

C++ Core Guidelines: Regeln für Deklarationen und die Initialisierung
Weiter mit der Tour durch die Regeln für Ausdrücke und Anweisungen in den C++ Core Guidelines. Dieser Artikel macht bei den Deklarationen und Initialisierungen halt.
- Rainer Grimm

Weiter mit der Tour durch die Regeln für Ausdrücke und Anweisungen in den C++ Core Guidelines. Dieser Artikel macht bei den Deklarationen und Initialisierungen halt.
Um ehrlich zu sein, die meisten dieser Regeln sind ziemlich offensichtlich. Sie bieten aber oft die eine oder andere interessante Einsicht an. Daher wird sich dieser Artikel auf diese besondere Einsichten fokussieren. Hier sind die Regeln, die uns in diesem Artikel beschäftigen.
- ES.11: Use auto to avoid redundant repetition of type names
- ES.12: Do not reuse names in nested scopes
- ES.20: Always initialize an object
- ES.21: Don’t introduce a variable (or constant) before you need to use it
- ES.22: Don’t declare a variable until you have a value to initialize it with
- ES.23: Prefer the {}-initializer syntax
- ES.24: Use a unique_ptr<T> to hold pointers
ES.11: Use auto to avoid redundant repetition of type names
Das Beispiel aus den Guidelines ist mir nicht überzeugend genug. Daher werde ich ein anderes Beispiel präsentieren. Falls auto zum Einsatz kommt, wird das Modifizieren des Codes zu einem Kinderspiel.
Das folgende Beispiel basiert vollständig auf auto. Daher musst du dich nicht mit den Datentypen beschäftigen und kannst somit – und das ist entscheidend – keinen Fehler machen. Das bedeutet in dem konkreten Fall, dass der Datentyp von res am Ende des Programmschnipsel int sein wird.
auto a = 5;
auto b = 10;
auto sum = a * b * 3;
auto res = sum + 10;
std::cout << typeid(res).name(); // i
Falls jetzt aber aus dem Literal b vom Datentyp int ein double (2) oder anstelle des Datentyps int ein float-Literal (3) verwendet werden soll, kein Problem. Das regelt die C++-Laufzeit automatisch.
auto a = 5;
auto b = 10.5; // (1)
auto sum = a * b * 3;
auto res = sum * 10;
std::cout << typeid(res).name(); // d
auto a = 5;
auto b = 10;
auto sum = a * b * 3.1f; // (2)
auto res = sum * 10;
std::cout << typeid(res).name(); // f
ES.12: Do not reuse names in nested scopes
Dies ist eine der ziemlich offensichtlichen Regeln. Du solltest aus Lesbarkeit- und Wartbarkeitgründen keine Namen in verschachtelten Bereichen verwenden.
// shadow.cpp
#include <iostream>
int shadow(bool cond){
int d = 0;
if (cond){
d = 1;
}
else {
int d = 2;
d = 3;
}
return d;
}
int main(){
std::cout << std::endl;
std::cout << shadow(true) << std::endl;
std::cout << shadow(false) << std::endl;
std::cout << std::endl;
}
Welche Ausgabe produziert das Programm? Verwirrt durch die "d"s? Hier ist die Ausgabe.
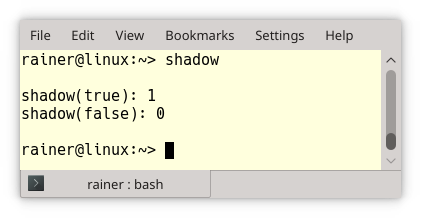
Das war einfach! Dasselbe Phänomen birgt aber eines an Überraschungspotenzial in Klassenhierarchien.
// shadowClass.cpp
#include <iostream>
#include <string>
struct Base{
void shadow(std::string){ // 2
std::cout << "Base::shadow" << std::endl;
}
};
struct Derived: Base{
void shadow(int){ // 3
std::cout << "Derived::shadow" << std::endl;
}
};
int main(){
std::cout << std::endl;
Derived derived;
derived.shadow(std::string{}); // 1
derived.shadow(int{});
std::cout << std::endl;
}
Beide Strukturen Base und Derived besitzen eine Method shadow. Die eine in der Basisklasse nimmt einen std::string (1) an, die anderen einen int (2). Wenn ich nun das Objekt derived mit einem default-konstruierten std::string (3) verwende, nehme ich doch an, dass die Base-Variante aufgerufen wird. Falsch! Da die Methode shadow auch in der abgeleiteten Klasse Derived implementiert ist, wird die Methode in der Klasse Base beim Auflösen der Namen nicht berücksichtigt. Hier ist die Ausgabe meines GCCs.

