

Trainierte Modelle in mobilen Apps einsetzen
Smartphones besitzen inzwischen eine ausreichend hohe Rechenleistung, um trainierte ML-Modelle direkt ausführen können. Mit CoreML und TensorFlow Lite existieren Frameworks, um Machine Learning auf mobile iOS- und Android-Geräte zu bringen.

(Bild: Canstock)
- Lars Gregori
Die Hauptgründe, ein Machine-Learning-Modell innerhalb einer mobilen Anwendung laufen zu lassen, liegen in der Privatsphäre, Geschwindigkeit und Verfügbarkeit. Fotos und Texte müssen nicht mehr das Gerät verlassen, um beispielsweise Personen oder Gegenstände auf einem Bild zu erkennen. Die Internetverbindung und deren Verfügbarkeit spielen keine Rolle, da die Anwendung keine Daten überträgt und somit nicht auf ein Ergebnis wartet. Das wirkt sich auf die Geschwindigkeit aus und ermöglicht Anwendungen, die große Datenmengen oder Videos mit Machine Learning verarbeiten. Zusätzlich erübrigt sich eine skalierbare Serverfarm, die für die Erkennung zuständig ist. Jedoch sollte man die Größe der Modelle und die benötigte Rechenleistung auf dem mobilen Endgerät beachten.
Sonderheft iX Developer – Machine Learning
Mehr Artikel zu Machine und Deep Learning sowie zur Künstlichen Inteligenz sind im Sonderheft "iX Developer – Verstehen, verwenden, verifizieren" zu finden, das unter anderem im heise Shop erhältlich ist.
Ein mit leistungsstarker Hardware ausgestatteter Rechner trainiert das Modell anhand von Trainings- und Zieldaten. Das Ergebnis lässt sich testen und weiterverwenden. Das kann entweder auf einem Server erfolgen oder als konvertiertes Modell auf dem Smartphone. Sowohl Android als auch iOS bieten die Möglichkeit, bereits trainierte oder eigens erstellte Modelle in eine Anwendung einzubinden. CoreML ist nur für iOS verfügbar, während TensorFlow Mobile und TensorFlow Lite beide Welten unterstützen.
Kern und Apfel
Apple hat 2017 auf der Entwicklerkonferenz WWDC 2017 mit den CoreML-Tools eine Software zum Umwandeln trainierter Modelle für CoreML vorgestellt. Zudem existieren bereits trainierte Modelle zum Verwenden in eigenen Anwendungen. Neben iOS lässt sich die Bibliothek unter macOS, watchOS und tvOS nutzen.

Zwischen CoreML und der Hardware liegen das Accelerate Framework mit den Basic Neural Network Subroutines (BNNS) und die Metal Performance Shaders (s. Abb. 1). Letztere sind die Schnittstelle zur Grafikkarte (GPU), während das Accelerate Framework Vektorrechnungen auf der CPU ausführt. iOS entscheidet, welcher Layer eines Machine-Learning-Modells auf der CPU oder GPU läuft. Die Anwendung wiederum muss nicht direkt auf CoreML zugreifen, sondern kann verschiedene Frameworks nutzen: das Vision Framework zur Bildanalyse, Natural Language für die Verarbeitung natürlicher Sprache und das GameplayKit-Framework für die Auswertung von Entscheidungsbäumen.
Schlankes TensorFlow
Im Moment gibt es mit TensorFlow Mobile und TensorFlow Lite zwei für mobile und Embedded-Geräte zugeschnittene Versionen des Frameworks, die auf Android, iOS und auch auf einem Raspberry Pi laufen. TensorFlow Lite ist seit Dezember 2017 die Weiterentwicklung von TensorFlow Mobile und steht im Fokus dieses Artikels. Da es sich noch in der Entwicklung befindet, deckt es im Gegensatz zum Vorgänger noch nicht alle Anwendungsfälle ab und kennt nicht alle TensorFlow-Operatoren. Jedoch sind die Applikationen kleiner, haben weniger Abhängigkeiten und eine bessere Leistung. Zusätzlich unterstützt TensorFlow Lite ab Android 8.1 (API Level 27) die Hardwarebeschleunigung mit der Android Neural Networks API.
