

Showdown bei Zwo-Null-Null
Über Geschmack läßt sich bekanntermaßen trefflich streiten - der eine schwärmt für Bill Gates, der andere schwört auf bunte Äpfel. Doch unter der schönen Bedienoberfläche zählen harte Fakten: Welche Prozessorfamilie verdient den Vorzug, wenn es mehr auf die schiere Rechengewalt ankommt als auf Betriebssystem und Outfit? Wir ließen die aktuellen Champions im PC-Markt, Pentium- und PowerPC-Boliden mit 200 und mehr MHz Taktfrequenz, über ausgesuchte Benchmark-Hürden um die Wette laufen.
- Carsten Meyer
- Christian Persson
- Peter Siering
- Andreas Stiller
Ein Prozessorvergleich über Plattformgrenzen hinweg ist ein vermessenes Unterfangen. Wir erheben denn auch keineswegs den Anspruch, im überschaubaren Rahmen eines Tests und mit irdischen Mitteln eindeutige 'Sieger' küren zu wollen - unter schnöder Missachtung von Vorzügen des einen oder anderen Betriebssystems, ohne Rücksicht auf Preise, Verbreitung und Softwareangebot. Trotzdem ist die Gegenüberstellung gelegentlich notwendig, um den Nebel von Werbesprüchen und Hausmacher-Benchmarks à la iComp etwas aufzulichten. Wir fragen also: Wer bietet mehr Performance, PowerPC oder Pentium(Pro)?
Nicht für den Alltag
Sollten Sie mit Ihrem Windows-PC oder Macintosh nur Texte verarbeiten, im Web surfen oder Daten pflegen wollen (wie 90 Prozent aller Anwender), ist der in diesem Beitrag angestellte Vergleich für Sie ohnehin nur von hypothetischer Bedeutung - etwas Schnelleres als ein 486er oder ein Schmalspur-PowerPC würde sich bei Ihnen nur langweilen. Die hier gegenübergestellten Brummer sind eigentlich nichts für Otto Normalverbraucher, und selbst anspruchsvolle User dürften mit der nächstkleineren Klasse noch gut bedient sein. Gleichwohl rekrutiert sich unsere Testriege nicht aus hochgezüchteten Labormustern, sondern aus real existierendem Konsumgut - etwas teurer zwar in der Anschaffung, aber durchaus käuflich.
Freizeitfördernd
Andererseits bringen Applikationen der Art 'Animationsprogramm mit Radiosity-Renderer' oder 'Bildbearbeitung für A4-Formate' selbst aktuelle Hochleistungs-PCs ins Schwitzen, und wer mit so etwas sein Geld verdienen muß, ist für jeden Prozentpunkt an Mehrleistung dankbar - weil die Luft während der heißen Produktionsphase dank eines schnelleren Rechners nun vielleicht eine halbe Stunde kürzer brennt. Völlig praxisfern ist unser Vergleich mithin nicht. Außerdem: Interessiert uns Golf-fahrende Motorwelt-Leser etwa nicht, was Schumis Werks-Ferrari so unter der Haube hat und warum dauernd Hill gewinnt? - Na also.
Spiele lassen wir an dieser Stelle bewußt außen vor, obwohl uns natürlich klar ist, daß die meisten High-End-PCs gerade wegen ihres Unterhaltungswertes eine Nummer größer als nötig gewählt werden und der dem Manne eigene Spieltrieb die Hardware-Entwicklung maßgeblich vorantreibt (deshalb findet man die leistungsfähigste Computer-Hardware auch eher in der Daddelhalle als beim Grafik-Designer).
Der Fairness halber haben wir die neun Kandidaten in zwei Gewichtsklassen gruppiert (siehe Tabelle Seite 272): In die untere sortierten wir die Maschinen mit Pentium und PowerPC 603e, in die obere die mit PentiumPro und PowerPC 604e. Alle Geräte stammen aus neuester Produktion und sind im Handel, wenn auch zum Teil noch nicht hierzulande.
Zwei-Klassen-Gesellschaft
Im Mittelgewichts-Wettkampf trat ein Compaq Deskpro 5200 gegen einen Macintosh Performa 6400/200 und einen Motorola PowerStack an, im Schwergewicht lief ein Compaq Deskpro 6000 gegen die PowerPC-604e-Mannschaft aus dem neuen Mac-kompatiblen Motorola StarMax 4200, dem Power Macintosh 9500/200, dem fast baugleichen Umax Pulsar 2000 und Taktfrequenz-Rekordhalter PowerTower 225 von Power Computing. Ihm zur Seite stand ein Elaborat aus Andreas Stillers redaktionseigener Tuning-Werkstatt: ein brandneues AMI-Board mit feinster Speicherausstattung. Diesem Superschwergewicht stellten wir einen etwas üppiger ausgestatteten 9500er Mac gegenüber.
Mit der Auswahl der Benchmarks taten wir uns diesmal bewußt schwer: Im Vordergrund sollte ja weniger der Gesamteindruck der Rechnermodelle stehen, sondern vielmehr die Leistung der Prozessoren in ihrer unmittelbaren Hardware-Umgebung, sprich L2-Cache und Hauptspeicheranbindung. Das Ergebnis ist eine wohldosierte Mischung aus synthetischen (wenngleich nicht ganz praxisfremden) Rechenaufgaben und rechenintensiven Anwendungs-Benchmarks.
Die synthetischen Benchmarks sind zum Teil Eigenproduktionen, aber auch Adaptionen 'amtlicher' Meßprogramme, wie etwa der HINT-Suite, die auf einer der nächsten Seiten ausführlich vorgestellt wird. Die Anwendungs-Benchmarks haben uns einiges Kopfzerbrechen bereitet, zumal in der Vergangenheit immer wieder Zweifel an der Gleichwertigkeit von Portierungen für verschiedene Plattformen anzumelden waren. Wir haben deshalb Gespräche mit Herstellern beziehungsweise Entwicklern geführt und detaillierte Auskünfte eingeholt. Nur diejenigen Programmfunktionen, die gemäß plausibler Darstellung vergleichbar gut implementiert sind, wurden in das Testprogramm aufgenommen.
Reimfrei
Leider ließ sich die eine oder andere Ungerechtigkeit nicht vermeiden, die eine oder andere Ungereimtheit nicht vollständig aufklären. Bei den Superschwergewichtlern mußten wir mit der angegebenen sehr üppigen RAM-Bestückung arbeiten, weil die Rechner mit anderen Speicherbausteinen bestimmte Features der Boards (Speicher-Interleave) nicht ausgenutzt hätten. Unsere synthetischen Benchmarks haben wir zwar mit aktuellen Compilern von Microsoft und Metrowerks übersetzt, es stellte sich aber heraus, daß Microsofts Visual C++ für PowerPC nicht immer bestens optimiert. Die Ergebnisse für den PowerPC-Rechner unter Windows NT sind also mit gewissem Vorbehalt zu betrachten - insbesondere, weil NT für PowerPC selbst mit diesem Compiler übersetzt worden sein dürfte. Ferner lagen die Applikationen für die Anwendungs-Benchmarks nicht für alle Plattformen vor, so daß Sie teils mit den synthetischen Werten vorlieb nehmen müssen.
