

Wer, wie, was: Textanalyse über Natural Language Processing mit BERT
Zwei Verfahren, deren Akronyme Namen von Figuren aus der Sesamstraße entsprechen, haben den Bereich NLP in jüngster Zeit deutlich vorangebracht: ELMo und BERT.

(Bild: Shutterstock)
- Dr. Christian Winkler
Die Analyse von Texten über Natural Language Processing (NLP) hat in den letzten Jahren aus mehreren Gründen einen beispiellosen Höhenflug erlebt. Einerseits stehen durch das Internet genügend große Textmengen zur Verfügung, deren Analyse realen geschäftlichen Mehrwert schaffen kann. Andererseits ist die Rechenleistung ausreichend stark angestiegen, um die Datenmengen gut zu verarbeitet. Schließlich sind viele Methoden entstanden, die eine effektive Verarbeitung solcher natürlichsprachlicher Texte erlauben.
Klassische Textanalyse mit Machine Learning
Über viele Jahre setzen Data Scientists zur Textanalyse und -klassifikation hauptsächlich auf sogenannte Bag-of-words-Modelle beziehungsweise die davon abgeleiteten TF/IDF-Modelle (Term Frequency, Inverse Document Frequency). Da fast alle Analyseverfahren Machine Learning verwenden, gilt es zunächst, die Dokumente in Vektoren umzurechnen. Der erste Schritt ist das Durchnummerieren des Vokabulars, und der Zugriff auf die Wörter erfolgt im Anschluss über die laufenden Nummern. Die Gesamtmenge aller Dokumente (Corpus) lässt sich damit als eine Matrix darstellen, die Dokument-Term-Matrix heißt (s. Abb. 1). Sie ist die Basis für weitergehende Analysen sowohl für Supervised als auch für Unsupervised Machine Learning.
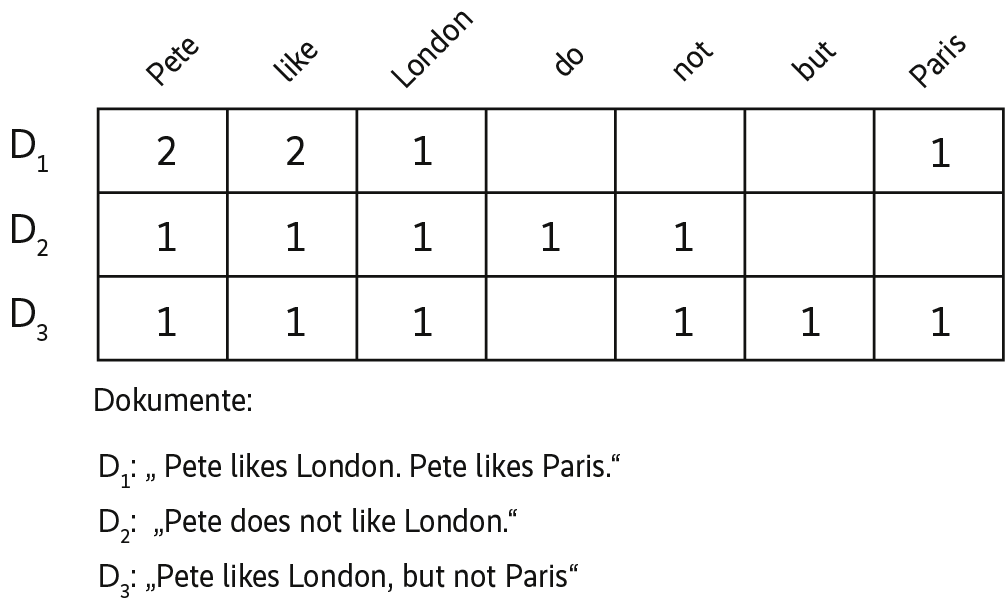
Das Verfahren lässt sich unter anderem durch das Berücksichtigen von Wortkombinationen (N-Gramme) verfeinern. Wer nur einzelne Wortarten oder lediglich die Grundformen der Wörter berücksichtigen möchte, kann eine linguistische Voranalyse nutzen. Mit einer TF/IDF-Transformation ist es möglich, besonders häufige Wörter weniger stark zu gewichten, weil sie eine geringere Trennschärfe haben.