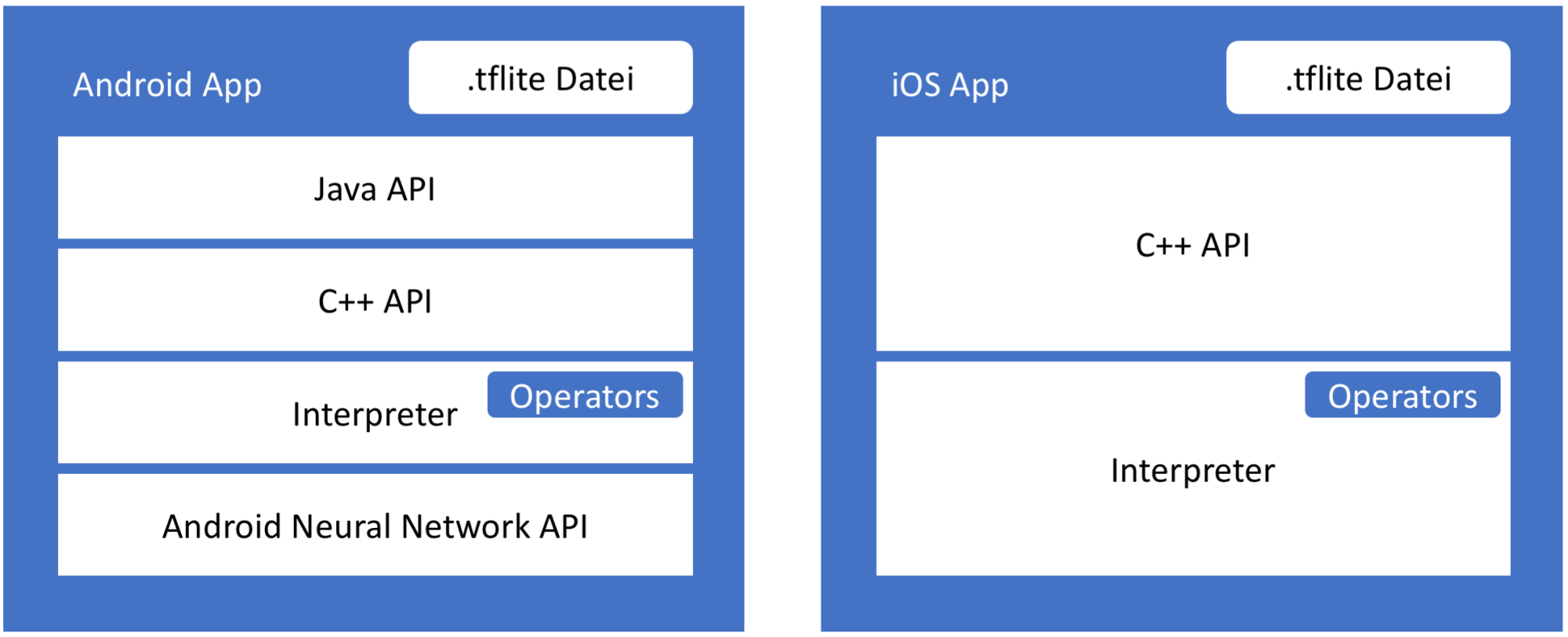
Der TensorFlow Lite Optimizing Converter (TOCO) konvertiert ein trainiertes TensorFlow-Modell in ein TensorFlow-Lite-Modell (.tflite). Für Android existiert eine Java-Schnittstelle zum Einbinden der C++-API. Die C++-Bibliothek existiert sowohl für Android als auch iOS. Sie lädt das TensorFlow-Lite-Modell und ruft den Interpreter auf, der das Modell und die TensorFlow-Operatoren ausführt. Auf bestimmten Android-Geräten nutzt der Interpreter die Hardwarebeschleunigung über die Android Neural Network API.
Beispiel Objekterkennung
Für das erste Beispiel beschränkt sich der Artikel auf ein bereits trainiertes Modell zur Erkennung von Objekten in Bilder, konkret das Inception-V3-Modell. Es erkennt 1000 Objekte wie Bäume, Tiere, Menschen und Fahrzeuge. Es ist mit etwas weniger als 100 MByte relativ klein und hat eine geringe Fehlerrate. Das Modell listet das richtige Objekt mit einer Wahrscheinlichkeit von 96,54 Prozent innerhalb der Top-5-Vorschläge.