Nestbeschmutzer
Ebenfalls nicht ganz zu vernachlässigen ist die 'Randbedingung' Betriebssystem; so beeinflußt beispielsweise die Verwendung von Windows 95 anstelle von NT die Performance bei einigen Benchmarks äußerst negativ, weil es anscheinend laufend den Cache kontaminiert. Wir haben deshalb auf den entsprechenden Plattformen immer beide Werte angegeben. Das Problem stellt sich auf dem Mac in weitaus geringerem Maße, da ein böswilliger Benchmark-Programmierer dessen kooperatives OS fast völlig zurückdrängen kann und die 'obenliegende' Applikation ohnehin bevorzugt Rechenzeit zugewiesen bekommt - was ansonsten eher von Nachteil ist.
Einer der Rechner, der PowerTower 225, hatte zuvor bei einem Besuch in einer anderen Redaktion sein Netzteil eingebüßt, das bei Inbetriebnahme noch auf US-Verhältnisse (110 Volt) eingestellt war. Unter dem unbeabsichtigten Feuerwerk litten offenbar noch andere lebenswichtige Organe: Wir hatten im Labor immer wieder mit Speicherfehlern und Ausfällen zu kämpfen. Einer der Anwendungs-Benchmarks (Photoshop) lief nur einmal, nach dem Einbau unserer Testfestplatte aber nicht mehr. Die abgedruckten Ergebnisse sind daher nicht ganz so gut, wie sie hätten sein können.
Einen anderen High-Ender mit 604e, ein Modell der brandneuen RS-6000-Serie von IBM, müssen wir Ihnen leider ganz vorenthalten. Der Rechner traf zwar kurz vor Redaktionsschluß noch auf dem c't-Prüfstand ein, aber es gelang trotz nächtelanger Telefonkonferenzen mit IBM-Experten nicht, Windows NT 4.0 darauf zu installieren. Wir konnten nicht einmal unsere synthetischen Benchmarks unter AIX zum Laufen bringen, denn es fehlte der Lizenzcode für den mitgelieferten Compiler. Wir hoffen, die Maschine demnächst noch einmal ins Labor holen und die Ergebnisse in einer späteren Ausgabe nachliefern zu können.
Graue Theorie
Vor dem Startschuß zum Wettkampf lohnt ein Blick auf die Besonderheiten der verschiedenen Prozessor-Architekturen. Mit diesem Hintergrundwissen lassen sich die ermittelten Ergebnisse besser interpretieren, und scheinbare Widersprüche lösen sich womöglich auf:
Pentium und PowerPC sind unter völlig unterschiedlichem Vorzeichen 'aufgewachsen'. Während Pentium und -Pro einem mittlerweile 17 Jahre alten Geschlecht entstammen und direkte, kompatible Nachfahren des klassischen CISC-Bausteins (CISC = Complex In- struction Set Computing) 8086 von Anno 1979 sind, ist die PowerPC-Familie als Spin-Off von IBMs POWER-Architektur mit fünf Jahren noch relativ jung. Grundprinzip ihrer RISC-Bauweise (RISC = Reduced Instruction Set Computing) ist die Fokussierung auf die 10 % der CISC-Befehle, die in der Regel 90 % eines typischen Programms ausmachen - und die auch ein Compiler gern benutzt.
Reduced oder Complex
Doch trotz RISC-Idee steht die PowerPC-Architektur an Befehlsreichtum den Intel-Prozessoren kaum nach. Manch aufwendige und exotische Befehle der x86-ISA (ISA = Instruction Set Architecture) fehlen zwar (etwa ASCII-Adjust-, Tabellen- und Stringbefehle), ebenso die recht komplexen Indizierungen (Scaled-Index-Based-Befehle), dafür bietet sie viele andere, zum Teil ebenso komplexe Möglichkeiten, etwa indizierte Ladebefehle, die zusätzlich zu ihrer eigentlichen Tätigkeit das Indexregister verändern.
Ein entscheidener Unterschied zur Intel-CISC-Architektur ist die konstante Befehlslänge von 32 Bit, was den Befehls-Dekoder erheblich vereinfacht. Andererseits kennt der PowerPC keine 32-Bit-'Immediates', man kann also keinem Register direkt einen 32-Bit-Wert oder eine 32bittige Adresse zuweisen, wie es bei Intel-CPUs in 32-Bit-Umgebungen gang und gäbe ist. Um einen 32-Bit-Wert zu laden, sind beim PowerPC zwei Befehle nötig.
Adreß-Odyssee
Länger noch als bei Intel-Prozessoren dauert die Odyssee, welche die Adressen vom logischen Zustand zu den physikalischen Pins mitmachen. PowerPC beherrscht nämlich vier Mechanismen der Adreßbildung:
- direkt 32bittig (entspricht x86 ohne Paging)
- über die Block Address Translation (BAT), wozu jeweils acht Spezialregister für Daten und Instruktionen Übersetzungsblöcke von 128 KByte bis 256 MByte definieren
- über Segmentregister und Paging Unit: Auch der PowerPC kennt Segmentregister, und zwar gleich 16 Stück. Diese legen Segmente von jeweils 256 MByte Größe fest. Über die Segmentregister werden 52bittige virtuelle Adressen erzeugt, die über eine aufwendige Page Address Translation mit 4-KByte-Pages und zwei TLBs (Translation Lookaside Buffer) von je 64 Einträgen (PPC604) letztendlich die physikalische Adresse festlegen. Dieser Translationsweg entspricht ganz grob der x86-Architektur mit Segment-Deskriptoren und Paging
- über Segmentregister mit Direct Store Segment Translation. Das ist eine Art I/O-Zugriff am Cache vorbei, ein Relikt aus alten POWER-Zeiten, seine Nutzung wird nicht empfohlen
Rechtwinklig
Eine herausragende Eigenschaft von RISC-Prozessoren ist die Orthogonalität ihrer Register. Jedes der 32 Integer-Register ist 'general purpose', also bezüglich aller Operationen gleichwertig. Einen Akkumulator als Engpaß, über den viele Operationen abgewickelt werden müssen, kennt die Architektur nicht. Das ist ein erheblicher Unterschied zur x86-Architektur, wo zwar inzwischen alle 32-Bit-Register als Index benutzt werden können, aber so wichtige Funktionen wie etwa die Multiplikation immer das EAX-Register beziehungsweise das Registerpaar EDX/EAX verwenden müssen. Insbesondere ist jedoch der Intel-Befehlssatz auf nur acht Register beschränkt.