In jedem Fall repräsentiert eine bloße Zahl ein Wort beziehungsweise ein N-Gramm. Für viele Aufgaben wie einfache Klassifikation oder Topic Modeling sind diese Verfahren absolut ausreichend und finden nach wie vor häufig Anwendung. Allerdings lässt sich damit nicht die Bedeutung von Wörtern erfassen, was besonders schwer bei Synonymen zu Buche schlägt, die als komplett unabhängige Entitäten existieren.
Semantik mit Wortvektoren
Diese Schwächen sind seit längerer Zeit bekannt. 2013 konnte der seinerzeit bei Google beschäftigte Thomas Mikolov jedoch einen Durchbruch mit einer Arbeit erzielen, die er zusammen mit Kai Chen, Greg Corrado und Jeffrey Dean verfasst hatte.
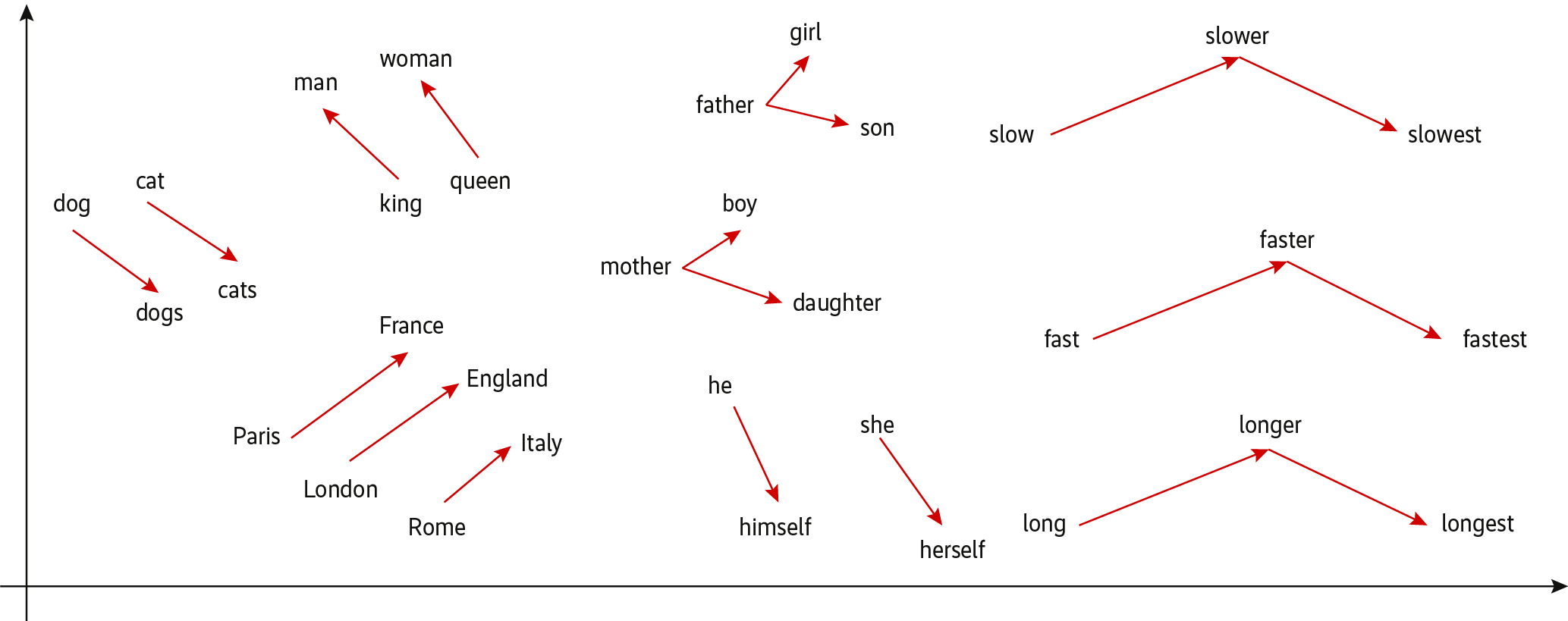
Durch das Training eines neuronalen Netzes gelang es ihm, aus fortlaufenden Texten Vektoren für Wörter zu finden, die deren Semantik repräsentieren. Die Bezeichnung Word Embeddings kommt daher, dass die Wörter in einen verhältnismäßig niedrigdimensionalen Raum eingebettet sind. Mikolov hat die Dimension 300 verwendet, die immer noch häufig anzutreffen ist. Das Verfahren heißt word2vec, und die daraus entstehenden Wortvektoren (s. Abb. 2) haben erstaunliche Eigenschaften:
- Wortvektoren semantisch ähnlicher Wörter haben einen geringen Abstand (als Abstandsmaß ist der Winkel zwischen solchen Vektoren definiert).
