

Künstliche Intelligenz: AlphaGo Zero übertrumpft AlphaGo ohne menschliches Vorwissen
Im asiatischen Strategiespiel Go hat das Programm AlphaGo der Google-Tochter DeepMind in diesem Jahr den stärksten menschlichen Profispieler besiegt. Eine neue Version hat das Spiel jetzt ohne menschliches Vorwissen gelernt und spielt noch stärker.

(Bild: Google)
Es sah so aus, als wäre das Thema Go für das KI-Start-up DeepMind in diesem Jahr abgehakt: 60 Online-Partien gegen Profis gewonnen im Januar, den Weltranglisten-Ersten Ke Jie geschlagen im Mai, ein Team aus fünf Top-Profis geschlagen ebenfalls im Mai, was soll da noch kommen? Jedenfalls eine wissenschaftliche Veröffentlichung, so viel hatte DeepMind im Anschluss an den 3:0-Sieg gegen Ke Jie auf dem The Future of Go Summit angekündigt.
Die ist nun da, und sie hat es in sich: In ihrem Aufsatz "Mastering the game of Go without human knowledge" in der renommierten Wissenschaftszeitschrift Nature beschreibt das Forscherteam von DeepMind nicht etwa nur die AlphaGo-Version, die Ke Jie besiegt hat, sondern eine noch neuere.
Spielerisch lernen

(Bild: Google DeepMind)
Vier Versionen von AlphaGo zählt DeepMind mittlerweile. Sie alle beruhen auf einer Kombination von neuronalen Netzen und der Baumsuchtechnik Monte Carlo Tree Search (MCTS); siehe dazu auch den Artikel "Mysteriöse Tiefe – wie Google-KI den Menschen im Go schlagen will" auf c't online. Während die neuronalen Netze der ersten drei Versionen mit Millionen von Stellungen aus Partien zwischen starken menschlichen Spielern trainiert wurden, hat die nun enthüllte Version AlphaGo Zero das Spiel von Grund auf selbst gelernt, nur aufgrund der Spielregeln. Und sie hat in internen Tests die "Master"-Version von AlphaGo nochmals übertroffen – gegen Menschen braucht sie da gar nicht mehr anzutreten.
Statt zweier neuronaler Netze (Policy Network für Vorschläge guter Züge und Value Network für die Stellungsbewertung) hat AlphaGo Zero nur noch eines, dieses allerdings mit zwei Ausgangspfaden ("Heads"), die gleichzeitig Zugvorschläge und Stellungsbewertung liefern. Am Eingang des neuronalen Netzes steht nur noch die nackte Stellung an, angereichert lediglich mit der Historie der letzten acht Züge und der Information, welcher Spieler am Zug ist. Die Go-spezifische Vorverarbeitung, mit der die Entwickler den neuronalen Netzen früherer AlphaGo-Versionen noch etwas auf die Sprünge geholfen hatten, ist Vergangenheit. Außer den Go-Regeln geht nur die Symmetrie ein: Drehungen und Spiegelungen des gesamten Brettes verändern das Spiel nicht.
Baumsuche als Strategieverstärker
Auch der MCTS-Algorithmus wurde abgespeckt: Statt Partien ab einem gewissen Punkt mit einer stark vereinfachten Zufallsstrategie zu Ende zu spielen, wächst der Spielbaum nun nur noch unter der Ägide des neuronalen Netzes. MCTS greift dem neuronalen Netz also nur noch als "Strategieverstärker" unter die Arme, indem es ein paar tausend Varianten möglicher Spielverläufe durchprobiert. Gleichzeitig lassen sich aus dem Ausgang dieser simulierten Partien Informationen über den Wert der besuchten Stellungen gewinnen.
Aus diesen beiden Dingen lernt das neuronale Netz nun, während das Programm gegen sich selbst spielt: Die Wahrscheinlichkeitsverteilung der Zugvorschläge passt sich den Ergebnissen der Baumsuche in den tatsächlich gespielten Partien an, sodass spätere Baumsuchen gleich mit besseren Strategien loslegen. Und die Stellungsbewertung des neuronalen Netzes gleicht sich den Ergebnissen der simulierten Partien an.