Sowohl für CoreML als auch TensorFlow Lite existieren Inception-V3-Modelle. Der Vorteil eines bereits trainierten Modells liegt darin, dass Entwickler keine zusätzlichen Trainingsdaten benötigen und vor allem nicht die Zeit und Rechenkapazität aufwenden müssen, um ein solches Modell zu trainieren. Zudem ist es nicht notwendig, das dahinterliegende Modell und dessen internen Aufbau zu verstehen.
Die Beispielanwendungen verlangen weder ein Android-Gerät noch ein iPhone, da sie innerhalb eines Emulators oder Simulators laufen können. Die Android-Beispiele benutzen Android Studio. Für die iOS-Beispiele ist ein Apple-Gerät notwendig, auf dem Xcode läuft.
Die Beispiel-Apps für iOS und Android sind gleich aufgebaut. Im oberen Teil der Anwendung befinden sich drei Bilder zur Auswahl. Beim Anklicken eines Bildes erscheint es in einer vergrößerten Darstellung. Die Vorhersageberechnung verwendet das ausgewählte, und die Anwendung zeigt das Ergebnis des am besten erkannten Objekts mit dem Prozentwert der Übereinstimmung und dem Namen des Objekts an. Um die Anwendung einfach zu halten, verwendet sie vordefinierte Bilder und benötigt keinen zusätzlichen Programm-Code für eine Kamerasteuerung und Bildumwandlung. Zudem bleiben die Ergebnisse durch die vordefinierten Bilder immer konstant. Außerdem muss sich niemand auf die Suche nach einem echten Elefanten machen.
Inception V3 und CoreML
Das Inception-V3-Modell findet sich auf der Apple-Seite zum Download. Es lässt sich per Drag-and-drop in Xcode einfügen, woraufhin die Entwicklungsumgebung eine Klasse erstellt, die alle notwendigen Schnittstellen enthält, um das Modell zu laden, die Ein- und Ausgabe-Typen und die Prediction-Methode, um eine entsprechende Vorhersage zu treffen:
override func viewDidLoad() {
super.viewDidLoad()
let model = try? VNCoreMLModel(for: Inceptionv3().model)
let request =
VNCoreMLRequest(model: model!,
completionHandler: resHandler)
requests.append(request)
}
@IBAction func predict(_ sender: UIButton) {
selectedImage.image = sender.currentImage
let image = sender.currentImage!.cgImage!
let handler = VNImageRequestHandler(cgImage: image,
options: [:])
try? handler.perform(requests)
}
func resHandler(request: VNRequest, _: Error?) {
let results = request.results
as! [VNClassificationObservation]
let percent = Int(results[0].confidence * 100)
let identifier = results[0].identifier
resultLabel.text = "\(percent)% \(identifier)"
}
Der Aufbau der Anwendung erfolgt in relativ wenigen Schritten, bei denen man sich keine Gedanken um die Bildkonvertierung machen muss. CoreML nutzt hierfür das Vision Framework, um die Bilder automatisch in das Zielformat des Modells zu konvertieren.
Die viewDidLoad-Methode lädt über die VNCoreMLModel-Klasse das Modell. Die VNCoreMLRequest-Klasse erzeugt einen Request mit diesem Modell und einer completionHandler-Methode als Parameter – in diesem Fall der resHandler-Methode. Ein Array sammelt die Request-Instanzen, von denen es im Beispiel lediglich eine gibt. Es ist durchaus möglich, mehrere Requests von unterschiedlichen Modellen aufzunehmen. Der Klickvorgang beim Auswählen eines Bildes ist als IBAction mit der predict-Methode verknüpft. Diese setzt das ausgewählte Bild und erzeugt einen Handler vom Typ VNImageRequestHandler mit der Auswahl. Die perform-Methode des Handlers erhält das Array mit den Request-Instanzen, die wiederum die resHandler-Methode enthält. Deren Aufruf erfolgt nach dem Abschluss der Objekterkennung, und sie passt den Text des resultLabel-Feldes an, indem sie das Ergebnis des ersten erkannten Objekts verwendet. Xcode erzeugt für die Ergebnisse der Inception-V3-Klasse entsprechende Properties, um direkt auf den Prozentwert der Übereinstimmung (confidence) und dem Identifier zuzugreifen, der in diesem Fall der Name des gefundenen Objekts ist.