- Wortvektoren können semantische Unterschiede fassen, woraus sich Gleichungen der Form
Apple – iOS = Google – Xaufstellen lassen, aus der das System für den Platzhalter X die Auflösung "Android" bestimmen kann. - Neben semantischen kann das Modell auch syntaktische Ähnlichkeiten repräsentieren. Daraus lassen sich unter anderem Steigerungsformen von Adjektiven oder Zeitformen von Verben ableiten.
- Besonders erstaunlich ist, dass das Training mit unstrukturierten Texten erfolgt, weshalb keine vorklassifizierten Daten notwendig sind. Das vereinfacht die Suche nach geeigneten Trainingsdaten.
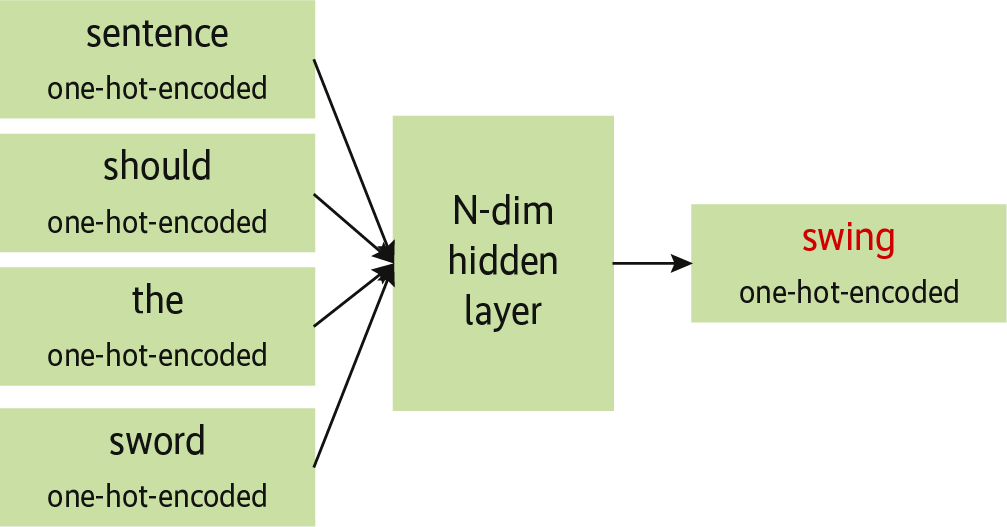
Die Grundidee der im Rahmen dieses Artikels nur am Rand vorgestellten Lernverfahren ist, die Wortvektoren auf solche Art zu justieren, dass sich ein Wort aus seinem Kontext vorhersagen lässt. Dieses Verfahren nennt sich Continuous-Bag-Of-Word-Modell (CBOW)(s. Abb. 3).
Für das Training mit umfangreichen Daten kehren Data Scientists das Modell häufig um und trainieren es darauf, aus dem Wort den gesamten Kontext vorherzusagen. Die Wortvektoren haben dabei ebenfalls die oben beschriebenen Eigenschaften. Einigermaßen erstaunlich ist, wie viel "Wissen" sich aus den reinen Textdaten extrahieren lässt.