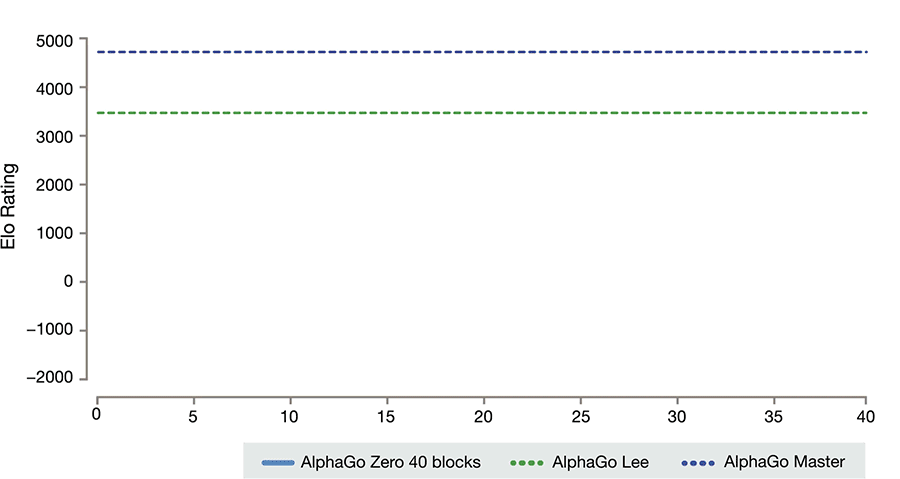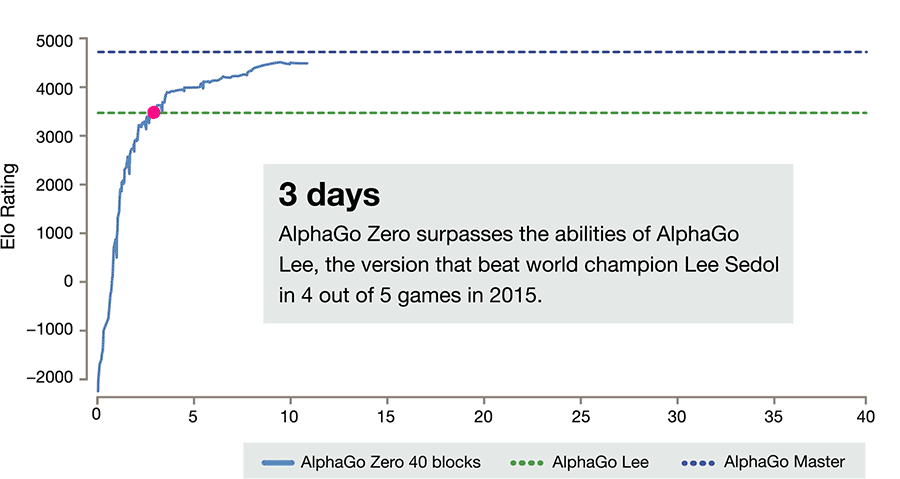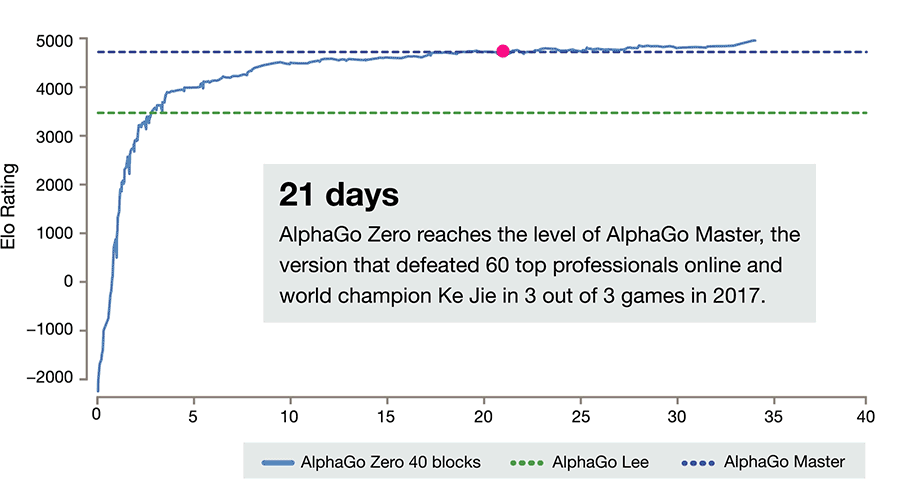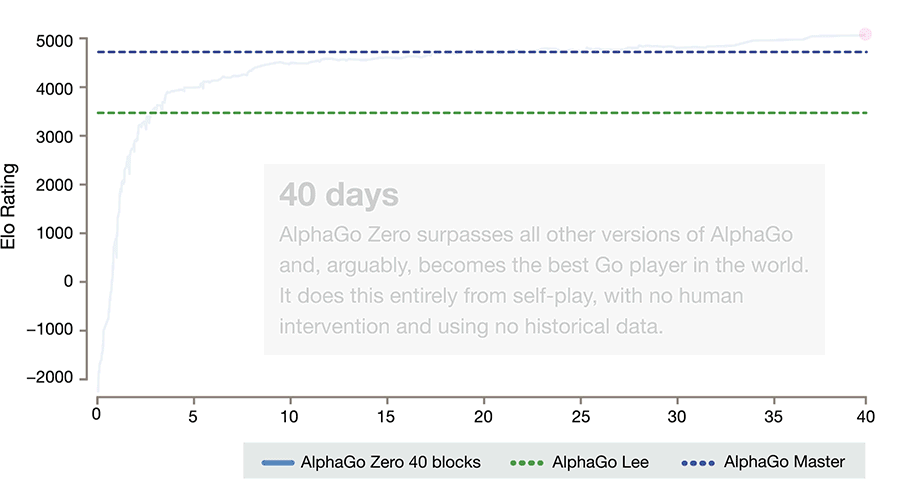
Vom Affen zum Profi in drei Tagen
(Bild: Google DeepMind)
Innerhalb von nur drei Tagen erreichte AlphaGo Zero damit, ausgehend von völlig zufällig gespielten Partien unterhalb jedes Anfängerniveaus, Profi-Spielstärke und übertraf die Version, die 2016 gegen Lee Sedol gewonnen hatte. Nach 21 Tagen war es auf dem Niveau der diesjährigen "Master"-Version, nach 40 Tagen deutlich darüber.
Dabei kommt AlphaGo Zero mit deutlich weniger Hardware aus als die erste AlphaGo-Version, nicht zuletzt dank der von Google eigens als Neuronale-Netze-Beschleuniger entwickelten Spezialchips TPU (Tensor Processing Unit). Nur noch eine Maschine mit 4 TPUs braucht AlphaGo Zero; bei der ersten Version war es noch ein Cluster mit über 1000 CPU-Kernen und 176 GPUs.
Entdeckt und verworfen

(Bild: Google DeepMind/Nature)
