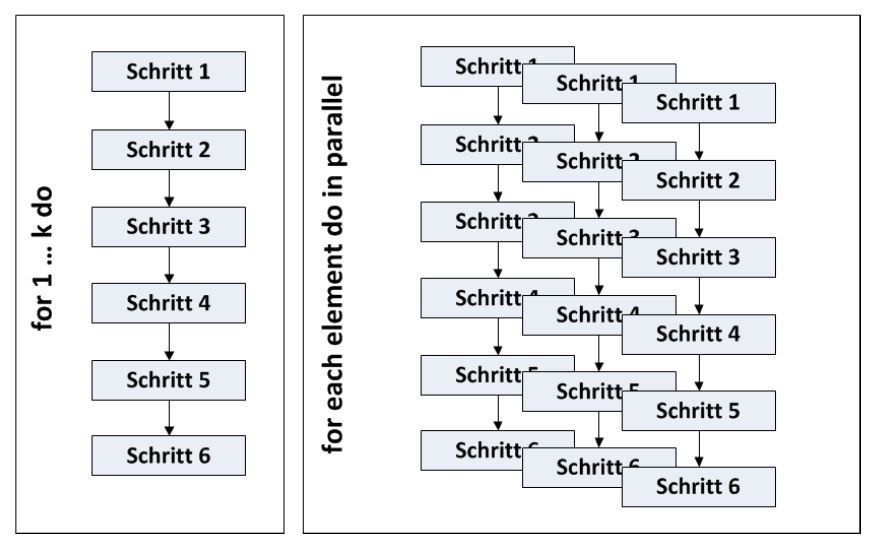
- Parallelisierung des Datenflusses: Die Abbildung 6 zeigt eine Parallelisierung des Datenflusses (rechts) im Vergleich zum sequenziellen Ablauf (links).
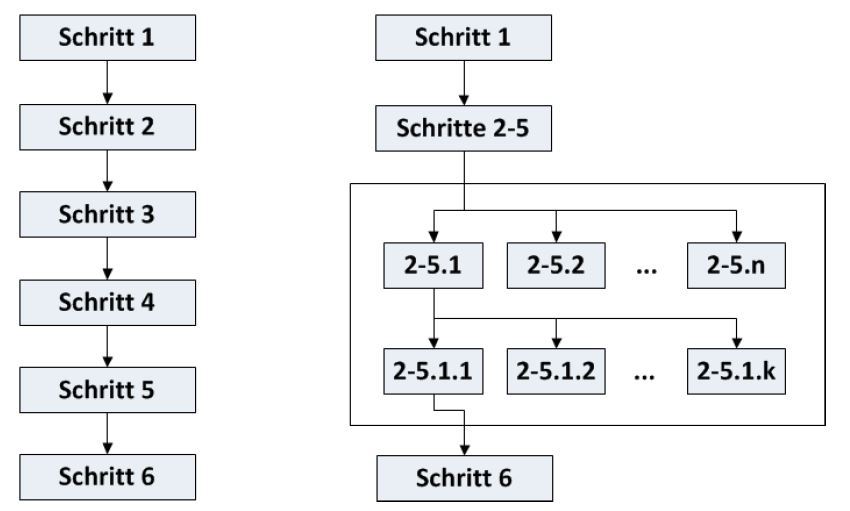
- Parallelisierung des Kontrollflusses: Der funktionale Programmierstil unterstützt die Parallelisierung des Kontrollflusses (vgl. Abb. 7 und 8), da er seiteneffektfreies Arbeiten gut unterstützt. Das erleichtert eine Parallelisierung erheblich, da sonst erforderliche Synchronisierungen nicht nur fehlerträchtig sind, sondern auch potenzielle Performance-Bottlenecks darstellen.