Inception V3 und TensorFlow Lite
Das Inception-V3-Modell für TensorFlow Lite befindet sich auf GitHub. Folgendes Listing benötigt die Dateien "inception_v3.tflite" und "labels.txt" im assets-Verzeichnis des Android-Projekts:
protected void onCreate(Bundle savedInstanceState) {
// ...
reader = new BufferedReader(... "labels.txt")));
// ...
labels.add(line);
// ...
tflite =
new Interpreter(loadModelFile("inception_v3.tflite"));
button1.setOnClickListener(new View.OnClickListener() {
@Override
public void onClick(View v) {
predict(context, R.drawable.image1);
}
});
button2.setOnClickListener(new View.OnClickListener() {
// ...
});
button3.setOnClickListener(new View.OnClickListener() {
// ...
});
}
private void predict(Context context, int imgId) {
// ...
Bitmap bitmap =
BitmapFactory.decodeResource(..., imgId, ...);
image.setImageBitmap(bitmap);
// ...
ByteBuffer imgBuf = convertBitmapToByteBuffer(bitmap);
float[][] labelProb = new float[1][labels.size()];
tflite.run(imgBuf, labelProb);
String label = "";
Float percent = -1.0f;
for(int i = 0; i < labels.size(); i++) {
if (labelProb[0] [i] > percent) {
percent = labelProb[0][i];
label = labels.get(i);
}
}
percent *= 100;
result.setText(percent.intValue() + "% " + label);
}
private ByteBuffer convertBitmapToByteBuffer(Bitmap bitmap) {
// ...
bitmap = Bitmap.createScaledBitmap(...);
// ...
imgData.putFloat((val >> 16) & 0xFF);
imgData.putFloat((val >> 8) & 0xFF);
imgData.putFloat(val & 0xFF);
// ...
return imgData;
}
private MappedByteBuffer loadModelFile(String modelFile) {
// ...
}
Das Laden des TensorFlow-Lite-Modells "inception_v3.tflite" erfolgt mit der loadModelFile-Hilfsmethode, die die Modelldatei einliest und als MappedByteBuffer zurückliefert. Basierend darauf erzeugt die Interpreter-Klasse eine TensorFlow-Lite-Instanz. Letztere beinhaltet eine run-Methode, die als Parameter ein input- und ein output-Objekt benötigt. Hierdurch ist die Methode generisch, jedoch müssen sich Entwickler um die entsprechenden Ein- und Ausgabetypen kümmern.
Wie schon im iOS-Beispiel wählen Anwender ein Bild auf der Oberfläche aus, wodurch der onClickListener die predict-Methode mit der Bild-ID aufruft. Diese lädt das Bild und zeigt es groß an. Außerdem passt die convertBitmapToByteBuffer-Hilfsmethode das Bild auf die richtige Größe an und konvertiert die Bilddaten in einen ByteBuffer, der als input-Wert für die run-Methode dient. Für die output-Werte kommt die von der onCreate-Methode eingelesene "labels.txt"-Datei ins Spiel. Das Programm legt entsprechend der Label-Anzahl ein Array an und befüllt es über die run-Methode mit den entsprechenden Werten. Die Methode ermittelt für jeden Label-Eintrag die Wahrscheinlichkeit zum entsprechenden Objekt und legt die Werte in das labelProb-Array ab. Im Anschluss daran sucht die predict-Methode den Wert sowie das Label mit der höchsten Wahrscheinlichkeit und zeigt diese mit Prozentwert und Namen auf der Oberfläche an.
Die Android-Anwendung ist insbesondere durch das Laden der Modelldatei und die Bildkonvertierung mit den Bit-Shift-Operatoren aufwendig und im Listing nur angedeutet. Das könnte sich möglicherweise in der Zukunft ändern.