Um zu überprüfen, ob das Modell so gut wie behauptet arbeitet, hat der Autor dieses Artikels das Modell mit den Daten des Heise-Newstickers von 1998 bis zum Mai 2020 trainiert. Auch wenn die Verarbeitung erstaunlich schnell erfolgt ist, sollen in erster Linie die Ergebnisse interessieren. Das Jupyter-Notebook ist auf GitHub verfügbar. Es lässt sich sowohl lokal als auch auf Google Colab ausführen.

Wer ein solches Training effektiv durchführen möchte, sollte allerdings darauf achten, dass die Datenmenge groß genug ist. Gute Ergebnisse sind erst ab etwa einer Million Wörter zu erwarten.
Neben word2vec existieren für Wortvektoren noch fastText von Facebook und gloVe von der Universität Stanford. Die Funktionsweise ist im Detail unterschiedlich, die Ergebnisse sind jedoch oft vergleichbar.
Sprache besteht aus Sätzen
Mit word2vec gelingt es, semantische Beziehungen zwischen Wörtern herzustellen. Das aufgeführte Beispiel zeigt, dass sich damit Synonyme gut abdecken und finden lassen.
Sprache ist allerdings deutlich mehr als die reine Aneinanderreihung von Wörtern. Die word2vec-Methoden lassen sich verallgemeinern auf die Embeddings von Sätzen oder ganzen Dokumenten (doc2vec), allerdings ist durch die große Vielfalt unterschiedlicher Sätze ein Ähnlichkeitsmaß schwierig anwendbar.
NLP-Experten haben weiter geforscht und sich auf die sogenannte Kontextualisierung konzentriert. Die Bedeutung eines einzelnen Worts ist häufig für sich nicht zu erschließen, weil es ein ganzes Bedeutungsspektrum abdeckt. Gut erkennbar ist die Sachlage bei Homonymen: Wörter mit unterschiedlichen Bedeutungen wie im Kinderspiel Teekesselchen.
Der nächste Schritt besteht somit darin, die Kontexte zu erschließen, womit der Bereich der Sprachmodelle erreicht ist. Um ganzen Sätzen eine Semantik zuzuordnen und sich damit implizit die Bedeutung der jeweiligen Wörter genauer zu erschließen, ist die sogenannte Kontextualisierung notwendig. Homonyme sind ein Extremfall, aber Wörter können durchaus abhängig von ihrer Verwendung subtil unterschiedliche Bedeutungen haben. Das lässt sich prinzipiell kaskadiert betrachten, denn die wahre Bedeutung von Sätzen erschließt sich oft erst über Absätze und deren Bedeutung über Dokumente. Besonders auffällig ist das bei Stilmitteln wie Ironie, die ein Wort, einen Satz oder einen Absatz in das komplette Gegenteil verkehren.
Die dafür notwendige Kontextualisierung kann auf unterschiedliche Arten erfolgen, und die einzelnen Verfahren haben unterschiedliche Ansätze.
ELMo verlangt Training
Das historisch erste Verfahren, das die Kontextualisierung angeht und eine gewisse Popularität erlangt hat, nennt sich ELMo. Die Gruppe AllenNLP am Allen Institute for AI hat es veröffentlicht, und es ähnelt im Großen und Ganzen anderen Verfahren wie den sogenannten Universal Sentence Encoder von Google, auch wenn die beiden im Detail etwas anders funktionieren.
Die Grundidee von ELMo ist, die Sätze beziehungsweise größere Einheiten wie Absätze kontextualisiert zu betrachten. Dazu reicht es nicht, die Sätze nur in eine Richtung zu lesen, da sich mancher Inhalt erst semantisch am Ende des Satzes richtig erschließt. (vgl. Abb. 6). Der Spruch "Lass mich ausreden!" erfährt somit eine linguistische Begründung.

ELMo betreibt für die Analyse einen erheblichen Aufwand. Es trainiert Kaskaden von Long Short-Term Memories (LSTMs) vorwärts und rückwärts. Als Ausgangspunkt dienen unkontextualisierte Wortvektoren, die mit Convolutional Neural Networks (CNNs) auf Buchstaben-N-Gramme trainiert werden, um Vor- und Nachsilben mit zu berücksichtigen. Besonders wichtig ist das bei sogenannten agglutinierenden Sprachen, in denen Nachsilben die grammatische Funktion bestimmen. Abbildung 7 zeigt ein Übersichtsbild.