Ein weiterer wichtiger Vorteil, den viele RISC-Prozessoren der Intel-Architektur voraus haben, ist ihre 'Harmonie mit C'. Die dortigen Pointerstrukturen, insbesondere die häufigen Pre- und Post-Dekrements und -Inkrements (- -I oder J+ +) sind hier oft in einem Prozessorbefehl abgebildet, während der x86 zwei Befehle benötigt. Der PowerPC unterstützt auch eine Variante des Post-Dekrements, nämlich die Update-Befehle. Dort, wo über Offset und ein oder zwei Indizes effektive Adressen berechnet werden, kann man noch ein Update-Register anfügen, das im Anschluß diese effektive Adresse aufnimmt.
In der Überzahl
Die gleiche Registerübermacht von 4 : 1 wie bei Integer trifft man auch bei den Fließkommaeinheiten (FPUs) an. Bei PowerPC ist die FPU als normale Drei-Adreß-Maschine organisiert: zwei beliebige FP-Register lassen sich verknüpfen und das Ergebnis einem dritten zuordnen. Ganz anders in der Intel-Architektur: die acht FPU- Register sind hier als Stack angeordnet, Operationen lassen sich nur auf das oberste Register im Stack anwenden. Compiler haben mit dem komplizierten Stackmanagement ihre liebe Not, Optimierungen über Registervariablen etwa sind hier kaum machbar - beim PowerPC gehört das hingegen zu den Pflichtaufgaben.
Außerdem sind viele Grundrechenarten des PPC604 deutlich schneller als beim Pentium oder PPro. Das gilt insbesondere für den wichtigen Multiply-Add-Befehl, den die Intel-Prozessoren mit zwei Befehlen erschlagen müssen. Weiterhin gibt es auch konditionierte Fließkommabefehle (FSEL). Andererseits fehlen alle transzendenten Befehle wie sin, cos, tan, ln oder exp, mit denen die Intel-Welt aufwarten kann. Hier muß der Compiler geeignete Approximationsroutinen in seiner Mathe-Bibliothek bereithalten, was den erzeugten Code natürlich aufbläht.
Cache und Co.
Sowohl Pentium und PentiumPro als auch die PPC60x-Prozessoren sind superskalar, das heißt, sie haben mehrere parallel arbeitende Funktionseinheiten. Zu den Integer-Rechenwerken (ALU = Arithmetic Logic Unit) gesellen sich die Fließkomma-, Load/Store- und die Sprungvorhersage-Einheit (Branch Unit). Letztere sorgt dafür, daß möglichst selten Wartezeiten durch Programmverzweigungen entstehen. Der Prozessor merkt sich in einem Branch History Buffer, welche Sprungmuster an welchen Adressen aufgetreten sind, um beim nächsten Mal mit möglichst hoher Trefferquote den weiteren Programmweg vorherzusagen.
Der Pentium hat zwei einfach gestrickte Pipelines. Es ist Aufgabe des Compilers, Abhängigkeiten zwischen den Befehlen möglichst zu entkoppeln, damit sie parallel ausgeführt werden können. Im Pentium ist der Parallelisierungsgrad daher recht klein. Hinzu kommt, daß eine Pipe warten muß, bis die andere fertig ist. So dreht sie zum Beispiel bei einer Division gut 40 Takte lang Däumchen.
PentiumPro und die PowerPCs (insbesondere der PPC 604) sind hier erheblich leistungsfähiger. Eine Vielzahl von Mechanismen sorgt für eine effiziente Befehlsentkopplung. Ein wichtiger 'Trick' dabei ist das Register-Renaming. Physikalische Register sind hierbei nicht mehr statisch einem logischen Register zugeordnet, sondern der Prozessor kann sie nach Bedarf ummappen. Außerdem müssen Befehle oft nicht unbedingt in der Reihenfolge ausgeführt werden, in der sie im Programm aufeinanderfolgen. Die modernen Prozessoren ordnen sie um und sorgen am Ende über einen Reorder-Buffer dafür, daß die Zugriffsreihenfolge wieder stimmt. Ein weiteres Bonbon sind Zwischenspeicher von ausdekodierten Befehlen, die auf eine freiwerdende Unit warten, die sogenannten Reservation States.
Der PPC603 hat recht wenig an parallelen Units zu bieten: er weist nur eine Integer-Unit auf. Demgegenüber kommt der PentiumPro mit zwei und der PPC604 gleich mit drei Integereinheiten daher, wobei die dritte Einheit nur für langandauernde Befehle (MUL, DIV) vorgesehen ist. Reservation States haben nur PPro und PPC604 zu bieten, der PPro speichert bis zu 20 'µOP' genannte Befehle zentral zwischen, der PPC604 hat dezentral an jeder Funktionseinheit kleinere Speicher.
Alle hier betrachteten Prozessoren besitzen getrennte Code- und Daten-Caches. Pentium-P54C und PPRo haben je 8 KByte, Pentium-55C (demnächst) und PPC603e je 16 KByte, während der PPC604e mit zweimal 32 KByte Cache der L1-Cache-König ist. Ungeschlagen bei der L2-Performance ist hingegen der PentiumPro, da hier der im Gehäuse integrierte L2-Cache mit der vollen Prozessorgeschwindigkeit betrieben wird, während alle anderen nur mit dem erheblich niedigeren exteren Systemtakt auf den externen L2-Cache zugreifen können.
Der Pentium weist eine besonders gute L1-Cache-Anbindung auf. Mit 256 Bit Breite gelangen die Instruktionen in den Decoder. Misalignments (Zugriffe auf ungerade Adressen und Daten) kann der Pentium nahezu problemlos wegstecken - die anderen Prozessoren haben hiermit mehr Probleme.
Alle vier Prozessoren transferieren ihre Daten zumeist in einem Burst von vier aufeinanderfolgenden Zugriffen vom und zum L2-Cache oder Hauptspeicher. Beim PPC603 kann ein externer Zugriff 32bittig oder 64bittig sein, bei den andern ist er immer 64bittig. Wie schnell die Bursts im Endeffekt sind, hängt von der Umgebung, also dem Chipsatz und der Art des Cache-Speicherinterface (synchron/asynchon) ab.
Vermessen

Der erste Teil unserer Benchmark-Schar besteht aus mehr oder weniger komplizierten synthetischen Aufgaben. Eine der interessantesten Übungen ist der HINT-Bench, 1994 von der amerikanischen Regierung beim Ames Laboratory in Auftrag gegeben mit der Zielsetzung, die Rechenleistung von Supercomputern verschiedener Provenienz vergleichen zu können. Das Ames-Lab entwickelte einen beliebig skalierbaren Benchmark, mit dem man auch die Leistung eines Taschenrechners, ja, sogar die eines College-Studenten in Zahlen fassen könnte.
HINT steht für Hierarchische INTegration. Dem Bench zugrunde liegt die Idee, daß man nicht willkürlich irgendwelche Ausführungszeiten von mehr oder weniger beliebigen Befehlen oder Befehlsfolgen abstoppt, sondern eine skalierbare Aufgabenstellung erfindet, deren Berechnung am Anfang recht einfach ist und die dann immer komplexer wird. Das Ergebnis von HINT ist mithin auch keine Ausführungzeit, sondern eine Kurve, die die Qualitätsverbesserung pro Zeiteinheit darstellt (QUIPS = Qualtity Improvement Per Second).