Vor dem Start der Anwendung ist in der "build.gradle"-Datei die Abhängigkeit zur TensorFlow-Lite-Bibliothek einzutragen und die aaptOptions, damit die "tflite"- und "lite"-Dateien nicht komprimiert eingelesen werden und einen Fehler verursachen:
aaptOptions {
noCompress "tflite"
noCompress "lite"
}
// ...
implementation 'org.TensorFlow:TensorFlow-lite:+'
Zusätzliches Training
Abbildung 3 zeigt Himbeeren, wird aber als Erdbeere (strawberry) erkannt. Das liegt daran, dass das Inception-V3-Modell keine Trainingsdaten für Himbeeren enthält und die Erdbeere ihr ähnlich scheint. Um dieses Problem zu lösen, lässt sich entweder ein komplett neues Modell trainieren oder ein bestehendes ergänzen. Im letzten Fall können Entwickler mit relativ wenigen Bildern und in kurzer Zeit ein Modell trainieren statt mit einem kompletten Trainingslauf und unzähligen Bildern.

Das Inception-V3-Modell besteht aus einem Convolutional Neural Network (CNN) mit mehreren Schichten und Pools. Bei dem trainierten Modell enthalten die ersten Schichten die Strukturdaten der Bilder wie Geraden und Kurven. In den weiteren Schichten entstehen aus diesen Strukturen bestimmte Merkmale wie Augen. Die letzten Schichten definieren die zu erkennenden Objekte.
Beim Aufsetzen auf ein trainiertes Modell lassen sich die Struktur- und Merkmalsdaten wiederverwenden. Das sogenannte Transfer Learning trainiert lediglich die letzten Schichten mit den eigenen Bildern und passt die Objekterkennung an. Da das Vorgehen trotzdem Rechenleistung und Zeit in Anspruch nimmt, aber nicht unbedingt für das Verständnis des Artikels notwendig ist, geht es im folgenden Beispiel um ein einfaches XOR-Modell, dessen Trainingslauf nur wenige Sekunden benötigt. Dabei definieren Entwickler das Modell, trainieren und konvertieren es und binden es schließlich in die Anwendung ein.
Entweder oder
Die XOR-Funktion liefert beim Aufruf mit zwei Werten, die 0 oder 1 sein dürfen, 1 bei unterschiedlichen und 0 bei gleichen Eingabewerte zurück. Daraus entstehen übersichtliche Trainingsdaten, die nicht aus großen Datenmengen oder vielen Bildern bestehen müssen. Für die Beschreibung des Modells kommen Python und die Keras-Bibliothek zum Einsatz. Letztere bietet eine einfache Schnittstelle für die Modelldefinition, die im Gegensatz zu TensorFlow nicht so feingranular ist. Da Keras auf TensorFlow aufbaut, lässt sich das Modell einfach in ein TensorFlow-Lite-Modell umwandeln. Zudem existiert für CoreML ein Keras-Konverter.
training_data = np.array([[0,0], [0,1], [1,0], [1,1]])
target_data = np.array([ [0], [1], [1], [0]])
model = Sequential()
model.add(Dense(8, input_dim=2, activation=sigmoid))
model.add(Dense(1, activation=sigmoid))
model.compile(loss=mean_squared_error,
optimizer=SGD(lr=1.0))
model.fit(training_data, target_data, epochs=1000)
print model.predict(training_data)
Die Trainingsdaten bestehen aus einem NumPy-Array mit vier Werten aus jeweils zwei Eingabepärchen für die verschiedenen Eingabemöglichkeiten. Die Zieldaten (target_data) bestehen ebenfalls aus einem NumPy-Array mit den Ausgabewerten der XOR-Ergebnisse.
Das Modell ist sequenziell, also fortlaufend aufgebaut und besteht aus zwei Dense-Layern. Einer davon verbindet die Neuronen der Schicht mit allen Neuronen der folgenden Schicht. In der ersten Schicht des neuronalen Netzes besteht der Dense-Layer aus 8 Hidden-Layern und einer Eingabedimension (input_dim) von 2, um die beiden Eingabepärchen der Trainingsdaten abbilden zu können. Zum Aktivieren kommt die Sigmoid-Funktion ins Spiel. Die Aktivierungsfunktion dient vereinfacht ausgedrückt als Berechnungsfunktion der Gewichte des neuronalen Netzes mit dessen Ein- und Ausgabewerten.
