

Intel: Mit Pentium-Kernen gegen Nvidia und ATI [Update]
Intels Chip fürs Visual Computing namens Larrabee setzt auf den guten alten Pentium P54C oder, genauer gesagt, auf Kerne mit dessen einfacher aber effizienten In-Order-Pipeline.
- Andreas Stiller

Das Prozessorgeflüster hatte es schon vorab verbreitet, nun ist es offiziell: Intels Chip fürs Visual Computing namens Larrabee setzt auf den guten alten Pentium P54C oder, genauer gesagt, auf Kerne mit dessen einfacher aber effizienten In-Order-Pipeline. Nur wird Larrabee nicht nur einen P54C-artigen Kern enthalten, sondern deren viele, und die nicht wie damals in 500- oder 350-nm-, sondern in aktueller 45-nm-Technik.
Die genaue Anzahl der Kerne hat Intel noch nicht bekannt gegeben, man geht davon aus, dass zu Beginn bis zu 32 Kerne auf einem Chip integriert sind. Die Fähigkeiten der P54C-Kerne wurden zudem massiv erweitert, so beherrschen sie jetzt AMD64-kompatible 64-Bit-Operationen und vierfaches simultanes Multithreading (SMT). Dieses SMT kann die Nachteile der einfachen In-Order-Architektur – insbesondere Wartezeiten beim Speicherzugriff – weitgehend kompensieren.
Außerdem sollen die Kerne nicht selber rechnen, sondern nur organisieren und kontrollieren. Fürs eigentliche Rechnen steht jedem Kern eine neu designte Vektoreinheit (VPU) zur Seite, die 16 Gleitkommaoperationen in einfacher Genauigkeit (also mit 512 Bit Breite) ausführen kann – viermal soviel wie die SSE-Einheit aktueller Intel-Prozessoren. Diese Vektoreinheit bietet auch mehr Register als SSE, wieviel, darüber hüllt sich Intel noch in Schweigen – es dürften 32 sein. Die VPU beherrscht das Rechnen mit einfach und doppeltgenauen Gleitkomma- sowie 32bittigen Integer-Operanden.
Da die Vektoreinheit auch "fused multiply-add"-Befehle unterstützt, also Multiplikation und Addition in einem Schwung, kommt sie im Durchsatz auf bis zu 32 FLOPs pro Takt. Mithin ergibt sich bei 32 Kernen und angenommenen 2 GHz Takt eine nackte Rechenperformance von Larrabee in einfacher Genauigkeit von 2 TFLOP/s, rund das Doppelte einer ATI 4850.
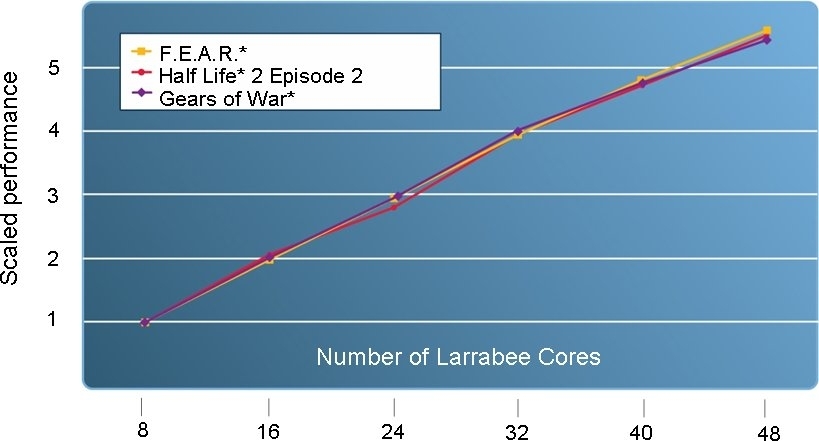
Doch nackte, theoretische Rechenperformance ist beim "Visual Computing" nur ein recht kleiner Teil der Miete. Weit wichtiger ist, wie die einzelnen typischen Grafikaufgaben zusammenspielen: Vertex&Geometrie-Shading, Pixel-Setup, Rasterization, Z-Operationen, Alpha-Blending, Antialiasing, et cetera. Und bei DirectX 11 kommt noch Tessellation dazu – alles komplexe Aufgaben, die von der Konkurrenz zum Teil mit spezifischer Hardware gelöst werden, bei Larrabee indes weitgehend in Software. Das ist zwar flexibler, braucht aber mitunter mehr Zeit. Larrebee hat für bestimmte, bislang nicht genauer umschriebene Funktionen aber auch eine "fix function unit". Auch das Texture Mapping übernimmt eine spezielle Hardware, die für 8-Bit-Texturen optimiert ist – nur sind 8-Bit-Texturen nicht mehr ganz Stand der Technik. Wie das mit FP16-Texturen und High Dynamic Range Rendering aussieht, bleibt abzuwarten. Ein bisschen veraltert sind auch die Analysen, die Intel aufführt, denn sie betreffen Spiele der vergangenen DirectX-9-Zeit wie F.E.A.R, Gears of War und Half Life 2.
