

Wer, wie, was: Textanalyse über Natural Language Processing mit BERT
Zwei Verfahren, deren Akronyme Namen von Figuren aus der Sesamstraße entsprechen, haben den Bereich NLP in jüngster Zeit deutlich vorangebracht: ELMo und BERT.

(Bild: Shutterstock)
- Dr. Christian Winkler
Die Analyse von Texten über Natural Language Processing (NLP) hat in den letzten Jahren aus mehreren Gründen einen beispiellosen Höhenflug erlebt. Einerseits stehen durch das Internet genügend große Textmengen zur Verfügung, deren Analyse realen geschäftlichen Mehrwert schaffen kann. Andererseits ist die Rechenleistung ausreichend stark angestiegen, um die Datenmengen gut zu verarbeitet. Schließlich sind viele Methoden entstanden, die eine effektive Verarbeitung solcher natürlichsprachlicher Texte erlauben.
Klassische Textanalyse mit Machine Learning
Über viele Jahre setzen Data Scientists zur Textanalyse und -klassifikation hauptsächlich auf sogenannte Bag-of-words-Modelle beziehungsweise die davon abgeleiteten TF/IDF-Modelle (Term Frequency, Inverse Document Frequency). Da fast alle Analyseverfahren Machine Learning verwenden, gilt es zunächst, die Dokumente in Vektoren umzurechnen. Der erste Schritt ist das Durchnummerieren des Vokabulars, und der Zugriff auf die Wörter erfolgt im Anschluss über die laufenden Nummern. Die Gesamtmenge aller Dokumente (Corpus) lässt sich damit als eine Matrix darstellen, die Dokument-Term-Matrix heißt (s. Abb. 1). Sie ist die Basis für weitergehende Analysen sowohl für Supervised als auch für Unsupervised Machine Learning.
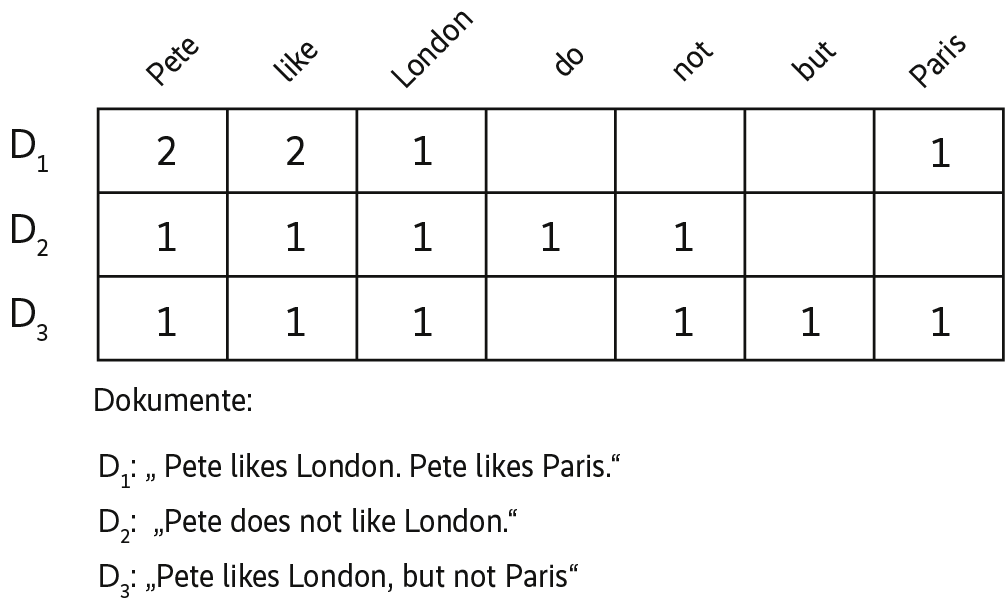
Das Verfahren lässt sich unter anderem durch das Berücksichtigen von Wortkombinationen (N-Gramme) verfeinern. Wer nur einzelne Wortarten oder lediglich die Grundformen der Wörter berücksichtigen möchte, kann eine linguistische Voranalyse nutzen. Mit einer TF/IDF-Transformation ist es möglich, besonders häufige Wörter weniger stark zu gewichten, weil sie eine geringere Trennschärfe haben.