Der zweite Dense-Layer besteht aus einem Output-Layer und ebenfalls der Sigmoid-Funktion zum Aktivieren. Die Eingabedimension ergibt sich aus der ersten Schicht – im konkreten Fall durch die 8 Hidden-Layer. Die Hidden-Layer der ersten Schicht sind ebenfalls Output-Layer, da sie sich aber zwischen dem ersten und zweiten Dense-Layer befinden, handelt es sich dabei um versteckte (hidden) Schichten.
Die compile-Methode konfiguriert das Modell für das Training und definiert die Loss-Funktion und den Optimizer. Während des Trainings des neuronalen Netzes berechnet die Loss-Funktion den Wert zwischen dem aktuell berechneten und dem erwarteten Wert. Dessen Minimierung ist die Aufgabe des Optimizers. Das Beispiel verwendet das Stochastic-Gradient-Descent-Verfahren (SGD) mit einer Lernrate von 1,0.
Nach dem Festlegen des Modells startet die fit-Methode das Training mit den entsprechenden Trainings- und Zieldaten. Der epochs-Parameter legt die Anzahl der Durchläufe fest, wobei ein kompletter Datendurchlauf einer Epoche entspricht. Je höher der Wert ist, desto länger läuft der Trainingsprozess, was jedoch nicht zwingend eine Verbesserung zur Folge hat. Die Ergebnisse lassen sich beispielsweise mit dem TensorBoard visuell überprüfen.
Anhand der Beispieldaten führt die predict-Methode eine Vorhersage aus. Bei dem vorhandenen Modell und der Anzahl von 2000 Epochen ergeben sich für die beiden erwarteten 0er-Ergebnisse Werte unterhalb von 0,1. Für die erwarteten 1er-Ergebnisse liegen die Werte oberhalb von 0,9. Nach dem Runden entsprechen die Werte den Zieldaten. Ein gleichbleibender Wert existiert jedoch nicht, da sich die Ausgabewerte mit jedem Trainingslauf ändern. Grund hierfür sind die zufällig initialisierten Werte, mit denen das Modell das Training startet und die Berechnung durchführt.
Speichern der Ergebnisse
Nachdem das Training abgeschlossen ist und die predict-Methode akzeptable Werte liefert, ist es an der Zeit, das Ergebnis festzuhalten und zu speichern. Zunächst geschieht das für das TensorFlow-Lite-Modell. Der TensorFlow Lite Optimizing Converter (TOCO) benötigt ein eingefrorenes Modell. Die from_session-Methode kann das eigentlich selbst erledigen, aber das Vorgehen funktionierte beim Erstellen dieses Artikels noch nicht korrekt.
Ein Modell ist mit verschiedenen Variablen aufgebaut, die der Trainingsprozess mit Werten füllt. Dazu gehören auch die des berechneten Modells. Die Methode convert_variables_to_constants wandelt die Variablen in Konstanten um und friert gleichzeitig das Modell ein. Hierfür benötigt sie die Session, die Graph-Definition, die Ausgabenamen des Models und noch eine Variablenliste, in diesem Fall aus den globalen TensorFlow-Variablen.
freeze_var_names =
list(set(v.op.name for v in tf.global_variables()))
output_names = [model.outputs[0].name.split(":")[0]]
frozen_graph =
convert_variables_to_constants(sess,
sess.graph.as_graph_def(),
output_names,
freeze_var_names)
fgraph = tf.Graph()
with fgraph.as_default():
tf.import_graph_def(frozen_graph, name="")
fsess = tf.Session(graph=fgraph)
toco = tf.contrib.lite.TocoConverter
converter = toco.from_session(fsess,
model.inputs,
model.outputs)
tflite_model = converter.convert()
open("xor.tflite", "wb").write(tflite_model)
Um den eingefrorenen Graphen (frozen_graph) zu verwenden, erzeugt der Code zunächst eine neue Graph-Instanz und importiert ihn dann. Zusätzlich erstellt er eine neue Session mit der erstellten Instanz. Die from_session-Methode erzeugt anhand der neuen Session des Modells und der Input- und Output-Werte einen converter. Die convert-Methode wandelt die Session mit dem Graphen und den trainierten Werten in Binärdaten um, die eine einfache Schreiboperation als "xor.tflite"-Datei speichert. Künftig soll es auch möglich sein, dass der TensorFlow-Lite-Konverter (toco) das Keras-Modell direkt speichert.