Die Komplexität und damit die Trainingszeit von ELMo ist erheblich. Dafür kann es bereits mit kleinen Datenmengen gute Resultate erreichen. Als Beispiel dienen die Schlagzeilen des Heise-Newstickers aus dem Jahr 2019. Aufgabe von ELMo ist, die semantisch ähnlichsten zu ermitteln. Ohne Grafikkarte dauert die Berechnung äußerst lang, weshalb erneut ein Colab-Notebook die Arbeit übernimmt, dessen Ausführung auf Googles Rechnern erfolgt. Da ELMo jedesmal neu trainiert werden muss, dauert die Ausführung sogar auf Colab bis zu 20 Minuten. Wer die Codebeispiele testen möchte, sollte unbedingt eine GPU bei Colab nutzen und dazu unter Runtime/Change Runtime Type "GPU" auswählen):

Die Ergebnisse für die ähnlichsten Meldungen sind leider bis auf die fast identischen nicht sehr überzeugend. Das liegt an dem Batch-Training und an der Datenmenge, die für ein Training auf der gründen Wiese etwas zu klein ist.
ELMo benötigt eine äußerst hohe Rechenleistung. Leider lassen sich errechnete Ergebnisse nicht direkt weiterverwenden, sondern für einen neuen Anwendungsfall muss eine separate Berechnung mit gleichem Aufwand erfolgen.
Neben dem hohen Rechenaufwand benötigt ELMo durch seine Architektur zudem viel Speicher. Auch leistungsfähige Grafikkarten stoßen daher schnell an ihre Grenzen, weil sie oft "nur" mit 8 GByte RAM ausgestattet sind, was für viele Anwendungszwecke nicht mehr ausreicht.
Transfer Learning mit BERT
Diese Nachteile versucht BERT (Bidirectional Encoder Representations from Transformers) zu umgehen. Die ursprüngliche Idee stammt von Google. Mit weiteren Verbesserungen ist inzwischen ein umfangreiches Ökosystem dazu entstanden.

Die Grundidee von BERT ist das sogenannte Transfer Learning. Data Scientists trainieren zunächst ein Sprachmodell ähnlich wie bei ELMo auf einem großen Korpus. Anders als bei ELMo können sie die erzielten Erkenntnisse in Form von Modellen weiterverwenden. Dafür müssen sie sie allerdings mit dem sogenannten Finetuning anpassen. Damit ist der Rechenaufwand immer noch groß, aber im Vergleich zum Gesamtmodell durchaus auf moderater Hardware in überschaubarer Zeit zu bewältigen.
Auslassen als Trainingshilfe
Ein Trick hilft dabei, das Modell besser trainieren zu können und es gegenüber Störungen zu immunisieren: Bestimmte Wörter werden absichtlich weggelassen, und das System dazu in einer Weise trainiert, dass es sie wieder vorhersagen kann.