Die Aufgabenstellung ist in der Tat recht einfach. Viele Leser entsinnen sich gewiß noch, wie sie dereinst die Integration lernten, nämlich mit den Ober- und Untersummen. Man zählte auf dem Millimeterpapier die Punkte aus, die oberhalb oder unterhalb der Schnittpunkte der betrachteten Intervalle lagen. So arbeitet auch HINT. Die ausgesuchte, recht harmlose Funktion ist (1-x)/(1+x) im Intervall [0, 1]. Sie ist dort streng monoton fallend, was die Auswertung sehr vereinfacht. Das korrekte Integralergebnis wäre übrigens 2ln(2)-1, ist also transzendent.
Statt Millimeterpapier dient bei HINT ein Gitter als Rastermaß, das durch die Darstellungsgenauigkeit der Zahlen vorgegeben ist. Bei vorzeichenbehafteten Integern mit 15 Bits beträgt das Gitter 7 x 8 Bit. Der Algorithmus ist so gewählt, daß er für den Funktionswert f in der Intervallmitte die Zahl der Gitterquadrate bestimmt, die sich sicher innerhalb der Kurve (also links unterhalb von f) beziehungsweise sicher außerhalb (rechts oberhalb von f) befinden. Die verbleibenden 'unsicheren' Quadrate im Verhältnis zur Gesamtzahl sind ein Maß für die Genauigkeit (Quality) des Zwischenergebnisses. Dann halbiert man die Intervalle und wiederholt dieses Spiel für die restlichen Quadrate, bis letztendlich nur noch die wegen begrenzter Zahlendarstellung nicht weiter zuordenbaren Quadrate übrig bleiben. Bei Erreichen der Genauigkeitsgrenze stoppt der Algorithmus.
Der vorgeschriebene Algorithmus führt zu einer typischen Befehlsfolge, in der einfache Lade- und Speicherbefehle gegenüber komplexeren Operationen deutlich in der Überzahl sind. Ähnlich verhält es sich in den meisten Anwendungen; die HINT-Entwickler John L. Gustafson und Quinn O. Snell gehen deshalb davon aus, mit ihrem Test sehr viel besser als mit anderen synthetischen Benchmarks die durchschnittliche Anwendungsperformance von Rechnern voraussagen zu können. So verteilen sich die Befehle:
| Index-Operationen | Daten-Operationen |
| 39 Adds/Subtracts | 69 Fetches/Stores |
| 16 Fetches/Stores | 24 Adds/Subtracts |
| 6 Shifts | 10 Multiplies |
| 3 Cond. Branches | 2 Cond. Branches |
| 2 Multiplies | 2 Divides |
HINT legt alle Zwischenergebnisse in Feldern ab, so daß mit zunehmender Laufzeit immer mehr Speicher alloziert wird. An der HINT-Kurve läßt sich dann deutlich der Einfluß des Cache, des Hauptspeichers und gegebenenfalls des Pagings ablesen. Bei höherer Genauigkeit begrenzt der verfügbare Speicher die Laufzeit. Wir haben für diesen Test eine Speicherobergrenze von 25 MByte vorgegeben; der Speicher wird vor Beginn der Messung bereits einmal alloziert und benutzt, so daß die späteren Ergebnisse bei der gewählten RAM-Bestückung von 32 MByte auch unter Windows NT nicht mehr durch das Auslagern auf die Festplatte beeinträchtigt wurden.
Um dem Wunsch nach einer einzigen Benchmark-Zahl nachzukommen, haben die HINT-Entwickler den Net-QUIPS-Wert definiert als das Integral unter der QUIPS-Kurve bei logarithmischer Zeitachse. Ein Student kommt demnach auf etwa 0,1 Net-QUIPS, Supercomputer wie Intels Paragon mit 1840 Prozessoren schaffen 633 Millionen Net-QUIPS.
Kurvenreich
Die ermittelten QUIPS-Kurven haben einen hohen Informationswert. Unter anderem läßt sich an ihrem Verlauf der Einfluß der Caches und der Speicher-Performance verfolgen. Wir haben HINT sowohl mit Integer-Variablen (32 Bit) als auch mit Double-Genauigkeit (64 Bit Fließkomma) implementiert. (Auch die gängigen Windows-Compiler arbeiten mit 64 Bit Genauigkeit, obwohl die Intel-kompatiblen Prozessoren intern mit dem 80-Bit-Standardformat rechnen.)
So legten die Power Macs beim Double-HINT aufgrund ihrer fixen Fließkommaeinheiten zunächst gewaltig los und lagen zum Teil mehr als 20 Prozent über der PentiumPro-Leistung unter Windows NT, gerieten dann aber mit zunehmender Datenmenge aufgrund des langsameren externen Caches etwas ins Hintertreffen. Beeindruckend war die Leistung desPentiumPro-Chips auf dem AMI-Board bei sehr großen Datenmengen (wiederum unter Windows NT), was auf ein hervorragendes Hauptspeicherinterface schließen läßt. Enttäuscht hat dagegen die Leistung aller Pentiums unter Windows 95, das offenbar massiv in die Cache-Kohärenz eingreift und vor allem bei den 'dicken' Pentiums die Geschwindigkeit im Extremfall auf weniger als die Hälfte (relativ zu NT) drosselt.
Beim Integer-HINT (unter Windows NT) lagen die PentiumPro-Brüder dagegen leicht vorn, dicht gefolgt von der PowerPC-Familie. Der 'kleine' Pentium, der noch gut 25 Prozent schlechtere Ergebnisse lieferte als der PowerPC603 im Performa, landete abgeschlagen auf dem letzten Platz.
PI mal Daumen
Die Berechnung von pi auf irrwitzig viele Stellen ist als Benchmark schon seit archimedischen Zeiten beliebt. Der diesem Benchmark-Programm zugrundeliegende Algorithmus basiert aber nicht auf einem der klassischen Verfahren, sondern wurde erst letztes Jahr von Bailey, Borwein und Plouffe entdeckt.
Er konvergiert ausgesprochen schnell, so daß sich 10 000 Stellen in wenigen Sekunden berechnen lassen. Beschränkt man sich auf weniger als 100 000 Stellen, läuft der Bench vollständig im L2-Cache ab.
Als wesentliche Operation geht in den Pi-Bench die doppeltgenaue Division ein. Unser Programm verzichtet jedoch weitgehend auf direkte Divisionen - da sonst ein einziger Befehl die Gesamtperformance bestimmen würde, sondern führt sie 'zu Fuß' mit Standardbefehlen wie Schieben und Subtrahieren, Vergleichen und Verzweigen aus. Würde man etwa auf einem Intel-Prozessor für die 64/32-Bit-Division statt dessen den vorgesehenen Prozessorbefehl benutzen, könnte man gut die sechsfache Performance erreichen. Doch für Benchmarkzwecke ist langsamere portable Lösung sinnvoller.