In jedem Fall repräsentiert eine bloße Zahl ein Wort beziehungsweise ein N-Gramm. Für viele Aufgaben wie einfache Klassifikation oder Topic Modeling sind diese Verfahren absolut ausreichend und finden nach wie vor häufig Anwendung. Allerdings lässt sich damit nicht die Bedeutung von Wörtern erfassen, was besonders schwer bei Synonymen zu Buche schlägt, die als komplett unabhängige Entitäten existieren.
Semantik mit Wortvektoren
Diese Schwächen sind seit längerer Zeit bekannt. 2013 konnte der seinerzeit bei Google beschäftigte Thomas Mikolov jedoch einen Durchbruch mit einer Arbeit erzielen, die er zusammen mit Kai Chen, Greg Corrado und Jeffrey Dean verfasst hatte.
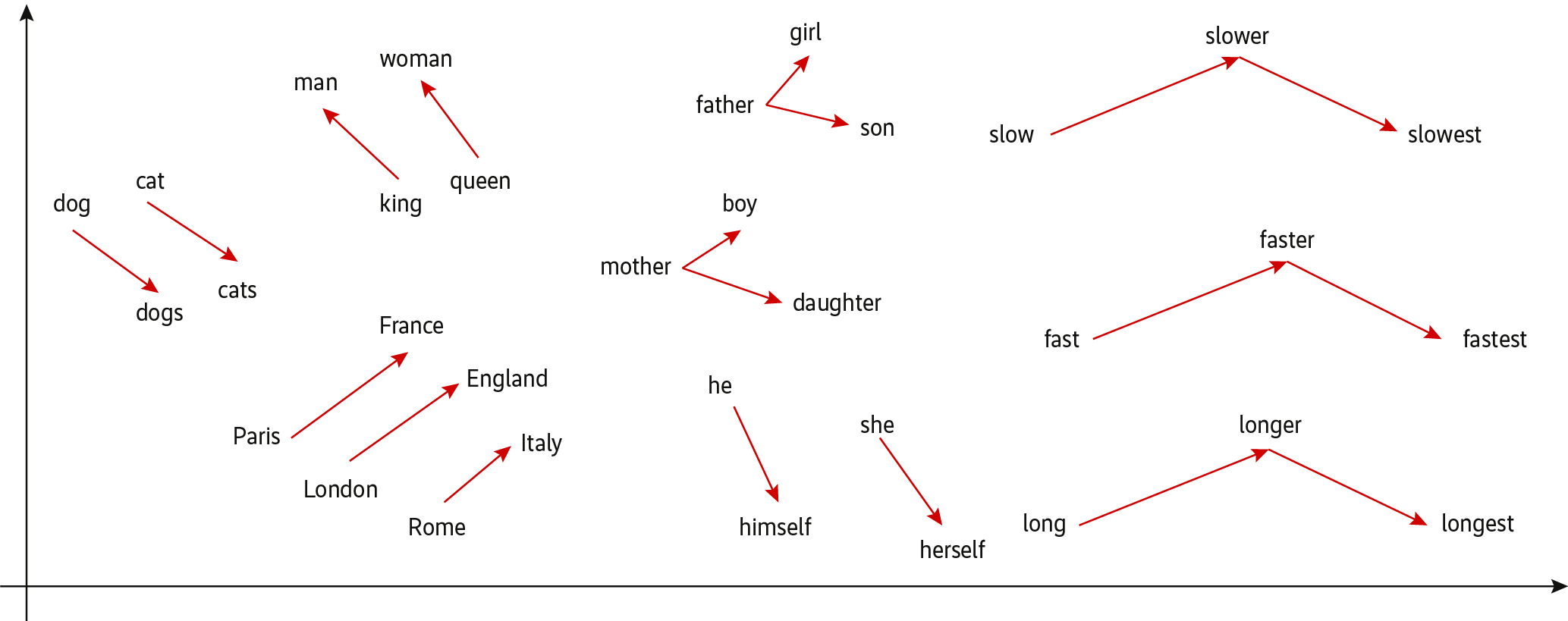
Durch das Training eines neuronalen Netzes gelang es ihm, aus fortlaufenden Texten Vektoren für Wörter zu finden, die deren Semantik repräsentieren. Die Bezeichnung Word Embeddings kommt daher, dass die Wörter in einen verhältnismäßig niedrigdimensionalen Raum eingebettet sind. Mikolov hat die Dimension 300 verwendet, die immer noch häufig anzutreffen ist. Das Verfahren heißt word2vec, und die daraus entstehenden Wortvektoren (s. Abb. 2) haben erstaunliche Eigenschaften:
- Wortvektoren semantisch ähnlicher Wörter haben einen geringen Abstand (als Abstandsmaß ist der Winkel zwischen solchen Vektoren definiert).