Parallelisierung in Streams
Java 7 führte das Fork/Join-Framework ein, und dieses ist nun Grundlage paralleler Operationen auf Streams. Fork/Join erlaubt die rekursive Parallelisierung des Kontrollflusses per "Teile & herrsche" (s. Abb. 8): Gleiche, zunehmend kleiner werdende Aufgaben werden per "Teile & herrsche" parallel verarbeitet und auf verschiedene CPUs/Cores verteilt. Der "JEP 107: Bulk Data Operations for Collections" ermöglicht solche "Bulk Operations" auf Java-Collections. Laut JEP-Selbstbeschreibung ist Parallelisierung der zentrale Kern dieses Features, das auf Fork/Join aus Java 7 basiert. Ein Beispiel, zunächst noch sequenziell:
String[] txt = { "State", "of", "the", "Lambda",
"Libraries", "Edition" };
// Stream wird definiert
IntStream is =
Arrays.stream(txt)
.filter(s -> s.length() > 3)
.mapToInt(s -> s.length());
// Stream wird verbraucht durch terminale Operation
int sum = is.reduce(0, (l1, l2) -> { return (l1 + l2); });
Im Beispiel wird das String-Array txt durchlaufen, es filtert alle Strings mit Länge größer 3 und berechnet die Länge der verbleibenden Strings. Mit der abschließenden terminalen reduce-Methode berechnet man die Gesamtsumme aller übrig gebliebenen String-Längen. Das Beispiel ist gut parallelisierbar:
- Jeder einzelne String lässt sich bei filter für sich alleine betrachten.
- Jeden gefilterten String kann man be mapToInt ebenfalls für sich alleine konvertieren.
- Die Reduce-Funktion ist kommutativ und assoziativ, die Gesamtsumme aller String-Längen lässt sich also in einer beliebigen Reihenfolge berechnen.
Wie kann man dieses Beispiel nun parallelisieren?
String[] txt = { "State", "of", "the", "Lambda",
"Libraries", "Edition" };
// Stream wird definiert
IntStream is =
Arrays.stream(txt)
.parallel() // Parallelisierung!
.filter(s -> s.length() > 3)
.mapToInt(s -> s.length());
// Stream wird durch terminale Operationverbraucht
int sum = is.reduce(0, (l1, l2) -> { return (l1 + l2); });
Es reicht tatsächlich aus, dem Stream durch parallel mitzuteilen, dass er "sich parallelisieren" soll. Alles andere passiert automatisch: Die interne Iteration wird mit "Teile & herrsche" per Fork/Join-Framework auf die CPUs beziehungsweise Cores verteilt ("fork"). Deren Detailergebnisse werden wieder eingesammelt ("join") und schließlich in der terminalen Operation zusammengerechnet.
Chancen und Grenzen der parallelen Verarbeitung
Zu viel Magie darf man aber nicht erwarten, der Teufel steckt wie immer im Detail. Denn nicht immer ist effiziente Parallelisierung überhaupt möglich:
- Zustandslose intermediäre Operationen wie filter und map bearbeiten ein einzelnes Element. Diese sind problemlos parallelisierbar, da keinerlei Synchronisierung mit Kontext erforderlich ist.
- Zustandsbehaftete intermediäre Operationen benötigen dagegen einen zusätzlichen Kontext und sind damit nur schwierig parallelisierbar. Beispiele: Stream.limit für "nur die ersten k Elemente des Streams durchlassen", Stream.distinct für "mehrfach vorkommende Elemente nur einmal durchlassen", Stream.sorted für "Sortiere den Stream".
- Davon abgesehen muss das Problem auch groß genug sein, damit sich die Parallelisierung lohnt. Das obige Trivialbeispiel verursacht wohl mehr Overhead durch die Parallelisierung per Fork/Join, als die Parallelisierung wirklich an Laufzeitperformance einbringt.
Nachstehendes Beispiel (Ausschnitt) ist gut parallelisierbar – vgl. die Zeilen 10 (parallel) und 14 (sequenziell): Auf einem Quad-Core-Rechner sieht man einen Geschwindigkeitszuwachs um circa Faktor 3. Da man diesen quasi ohne jede eigene Programmieranstrengung gewinnt, ist das durchaus ansehnlich.