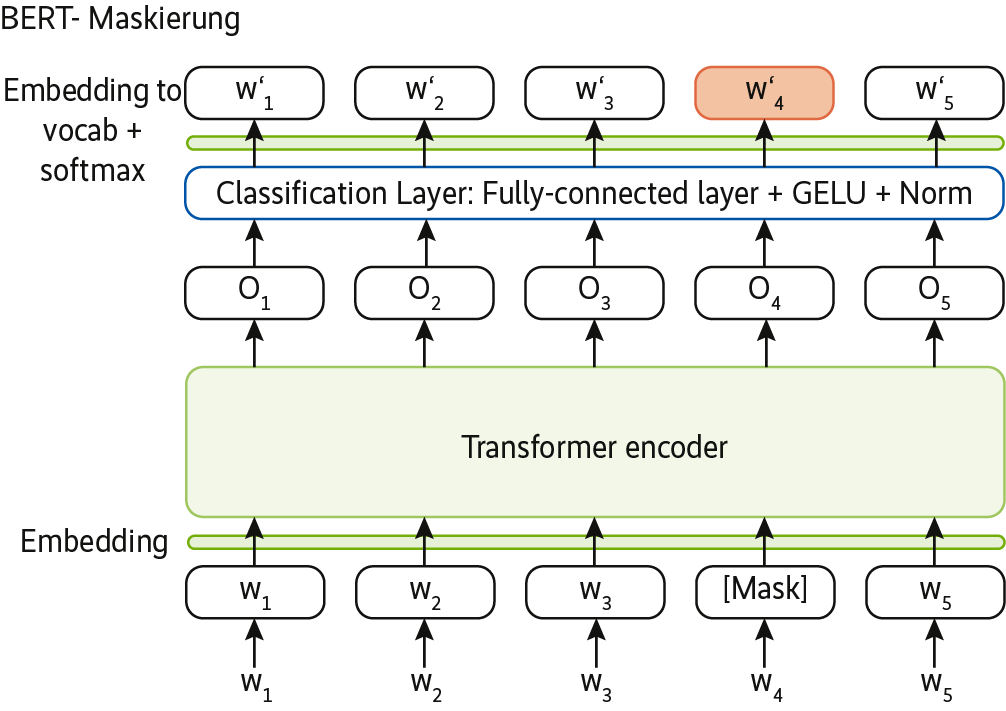
(Bild: Towards Data Science)
Für BERT verwenden Data Scientists ein mehrschichtiges tiefes neuronales Netz (DNN, Deep Neural Network) mit üblicherweise zwölf Layers, das sie darauf trainieren, den jeweils nächsten Satz vorherzusagen. Ein Beispiel auf der Webseite towards data science verdeutlicht das Vorgehen (s. Abb. 10).
![Einsatz von BERT zur Klassifikation, wofür alleine der vollkontextualisierte Wortvektor von [CLS] genutzt wid (Abb. 11)](/imgs/18/2/9/4/7/9/8/9/Grafik11-b54a08fefd5db905.png)
Entscheidend sind dabei die Tokens, die den Anfang [CLS] und das Ende [SEP] eines Satzes markieren. Durch die komplette Kontextualisierung können sie abhängig von ihrem Kontext die gesamte Bedeutung des Satzes darstellen. Diese Tatsache lässt sich für das Finetuning verwenden.
BERT in der Praxis
Glücklicherweise muss sich niemand mit allen Details von BERT auseinandersetzen, um es nutzen zu können. Google stellt mehrere vortrainierte Modelle zur Verfügung, die das folgende Codebeispiel nutzt. Das Training der Modelle hat äußerst lange gedauert: Ganze Rechenzentren von Google mit hochspezialisierten TPUs (Tensor Processing Units) waren damit viele Tage beschäftigt. Für Unternehmen, die das Modell nur nutzen wollen, wären damit große Investitionen in Rechner oder Rechenleistung erforderlich, die durch die vorgefertigten und übertragbaren Modelle deutlich geringer ausfallen.
Google hat BERT ursprünglich in TensorFlow implementiert. Die seinerzeit kleine Firma Huggingface hat auf der Grundlage ein deutlich eleganteres Interface geschaffen, dessen PyTorch-API im Folgenden zum Einsatz kommt.