Die CoreML-Tools haben bereits mehrere Konverter für verschiedene Machine-Learning-Frameworks, darunter auch Keras. Zusätzlich können auf dem CoreML-Tools-Framework weitere Konverter wie der TensorFlow-Konverter tfcoreml aufbauen. Im Gegensatz zum Keras-Konverter bietet er derzeit jedoch nicht die Option, die Namen der Input- und Output-Werte festzulegen, sondern er erzeugt die Namen anhand des internen Modellaufbaus.
from coremltools.converters.keras import convert
coreml = convert(model,
input_names = 'input',
output_names = ['result'])
coreml.input_description['input'] = '2-dim input array'
coreml.output_description['result'] = 'XOR result'
coreml.short_description = 'XOR model'
coreml.save("xor.mlmodel")
In diesem Codeausschnitt benötigt der convert-Aufruf des Keras-Konverters das Modell. Optional lassen sich die Namen der Input- und Output-Werte angeben. Xcode erzeugt anhand dieser Namen den entsprechenden Code. Zusätzlich beschreiben die description-Properties diese Werte, die Xcode auf einer Übersichtsseite des CoreML-Modells anzeigt. Die save-Methode speichert schließlich das CoreML-Modell.
Eine XOR-App
Nach dem Speichern der Modelle lassen sie sich in die jeweiligen Anwendungen integrieren. Sowohl die Android- als auch die iOS-Anwendung besteht aus vier Textfeldern, die das Ergebnis der vier möglichen Berechnungen anzeigen. Die Ergebnisse sind nicht gerundet, und sollte bei der Konvertierung kein Fehler aufgetreten sein, zeigen sie dieselben Werte an wie die Ausgabe der model.predict-Methode.
protected void onCreate(Bundle savedInstanceState) {
// ...
tflite = new Interpreter(loadModelFile("xor.tflite"));
result00.setText(prediction(0, 0));
result01.setText(prediction(0, 1));
result10.setText(prediction(1, 0));
result11.setText(prediction(1, 1));
}
private String prediction(int a, int b) {
float[][] in = new float[][]{{a, b}};
float[][] out = new float[][]{{0}};
tflite.run(in, out);
return String.valueOf(out[0][0]);
}
Wie beim Inception-Beispiel lädt der Java-Code für Android mit der loadModelFile-Hilfsmethode die TensorFlow-Lite-Modell-Datei, um sie der Interpreter-Instanz zu übergeben. Für alle vier Ergebnisse berechnet die prediction-Methode den Wert. Hierfür benötigt die run-Methode der Interpreter-Instanz ein float-Array mit zwei Eingabewerten, die als Parameter der prediction-Methode übergeben werden. Ebenso benötigt die run-Methode ein zweidimensionales float-Array für die Ausgabe. Nach dem Aufruf befindet sich das Ergebnis, das die prediction-Methode als String zurückgibt, an der Position [0][0]. Die jeweiligen Ergebnisfelder der Oberfläche ersetzen den Text mit dem Ergebniswert.

let model = xor()
override func viewDidLoad() {
super.viewDidLoad()
out00.text = "\(predict(0, 0))"
out01.text = "\(predict(0, 1))"
out10.text = "\(predict(1, 0))"
out11.text = "\(predict(1, 1))"
}
func predict(_ a: Int, _ b: Int) -> NSNumber {
let input_data = try!
MLMultiArray(shape:[2],
dataType: MLMultiArrayDataType.float32)
input_data[0] = NSNumber(value: a)
input_data[1] = NSNumber(value: b)
let xor_input = xorInput(input: input_data)
let prediction = try! model.prediction(input: xor_input)
print(prediction.result.count)
return prediction.result[0]
Die gezeigte iOS-Anwendung hat den gleichen Aufbau wie die Android-App. Xcode generiert dynamisch für das CoreML-Modell Schnittstellen und den entsprechenden Code, sodass ein einfacher Aufruf die XOR-Instanz erzeugt. Die predict-Methode führt die Berechnung aus und erhält die entsprechenden Werte als Parameter, um sie in einem zweidimensionalen MultiArray einzutragen. Die prediction-Methode des CoreML-Modells benötigt als input-Parameter eine xorInput-Instanz mit dem zweidimensionalen MultiArray, um die Berechnung auszuführen. Das Ergebnis, das ebenfalls ein MultiArray ist, enthält den Wert im ersten Element. Diesen gibt die Methode zurück, damit das Textfeld das Ergebnis anzeigen kann.