- Wortvektoren können semantische Unterschiede fassen, woraus sich Gleichungen der Form
Apple – iOS = Google – Xaufstellen lassen, aus der das System für den Platzhalter X die Auflösung "Android" bestimmen kann. - Neben semantischen kann das Modell auch syntaktische Ähnlichkeiten repräsentieren. Daraus lassen sich unter anderem Steigerungsformen von Adjektiven oder Zeitformen von Verben ableiten.
- Besonders erstaunlich ist, dass das Training mit unstrukturierten Texten erfolgt, weshalb keine vorklassifizierten Daten notwendig sind. Das vereinfacht die Suche nach geeigneten Trainingsdaten.
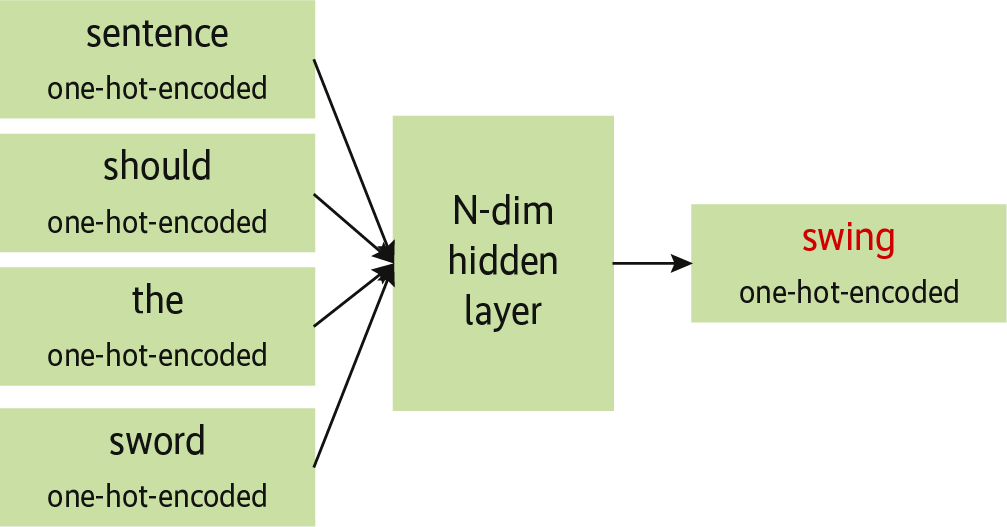
Die Grundidee der im Rahmen dieses Artikels nur am Rand vorgestellten Lernverfahren ist, die Wortvektoren auf solche Art zu justieren, dass sich ein Wort aus seinem Kontext vorhersagen lässt. Dieses Verfahren nennt sich Continuous-Bag-Of-Word-Modell (CBOW)(s. Abb. 3).
Für das Training mit umfangreichen Daten kehren Data Scientists das Modell häufig um und trainieren es darauf, aus dem Wort den gesamten Kontext vorherzusagen. Die Wortvektoren haben dabei ebenfalls die oben beschriebenen Eigenschaften. Einigermaßen erstaunlich ist, wie viel "Wissen" sich aus den reinen Textdaten extrahieren lässt.
Um zu überprüfen, ob das Modell so gut wie behauptet arbeitet, hat der Autor dieses Artikels das Modell mit den Daten des Heise-Newstickers von 1998 bis zum Mai 2020 trainiert. Auch wenn die Verarbeitung erstaunlich schnell erfolgt ist, sollen in erster Linie die Ergebnisse interessieren. Das Jupyter-Notebook ist auf GitHub verfügbar. Es lässt sich sowohl lokal als auch auf Google Colab ausführen.