Für diesen Test haben wir uns auf eine Genauigkeit von 8192 Stellen beschränkt. Angegeben ist der Gesamtwert für das Ermitteln aller Stellen. c't wird in einer der nächsten Ausgaben den Algorithmus samt C-Programm von Sebastian Wedeniwski genauer vorstellen. Wie Sie der Grafik auf Seite 278 entnehmen können, liegen die PowerPC-bestückten Rechner hier sehr gut im Rennen: Selbst der Apple Performa ist um mehr als ein Drittel schneller als der beste Pentium.
Schmetterlinge im Cache
Ein weiterer Klassiker bei den wissenschaftlichen Benchmarks ist die schnelle Fourier-Transformation (FFT). Hierzu dient in aller Regel der sogenannte Butterfly-Algorithmus, wie er in [1] beschriebenen wurde. Das vorliegende Benchmarkprogramm für eine komplexe FFT von 1024 Werten nach John Greene ist hochoptimiert und arbeitet mit einer größeren Folge aufeinanderfolgender Multiply/Add-Operationen in doppelter Genauigkeit. Prozessoren mit vielen Floating-Point-Registern profitieren besonders davon - das kommt natürlich dem PowerPC mit seinen 32 FP-Registern entgegen.
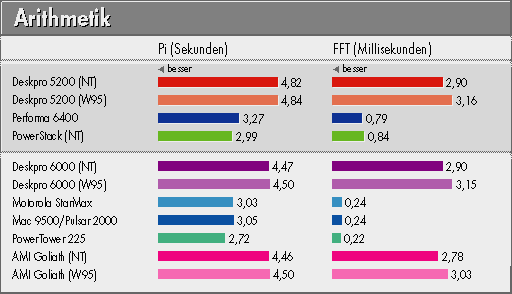
Hinzu kommt, daß die uns bekannten Intel-C-Compiler zwar für Registervariable ausgefuchste Optimierungen beherrschen - aber nur für Integer. Für Floatingpoint-Register wird üblicherweise mühsam hin- und hergeladen - wegen ihrer stackartigen Verwaltung ist es für Compiler ausgesprochen schwierig, hier zu optimieren. Tatsächlich erledigten die PowerPCs die gestellte Aufgabe fünfmal (PPC603e) oder gar zehnmal (PPC604e) schneller (!) als die Intel-Prozessoren - der Power Tower 225 von Power Computing berechnet die 1024-Punkte-FFT in atemberaubenden 220 Mikrosekunden, während der schnellste PentiumPro dafür 2,78 ms benötigt.
Obwohl der FFT-Benchmark extrem 'lokal' ist, da er praktisch vollständig im prozessor internen Cache läuft, sah das Ergebnis für den PowerStack von Motorola (unter NT 4.0) mit 0,95 ms um 20 % schlechter aus als für den hier gleichwertigen Performa 6400. Beim Disassemblieren zeigte sich, daß Microsofts C++-Compiler 15 Floatingpoint-Register des PPC 603 ungenutzt ließ; der Metrowerks-Compiler für MacOS benutzt dagegen alle bis auf zwei. Obendrein gestattet Microsofts C++ als einzige globale Einstellung für den Funktionsaufruf die 'cdecl'-Konvention (Parameterübergabe über den Stack), bei der Intel-Version des Compilers wird dagegen auch 'fastcall' (Parameterübergabe über Register) angeboten. Dabei wäre letztere gerade bei einem RISC-Prozessor mit vielen Registern durchgehend angebracht. Wir haben den FFT-Test schließlich mit einer zufällig vorhandenen alten Beta eines Motorola-Compilers noch einmal übersetzt und damit das abgedruckte Ergebnis erzielt, immerhin um gut 10 % besser als mit dem aktuellen Microsoft-Compiler.
Niedere Mathematik...
Hinter dem c't-eigenen Syscomp steckt ein weiterer synthetischer Benchmark. Das in ANSI-C realisierte Programm versucht, soweit das in einer Hochsprache überhaupt möglicht ist, die Prozessor-Performance in verschiedenen arithmetischen Disziplinen zu ermitteln. Syscomp tut dies, wie HINT, für die Datentypen int und für double. In handgetrimmten Meßschleifen wiederholt es dazu Rechenoperationen in einem vorgegebenen Adreßraum solange, bis eine Mindestlaufzeit erreicht ist.
Beim Datentyp int setzt sich der Benchmark aus Addition, Multiplikation und Division zusammen, beim Datentyp double gesellen sich Logarithmus, Tangens und Quadratwurzel dazu. Für jede dieser Disziplinen bestimmt Syscomp die Anzahl der pro Millisekunde ausgeführten Operationen. In das Endergebnis (gewichtetes Mittel) gehen die einzelnen Disziplinen mit folgender Wertigkeit ein:
| Typ | int | double |
| Add | 20 | 20 |
| Mul | 10 | 10 |
| Div | 5 | 5 |
| Tan | <br> | 1 |
| Ln | <br> | 1 |
| Sqrt | <br> | 1 |
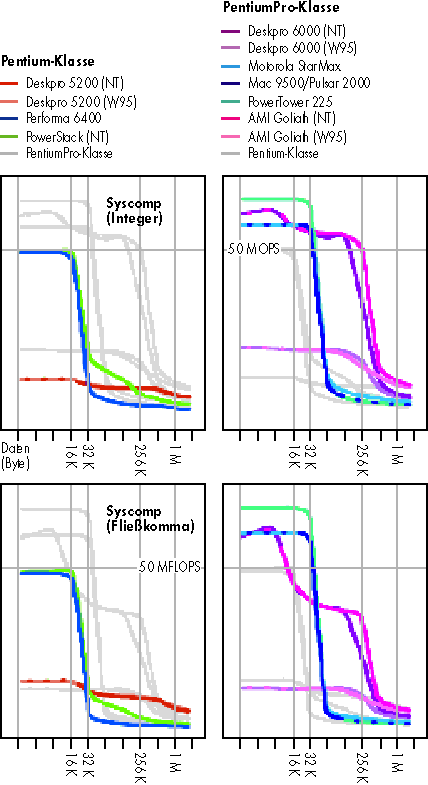
Trotz der ausgefeilten Meßschleifen fließen natürlich Speicherzugriffe in das Ergebnis ein - ganz und gar lassen sich Operationen und Operanden eben nicht trennen. Der Aufbau der Meßschleifen garantiert jedoch weitestgehend, daß sich die Ergebnisse auch bei Einsatz hochoptimierender Compiler nicht besonders verbessern lassen. Um die Abhängigkeit von Speicherzugriffen zu ermitteln, wiederholt Syscomp die Messungen auf einer wachsenden, immer gleich vorbesetzten Speichermenge. Aus den separat ausgewiesenen gewichteten Resultaten ergeben sich die abgebildeten Performance-Kurven.