Erstaunlich ist es für den Go-Kundigen auch zu beobachten, wie AlphaGo Zero in kürzester Zeit das jahrhundertealte Go-Wissen der Menschheit entdeckt, etwa in Form bestimmter etablierter Zugfolgen in der Nähe der Ecken, sogenannter Joseki – und diese dann beim Weiterlernen wieder verwirft zugunsten anscheinend noch besserer Strategien. Das wird für Go-Profis nicht leicht zu verdauen sein: zu sehen, wie ein Computer innerhalb von zwei Tagen ihre ganze Karriere durchläuft und dann im gleichen Tempo über sie hinauswächst.
Ausblick
Mit AlphaGo Zero hat DeepMind Erstaunliches vollbracht: Es ist nicht nur der neue stärkste Go-Spieler auf diesem Planeten, sondern hat das Spiel nur aufgrund der Regeln gelernt und ist dabei über den Menschen hinausgewachsen.
Und weil weder Daten über von Menschen gespielte Partien noch irgendwelche Go-spezifischen Heuristiken eingegangen sind, stehen die Chancen nicht schlecht, dass sich die gewonnenen Erkenntnisse auf vergleichbare Spiele übertragen lassen: Nullsummenspiele mit vollständiger Information. Das höhere Ziel von DeepMind sind allerdings nicht Spiele, sondern künstliche Intelligenz für die echten Probleme der Menschheit – wer weiß, was diese Forschung zu deren Lösung beitragen kann. (bo)