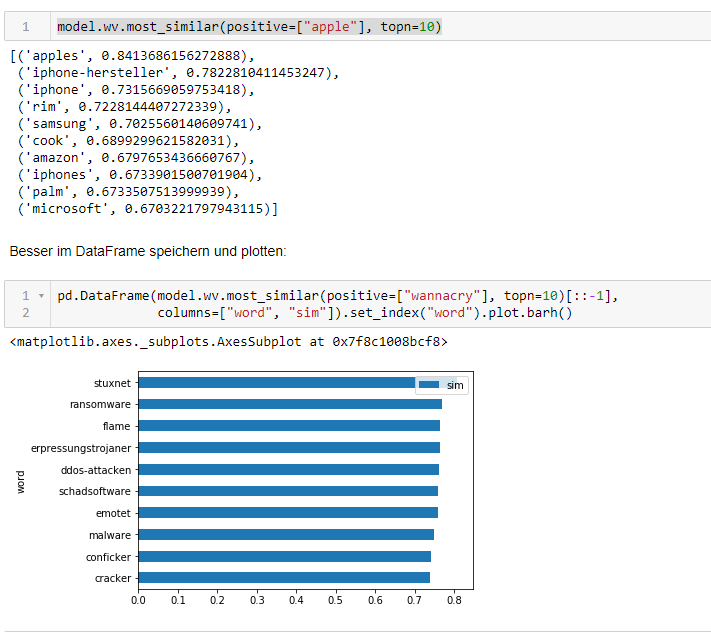
Das Colab-Notebook berechnet mit BERT die Embeddings der Heise-Headlines von 2019 und bestimmt die ähnlichsten (s. Abb. 12). Dabei hilft, dass der vorletzte BERT-Layer die gewünschten Embeddings enthält, die sich mit PyTorch auslesen lassen.

Finetuning zur Klassifikation
Die wahre Stärke von BERT ist allerdings nicht das Berechnen kontextualisierter Embeddings, sondern deren Nutzung, um beispielsweise Klassifikationsprobleme zu lösen. Die Idee dahinter ist, lediglich den (kontextualisierten) Wortvektor des jeweiligen Satzanfangs ([CLS]-Token) zu berücksichtigen und nur im letzten Layer die Gewichte auf eine Weise anzupassen, die ein Einordnen des Satzes in die passende Kategorie ermöglicht (s. Abb. 13).
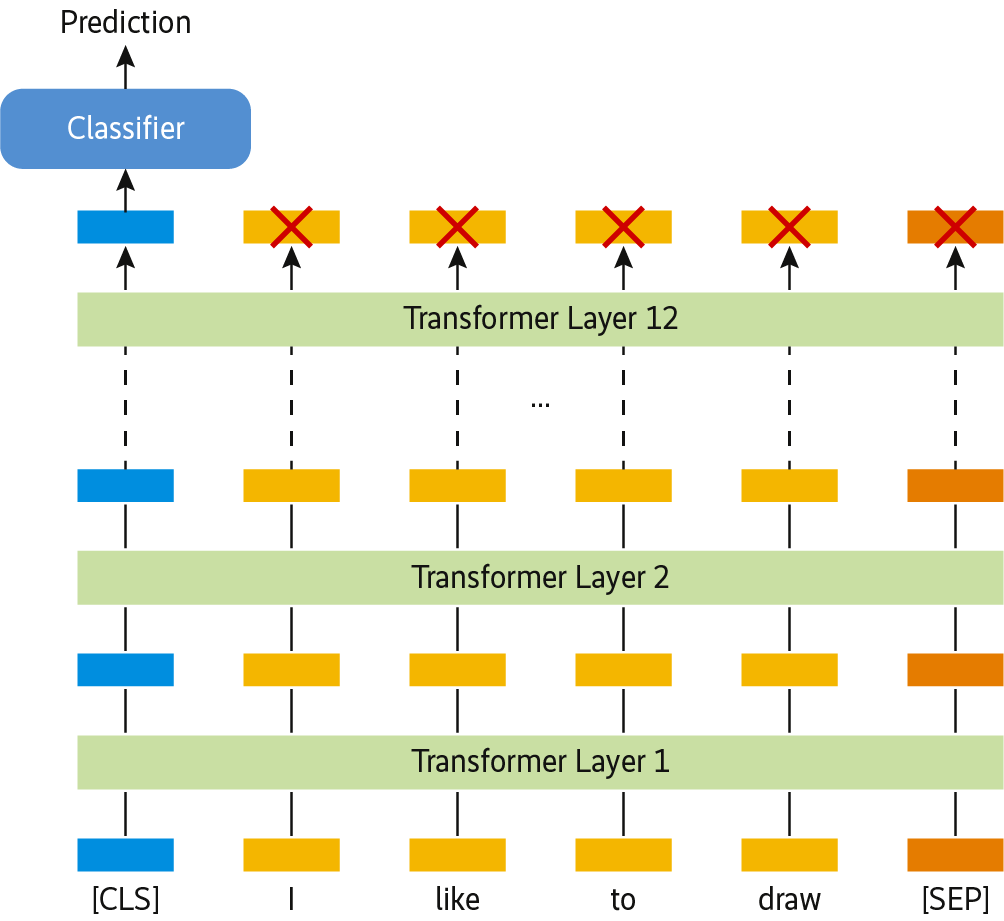
(Bild: Chris McCormick)
Besonders gut geeignet ist das Vorgehen für Aufgabenstellungen wie Sentiment-Analyse, in denen es auf die Semantik der Sätze ankommt. Für den Heise-Newsticker ließe sich das System unter anderem effektiv einsetzen, um Troll-Kommentare zu erkennen. Der folgende Code versucht, mit BERT vorherzusagen, welche Headlines besonders viele Kommentare auf sich ziehen. Dazu ist der komplette Datensatz in solche mit wenigen (<20) und solche mit vielen Kommentaren (>100) unterteilt:

Das in Machine-Learning-Szenarien übliche und wichtige Vorgehen, mit einem Trainings- und Testdatensatz zu arbeiten, entfällt im Beispiel, um den Code nicht unnötig aufzublähen. Trotz des fehlenden Abgleichs ist die Klassifikationsperformance recht gut.
Question Answering
Statt BERT auf die Heise-Headlines zu tunen, lässt es sich auf andere Anforderungen optimieren. Besonders populär und beeindruckend ist dabei das sogenannte Question Answering.
Data Scientists starten mit einem trainierten Sprachmodell, das sie mit einem sogenannten Squad-Korpus feintunen, bei dem sie als Trainigsmenge viele Texte mit den dazugehörigen Fragen zur Verfügung stellen. Das jeweilige Vorhersageergebnis ist die Antwort auf die Frage, die im Text vorhanden sein sollte. Das Modell wird auf diese Fragen-Antworte-Paare trainiert.