Wie schon beim HINT-Benchmark tritt bei den Syscomp-Kurven deutlich die Speicherabhängigkeit hervor, und ebenso deutlich fällt das miserable Ergebnis unter Windows 95 auf - trotz hochaktueller 32-Bit-Compiler. Natürlich kann sich der PentiumPro mit zunehmendem Datenaufkommen aufgrund seines großen internen L2-Caches länger 'über Wasser halten' als der PowerPC, der hier nur bei Fließkomma-Arithmetik im internen Cache Vorteile für sich verbuchen konnte. Das wiegt allerdings stärker, weil ihm Prozessorbefehle für die transzendenten Operationen fehlen und der Compiler diese durch Bibliotheksfunktionen nachbilden muß.
...und die höhere
MuPAD ist ein kostenlos verfügbares Computeralgebrasystem der UGH Paderborn (siehe c't 7/95, S. 194). Sowohl Windows-95/NT- wie Mac-Version sind im wesentlichen in ANSI-C geschrieben und nutzen kaum hardwarespezifische Eigenschaften aus. Insbesondere verzichtet MuPAD auf jegliche Fließkomma-Unterstützung durch den Prozessor. Kompiliert wurden die MuPAD-Versionen mit maximaler Optimierungsstufe von Microsoft Visual C++ 4.1 beziehungsweise Metrowerks Codewarrior 8.
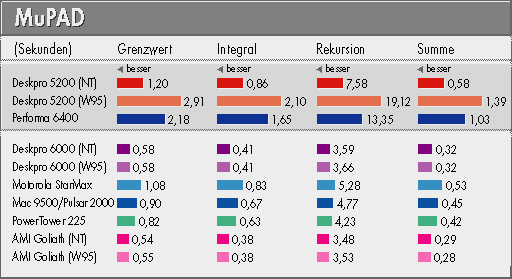
Die in MuPAD eingebaute Langzahlarithmetik PARI, die das Rechnen mit ganzen Zahlen übernimmt, enthält einen kleinen handoptimierten Assemblerkern. Daher haben wir als Benchmarks Aufgaben gewählt, die wenig auf PARI zugreifen. Weil MuPAD zu Beginn eines jeden Tests einige Routinen von der Festplatte lädt, ließen wir jede Rechnung mehrfach hintereinander ablaufen; die stark von der Festplatte bestimmte Dauer der ersten Rechnung ignorierten wir.
Arithmetik wird in MuPAD (überraschenderweise) verhältnismäßig klein geschrieben. Der überwiegende Anteil an Rechnungen sind die Manipulationen der recht komplexen internen Ausdrucksbäume. Dabei kommt es hauptsächlich zu sehr vielen Speicherzugriffen, meist mehrfach indirekt, zu vielen Vergleichsoperationen und zu häufigem Anfordern und Freigeben von Speicherblöcken. MuPAD arbeitet ferner oft mit Rekursionen, teilweise mit sehr hoher Schachtelungstiefe (1000 und mehr). Wegen der Größe des Algebrasystems sollten RAM-Caches nicht allzuviel Wirkung zeigen, es kommt also primär auf die Effizienz der Hauptspeicherzugriffe an, so ein Programmierer von MuPAD.
Die MuPAD-Benches bestanden aus der symbolischen Berechnung eines Grenzwerts, der symbolischen Auswertung eines Integrals, der Berechnung des 20sten Elements der Fibonacci-Folge (1, 1, 2, 3, 5, 8, ...) durch 220 Rekursionen und schließlich der symbolischen Berechnung einer unendlichen Summe. Bei diesen Tests lagen eindeutig die 'dicken' PentiumPro vorn, die rote Laterne durften der Compaq-Pentium unter Windows 95 und der 603ev im Performa gemeinsam tragen.
Formelknacker
Wolfram Mathematica 2.2.3 für Windows (95 und NT mit Patch) und MacOS ist eines der am weitesten verbreiteten Computeralgebrasysteme (siehe o.g. c't). Es beherrscht sowohl symbolische Rechnungen (das Auswerten algebraischer Formeln) wie auch numerische Aufgaben (das 'übliche' Rechnen mit Zahlen).
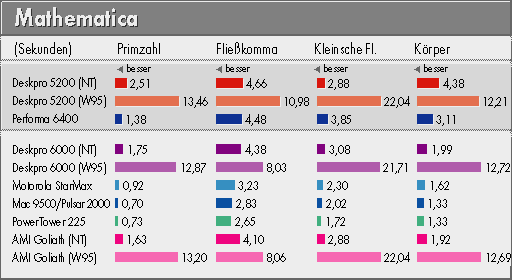
Auf dem Mathematica-Programm standen: die Berechnung von Primzahlen, eine aufwendige Fließkomma-Rechnung, die 3D-Darstellung der 'Kleinschen Flasche' und die Darstellung eines komplizierten 3D-Körpers. Die letzteren drei Aufgaben machen rege Gebrauch von den Fließkomma-Fähigkeiten des Prozessors. Das konnten die PowerPCs zu ihrem Vorteil nutzen: Halb so lange Ausführungszeiten wie auf den schnellsten Pentiums waren hier keine Seltenheit, selbst der Sparprozessor des Performa konnte noch gut mithalten. Ein Trauerspiel wiederum die Ergebnisse unter Windows 95 - die PowerPC-Riege war teilweise mehr als zehnmal (!) so schnell.
Bücherwurm
Für einen Real-World-Test in der Disziplin Datenbanken verwendeten wir die Search Engine von eMedia, deren Browser-Version c't-ROM-Anwendern als eMedia Navigator bekannt ist. Das Programm liegt uns im Quelltext vor; wir haben es für Windows mit Microsofts Visual C++ und für MacOS mit Metrowerks Code Warrior Version 10 kompiliert.
Beim Suchen im Volltext geben Festplatte oder CD-ROM das Tempo vor, deshalb eignet sich dieser Vorgang kaum als Prozessor-Benchmark. Anders sieht es bei der Erstellung eines Volltext-Index aus. Der schnelle Indizierer in der Produktionsversion der Suchmaschine liest und schreibt ausschließlich größere Datenblöcke von zumeist 32 KByte Länge. Die Festplatte wird also mit maximaler Geschwindigkeit betrieben, und die Massenspeicherzugriffe machen nur den kleineren Teil der Laufzeit aus. Natürlich haben wir trotzdem alle Tests mit derselben Platte durchgeführt.
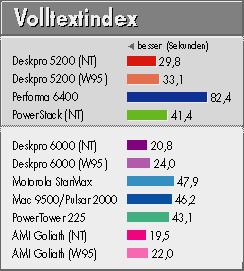
Die Aufgabe besteht darin, eine Textdatei von 10 MByte Länge für die 'Fuzzy Logic'-Volltextsuche zu indizieren. Der Indizierer bildet dabei unter anderem eine sortierte Liste aller vorkommenden Wörter und ihrer Positionen in der Datei. Er legt im Speicher eine große Datenstruktur aus Bäumen und verketteten Listen an; virtueller Speicher und das damit verbundene Swapping werden strikt gemieden. Das Ergebnis ist eine frappierend schnelle Volltextindizierung. Die 32-Bit-Indizes werden zwecks Platzersparnis noch 'komprimiert' und in überwiegend 16bittigen Strukturen abgelegt.