Damit das Software-Rendering effizient auf die Kerne verteilt werden kann, wird bei Larrabee der Bildschirm wie bei PowerVR in Kacheln (tiles) aufgeteilt, deren Daten in die zugeordneten L2-Cache-Partitionen passen (Binning Rendering). Zum Software-Konzept gehört ferner eine filigrane Zerlegung der Rechenschritte nicht nur auf die Kerne und in Threads sondern auch in Fiber und Strands -- alles Tricks um die verschiedenen Latenzzeiten geschickt zu überbrücken. Mit Strands oder Strands-Gruppen kann man einzelne Registerteile der VPU, die SIMD-Lanes, quasi unabhängig voneinander programmieren. Spezielle Maskenregister vereinfachen dabei den Umgang mit Konditionen für If-Then-Else-Zweige. Mit den Strands lassen sich "virtuell" die Anzahl der quasi gleichzeitig laufenden Microthreads auf bis zu 16 pro Kern und Thread erhöhen. Das klingt nach viel, aber die Konkurrenz ist diesbezüglich zum Teil schon weiter. So kann Nvidias GPU bei der GT200 in seinen Warps genannten Threads bis zu 30.720 Microthreads on the fly haben. Andererseits hat Intel die parallellaufenden skalaren x86-Kerne, die viele Kontrollaufgaben wahrnehmen können, die bei Nvidia zusätzliche Microthreads erfordern.
Von elementarer Wichtigkeit ist auch, wie viel Daten wie schnell zwischen Hauptspeicher einerseits und zwischen den Kernen und den spezifischen Units andererseits transferiert werden können. Larrabee hat einen partitionierten L2-Cache mit 256 KByte/Kern, an dem ein "übliches Speicherinterface" für Grafikkarten angekoppelt ist. Der Verkehr zwischen den Kernen wird von zwei Ringbussen à 64 Byte Breite getragen. Das ist nicht arg viel: Nur zwei Ringbusse für 32 Kerne. IBM etwa hat für nur acht Synergistic Processing Elements im Cell-Prozessor immerhin doppelt so viele Ringbusse vorgesehen. ATI hat mit Ringbussen offenbar auch keine so guten Erfahrungen gemacht und bei der 48xx-Linie wieder davon Abstand genommen.
Larrabee soll als Visual Prozessor auf Basis der Intel-Architektur mehr können, als nur Pixel zu rastern. Dazu gehören Ray-Tracing und andere typische Rechenaufgaben. Speziell fürs High-Performance-Computing soll später Larrabee 2 herauskommen, vermutlich ohne Texture-Unit aber vielleicht mit einer speziellen Fix-Function-Unit für diesen Einsatzbereich. Mehr zum Thema Larrabee will Intel auf der SIGGRAPH 2008 am 12. August präsentieren.
[Update]:
Beim Zeitplan für Larrabee ging man bislang von einem Launch im ersten Quartal 2009 aus. Das hat Intel jetzt aber nicht bestätigt,sondern nur recht schwammig 2009/2010 benannt:"expected in 2009 or 2010". Erste Muster für Entwickler, so verlautete hinter den Kulissen, sollen aber schon Ende dieses Jahres zur Verfügung stehen.
(as)