Was unglaublich klingt, lässt sich in der Praxis gut einsetzen und produziert gespenstisch gute Resultate. 2019 gelang es einem Forscherteam, ein System zu trainieren, das den amerikanischen Schulabschluss der zehnten Klasse mit 80 Prozent Score bestehen kann. Dabei handelt es sich zwar um einen Multiple-Choice-Test, aber eine gute Zahl von Schülern bestehen den Test nicht.
Das Experiment im Rahmen dieses Artikels ist etwas bescheidener: Ein Bot soll ein paar Fragen zum Wikipedia-Artikel über Raumschiff Enterprise beantworten. Lustig ist am Rande, wie wenig tief das Verständnis des Systems tatsächlich ist, wenn es auf Fragen antwortet, deren Antwort sich im Text nicht findet

Rück- und Ausblick
BERT ist durchaus eine kleine Revolution im Bereich des NLP. Dank Transfer Learning lassen sich mit zumindest überschaubarem Aufwand umfangreiche Sprachmodelle erstellen, die inhaltliche Zusammenhänge in beliebigen Texten sinnvoll erfassen können.
Die Codebeispiele waren bisher auf vorberechnete BERT-Modelle begrenzt. Für weitere Anwendungszwecke existieren spezielle Varianten wie SciBERT und MedBERT. Sie erfordern jedoch abhängig von der Domäne weitere Anpassungen, damit BERT zum Fachexperten werden kann. Zu den Themen hat heise Developer einen weiteren Artikel in Planung, der im Herbst erscheinen soll.
Christian Winkler
ist Data Scientist und Machine Learning Architect. Er promovierte in theoretischer Physik und arbeitet seit 20 Jahren im Bereich großer Datenmengen und Künstliche Intelligenz, insbesondere mit Fokus auf skalierbaren Systemen und intelligenten Algorithmen zur Massentextverarbeitung. Er ist Gründer der datanizing GmbH, Referent auf Konferenzen und Autor von Artikeln zu Machine Learning und Text Analytics.
(rme)