Daß die PowerPCs in diesem Benchmark deutlich schlechter abschneiden als die Pentium-Familie, ließ zunächst eine Diskrepanz zwischen ihrer 32-Bit-Architektur und den 8-Bit-Textdaten vermuten. Dem ist aber nicht so: der Byte-Ladebefehl kostet, nur zwei Prozessortakte. Die Programmanalyse mittels Profiler erwies denn auch, daß ein Großteil der Laufzeit beim Abklappern der weit im Speicher verzweigten Bäume und verketteten Listen draufgeht. Ihren deutlichen Sieg verdanken die Pentiums demnach vornehmlich dem schnelleren Zugriff auf den Hauptspeicher.
Hinzu kommt ein Einfluß der beiden Windows-Varianten im Vergleich zu MacOS: Dessen Massenspeicher-Cache wird nur beim Lesen wirksam, der von Windows dagegen auch beim Schreiben. Da der Indizierer temporäre Dateien schreibt und kurz darauf wieder liest, werden unter Windows einige Plattenzugriffe quasi übersprungen. Dennoch blieb auch Motorolas PowerStack unter Windows NT hinter den Erwartungen zurück; möglicherweise hat der Microsoft-Compiler auch hier das Programm für den PowerPC weniger gut optimiert als für den Pentium.
Bilderbuchbench
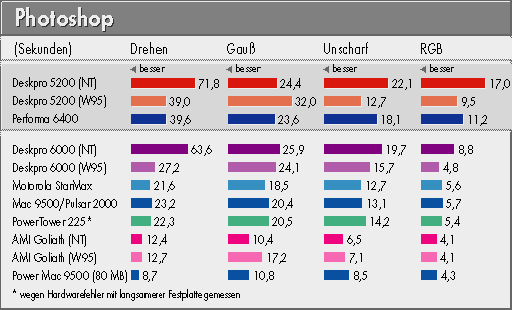
Mit einem CMYK-Bild von 1430 x 1793 Pixeln Größe (Datenvolumen knapp 10 MByte) führten wir Teile unseres Standard-Benchmarks für Photoshop aus, deren Eignung für Cross-Plattform-Benchmarks Adobe uns ausdrücklich bestätigt hat: Drehen des Bildes um 1 Grad (bikubische Interpolation eingeschaltet), Gaußscher Weichzeichner (Stärke 50 Pixel), Scharfzeichnungsfiler 'Unscharf Maskieren' (50 %, 3 Pixel, Schwelle 18 Stufen), Farbraumwandlung von CMYK in RGB (Werkseinstellungen). Alle diese Benchmarks prüfen vor allem Integer-Leistung und Speichertransfer. Da Photoshop mit seinem eigenen virtuellen Speicher für viele Festplattenzugriffe sorgt, haben wir alle Messungen mit derselben Platte ausgeführt. Wie stark die Ergebnisse davon bestimmt werden, zeigen die Meßwerte in der Superschwergewichtsklasse: Bei dem AMI-Board mit seiner Grundausstattung von 128 MByte RAM mußte Photoshop überhaupt nicht mehr swappen - ebenso wenig wie bei dem Power Mac 9500 mit 80 MByte RAM. In diesem Licht sind auch die übrigen Ergebnisse zu sehen.
Leider lag uns keine Photoshop-Implementierung für Windows NT auf PowerPC vor, so daß die Zeile für den Motorola PowerStack entfallen mußte. Die sonstigen Ergebnisse waren recht gemischt. Mit 'nur' 32 MByte Hauptspeicher brach Adobes NT-Anpassung stark ein, während Windows 95 sich teils von einer besseren Seite zeigte. Die PowerPC-Mannschaft durfte fast immer aufs Siegertreppchen, nur im Superschwergewicht lief das AMI-Goliath-Board dem Power Mac 9500 knapp den Rang ab.
Filmreif
Cinema 4D, eine plattformübergreifend verfügbare 3D-Animationssoftware, kompilierte Hersteller Maxon extra für diesen Test auch für den PowerPC unter Windows NT. Das Programm stand damit auf allen Rechnern zur Verfügung. (Einen Test der Versionen für Windows und MacOS finden Sie auf S. 72.)
Als Benchmark diente ein Film, der zeigt, wie sechs Tropfen auf einen Marmorfußboden fallen und zerfließen. Dabei handelt es sich um halbtransparente Objekte aus je 1392 Vierecken; die Tropfen wandeln ihre Form per 'Morphing'. Gerendert wurden in höchster Qualitätsstufe (Raytracing) bei 2 x 2-Antialiasing ein Einzelbild (472 x 321 Pixel) sowie ein Film (240 x 160 Pixel) aus 26 Bildern - letzterer einmal mit eingeschalteter Transparenz (und Lichtbrechung) und einmal ohne, wodurch unzählige Iterationen des Raytracing entfallen.
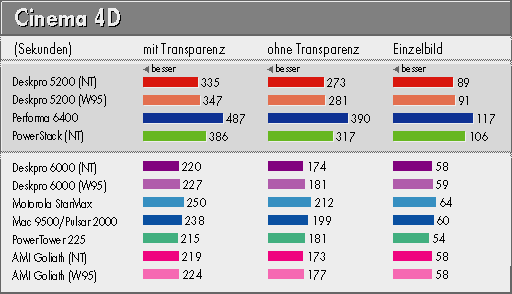
Erstaunlicherweise fiel Windows 95 hier nicht negativ auf, so daß der Performa das Schlußlicht bildete. PowerPC 604e und PentiumPro lagen Kopf an Kopf, während der Pentium im Deskpro 5200 um mehr als 20 Prozent bessere Ergebnisse lieferte als der Performa mit seinem 603ev.
Schachmatt
Schach-Algorithmen sind ebenfalls eine beliebte Herausforderung für Rechner aller Art - und warum sollte man einen Prozessorvergleich nicht mit einem kleinen Turnier beschließen? Da die Berechnungstiefe der möglichen Züge pro Zeiteinheit bei einem schnelleren Prozessor natürlich größer ist, sollte im statistischen Mittel auch dieser gewinnen. Wir bedienten uns der Textversion von GnuChess 4.0 Patchlevel 73, um über eine TCP/IP-Verbindung den PowerPC 603e im Motorola PowerStack unter Windows NT 4.0 gegen den klassengleichen Pentium im Deskpro 5200 antreten zu lassen.
Als Leistungsmaß dient die Anzahl der in einem Spiel analysierten Züge. Unsere GnuChess-Adaption, die den Streithähnen abwechselnd die Spieleröffnung zuwies, ermittelte hier für den PowerPC im Schnitt um 18,5 Prozent höhere Werte. Kein Wunder, daß er das Turnier auch gewann: Nach einer langen Schachnacht von 53 Partien lag das unten illustrierte Endergebnis vor.