1: // Anlegen und Befuellen eines Arrays
2: final int[] array = createRandomArray(ARRAY_SIZE);
3: // Definition einer (lang andauernden) Operation "wasteTime"
4: final IntUnaryOperator op = ( n-> { wasteTime(n%10000);
5: return n%100; });
6: // Hilfsklasse auf Basis von java.time.*
7: final Timer timer=new Timer();
8: // Parallele Ausfuehrung
9: timer.start();
10: int resPar = Arrays.stream(array).parallel().map(op).sum();
11: Duration durPar = timer.getDuration();
12: // Sequentielle Ausfuehrung
13: timer.start();
14: int resSeq = Arrays.stream(array).map(op).sum();
15: Duration durSeq = timer.getDuration();
...
20: private static double wasteTime(int max) {
... // rechenintensive Berechnung (nicht weiter ausgefuehrt)
... }
Die parallele Verarbeitung skaliert in dem Beispiel gut, weil die Hauptlast der Arbeit in der Map-berechnungsintensiven Operation wasteTime passiert. Eine solche Skalierung durch Parallelisierung ist jedoch keine Selbstverständlichkeit, wie einfach zu konstruierende Gegenbeispiele (z. B. mit dem max-Terminaloperatorl) zeigen – in diesen verlangsamt der Overhead durch die parallele Verarbeitung sogar noch die Gesamtperformance.
Fazit
Objektorientierte und funktionale Programmierung schließen sich nicht gegenseitig aus, sondern ergänzen sich und ermöglichen die Gestaltung von Anwendungen, die ausdrucksstark und elegant sind. Die Streams-API von Java 8 ist ein gutes Beispiel für eine gelungene Kombination beider Paradigmen. Zum einen bekommt der Java-Entwickler ein mächtiges Werkzeug zur Datenverarbeitung an die Hand, zum anderen ist die API ein schönes Beispiel dafür, wie moderne Java-APIs unter Ausnutzung von Lambda-Ausdrücken aussehen können.
Den größten Nutzen für Entwickler stiftet dabei vielleicht gar nicht so sehr die Kombination von Objektorientierung und funktionaler Programmierung, sondern vielmehr die daraus resultierende Abkehr von rein imperativer Programmierung hin zu einem deklarativen Ansatz. An dieser Stelle muss in erster Linie der Entwickler umdenken und sich mit den neuen Möglichkeiten von Java 8 vertraut machen.
Martin Lehmann
ist Diplom-Informatiker und als Cheftechnologe und Softwarearchitekt bei Accso – Accelerated Solutions GmbH tätig. Seit Ende der 90er-Jahre arbeitet er in der Softwareentwicklung in diversen Projekten der Individualentwicklung für Kunden verschiedener Branchen.
Markus Günther
ist MSc. Inf. und als Senior Software Engineer bei der Accso – Accelerated Solutions GmbH tätig. Seine aktuellen Schwerpunktthemen sind Enterprise-fähige Suche-Lösungen mit Open-Source-Software und effiziente Java-Architekturen in verteilten Systemlandschaften.
Literatur
- Benjamin Schmid; Fremdsprachenkurs – Ein Überblick über Java-Alternativen für den industriellen Einsatz; Artikel auf heise Developer
- Michael Kofler; Der steinige Weg; Was Entwickler mit Java 8 erwartet; Artikel auf heise Developer
- Maurice Naftalin; Lambda FAQ
- Brian Goetz; State of the Lambda (Final Edition); September 2013
- Gregor Hohpe, Bobby Woolf; Enterprise Integration Patterns; Designing, Building, and Deploying Messaging Solutions; Addison-Wesley 2003
- Markus Günther, Martin Lehmann; Java 7: Das Fork-Join-Framework für mehr Performance; JavaSPEKTRUM 5/2012
(ane)