Für iOS besteht ebenfalls die Möglichkeit, Anwendungen mit TensorFlow Lite zu entwickeln. Hierzu ist aber eine zusätzliche Abhängigkeit zu der TensorFlow-Lite-Bibliothek und die Integration der C++-Bibliothek notwendig. Das ist sowohl in Swift als auch in Objective-C möglich, jedoch aufwendiger als mit CoreML. Interessierte Leser finden beim TensorFlow-Lite-Projekt ein entsprechendes Objective-C-Beispiel.
Des Weiteren bietet das Keras-Modell Möglichkeiten für Experimente: Durch den einfachen Aufbau des Modells lassen sich die einzelnen Methoden und Parameter bequem anpassen. Ebenso ist das Training in wenigen Sekunden beendet. Somit lässt sich beispielsweise die Zahl der Hidden-Layer von 8 auf 16 oder 32 erhöhen oder die erste Aktivierungsmethode durch eine relu-Funktion (Rectified Linear Unit) austauschen, die im Gegensatz zum S-förmigen Graphen der Sigmoind-Funktion einen linearen Verlauf im positiven Wertebereich besitzt. Durch das Hinzufügen eines weiteren Dense-Layers mit 16 Hidden-Layer liefert das Training vergleichbare Ergebnisse bei einem gleichzeitig auf 100 reduzierten epochs-Parameter. Die Änderung wirkt sich jedoch auf die Größe der TensorFlow-Lite- beziehungsweise CoreML-Modelle aus.
Schlankheitskur mit Quantisierung
Das Reduzieren der sogenannten Weight-Werte zum Trainieren des Modells in einen anderen Wertebereich nennt sich Quantisierung (Quantization). Der Trainingsprozess speichert sie als 32-Bit-Float-Wert ab und benötigt somit 4 Byte pro Wert. Das TensorFlow-Lite-Konvertierungstool (toco) kann sie in 8-Bit-Werte umwandeln und reduziert so die Größe des Modells entsprechend. Meistens geht das zu Lasten der Objekterkennungsgenauigkeit. Ein Testlauf mit unterschiedlichen Testbildern kann die Veränderung aufzeigen.
Zudem müssen Entwickler die convertBitmapToByteBuffer-Methode aus dem Android-Beispiel entsprechend von Float- auf Byte-Werte anpassen. Hierzu existiert innerhalb von TensorFlow Lite ein Beispiel, das anstelle eines Inception-V3-Modells ein MobileNet-Modell mit einer 8-Bit-Quantisierung verwendet.
Auf der iOS-Seite bietet CoreML mit der Version 2 ab iOS 12 ebenfalls eine Unterstützung der Quantisierung an und kann die Werte neben 8 Bit auch auf 4, 2 und 1 Bit reduzieren. Das Anpassen des Programmcodes ist nicht erforderlich, jedoch setzt die Quantisierung mit dem CoreML-Tool eine macOS-Version 10.14 beziehungsweise iOS 12 auf dem Mobilgerät voraus.
Fazit
Machine Learning auf dem Smartphone findet zunehmend Verbreitung. Apple, Facebook und Google nutzen entsprechende Methoden bereits in ihren Anwendungen. Zudem verbauen die Hersteller in ihre Geräte spezielle ML-Hardware. Aber auch auf der Softwareseite wird es weitere Verbesserungen geben. So sind für TensorFlow Lite Vereinfachungen unter anderem im Bereich der Bildbearbeitung in Planung. Die neue CoreML-Version ermöglicht durch die Quantisierung kleinere Modelle und durch Batch-Prediction eine schnellere Ausführung. Die im Artikel aufgeführten Beispiele sind auf GitHub zu finden und bieten eine Grundlage, mit denen die Leser trainierte Modelle in Apps einsetzen können.
Lars Gregori
arbeitet als Technology Strategist bei SAP CX in München. Er interessiert sich beruflich und privat für Technologien rund um das Thema Machine Learning und spricht auf Konferenzen zu diesem Thema.
(rme)