Für MacOS mangelte es leider an einer geeigneten GnuChess-Implementierung, so daß ein dem PentiumPro angemessener Gegner fehlte. Doch warum sollte der 'kleine' 603e nach dem überraschend guten Abschneiden in seiner Gewichtsklasse nicht das Schwergewicht herausfordern? - Als kleinen Ausgleich für das Untergewicht verpaßten wir dem PowerStack eine Sonderausstattung in Form von 1 MByte Sync-Cache. So beflügelt schlug er sich wacker gegen den Deskpro 6000.
Das Ergebnis war noch eine Überraschung: Der PPC 603e erreichte im Schnitt 94,2 % der Berechnungstiefe seines starken Gegners und holte in den sechs Spielen, für welche die Zeit bis zum Redaktionsschluß gerade noch reichte, zwei Siege und zweimal Unentschieden heraus - insgesamt also ein Remis.
Fazit
Obwohl die Einzelergebnisse für die konkurrierenden Prozessorfamilien insgesamt sich einigermaßen die Waage halten, kann man wohl kaum von einer ausgeglichenen Bilanz sprechen. Immerhin liegen die Resultate zum Teil dramatisch weit auseinander.
Die PowerPCs besitzen offenbar den 'besseren Kern': Im Umgang mit kleineren Datenstrukturen haben sie die Nase vorn, wie es sich besonders deutlich bei den isolierten Aufgaben der Pi-Berechnung und der Fourier-Transformation zeigt. Hier zahlt sich das modernere Konzept aus. Dessen Möglichkeiten freilich, speziell die Vielzahl der universellen Register, dürften oft nicht ausgeschöpft werden. Da haben nicht nur manche Compilerbauer noch Hausaufgaben zu erledigen. Auch die Softwareentwickler könnten sicher oftmals durch besser angepaßte Algorithmen wesentlich mehr Leistung herausholen. Damit ist allerdings in der Breite kaum zu rechnen, solange die Marktanteile der PowerPC-Systeme so klein bleiben, daß sich die eigenständige Softwareentwicklung dafür nicht rentiert. Dabei haben die PowerPCs für Anwendungen im umkämpften Multimedia-Bereich aus Programmiersicht gewiß den größeren Charme - so 'signalfest' wie Intels für 1997 angekündigte MMX-Prozessoren (siehe c't 6/96, S. 206) sind sie längst.
Die PowerPC-Rechner (nicht unbedingt die Prozessoren) kranken dafür an einem etwas nachlässig implementierten Hauptspeicher-Interface, worunter natürlich das Tempo bei der Bearbeitung größerer Datenstrukturen leidet. In den Apple-Kompatiblen fanden wir nur asynchrone Caches und mit 70 ns recht lahme Standard-RAMs; allein Motorolas StarMax machte mit EDO-RAM eine Ausnahme. Und nur der PowerStack lag mit 67 MHz Bustakt auf Pentium-Niveau - war aber ebenfalls bloß mit asynchronem Cache und Standard-RAM ausgerüstet.
Mit der durch Intels aktuelle Prozessoren und Chipsätze gesetzten Marke bei der Hauptspeicherbandbreite kann das PowerPC-Lager bisher nicht konkurrieren. 67 MHz Bustakt, Pipelined Burst Cache und die Unterstützung moderner, schnellerer RAM-Technologien sind hier inzwischen selbstverständlich. Dem superschnellen internen L2-Cache des Pentium Pro hat man erst recht nichts entgegenzusetzen, selbst wenn man den lediglich als teure und hochaufwendige Holzhammer-Methode abtut. Gewiß, der PentiumPro hat aufgrund seines stolzen Preises ein schlechteres Preis/Leistungsverhältnis als der PPC 604e - aber das bedeutet am Markt gar nichts, solange die kompletten PowerPC-Rechner keinen Deut billiger verkauft werden. Nichtsdestotrotz: der PentiumPro-Thron kippelt arg, und hätte sich Apple mit dem 604-Chipsatz nur ein wenig mehr Mühe gegeben, wäre er glatt umgefallen.
Wenn es auch keine klaren Sieger gibt, ein Verlierer ist auszumachen: Warum Windows 95 im Vergleich zum neuen NT 4.0 einen dermaßen 'lähmenden' Effekt auf einige Benchmarks hatte, vermochten wir während dieses Tests nicht zu klären. Der spontane Verdacht, es könne sich um betriebssystemspezifische Ungenauigkeiten der Timer-Funktionen handeln, die lediglich die Meßwerte verfälschten, ließ sich durch diverse Experimente und mühsames Nachmessen mit der Stoppuhr nicht erhärten. Microsoft konnte unsere Nachfrage dazu nicht beantworten; sicher wird dieses Thema uns noch weiter beschäftigen.
| Prozessor-Vergleich: Testteilnehmer | |||||
| Pentium/PowerPC603-Klasse | |||||
| Modell | Prozessor/Takt | L1/L2-Cache | Hauptspeicher | Bustakt | Betriebssystem |
| Compaq Deskpro 5200 | Pentium/200 | 2x8/256 KByte synchron | 32 MByte EDO | 67 MHz | Win 95, Win NT 4.0 |
| Apple Performa 6400 | PPC603ev/200 | 2 x 16/256 KByte asynchron | 32 MByte | 40 MHz | MacOS 7.5.3 |
| Motorola PowerStack 2000 | PPC603ev/200 | 2 x 16/256 KByte asynchron | 32 MByte | 67 MHz | Win NT 4.0 |
| PentiumPro/PowerPC604-Klasse | |||||
| Compaq Deskpro 6000 | PentiumPro/200 | 2 x 8/256 KByte integriert | 32 MByte EDO | 67 MHz | Win 95, Win NT 4.0 |
| Motorola StarMax 4200 | PPC604e/200 | 2 x 32/256 KByte asynchron | 32 MByte EDO | 50 MHz | MacOS 7.5.3 |
| Apple Power Mac 9500 | PPC604e/200 | 2 x 32/512 KByte asynchron | 32 MByte | 50 MHz | MacOS 7.5.3 |
| Umax Pulsar 2000* | PPC604e/200 | 2 x 32/512 Kbyte asynchron | 32 MByte | 50 MHz | MacOS 7.5.3 |
| Power Computing PowerTower 225 | PPC604e/225 | 2 x 32/1024 KByte asynchron | 32 MByte | 45 MHz | MacOS 7.5.3 |
| AMI-Board Goliath | PentiumPro/200 | 2 x 8/256 KByte integriert, | 128 MByte | 67 MHz | Win 95, Win NT 4.0 |
| Apple Power Mac 9500 | PPC604e/200 | 2 x 32/512 KByte asynchron | 80 MByte | 50 MHz | MacOS 7.5.3 |
| *weitgehend bau- und leistungsgleich mit Apple Power Mac 9500/200 | |||||
Zum Vergleich können Sie die von uns verwendeten Benchmarks von unserem ftp-Server downloaden:
(cp)