Um das Problem zu lösen, reicht es aus, die Methode shadow in Derived bekannt zu machen.
struct Derived: Base{
using Base::shadow; // 1
void shadow(int){
std::cout << "Derived::shadow" << std::endl;
}
};
Durch den Ausdruck using Base::shadow (1) kennt die Klasse Derived die Methode shadow und das Programmverhalten entspricht unseren Erwartungen.

ES.20: Always initialize an object
Die Regeln, wann Objekt initialisiert werden, sind recht haarig in C++. Hier ist ein einfaches Beispiel.
struct T1 {};
class T2{
public:
T2() {}
};
int n; // OK
int main(){
int n2; // ERROR
std::string s; // OK
T1 t1; // OK
T2 t2; // OK
}
n ist eine globale Variable und wird daher mit 0 initialisiert. Das gilt aber nicht für n2, da dies eine lokale Variable ist und somit nicht initialisiert wird. Wenn jedoch ein benutzerdefinierter Typ wie std::string, T1 oder T2 in einem lokalen Bereich zum Einsatz kommt, wird dieser initialisiert.
Falls das zu kompliziert ist, gibt es eine einfache Lösung. Verwende auto. Nun kannst du das Initialisieren nicht mehr vergessen. Der C++-Laufzeit stellt das sicher.
struct T1 {};
class T2{
public:
T2() {}
};
auto n = 0;
int main(){
auto n2 = 0;
auto s = ""s;
auto t1 = T1();
auto t2 = T2();
}
ES.21: Don’t introduce a variable (or constant) before you need to use it
Diese Regel ist selbsterkärend. Wir programmieren C++, nicht C.
ES.22: Don’t declare a variable until you have a value to initialize it with
Falls diese Regel nicht eingehalten wird, kann es zum used-befor-set-Fehler kommen. Hier ist das Beispiel aus den Guidelines.
int var;
if (cond) // some non-trivial condition
Set(&var);
else if (cond2 || !cond3) {
var = Set2(3.14);
}
// use var
Bist du dir sicher, dass eine der Bedingungen immer zuschlagen wird? Falls nicht, wird die lokale Variable var nichtinitialisiert verwendet.
ES.23: Prefer the {}-initializer syntax
Es gibt viele gute Gründe, {}-Initialisierung zu verwenden:
- immer anwendbar
- überwindet den ärgerlichsten Parserfehler (most vexing parse)
- verhindert verengende Konvertierung
Eine Regel gilt es aber, bei {}-Initialisierung in Kombination mit auto im Gedächtnis zu behalten. Falls du auto in Kombination mit {}-Initialisierung verwendest, erhältst du nur in C++11 und C++14 eine std::initializer_list, aber nicht in C++17.
Die Details dazu gibt es in meinem Artikel zu {}-Initialisierung.
ES.24: Use a unique_ptr<T> to hold pointers
Ich werde es kurz machen. Ein std::unique_ptr ist per Design so effizient wie ein nackter Zeiger, besitzt aber einen großen Mehrwert. Er passt auf seine ihm anvertraute Ressource auf. Das heißt: Verwende keine nackten Zeiger. Falls dir das als Information zu wenig ist, kannst du die Details zu std::unique_ptr in meinen früheren Artikel nachlesen.
Wie geht's weiter?
Wir sind mit den Regeln für Deklarationen noch nicht fertig. Der verbleibenden werden im nächsten Artikel folgen.
Weitere Informationen
Für mein offenes Seminar sind noch Plätze frei. Es wird definitiv stattfinden.
- C++11 und C++14: 13. bis 15. März 2018
