

Künstliche Intelligenz: Offline-Bibliothek für Verständnis natürlicher Sprache veröffentlicht
Das französische Start-up Snips hat die NLU-Bibliothek, die als Basis für das Sprachverständnis ihrer Embedded-Plattform dient und ohne Cloud-Anbindung arbeitet, als Open-Source-Software freigegeben.

Snips, ein französisches Start-up mit Fokus auf Software und Forschung für künstliche Intelligenz, hat Snips NLU als Open-Source-Software freigegeben. NLU ist ein Akronym für Natural Language Understanding, also Verständnis natürlicher Sprache, einem wichtigen Baustein für die Kommunikation zwischen Menschen und Geräten. Es gehört zu den komplexen Aspekten der künstlichen Intelligenz und bezeichnet die Analyse natürlicher Sprache, um die Intention und die passenden Parameter hinter den Sätzen zu verstehen.
Die Besonderheit der von Snips veröffentlichten Bibliothek ist, dass sie auf den Endgeräten arbeitet. Auf die Weise lassen sich Sprachassistenten oder Chatbots realisieren, die anders als beispielsweise Amazon Lex, Microsofts LUIS auf Azure oder IBMs Watson Natural Language Understanding keine privaten Daten an die Cloud übermitteln. Snips verweist auf einen auf GitHub verfügbaren Benchmark, der die eigene Bibliothek mit Cloud-Diensten vergleicht. Ein PDF mit Vergleichsdaten ist öffentlich zugänglich.
Zwei Parser und eine Entity Resolution
Snips NLU verbindet zwei Parser: einen deterministischen und einen probabilistischen. Ersterer verarbeitet Sätze, die dem Trainingsmodell entsprechen, während letzterer versucht, ähnliche Sätze zu verstehen. Wenn das System beispielsweise "Sag mir das Wetter in ..." kennt und deterministisch verarbeitet, sollte es "Wie ist das Wetter in ..." als selbe Intention herleiten können.
Zur Auswertung der Parameter dient die Entitätsauflösung (Entity Resolution), um beispielsweise aus "am zweiten Mittwoch im März 2018" das konkrete Datum 14.3.2018 herzuleiten, die das System als Parameter verwenden kann.
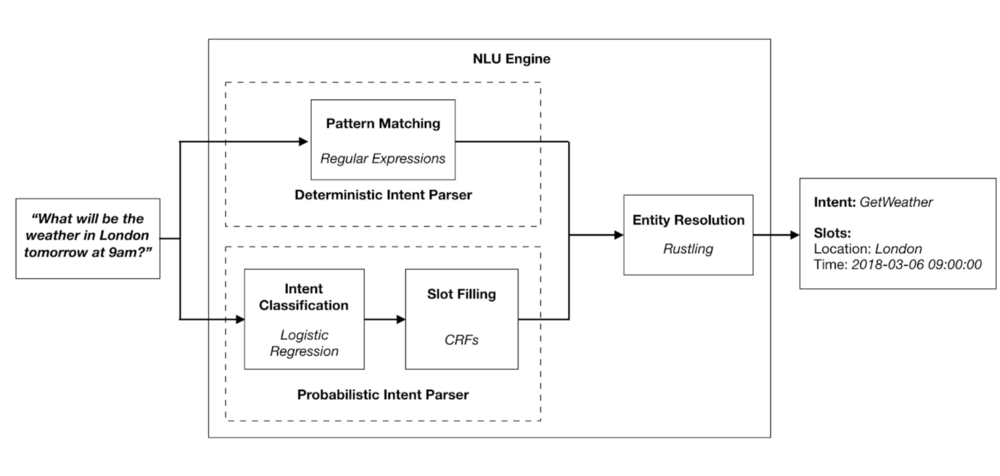
(Bild: Snips)
Reguläre Ausdrücke und Conditional Random Field
Während der deterministische Parser schlicht auf reguläre Ausdrücke (Regular Expressions) setzt und so eine klare Zuweisung der Intention vornehmen kann, arbeitet der probabilistische Parser auf der Basis von Conditional Random Fields (CRF), die speziell darauf trainiert sind, zur Intention passende Felder zu erkennen. Das Team hat laut eigenen Angaben zahlreiche andere Ansätze und Architekturen getestet, darunter auch Methoden des Deep Learning, und schließlich CRFs als effizientesten Weg ausgewählt.
Snips NLU ist auf GitHub verfügbar. Dort findet sich auch eine Implementierung in der Programmiersprache Rust. Die Bibliothek lässt sich unter anderem auf Linux, iOS und Android einsetzen, außerdem läuft sie in der Webkonsole mit einem Scala-Backend. Eine JSON-Serialisierung trainierter Modelle lässt sich als Interface zwischen NLU-Bibliotheken verwenden.
Weitere Details lassen sich dem Blogbeitrag entnehmen. Der Speicherbedarf für die Bibliothek liegt demnach je nach Trainingsumfang zwischen ein paar hundert KByte und wenigen MByte. (rme)