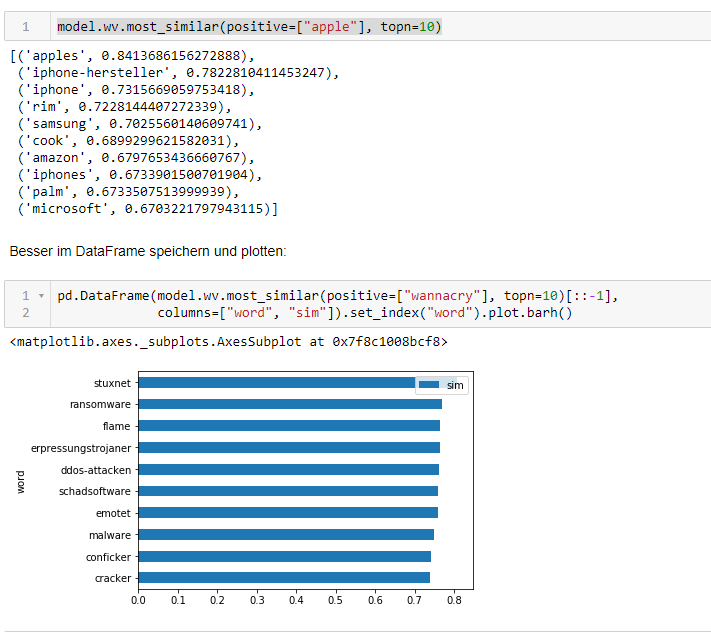

Wer ein solches Training effektiv durchführen möchte, sollte allerdings darauf achten, dass die Datenmenge groß genug ist. Gute Ergebnisse sind erst ab etwa einer Million Wörter zu erwarten.
Neben word2vec existieren für Wortvektoren noch fastText von Facebook und gloVe von der Universität Stanford. Die Funktionsweise ist im Detail unterschiedlich, die Ergebnisse sind jedoch oft vergleichbar.
Sprache besteht aus Sätzen
Mit word2vec gelingt es, semantische Beziehungen zwischen Wörtern herzustellen. Das aufgeführte Beispiel zeigt, dass sich damit Synonyme gut abdecken und finden lassen.
Sprache ist allerdings deutlich mehr als die reine Aneinanderreihung von Wörtern. Die word2vec-Methoden lassen sich verallgemeinern auf die Embeddings von Sätzen oder ganzen Dokumenten (doc2vec), allerdings ist durch die große Vielfalt unterschiedlicher Sätze ein Ähnlichkeitsmaß schwierig anwendbar.
NLP-Experten haben weiter geforscht und sich auf die sogenannte Kontextualisierung konzentriert. Die Bedeutung eines einzelnen Worts ist häufig für sich nicht zu erschließen, weil es ein ganzes Bedeutungsspektrum abdeckt. Gut erkennbar ist die Sachlage bei Homonymen: Wörter mit unterschiedlichen Bedeutungen wie im Kinderspiel Teekesselchen.
Der nächste Schritt besteht somit darin, die Kontexte zu erschließen, womit der Bereich der Sprachmodelle erreicht ist. Um ganzen Sätzen eine Semantik zuzuordnen und sich damit implizit die Bedeutung der jeweiligen Wörter genauer zu erschließen, ist die sogenannte Kontextualisierung notwendig. Homonyme sind ein Extremfall, aber Wörter können durchaus abhängig von ihrer Verwendung subtil unterschiedliche Bedeutungen haben. Das lässt sich prinzipiell kaskadiert betrachten, denn die wahre Bedeutung von Sätzen erschließt sich oft erst über Absätze und deren Bedeutung über Dokumente. Besonders auffällig ist das bei Stilmitteln wie Ironie, die ein Wort, einen Satz oder einen Absatz in das komplette Gegenteil verkehren.
Die dafür notwendige Kontextualisierung kann auf unterschiedliche Arten erfolgen, und die einzelnen Verfahren haben unterschiedliche Ansätze.
